









 本文通过绘制训练集和验证集的热点图,发现并解决数据集存在的问题,并提供了一种处理数据集中异常值的方法。
本文通过绘制训练集和验证集的热点图,发现并解决数据集存在的问题,并提供了一种处理数据集中异常值的方法。
在对数据集进行训练之前,需要先验证数据集。本文以美国加利福尼亚州房价相关数据,作为演示。训练集和验证集用到的CSV文件在这里:https://download.youkuaiyun.com/download/zhangchao19890805/10584496
下图是加利福尼亚州的地图:
为了验证数据集是否存在缺陷,我们要读取训练集和验证集,观察这些数据的规律。并且按照经纬度绘制热点图,观察地图数据是否准确。
下面的代码完成了上面的工作:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# 从CSV文件中读取数据,返回DataFrame类型的数据集合。
def zc_func_read_csv():
zc_var_dataframe = pd.read_csv("http://49.4.2.82/california_housing_train.csv", sep=",")
return zc_var_dataframe
# 预处理特征值
def preprocess_features(california_housing_dataframe):
selected_features = california_housing_dataframe[
["latitude",
"longitude",
"housing_median_age",
"total_rooms",
"total_bedrooms",
"population",
"households",
"median_income"]
]
processed_features = selected_features.copy()
# 增加一个新属性:人均房屋数量。
processed_features["rooms_per_person"] = (
california_housing_dataframe["total_rooms"] /
california_housing_dataframe["population"])
return processed_features
# 预处理标签
def preprocess_targets(california_housing_dataframe):
output_targets = pd.DataFrame()
# Scale the target to be in units of thousands of dollars.
output_targets["median_house_value"] = (
california_housing_dataframe["median_house_value"] / 1000.0)
return output_targets
# 画热度图
def draw_heat_map(pa_ax, pa_title, pa_x_arr, pa_y_arr, pa_c):
# 设置图表标题
pa_ax.set_title(pa_title)
# 设置y轴自动缩放
pa_ax.set_autoscaley_on(False)
# 设置y轴数值限制
pa_ax.set_ylim([32, 43])
# 设置x轴自动缩放
pa_ax.set_autoscalex_on(False)
# 设置x轴数值限制
pa_ax.set_xlim([-126, -112])
pa_ax.scatter(pa_x_arr, pa_y_arr,
cmap="coolwarm",
c=pa_c)
def zc_func_main():
california_housing_dataframe = zc_func_read_csv()
# 对于训练集,我们从共 17000 个样本中选择前 12000 个样本。
training_examples = preprocess_features(california_housing_dataframe.head(12000))
print(training_examples.describe())
training_targets = preprocess_targets(california_housing_dataframe.head(12000))
print(training_targets.describe())
# 对于验证集,我们从共 17000 个样本中选择后 5000 个样本。
validation_examples = preprocess_features(california_housing_dataframe.tail(5000))
print(validation_examples.describe())
validation_targets = preprocess_targets(california_housing_dataframe.tail(5000))
print(validation_targets.describe())
fig = plt.figure()
fig.set_size_inches(14,7)
# 绘制验证集的热点图
var_c = validation_targets["median_house_value"] / validation_targets["median_house_value"].max()
draw_heat_map(fig.add_subplot(1, 2, 1), "Validation Data", validation_examples["longitude"],
validation_examples["latitude"], var_c)
# 绘制训练集的热点图
var_c_train = training_targets["median_house_value"] / training_targets["median_house_value"].max()
draw_heat_map(fig.add_subplot(1, 2, 2), "Training Data", training_examples["longitude"],
training_examples["latitude"], var_c_train)
plt.show()
zc_func_main()结果如下:
latitude longitude housing_median_age total_rooms total_bedrooms population households median_income rooms_per_person
count 12000.000000 12000.000000 12000.000000 12000.000000 12000.000000 12000.000000 12000.00000 12000.000000 12000.000000
