



目录
(1)为什么python不是像c++那样直接把成员变量列在类的最下方?
1.if、else示例,if,while,for不用加括号而用:
6.append追加元素、“+”拼接两个列表、insert插入元素、pop删除元素、remove删除元素、clear清空元素、del删列表
BGR:顺序为蓝、绿、红,常见于OpenCV默认读取的图像数据(因历史兼容性原因)。
pip install -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple opencv-python
C:\Users\sponge>python -c "import cv2; print(f'OpenCV版本: {cv2.__version__}')"
OpenCV版本: 4.11.0python一键格式化快捷键:ctrl+alt+L
一.基础常识
1.3种注释
快捷注释(再点一次取消注释)ctrl + /
#print("hello world1")
"""
print("hello world2")
"""
'''
print("hello world3")
'''2.python与c++类的区别
(1)为什么python不是像c++那样直接把成员变量列在类的最下方?
Python 和 C++ 的类设计理念、语法规则完全不同,Python 没有 “提前声明成员变量” 的语法要求,也不需要像 C++ 那样在类体固定位置列成员变量
核心原因:
-
Python 是动态类型语言,C++ 是静态类型语言
- C++ 必须在类体中(通常是上方 / 下方)提前声明成员变量的类型(如
int num;),编译器需要靠这个确定内存布局,否则无法编译; - Python 的成员变量是运行时动态绑定的,只有在
__init__(构造方法)中通过self.xxx = ...赋值时才真正创建,无需提前声明,自然也不需要在类体固定位置罗列。
- C++ 必须在类体中(通常是上方 / 下方)提前声明成员变量的类型(如
-
Python 类的成员变量 “诞生于__init__”ISBI2012Dataset 的所有成员变量(如
self.images、self.root_dir)都是在__init__方法中赋值的 —— 这是 Python 类定义的通用规范,而非 “可选写法”。你看到的 C++ 把成员变量列在类下方,是 C++ 的语法强制要求;Python 没有这个要求,且把成员变量的初始化集中在__init__里,是更符合 Python“一切皆对象、运行时绑定” 的设计逻辑。 -
代码可读性与逻辑一致性 Python 将成员变量的初始化放在
__init__中,能让变量的 “定义 + 赋值 + 初始逻辑” 集中在一起(比如self.images在__init__中调用_load_data()赋值),而不是像 C++ 那样 “声明和初始化分离”。对 ISBI2012Dataset 来说,self.images需要依赖self.root_dir和self.train才能加载,把这些逻辑都放在__init__里,比在类体单独列变量更易读、更不易出错。
二.输出变量
1.输出变量
a=123
print(a)
print(f'hello1 {a}')
print('hello2 %d'%a)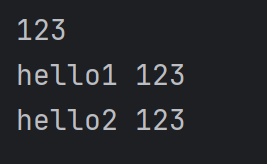
2.结束符end
end表示结束符,默认end=“\n”
print("hello world1",end=" ")
print("hello world2")
print("hello world3")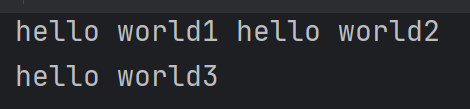
三.input输入变量
input默认字符串类型,可强制类型转换
a=int(input('请输入:'))
print(a)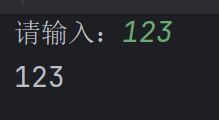
四.生成随机数random
| 功能场景 | Python 标准库random | NumPynumpy.random |
|---|---|---|
| 生成整数随机数 | randint(a, b):闭区间[a, b] | randint(low, high=None, size=None):半开区间[low, high),支持size参数指定数组形状 |
| 生成浮点数随机数 | random():范围[0.0, 1.0)uniform(a, b):范围[a, b] | random(size=None):支持size参数生成数组uniform(low, high, size):范围[low, high) |
1. random模块
import random
a=random.randint(1,10) #生成整数随机数
b=random.uniform(1,10) #生成浮点数随机数
c=random.random() #生成 [0, 1) 的浮点数
print(a,b,c)、
2.numpy中的random模块
np.random.randint(low, high=None, size=None, dtype=int)
- 功能:生成指定范围内的整数随机数。
- 参数:
low:下限(闭区间)。high:上限(开区间,默认None时生成[0, low)的整数)。size:输出数组的形状(如3、(2,3))。dtype:数据类型(默认int,可选np.int32、np.uint8等)。
np.random.randint(1, 5) # 生成1到4之间的单个整数
np.random.randint(5, size=3) # 生成3个0到4之间的整数
np.random.randint(1, 5, (2,3)) # 生成2x3的整数矩阵五.整数可自动变为小数、**为 次方
a=10
a/=3
print(a)
b=10
b**=3
print(b)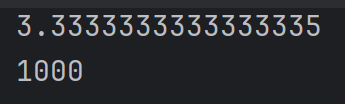
六.or对应||,and对应&&
a = False
b = not a
c = (a and (b or not a)) or a
print(a,b,c)
