







为什么要用交叉熵损失函数
在机器学习中用到的最多的是MSE(最小二乘损失函数),这个比较好理解,就是预测值和目标值的欧式距离。而交叉熵是一个信息论的概念,
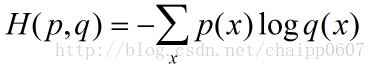
其中p代表目标值,q代表预测值 。x表示单个样本的维度。对于分类问题,假如n个类别,一般情况下输出为n个神经元(只有其中正确属性的一维为1,其他为0),则上式可以简写为:
H(p,q)=-log(qi) ,i为其中正确属性维数的置信概率值。如此我们便非常清晰的看到,实际的交叉熵损失函数就是预测的正确维数值与1的某种距离(当qi=1时,即预测完全正确,距离为0)。多个样本可以取平均。所以说交叉熵损失函数可以很好地适用于分类问题,而不是其他回归问题。

















 3735
3735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









