



基于词秩图的无载体文本信息隐藏方法
1 引言
信息隐藏是一个研究领域,其技术可将秘密数据不可察觉地隐藏到载体介质中,以保护知识产权或实现秘密通信[1]。由于文本在人们的日常生活中被广泛使用,文本信息隐藏吸引了众多研究人员的关注,并取得了大量成果。文本信息隐藏可分为四类:基于文本格式的文本信息隐藏、基于文本图像的文本信息隐藏,以及基于生成方法和嵌入方法的自然语言信息隐藏。
基于文本格式的信息隐藏方法自1994年由马克斯姆丘克、布拉西尔和洛等人首次提出,他们通过改变行间距、词间距、字符高度、字符宽度及其他字符特征来实现信息隐藏,并在PostScript文档上测试了这些隐藏方法。此后,许多学者对这些方法进行了改进[2–9]。[10]通过调整组单元中词语或字符间距的统计特征来嵌入信息。根据该理论
中文数学表达式[11]将汉字拆分为若干部分,利用部分间的互联图匹配,并结合文本相似性来隐藏信息。秘密信息可以通过在句子末尾、行末、段落末尾以及文本文件末尾插入或删除换行符和不可见字符(如空格、制表符、特殊空格)的方式进行隐藏[12–15]。这些基于不可见性的方法具有较大的嵌入容量和良好的隐蔽性,但无法抵抗基于统计分析的隐写检测,因此安全性不高[16]。
基于文本格式的信息隐藏方法有很多种类,隐藏容量较大,但大多数无法抵抗重排攻击、OCR攻击以及基于统计分析的隐写检测[17–20]。如果文档在提取文本内容后以无格式方式重新生成,则嵌入在文本格式中的隐藏信息将不复存在。
文本可被视为二值图像,与灰度图像和彩色图像相比具有一些特殊性质,因此基于文本图像的信息隐藏方法利用这些特性来隐藏信息。例如,[21, 22]通过修改块内黑白像素数量的奇偶性来嵌入信息,[23]通过修改块内黑白像素的比例来嵌入信息。[24]通过修改边界的连通区域在二值图像中嵌入信息。[25]提出了一种基于像素翻转的嵌入方法。[26]通过结合DCT域与DWT域,将隐藏信息嵌入文本的原始DWT域中。基于文本图像的信息隐藏方法的一个主要缺陷是完全无法抵抗重排和OCR攻击。如果隐写文本中的字符被重新格式化,隐藏信息将完全消失。