七.字符可加、可乘
a='ab'
b='cd'
c=a+b
d=a*2+b
print(c,d)——————abcd ababcd
八.循环语句
1.if、else示例,if,while,for不用加括号而用:
-
Python使用冒号(
:)和缩进代替其他语言的括号和花括号 -
条件表达式本身可以加括号(但不改变语义),但控制语句关键字后绝对不能加
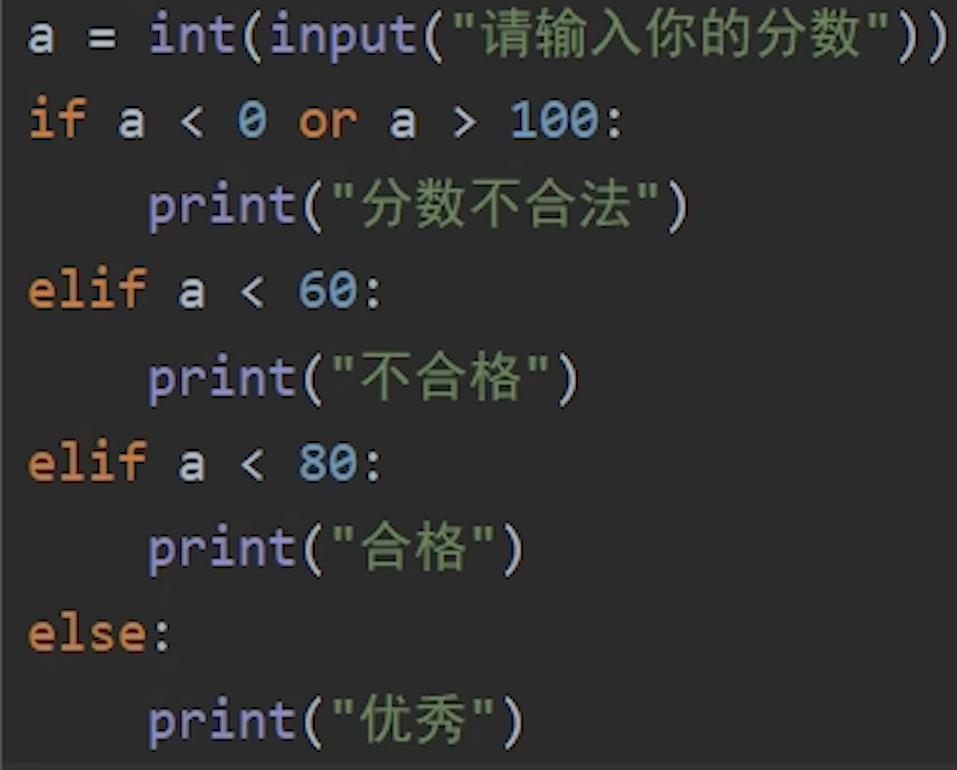
| 语句类型 | 正确写法 | 错误写法(带括号) |
|---|---|---|
while | while a < 10: | while (a < 10): ❌ |
if | if a == 5: | if (a == 5): ❌ |
for | for i in range(5): | for (i in range(5)): ❌ |
2.for循环示例
range[5] 相当 [0,5),即0、1、2、3、4
#[0,1,2,3,4,5,6,7,8,9]
for i in range(10): i是range序列里的一个元素
print(i) 输出:竖着打印0、1、2、3…… 8、9
for i in range(1, 256): 打印从1~255这个序列,因为是左闭右开
print(i)
arr=[1,2,3,4,5]
for j in arr:
print(j) 输出:竖着打印1、2、3、4、5
string="ABCDEFG"
for i in string:
print(i) 输出:竖着打印A、B、C…… G
竖着打印例如:
3.for、while循环搭配else
for i in range(10):
print(i)
if i==5:
break
else:
print('正常结束')
a=0
while a<5:
a+=1
else:
print('end')
九.字符串切片
1.a[1:5]
a=a[1:5] ————左闭右开,切出下标为1、2、3、4的元素,不包括下标为5的元素
a='my name is XXX'
a=a[1:5] 左闭右开,切出下标为1、2、3、4的元素
print(a)
————a=y na
————y na
2.切片各种示例
s = "Hello, World!"
print(s[7:]) # 输出: World!(从索引7开始到结尾)
print(s[:5]) # 输出: Hello(从开头到索引5之前,即开头到索引5的左闭右开)
print(s[3:8]) # 输出: lo, W(从索引3到索引8的左闭右开,即索引3到索引7)
print(s[::2]) # 输出: Hlo ol!(每隔一个字符取一个)步长2是序列操作中跳过元素的间隔数
print(s[::-1]) # 输出: !dlroW ,olleH(反转字符串)
print(s[:]) # 输出: Hello, World!(全部)
print(s[-5:-1]) # 输出: orld 倒数第五个到倒数第一个的左闭右开
❌不用看下面这个例子了❌
a='my name is XXX'
a1=a[:5] 从开始到下标5的左闭右开,即从0到4
print(a1)
————my na
a2=a[1:] 从1开始到结尾
print(a2)
————y name is XXX
a3=a[:] 全部
print(a3)
————my name is XXX
a4=a[1:5:2] 步长2是序列操作中跳过元素的间隔数
print(a4)
————yn
a5=a[::-1] 把字符串反过来
print(a5)
————XXX si eman ym
a6=a[-5:-1] 倒数第五个到倒数第一个的左闭右开
print(a6)
————s XX十.字符串操作
1.替换replace
a='my name is XXX'
a=a.replace('XXX','pig')
print(a)————my name is pig
2.拼接字符串除了直接相加,还可以用join
a=["Hello", "World", "!"]
b="+".join(a)
print(b) # 输出: Hello+World+!
将 a 列表中的所有字符串连接起来,并且使用字符串 "+" 作为连接符。
3.其他操作

十一.与c一样的索引访问
十二.元组
1.元组性质
元组是以圆括号“()”包围的数据集合,括号()可以省略,不同成员(元素)以逗号“,”分隔,如:T=(1,2,3)。
元组是不可变序列,即元组一旦创建,元组中的数据一旦确立就不能改变,不能对元组中中的元素进行增删改操作,因此元组没有增加元素append、修改元素、删除元素pop的相关方法,只能通过序号(索引)访问元组中的成员,元组中的成员的起始序号为0,如:T[0]=1, T=(1,2,3)。
元组中可以包含任何数据类型,也可以包含另一个元组,如:T=(1,2,3,('a','b'))。
空元组(没有元素的元组):T=(),含1个元素的元组:T=(1,),注意有逗号,多个元素的元组:T=(1,2,3)。
任意无符号的对象,以逗号隔开,默认为元组,如下: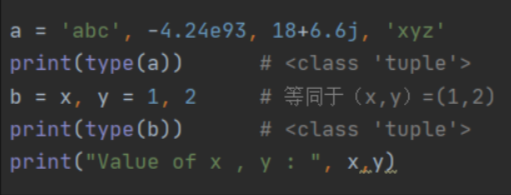
2.元组运算符
与字符串和列表一样,元组之间可以使用+号和*号进行运算,+号用于组合元组,*号用于重复元组,运算之后会生成一个新的元组,如下图所示:
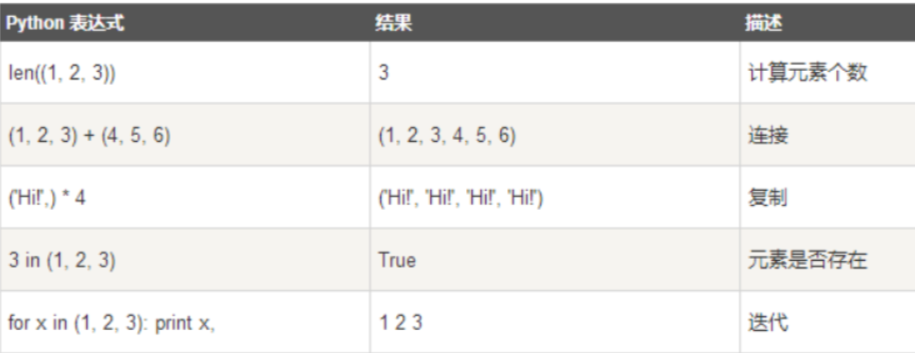
十三.列表
0.一维列表初始化
(1)把arr1元素全初始化为0
arr1 = [0 for i in range(5)]
for i in range(5):
print(arr1[i])(2) numpy一维数组初始化
①
import numpy as np
# 1.从列表创建
arr = np.array([1, 2, 3, 4])
print(arr) # 输出: [1 2 3 4]
# 2.指定数据类型为浮点数
float_arr = np.array([1, 2, 3], dtype=np.float64)
②固定值数组
# 3.长度为5的全0数组
zeros_arr = np.zeros(5) # 输出: [0. 0. 0. 0. 0.]