mean 34.614578 -118.470274 27.468333 2655.682333 547.057167 1476.007000 505.38425 3.795047 1.940185
std 1.625970 1.243589 12.061790 2258.147574 434.314754 1174.280904 391.71534 1.851925 1.327142
min 32.540000 -121.390000 1.000000 2.000000 2.000000 3.000000 2.00000 0.499900 0.018065
25% 33.820000 -118.940000 17.000000 1451.750000 299.000000 815.000000 283.00000 2.517200 1.420007
50% 34.050000 -118.210000 28.000000 2113.500000 438.000000 1207.000000 411.00000 3.462250 1.880875
75% 34.440000 -117.790000 36.000000 3146.000000 653.000000 1777.000000 606.00000 4.644625 2.258830
max 41.820000 -114.310000 52.000000 37937.000000 5471.000000 35682.000000 5189.00000 15.000100 55.222222
median_house_value
count 12000.000000
mean 198.037593
std 111.857499
min 14.999000
25% 117.100000
50% 170.500000
75% 244.400000
max 500.001000
latitude longitude housing_median_age total_rooms total_bedrooms population households median_income rooms_per_person
count 5000.000000 5000.000000 5000.00000 5000.000000 5000.000000 5000.00000 5000.000000 5000.000000 5000.000000
mean 38.050778 -122.182510 31.27980 2614.821400 521.059600 1318.13460 491.232400 4.096053 2.078781
std 0.923030 0.480337 13.38939 1979.620397 388.452096 1073.74575 366.523912 2.021218 0.638113
min 36.140000 -124.350000 1.00000 8.000000 1.000000 8.00000 1.000000 0.499900 0.135721
25% 37.490000 -122.400000 20.00000 1481.000000 292.000000 731.00000 278.000000 2.690900 1.749190
50% 37.790000 -122.140000 31.00000 2164.000000 424.000000 1074.00000 403.000000 3.728450 2.066278
75% 38.370000 -121.910000 42.00000 3161.250000 635.000000 1590.25000 603.000000 5.064100 2.375372
max 41.950000 -121.390000 52.00000 32627.000000 6445.000000 28566.00000 6082.000000 15.000100 18.255319
median_house_value
count 5000.000000
mean 229.532879
std 122.520063
min 14.999000
25% 130.400000
50% 213.000000
75% 303.150000
max 500.001000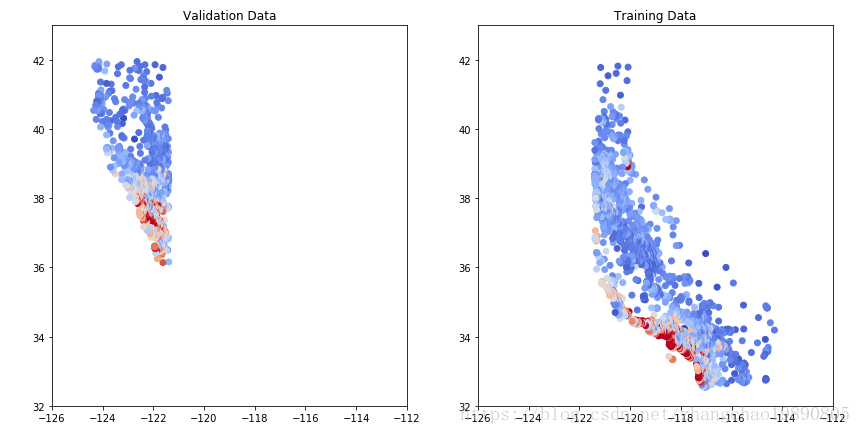
我们可以观察到,训练集的热点图有点类似加利福尼亚州的地图,而验证集的则完全不像。这表明我们的数据可能出了问题,没有均匀覆盖整个州。
我们用CSV文件中的前12000个样本做训练集,后5000个样本做验证集。如果CSV中的数据按照某种顺序排列,确实可能造成这样的问题,所以我们在读取了CSV文件后,需要打乱原来的顺序。改造函数 zc_func_read_csv ,变成如下的样子:
# 从CSV文件中读取数据,返回DataFrame类型的数据集合。
def zc_func_read_csv():
zc_var_dataframe = pd.read_csv("http://49.4.2.82/california_housing_train.csv", sep=",")
# 打乱数据集合的顺序。有时候数据文件有可能是根据某种顺序排列的,会影响到我们对数据的处理。
zc_var_dataframe = zc_var_dataframe.reindex(np.random.permutation(zc_var_dataframe.index))
return zc_var_dataframe热点图的结果就正常了:
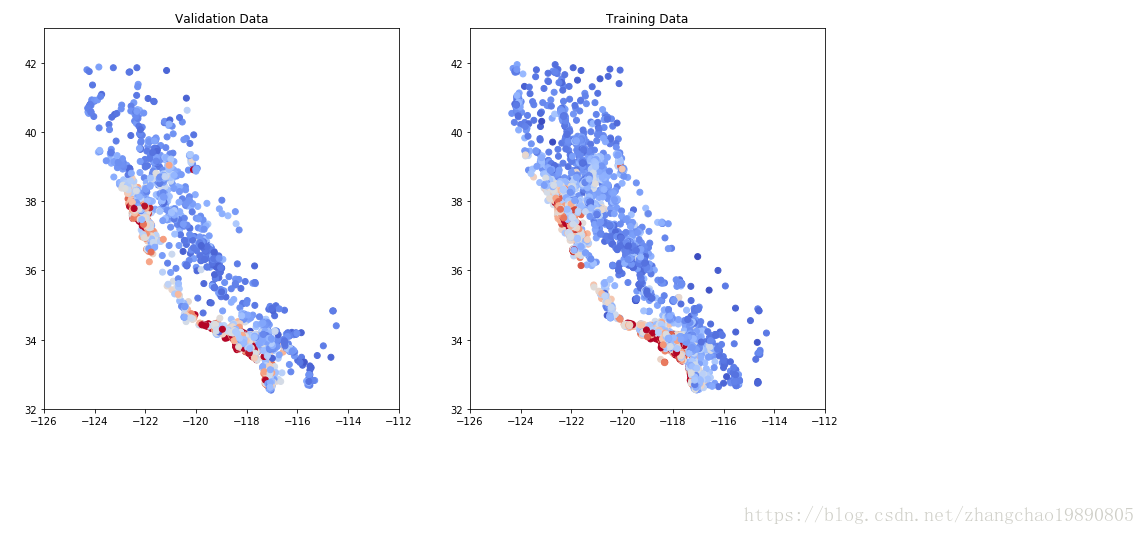
根据输出的列表,可以检查一下其它数据:
对于一些值(例如 median_house_value),我们可以检查这些值是否位于合理的范围内(请注意,这是 1990 年的数据,不是现在的!)。
如果您仔细看,可能会发现下列异常情况:
median_income 位于 3 到 15 的范围内。我们完全不清楚此范围究竟指的是什么,看起来可能是某对数尺度?无法找到相关记录;我们所能假设的只是,值越高,相应的收入越高。
median_house_value 的最大值是 500001。这看起来像是某种人为设定的上限。
rooms_per_person 特征通常在正常范围内,其中第 75 百分位数的值约为 2。但也有一些非常大的值(例如 18 或 55),这可能表明数据有一定程度的损坏。
我们将暂时使用提供的这些特征。但希望这些示例可帮助您较为直观地了解如何检查来自未知来源的数据。

















 5321
5321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