在文本信息隐藏中,还有两种常用的方法。一种是基于文本生成的自然语言信息隐藏方法,也称为基于生成方法的自然语言信息隐藏,通过使用自然语言处理技术自动生成类自然文本以包含秘密信息。该方法可以欺骗计算机的统计分析,但相对容易被人识别[27]。另一种是基于改变文本内容的信息隐藏方法,也称为基于嵌入的自然语言信息隐藏,通过不同粒度修改文本,在保持局部和全局文本语义不变的前提下隐藏信息[28, 29]。与基于文本格式的信息隐藏相比,该方法具有更强的鲁棒性和更好的隐蔽性,但由于自然语言处理技术的限制,隐藏算法非常困难,并且在统计和语言学方面存在一些偏差和失真[30]。
从上述可以看出,文本信息隐藏已引起众多学者的关注,并取得了大量成果,但仍存在抗统计分析能力弱、文本合理性差等问题。此外,理论上只要对载体进行了修改,秘密消息就必然会被检测到。只要秘密信息存在于载体文本中,就很难逃脱隐写分析。因此,现有的隐写技术正面临着巨大的安全性挑战,其发展遇到了瓶颈[31]。
所提出的方法基于通过对文本大数据进行统计分析计算得到的秩图,转换隐藏信息,计算秩表,并检索文本大数据以获得包含转换后的词的隐写文本。最后,该隐写文本可以在不作任何修改的情况下发送给接收方。由于该方法不修改隐写文本,因此对所有当前的隐写分析方法都具有鲁棒性,且所提出的算法具有较高的理论意义和应用价值。
2 无载体信息隐藏
无载体信息隐藏是一种新的、具有挑战性的研究领域。事实上,“无载体”并非指完全没有载体,而是与传统信息隐藏相比,无载体信息隐藏不需要额外的[31]载体。无载体信息隐藏的思想具有深厚的历史渊源,古代的藏头诗就是一个经典例子。藏头诗是一种诗歌或其他形式的文本,其中每一行、段落或其他重复结构的首字母、音节或词语连起来可拼出一个单词或信息。查尔斯·路德维希·道奇森(1832年1月27日–1898年1月14日),更广为人知的是其笔名刘易斯·卡罗尔,是一位英国作家、数学家、逻辑学家、圣公会执事和摄影师。他最著名的作品是《爱丽丝梦游仙境》’。刘易斯·卡罗尔为作者一生中最重要的童年朋友之一格特鲁德·查塔韦创作了一首独特的双层藏头诗。正是格特鲁德激发了他创作伟大的荒诞叙事诗《猎鲨记》(1876年),该书题献给她,并以一首以其名字作为双层藏头诗的诗歌开篇。这首藏头诗如图1所示。

3 提出的方法
3.1 预处理
假设我们已获得一个文本数据库,并且该集合中包含U个唯一词(词汇表)。对于集合中的每个词语,我们计算其出现次数的频率——即该词语在集合中出现的次数。然后,我们根据频率对这些词语进行降序排名(出现频率最高的词语排名为1,其次的词语排名为2⋯⋯)。
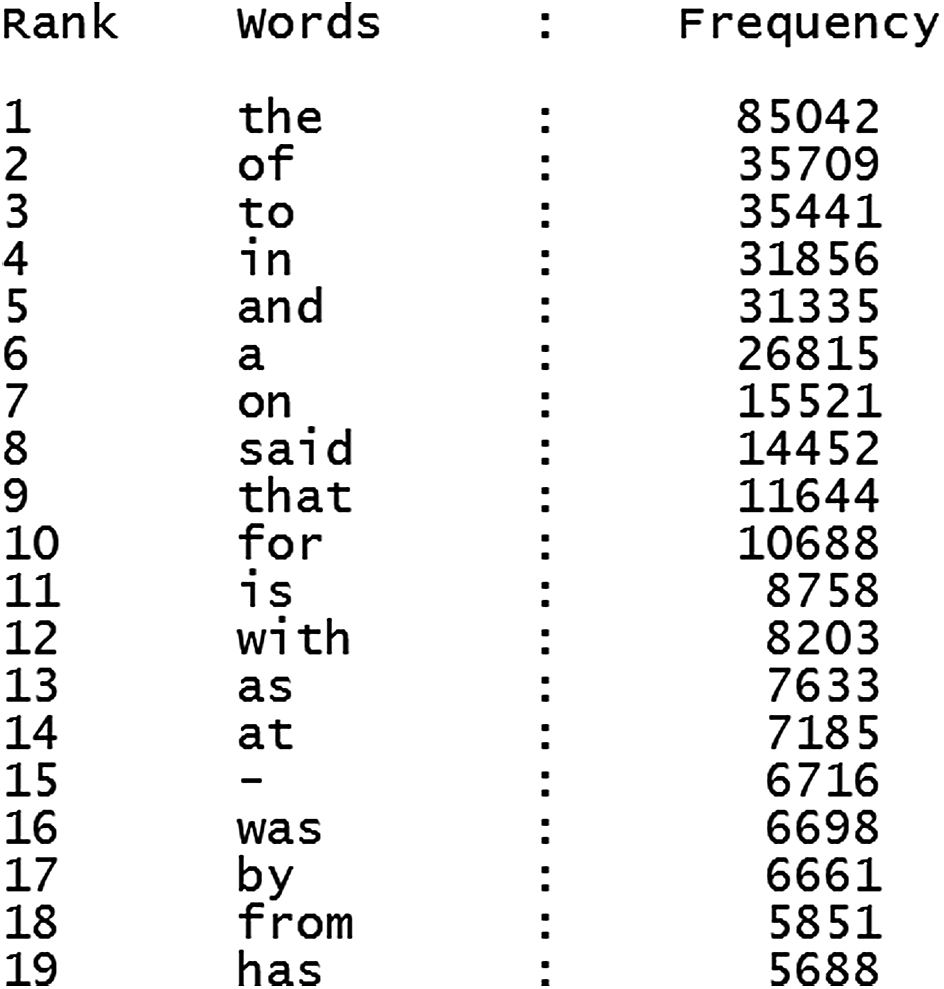