# 4.长度为3的全1数组(整数类型)
ones_arr = np.ones(3, dtype=int) # 输出: [1 1 1]
# 5.长度为4的全5数组
full_arr = np.full(4, 5) # 输出: [5 5 5 5]1.二维列表
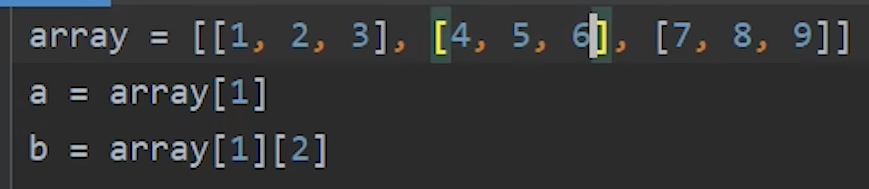
a=[1,2,3]
b=6
(1)二维列表初始化
外层m行,内层每行n个0
m, n = 3, 4 # 行数、列数
arr2 = [[0 for _ in range(n)] for _ in range(m)]
print(arr2)(2)numpy二维数组初始化
用于定义卷积核,因为后续用到 cv2.filter2D() 等函数进行卷积操作,该函数 要求卷积核必须是 NumPy 数组
kernel_x = np.array([[1, 0], [0, -1]], dtype=np.float32)如果直接kernel_x =[[1, 0], [0, -1]],会触发 类型错误(TypeError),因为 OpenCV 无法处理原生 Python 列表。
(3)numpy中初始化全0数组
NumPy 数组的底层数据缓冲区是在 堆 上分配的,类似于C++中的malloc
import numpy as np
# 创建一个形状为 (3, 4) 的全零二维数组(3行4列)
arr = np.zeros((3, 4),dtype=np.uint8)
print(arr)
# 创建3×4的全0数组
zeros_arr = np.zeros((3, 4)) # 形状用元组(3, 4)表示
# 创建2×2的全1数组
ones_arr = np.ones((2, 2), dtype=np.int32) # 指定整数类型
# 创建3×3的全5数组
full_arr = np.full((3, 3), 5)输出:[[0. 0. 0. 0.] [0. 0. 0. 0.] [0. 0. 0. 0.]]
参数1:(3, 4)——指定数组的形状(shape),用元组表示。对于图像,通常是(高度, 宽度)。参数2:dtype=np.uint8(如果不写,默认类型是float):指定数组的数据类型。在图像处理中,通常用uint8(无符号 8 位整数,范围 0-255)表示像素值。
2.三维列表
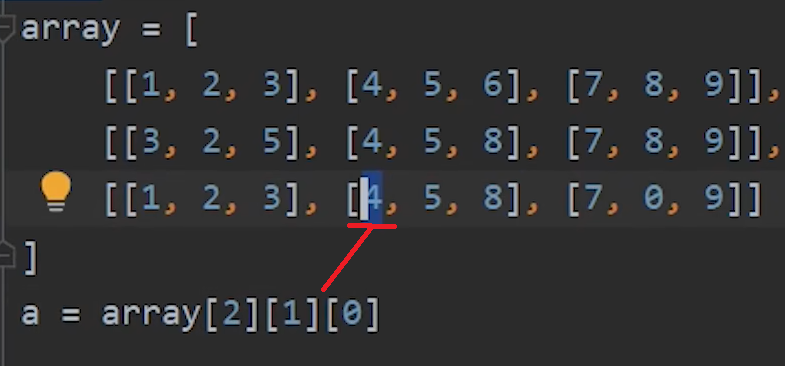
3.遍历三维列表
a是array中的子元素、b是a中的子元素、c是b中的子元素
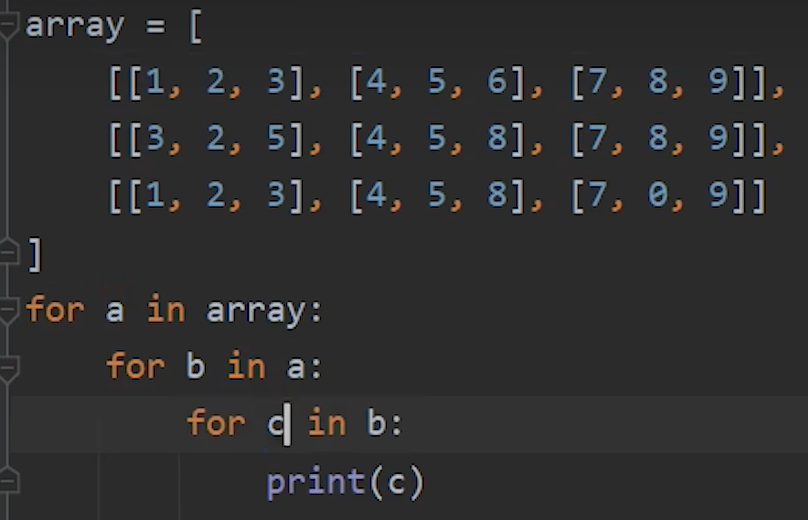
4.判断一个元素是否在列表中(列表什么类型元素任意放)
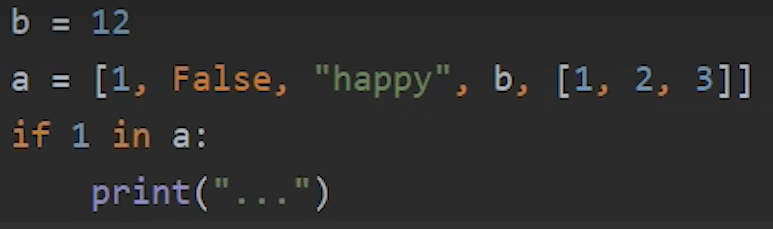
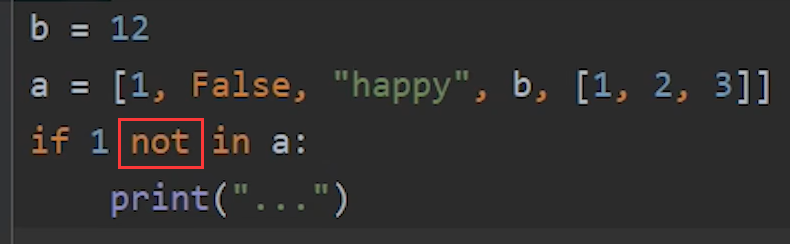
5.判断一个元素是否不在列表中
6.append追加元素、“+”拼接两个列表、insert插入元素、pop删除元素、remove删除元素、clear清空元素、del删列表
b=12
a= [1,False,"happy", b,[1,2,3]]
a.append ("abc") #在列表尾部追加一个字符串元素"abc"
print(a) #输出:[1, False, 'happy', 12, [1, 2, 3], 'abc']
#拼接列表
a = [1, 2] + [3, 4] # → [1,2,3,4](正确)
a = a + ['abc'] # → [1,2,3,4,'abc'](正确)
错误:a=[1, 2]+'abc' #错误写法,必须两个列表拼接,不能直接拼接元素
a= [1,False,"happy", b,[1,2,3]]
a.insert(1,'t') #在索引1的前面加上元素't'
print(a) #输出:[1, 't', False, 'happy', 12, [1, 2, 3]]
a= [1,False,"happy", b,[1,2,3]]
a.pop(0) #删除索引0的元素
print(a) #输出:[False, 'happy', 12, [1, 2, 3]]
a= [1,False,"happy", b,[1,2,3]]
a.remove("happy") #删除指定元素
print(a) #输出:[1, False, 12, [1, 2, 3]]
a= [1,False,"happy", b,[1,2,3]]
a.clear() #清空列表元素
print(a) #输出:[]
del a #直接删除列表a7.列表可直接修改元素,字符串不可
字符串不可修改,因为字符串是不可变数据类型
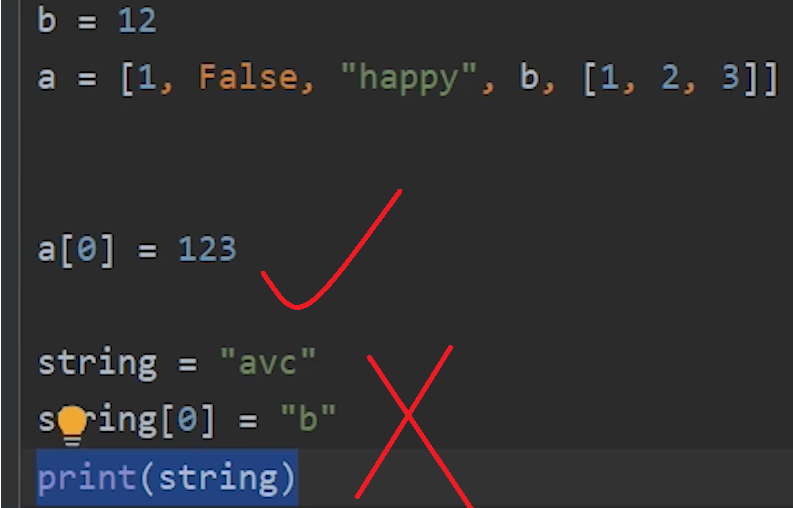
8.列表的拷贝
了解深浅拷贝的区别:把这两个链接结合看C++入门:构造函数,析构函数,拷贝构造函数,运算符重载详解_构造函数的重载规则-优快云博客
大标题 三—> 小标题 2 —>小小标题 <5
C++:vector类【后序】(模拟实现)+深拷贝_c++ vector 深拷贝-优快云博客
大标题 三—> 小标题 1
不愿意看的话,直接总结来说:在c++中举例,浅拷贝只适用于日期类这种数据成员中没有指针的类,不适用栈类这种数据成员中有指针的类,如果对
浅拷贝,它能够完成类成员的一 一复制。当数据成员中没有指针时,浅拷贝是可行的;但当数据成员中有指针时,如果采用简单的浅拷贝,则两类中的两个指针将指向同一个地址,当对象快结束时,会调用两次析构函数,而导致指针悬挂现象,所以,此时,必须采用深拷贝。
深拷贝与浅拷贝的区别就在于深拷贝对于第一个对象中的指针指向的数据,在拷贝出第二个对象时,会在堆内存中另外申请空间来储存一份同样的数据,从而也就解决了指针悬挂的问题。而浅拷贝会导致拷贝出第二个对象时,仅仅把第一个对象的指针复制进第二个对象中,这俩对象的指针会指向同一空间,这样修改第二个对象中指针指向的数据时,第一个对象中的这部分数据也会被修改。简而言之,当数据成员中有指针时,必须要用深拷贝。
b=12
a= [1,False,"happy", b,[1,2,3]]
c=a #①仅仅拷贝指针
d=a.copy() #②独立开辟空间再赋值给d
d.append(5)
d[4].append(4)
print("原始列表 a:", a) 输出:原始列表 a: [1, False, 'happy', 12, [1, 2, 3, 4]]
print("拷贝列表 d:", d) 输出:拷贝列表 d: [1, False, 'happy', 12, [1, 2, 3, 4], 5]
①此处c=a:c和a都指向完全相同的数据
②d=a.copy():d是a的浅拷贝,1,False,"happy", b这些,它属于基本数据类型,直接浅拷贝,自己也有一份,改的就是自己的;而[1,2,3,4]这种,本质d里面拷贝的是a的[1,2,3,4]的首元素地址。所以a、d里面的【1,2,3,4】本质都是一个,因为他们地址一样。所以正常情况还是得用深拷贝deepcopy才能完全把内部的列表(实际是指针)彻底分离、互不影响。
9.排序
sort是直接修改a里面的元素,而sorted有返回值
a=[4,2,3,1]
a.sort() #直接把a排序
a=sorted(a) #排序完返回一个列表10.列表与元组
(1)元组不可修改,只可访问
a=[1,2,3] 列表
b=(1,2,3) 元组
a[0]=5
print(b[0])| 特性 | 列表(List) | 元组(Tuple) | |
|---|---|---|---|
| 可变性 | ✅ 可变(Mutable) | ❌ 不可变(Immutable) | |
| 元素类型 | 异构 (任意类型) | 异构 (任意类型) | |
| 语法标识 | 方括号 [] | 圆括号 ()(可省略) | |
| 内存占用 | 较大(动态扩容) | 较小(固定分配) | |
| 性能 | 增删慢(平均O(n)) | 访问快(O(1)) | |
| 适用场景 | 需要修改的数据集合 | 固定数据(如坐标、配置项) |
(2)元组的两种遍历
第一个直接遍历,第二个是索引遍历
a=(1,2,3,4,5)
for i in a:
print(i,end="")
print() #打印一个换行
for i in range(len(a)):
print(a[i],end="")(3)单元素元组
元组的定义是用圆括号 () 包裹元素,且元素之间用逗号分隔。对于单元素元组,为了与 “用括号包裹的表达式” 区分(比如 (3+2) 是表达式,不是元组),Python 规定:单元素元组必须在元素后加一个逗号。
(1,)
(array([5, 10, 15]),)十四.张量与元组
1.介绍张量
张量是 PyTorch 中用于数值计算的多维数组对象。它包含的数据几乎总是数值数据,因此它是数字的容器。你可能对矩阵很熟悉,它是二维张量。张量是矩阵向任意维度的推广[注意,张量的维度(dimension)通常叫作轴(axis)]。所有多维数组(包括 NumPy 数组、PyTorch Tensor 等)都可以称为 “张量”(按维度分为 0 阶、1 阶、2 阶等),例如np.array(12)是一个0维张量;torch.tensor([1, 2, 3])是一个一维张量
- numpy数组在广义上被称为 “张量”,主要用于通用数值计算。
torch.Tensor是专为深度学习设计的张量,在多维数组基础上增加了深度学习必需的功能。
张量形状的描述:
注:张量(Tensor)是 多维数组对象,而张量的形状(shape) 是一个元组(tuple)
在描述张量的维度结构(如 [batch_size, 32, 28, 28] 这类场景)时,中括号和小括号在语义上是等价的,都可以使用,区别仅在于语境和习惯:
- 用中括号更偏向 “直观表达维度的顺序和含义”,是文档、教程中最常见的简化写法,强调 “这是一组维度大小的列表”,可读性更强。
- 用小括号更严格对应代码中
shape属性的元组类型(如(batch_size, 32, 28, 28)),适合在强调 “形状的技术本质是元组” 时使用。
2.pytorch中的tensor张量
(1)tensor类长什么样子?
pytorch中的tensor张量是严格意义上的张量,torch.Tensor类的对象就是张量,它除了存储 “单个数值” 外,还自带了 PyTorch 为张量设计的一系列属性和方法(如 grad_fn、requires_grad、grad 等),在这里:那value可以理解为数组类型,也就是说value取一个值时整个张量就是标量,value取一维数组多个值时就是一维张量,取二维数组整个张量就是二维张量,value 的数据结构(维度)直接决定了张量的 “阶数”(即标量、向量、矩阵等)