图2显示了定义为文本集合的词序图的排序结果。从秩图中,我们发现该集合中的总词数(非唯一词数量)为1282023,唯一词数量为33268,最频繁的词是词语“the”。同时,我们可以获得集合中每篇文章的词序图。图3显示了一篇名为“德克萨斯州小型飞机坠毁事故致1死1伤”的文章的秩图,其中包含178个词,以及120个唯一词。
通过对文集进行统计分析,我们可以得到文集中每个词的秩图,并获取其在文集中的出现信息,例如,频率、排名和来源文章。图4展示了单词“said”的秩图。
我们将文本集合或文章的词序图定义为
$$
W = {w_i \mid i = 1, 2, 3, …, U}
\tag{1}
$$
其中,U是文本集合中的唯一词数量,i是$w_i$的排名。对于图2中的示例,我们可以得到
$W = {\text{the}, \text{of}, \text{to}, \text{in}, \text{and}, \text{a}, \text{on}, \text{said}, …}$。
对于文本集合中出现的每个词$w_i$,我们将其定义为排名图
$$
RW_i = {rw_{ij} \mid i = 1, 2, 3, …, U; j = 1, 2, 3, …, Z}
\tag{2}
$$
其中$rw_{ij}$是单词$w_i$在文章中根据其出现次数的排名,Z是单词$w_i$出现的文章数量。对于如图4所示的示例,我们find
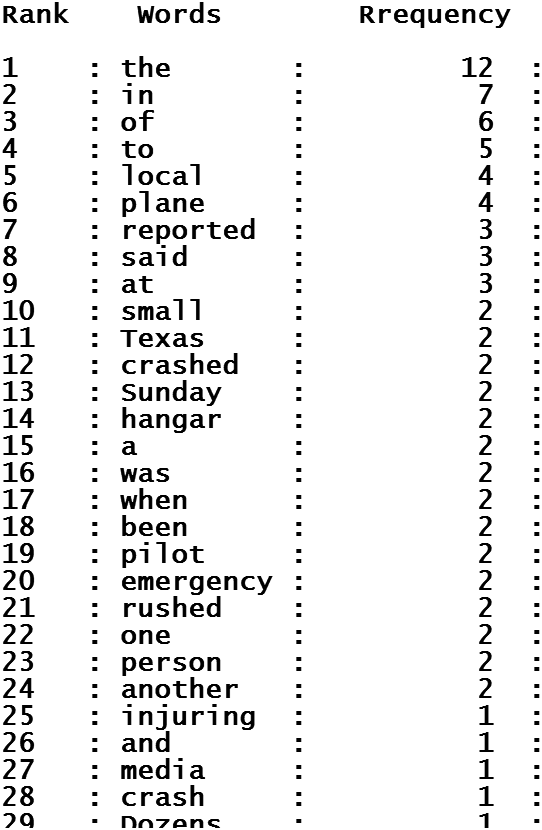

$RW_8 = {4, 6, 9, 3, 4, 6, 11, 6, 8, 8, 7, 15, 9, 10, 7, 11, 6, 9, 12, …}$用于词“said”,其在文本数据库中的出现次数排名为8,如图2所示。
3.2 信息隐藏
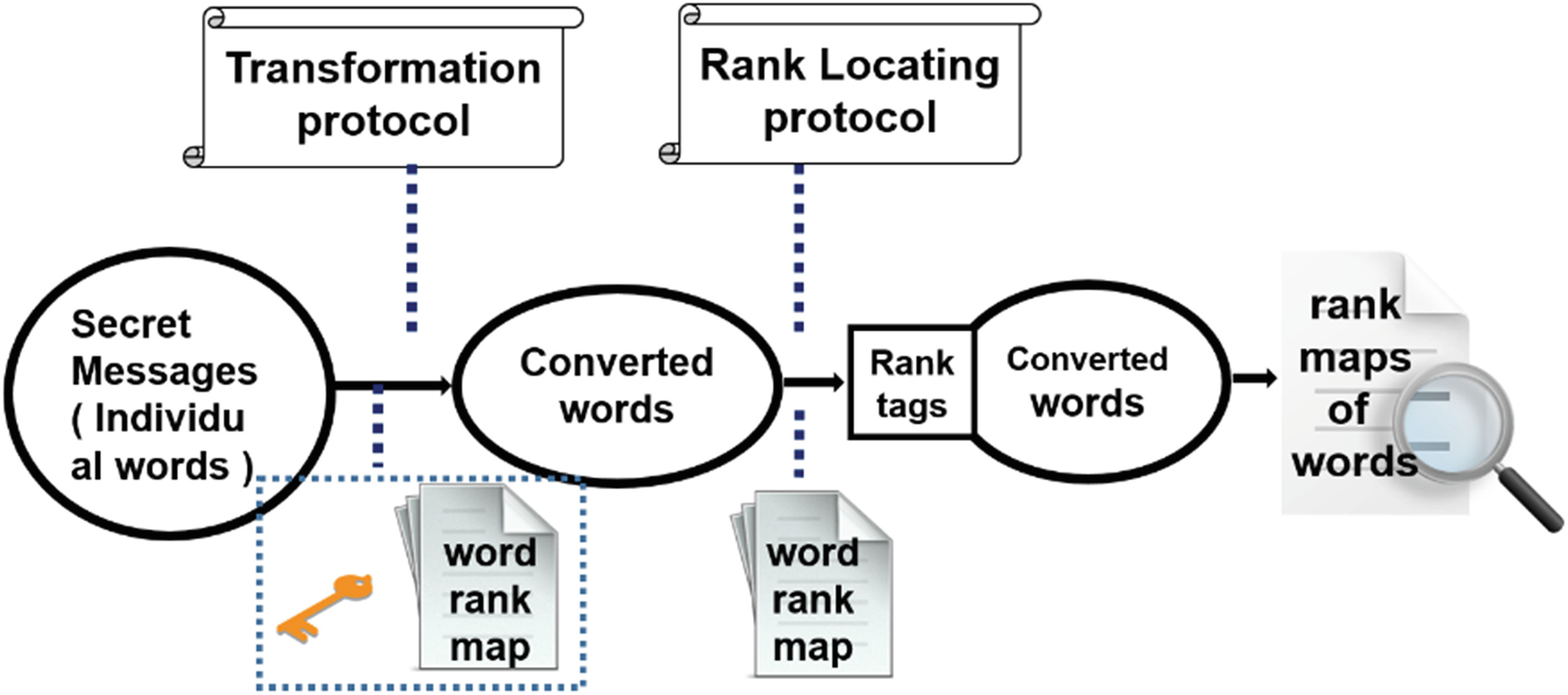
基于文本集合的无载体文本信息隐藏方法,首先,我们将秘密信息分割成若干单个词。通过分析文本集合的秩图以及每个词语在其中出现的秩图,利用变换协议将这些词语转换为文本集合秩图中的高频词。然后,通过使用排名定位协议为转换后的词设计排名标签,得到包含秘密信息的词语及其排名标签。最后,我们搜索这些词语’的秩图以找到一些包含该秘密信息的文章,并实现零修改的信息隐藏。设$m$为一个词语,假设秘密信息为$M = {m_1,m_2,m_3,…,m_n}$,其中$m_i$是一个单个词,n是秘密消息中词语的数量。其秘密信息的转换与排序过程如图5所示。具体细节介绍如下。