下面用 Python 模拟一个简化版的 “张量类”(类似 PyTorch 的 Tensor),这个类会包含深度学习中张量的关键特性(如值、梯度、梯度函数、父张量依赖等):
class MyTensor:
def __init__(self, value, requires_grad=False, grad_fn=None, parents=None):
self.value = value # 张量存储的数值(可以是标量或数组)
self.requires_grad = requires_grad # 是否需要计算梯度
self.grad = None # 存储梯度(反向传播后赋值)
self.grad_fn = grad_fn # 梯度函数:记录反向传播的运算逻辑
self.parents = parents # 父张量列表:记录生成当前张量的原始张量
def __add__(self, other):
"""重载加法运算,自动构建计算图依赖"""
# 计算加法结果值
result_value = self.value + other.value
# 标记是否需要梯度(只要一个父张量需要,结果就需要)
requires_grad = self.requires_grad or other.requires_grad
# 定义加法的反向传播函数(计算梯度)
def add_backward(grad):
# 加法的梯度:对两个父张量的梯度等于传入的梯度
self.grad = grad if self.grad is None else self.grad + grad
other.grad = grad if other.grad is None else other.grad + grad
# 递归计算父张量的梯度(如果父张量有自己的反向函数)
if self.grad_fn:
self.grad_fn(self.grad)
if other.grad_fn:
other.grad_fn(other.grad)
# 返回新的张量,记录依赖关系和反向函数
return MyTensor(
value=result_value,
requires_grad=requires_grad,
grad_fn=add_backward, # 绑定加法的反向函数
parents=[self, other] # 记录父张量
)
def __mul__(self, other):
"""重载乘法运算,类似加法"""
result_value = self.value * other.value
requires_grad = self.requires_grad or other.requires_grad
def mul_backward(grad):
# 乘法的梯度:对a的梯度是b*grad,对b的梯度是a*grad
self.grad = other.value * grad if self.grad is None else self.grad + other.value * grad
other.grad = self.value * grad if other.grad is None else other.grad + self.value * grad
if self.grad_fn:
self.grad_fn(self.grad)
if other.grad_fn:
other.grad_fn(other.grad)
return MyTensor(
value=result_value,
requires_grad=requires_grad,
grad_fn=mul_backward,
parents=[self, other]
)
def backward(self, grad=1.0):
"""触发反向传播,计算梯度"""
if self.requires_grad and self.grad_fn:
self.grad_fn(grad) # 调用当前张量的反向函数,传入初始梯度(标量默认1.0)
def __repr__(self):
return f"MyTensor(value={self.value}, requires_grad={self.requires_grad}, grad={self.grad})"(2)类成员变量grad_fn与反向传播函数的联系
重点说一下这个类成员变量,为了给我的文章:opencv学习笔记9——>大标题二——>10——>(5)做解释。
<1>引入
在我的opencv学习笔记9文章中,我们在基于CNN的mnist分类任务中,先跑了一遍前向传播得到预测结果output,再通过loss = criterion(output, target) 得到交叉损失熵赋给loss,使其成为一个标量,(而这个标量正如上面所说的不单单是一个单一数值的数组,而是一个tensor对象,这个loss对象其中的value是一个单一数值的数组,除了包含这个value变量还自带了其他许多变量和函数)接下来进行 loss.backward()反向传播函数可以通过标量loss进行————,那是如何通过loss损失值反向找到父张量呢?
# 训练
for epoch in range(5): # 训练5轮
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()<2>grad_fn 的类型:反向传播函数对象
grad_fn 本质是一个 **“反向运算函数对象”**,它不仅记录了 “当前张量由哪些父张量生成”,还记录了 “通过什么运算生成”。在 PyTorch 中,grad_fn 的类型取决于生成当前张量的运算类型,例如:
- 加法运算生成的张量,
grad_fn是AddBackward0类的实例; - 乘法运算生成的张量,
grad_fn是MulBackward0类的实例; - 卷积运算生成的张量,
grad_fn是Conv2dBackward0类的实例; - 交叉熵损失生成的
loss张量,grad_fn是CrossEntropyLossBackward类的实例。
这些类都是 PyTorch 底层预定义的,专门用于实现对应运算的反向传播逻辑。
<3>grad_fn 用于找寻父张量
grad_fn 对象内部通过属性引用的方式记录父张量(即生成当前张量的原始张量)。例如,对于 c = a + b:
c.grad_fn是AddBackward0的实例,它内部会有一个属性(如_inputs)存储[a, b]这两个父张量。- 当调用
c.backward()时,AddBackward0对象会利用存储的a和b,计算它们的梯度(dc/da和dc/db)。
我们可以通过代码验证这一点(以加法为例):
import torch
a = torch.tensor(2.0, requires_grad=True)
b = torch.tensor(3.0, requires_grad=True)
c = a + b # c的grad_fn是AddBackward0
# 查看grad_fn的类型
print(type(c.grad_fn)) # <class 'torch.autograd.function.AddBackward0'>
# 查看grad_fn存储的父张量(不同版本属性名可能不同,通常是_inputs)
print(c.grad_fn._inputs) # (tensor(2., requires_grad=True), tensor(3., requires_grad=True))
# 这里的_inputs就是父张量a和b<4>grad_fn 作用
每个张量都通过<3>的方式存着父张量的信息,对于一个张量就能找到他的父张量,找到父张量又能找他的父张量,这个过程就像沿着 grad_fn 组成的 “运算依赖链” 反向追溯,每个 grad_fn 都是链条上的一个节点,既指明了父张量,又提供了反向计算的方法。所有张量的 grad_fn 以及它们之间的依赖关系隐式构建一个类似于链表的计算图,就像一串珍珠项链。这也就是反向传播函数为什么能通过loss损失值反向找到每一个张量节点,进而再进行后续梯度计算工作。
3.张量举例
(1)标量(0D 张量)即0维张量
仅包含一个数字的张量叫作标量,np.array(12)就是一个0维张量。
在 Numpy中,一个 float32 或 float64 的数字就是一个标量张量(或标量数组)。你可以用 ndim 属性来查看一个 Numpy 张量的轴的个数。标量张量有 0 个轴( ndim == 0 )。
import numpy as np
x = np.array(12)
print(x.ndim)
print(x) 输出:
- 0
- 12
(2) 向量(1D 张量)/ 一维张量
数字组成的数组叫作向量(vector)或一维张量(1D 张量)。一维张量只有一个轴。下面是一个 Numpy 向量。np.array([12, 3, 6, 14, 7])就是一个1维张量。
import numpy as np
x = np.array([12, 3, 6, 14, 7])
print(x.ndim)
print(x) 输出:
- 1
- array([12, 3, 6, 14, 7])
注意:这个向量有 5 个元素,所以被称为 5D 向量。不要把 5D 向量和 5D 张量弄混! 5D 向量只有一个轴,沿着轴有 5 个维度,而 5D 张量有 5 个轴(沿着每个轴可能有任意个维度)。维度(dimensionality)可以表示沿着某个轴上的元素个数(比如 5D 向量),也可以表示张量中轴的个数(比如 5D 张量),这有时会令人感到混乱。对于后一种情况,技术上更准确的说法是 5 阶张量(张量的阶数即轴的个数),但 5D 张量这种模糊的写法更常见。
(3) 矩阵(2D 张量)/ 二维张量
向量组成的数组叫作矩阵(matrix)或二维张量(2D 张量)。矩阵有 2 个轴(通常叫作行和列)。你可以将矩阵直观地理解为数字组成的矩形网格。下面是一个 Numpy 矩阵。
import numpy as np
x = np.array([[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]])
print(x.ndim)结果:
- 2
张量形状是(3,5)
(4)3D 张量与更高维张量
将多个矩阵组合成一个新的数组,可以得到一个 3D 张量,你可以将其直观地理解为数字组成的立方体。下面是一个 Numpy 的 3D 张量。
import numpy as np
x = np.array([[[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]],
[[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]],
[[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]]])
print(x.ndim)结果:
- 3
将多个 3D 张量组合成一个数组,可以创建一个 4D 张量,以此类推。深度学习处理的一般是 0D 到 4D 的张量,但处理视频数据时可能会遇到 5D 张量。
(5)torch.Tensor 张量
import torch
#从 Python 列表 / 元组创建——————————————————————————————————————————
# 从列表创建(1阶张量)
t1 = torch.tensor([1, 2, 3])
print(t1) # tensor([1, 2, 3])
# 从嵌套列表创建(2阶张量,矩阵)
t2 = torch.tensor([[1, 2], [3, 4]])
print(t2) # tensor([[1, 2], [3, 4]])
#预定义初始化(常用场景)——————————————————————————————————————————
# 全0张量(形状为(2, 3))
t_zero = torch.zeros(2, 3)
# 全1张量(形状为(3, 1))
t_one = torch.ones(3, 1)
# 随机初始化(均匀分布,0~1之间)
t_rand = torch.rand(2, 2)