(1) 词语转换。为了增强数据的安全性,我们不直接对秘密信息进行处理,而是利用通信双方事先约定的转换协议,将M中的单个词转换为一些高频词。该转换协议可设计如下:$m’_i = f_w(m_i, T), i = 1, 2, 3, …, n$,其中$f_w(m_i, T)$为词语映射函数,T为私钥(例如上述公式中的T),n为M中词语的数量。T可通过通信双方运行同步函数生成,并每日更新。词语映射函数用于将秘密消息转换为W中前T个词构成的子集,该集合在“预处理”部分中由公式(1)定义。
假设T为50,则$m’_i (i=1,2,3,…,n)$的集合即为W中前50个词所组成词集的一个子集。为了增强随机性,我们可以根据事先约定的通信协议设计一组转换函数,并使用不同的转换函数每次通信时,将M中的单个词映射到高频词语集合的不同子集,以提高数据安全性。通过对秘密消息M应用转换函数,可得到转换后的秘密消息$M’ = m’_1 m’_2 … m’_n$。其中,M显然是在‘预处理’部分定义的词语集合W的一个子集。
(2) 获取排名标签。为了获得秘密消息$M’$的排名标签,过程介绍如下:
步骤1. 对于W中前T个词中的每个词语,计算其在文本集合中的秩图。例如,假设一个词语是“an”,其排名为26,如图3所示,其秩图为{7, 21, 21, 4, 4, 8, 8, 3, 9, 4, 5, …}。我们可以得到W中前T个词的一组秩图,记为$RW_i$,其中$i = 1, 2, 3, …, T$。$RW_i$在“预处理”部分由公式(2)定义。
步骤2. 获取$RW_i (i = 1, 2, 3, …, T)$的交集,记为IR。因此$IR = \bigcap_{i=1}^{T} RW_i$。由于这些词语是W中的前T个词,因此该交集非空,且IR中元素的值为整数,即W中前T个词的共同秩。
步骤3. 对于秘密消息$M’$,通过实施通信双方约定的排名定位协议,从交集IR中选择一个排名数值。设$M’$所选的排名为$r’$。排名定位协议可设计如下:$r’ = f_r(IR)$,其中$f_r(IR)$为整数生成函数,生成的整数属于IR。该函数可设计为通信双方之间的同步函数。