# 随机初始化(标准正态分布)
t_randn = torch.randn(3, 3)
# 单位矩阵(2阶方阵)
t_eye = torch.eye(3)
#张量的基本属性——————————————————————————————————————————
t = torch.tensor([[1, 2, 3], [4, 5, 6]])
print(t.shape) # 形状(维度大小):torch.Size([2, 3])
print(t.dtype) # 数据类型:torch.int64(默认整数类型)
print(t.device) # 存储设备:cpu(默认)或 cuda:0(GPU)
print(t.requires_grad) # 是否跟踪梯度:False(默认不跟踪,需手动开启)
#从 NumPy 数组转换(共享内存,高效交互)——————————————————————————————————————————
import numpy as np
np_arr = np.array([[1, 2], [3, 4]])
t_from_np = torch.from_numpy(np_arr) # NumPy→PyTorch
np_from_t = t_from_np.numpy() # PyTorch→NumPy(共享内存,修改一个会影响另一个)2.张量与元组
(1)数据类型与存储
张量:仅存储数值型数据(整数、浮点数等),支持 GPU 加速和自动微分,底层基于高效的 C++ 实现,适合大规模数值计算。
元组:可存储任意类型数据(数值、字符串、对象等),是纯 Python 结构,不支持数值加速或微分。
张量:
import torch
tensor = torch.tensor([1.0, 2.0, 3.0]) # 仅存储数值型数据
元组:
tuple_data = (1, "hello", [2, 3]) # 同时存储整数、字符串、列表(2)可变性
张量:部分可变(值可修改,但形状需通过特定操作调整),且支持自动微分(跟踪运算历史)。
元组:完全不可变(创建后元素和结构均无法修改)。
张量:
tensor = torch.tensor([1, 2, 3])
tensor[0] = 10 # 可修改元素值
tensor = tensor.reshape(3, 1) # 可调整形状
元组:
tuple_data = (1, 2, 3)
# tuple_data[0] = 10 # 报错:元组不支持元素赋值(3)运算能力
张量:支持丰富的数值运算(加减乘除、矩阵乘法、激活函数等),且能利用 GPU 并行加速。
元组:仅支持基本的 Python 内置操作(索引、切片、拼接等),无数值运算加速。
张量:
a = torch.tensor([1, 2])
b = torch.tensor([3, 4])
print(a + b) # 逐元素相加:tensor([4, 6])
print(torch.matmul(a, b)) # 点积:1*3 + 2*4 = 11
元组:
a = (1, 2)
b = (3, 4)
print(a + b) # 拼接元组:(1, 2, 3, 4),而非数值相加十五.集合
1.介绍
在python中,一般通过花括号或set来定义一个集合,例如
S = set() # 定义一个空的集合
S1={} #这是一个空字典了使用花括号定义一个有数据的集合,元素可以是数字、字符串、元组等
S = {1.1, "AA", ("X", "Y")}注意:由于定义集合的符号与字典一致,所以当定义一个空的花括号会被识别为字典,而不是集合
集合的特点:
- 集合中的元素是唯一的,重复的元素会被自动忽略。
- 集合是无序的,元素没有固定的位置。
- 集合中的元素必须是可哈希的,因此,只能包含不可变对象,如数字、字符串、元组等。
- 集合支持常用的集合操作,如并集、交集、差集等。
S = {1, 2, 2, 4,4}
print(S) #输出:{1, 2, 4}2.添加元素
常用的两种添加元素方法:
- add:向集合中添加一个元素。如果集合中已经存在该元素,则不会进行任何操作。
- update:向集合中添加一个或多个元素,参数可以是可迭代对象。
【示例一】添加一个元素 add
S = {"A", "B"}
S.add(10)
print(S)输出:{'A', 10, 'B'}
【示例二】添加多个元素 update
S = {"A", "B"}
S.update([1, 2, 3])
print(S)输出:{1, 2, 3, 'A', 'B'}
3.删除元素
常见有4种删除元素的方法:
- remove:如果元素在集合中,则移除该元素,否则会引发 KeyError 错误。
- discard:如果元素在集合中,则移除该元素,否则不做任何操作。
- pop:随机移除并返回集合中的一个元素。如果集合为空,会引发 KeyError 错误。
- clear:移除集合中所有的元素
S={"A","B","C","D","E","F","G","H"}
S.remove('A')
print(S) #输出:{'B', 'E', 'C', 'H', 'F', 'G', 'D'}
S.discard('B')
print(S) #输出:{'E', 'C', 'H', 'F', 'G', 'D'}
S.pop()
print(S) #输出:{'C', 'H', 'F', 'G', 'D'}
S.clear()
print(S) #输出:set()4.修改元素
集合是无序且不可更改的,所以需要修改某个元素时只能先删除,后添加
S = {"A", "B", "C"}
# 移除B
S.discard("B")
# 添加E
S.add("E")5. 访问元素
集合一般是用于存储唯一元素的无序数据结构,重点在于元素的唯一性和高效的成员关系测试。所以它的重点并不是用于访问单个元素,而是用于快速读取。
S = {1, 2, "A", "B"}
for i in S:
print(f"当前元素是: {i}")6.统计元素
S = {1, 2,3, 4}
print(len(S)) 统计元素个数 输出:4
print(max(S)) 求最大值(仅全数字) 输出:4
print(min(S)) 求最小值(仅全数字) 输出:1
print(sum(S)) 求和(仅全数字) 输出:107.计算列表不重数个数
S = [1, 2, 2, 3, "A", "A"] # 示例输入(列表)
step1 = set(S) # 去重:{1, 2, 3, "A"}
step2 = len(step1) # 计算唯一元素数量:4
print(step2) # 输出:48.成员检查
- 集合提供了一种高效的方法来检查元素是否属于某个集合。使用集合的成员关系操作,可以快速判断一个元素是否在集合中。
在集合中一般通过 in 判断某个元素是否存在。成功为True,失败为False
S = {1, 2, "A", "B"}
print("A" in S) 输出:True
print("A" not in S) 输出:Flase十六.字典
1.介绍
字典中元素是一个个键值对
2.各种字典操作
d = {"name":"sponge", "age" :20}
d.keys() 取出所有key值
# ['name', 'age']
d.values() 取出所有val值
#['sponge',20]
d.items() 返回键值对组成的元组,元组又靠列表包着
#[('name','sponge'),('age',20)]
for k,v in d.items(): 遍历
print(k)
print(v)d = {"name" : "sponge", "age": 20}
print(d["name"]) 访问值
d["name"] ="squidward" 修改值
del d["age"] 删除值
d.clear() 清空字典
del d 删除字典十七.定义函数
1.定义格式
def function():
print('hello world1')
for i in range(5):
function()2.形参、实参
n是形参、num是实参
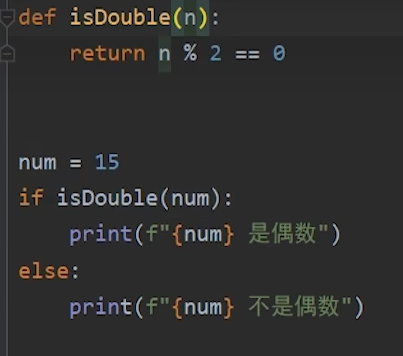
3.函数使用外部变量
函数使用外部变量要用global关键字声明这是一个外部变量
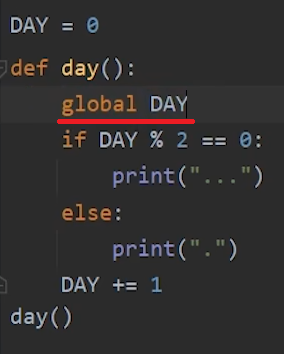
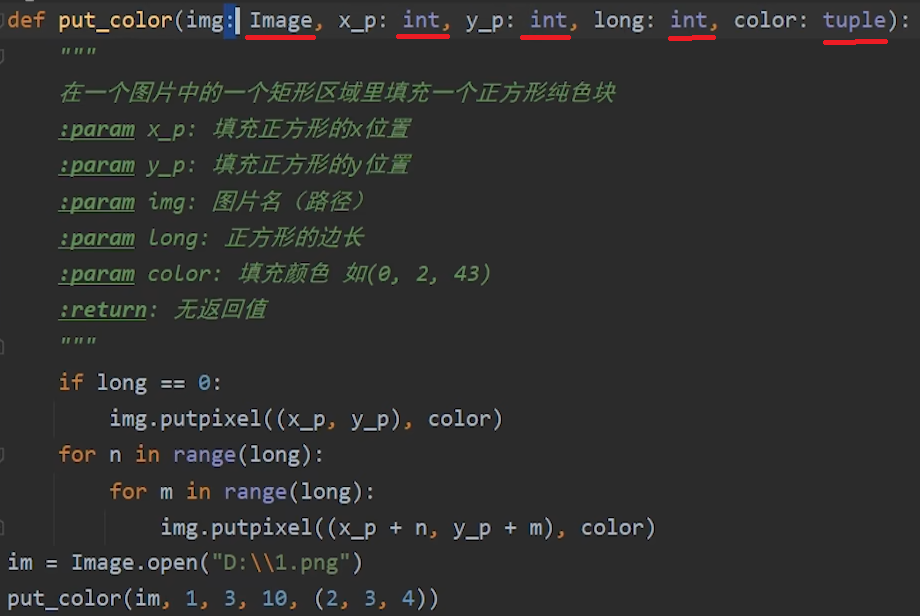
4.函数的形参可以用冒号标识类型
5.函数返回元组、元组的拆包
def g():
return 1,2
a=g() #变成元组
print(a)
a,b=g() #元组的拆包
print(a,b)输出:
(1, 2)
1 2
6.不定长参数 args
不定长参数允许函数接受可变数量的参数。下面g函数里面,n是普通参数,要写到不定长参数前面,调用中实参填入的“1”传入n这个普通参数中。args是不定长参数,可以传任意个参数,调用中实参填入的“2,3,4,5,6”传入不定长参数中。
def g(n,*args):
print(f"n:{n}")
for i in args:
print(f"args:{i}",end=" ")
g(1,2,3,4,5,6)输出:
n:1
args:2 args:3 args:4 args:5 args:6
7.包裹关键字参数
传入的是字典
def func(**kwargs):
print(kwargs) # kwargs 是一个字典
func(name="Alice", age=25) # 输出: {'name': 'Alice', 'age': 25}十八.调试
启动调试:Shift + F9
| 操作 | 功能描述 |
|---|---|
| F9 | 跳到下一个断点 |
F8 | 执行当前行并跳到下一行,不进入函数内部(适合跳过已知正确的代码)。 |
F7 | 进入当前函数内部(如调试calculate_average()时,按F7进入函数体)。 |
Alt + Shift + F7 | 只进入自己项目的代码,忽略库函数(如跳过 NumPy 内部实现)。 |
Shift + F8 | 从当前函数返回到调用处(执行完当前函数剩余代码并跳出)。 |
Alt + F9 | 快速执行到光标所在位置(无需设置断点,适合跳过大量无关代码)。 |
十九.打印函数print常用语法
1.打印 字符串、数字、变量
# 打印单个内容
print("Hello Python") # 输出字符串
print(123) # 输出数字
print([1, 2, 3]) # 输出列表
# 打印多个内容(逗号分隔,自动用空格连接)
name = "Alice"
age = 20
print("姓名:", name, "年龄:", age) # 输出:姓名: Alice 年龄: 202.自动换行
print("第一行", end=" ") # 结尾用空格,不换行
print("第二行") # 输出:第一行 第二行
#下面这两个完全等价,print打印后自动换行
print("Hello")
print("Hello", end="\n") # 输出:Hello 并换行3.字符串
(1)字符串拼接(+)
适合简单拼接,但需保证类型一致(非字符串需转换):
score = 95
print("成绩:" + str(score)) # 输出:成绩:95(2)f-string(Python 3.6 + 推荐)
在字符串前加 f,用 {} 嵌入变量 / 表达式,简洁高效:
name = "Bob"
height = 1.75 #下面的.2f表示表示保留两位小数、以浮点数形式显示数值
print(f"姓名:{name},身高:{height:.2f}米") # 输出:姓名:Bob,身高:1.75米
print(f"1+2={1+2}") # 支持表达式,输出:1+2=3(3)% 格式化(老式用法)
类似 C 语言的格式化,用 % 占位符匹配内容:
print("姓名:%s,年龄:%d" % ("Charlie", 25)) # 输出:姓名:Charlie,年龄:25
print("圆周率:%.2f" % 3.1415) # 输出:圆周率:3.144.计时器
(1)计算总运行时间
记录开始时间,结束时间,然后两者相减
import time
# 记录开始时间
start_time = time.time()
# 执行需要计时的代码(比如你的MNIST训练代码)
for epoch in range(5):
# 模拟耗时操作
time.sleep(0.1)
# 记录结束时间
end_time = time.time()
# 计算并输出耗时
print(f"总耗时:{end_time - start_time:.4f} 秒")(2)动态打印时间:用两个开始时间相减
这个是原始版本(别用)
import time
def dynamic_timer():
start_time = time.perf_counter() # 记录开始时间
# 模拟你的任务(比如训练循环)
for epoch in range(5):
# 模拟每个epoch的耗时操作
time.sleep(1) # 替换为你的实际代码
# 计算并打印已运行时间
elapsed_time = time.perf_counter() - start_time
print(f"已运行:{elapsed_time:.2f}秒 | 当前epoch:{epoch+1}/5")
dynamic_timer()这是我改进的版本(推荐):
start_time=time.perf_counter() #直接把开始时间定义成全局变量
def over_timer(start_time):
over=time.perf_counter()-start_time
print(f"已运行:{over:.2f}秒",end="\n")
#在需要计时的地方放上计时器:
over_timer(start_time)

















 2475
2475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