(3) 搜索隐写文本。对于每个$m’_i$,我们通过选择的排名$r’$检索其秩图,并从文本集合中获取一个隐写文本,其中$m’_i$在该隐写文本的秩图中的排名为$r’$。因此,我们得到一个隐写文本集。这些隐写文本是一个包含已转换秘密消息的正常文本集,可以发送给接收方。
3.3 信息提取
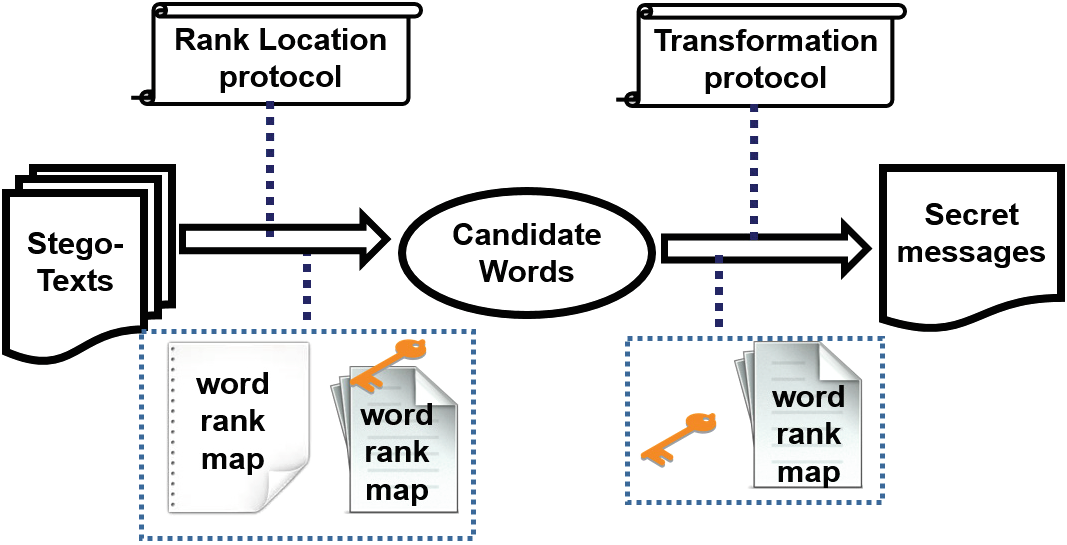
在传统文本信息隐藏中,隐写文本对接收方而言是异常的,但对其他人来说是正常的,因此接收方可以通过分析这些异常来提取隐藏信息。然而,在无载体信息隐藏中,隐写文本实际上是公开且正常的正常文本,接收方无法通过’发现异常位置findingthe abnormal place[31]来提取秘密信息。假设隐写文本为S,则 S是一组正常文本,其中元素的个数等于秘密消息中词语的数量。设T为接收方的私钥,则提取过程如图6所示。具体细节如下所述。
(1)获取秩图。接收到隐写文本后,接收方计算词语的出现次数频率,并按频率降序对词语进行排名。然后,接收方即可得到如图’ 3所示的秩图。3。
(2)获取秩表。由于文本集合对所有用户开放,因此接收方可以获取“预处理”部分中定义的集合W,并使用私钥T获得W的一个子集。该子集的元素为W中的前T个词。然后,对于该子集中的每个词语,接收方可以获取其排名图集合 $RW_i(i = 1, 2, 3, …, T.)$,其中$RW_i$在“预处理”部分的公式(2)中定义。因此,接收方可以通过执行函数$f_r(IR)$得到交集$IR = \bigcap_{i=1}^{T} RW_i$以及秩表,并将其记为 $R_r$。$R_r$显然等于发送方计算出的秩表$r’$。
(3)获取候选词。接收方可以通过密钥$R_r$检索隐写文本的秩图来找到候选词,并获得候选词$m’_i$。由于接收到的隐写文本序列对应于秘密消息中单个词的顺序,因此接收方可以获得由发送方转换得到的秘密消息对应的候选词序列$M’ = m’_1 m’_2 … m’_n$。
(4) 获取秘密消息。在获得候选词后,接收方可以使用$f^{-1}_w(m’_i, T)$与私钥T来获取秘密消息中的单个词,然后得到秘密消息$M = {m_1, m_2, m_3, …, m_n}$。
4 示例验证
为了清晰地说明上述无载体文本信息隐藏过程,我们通过一个简单的例子进行说明。例如,设秘密信息M仅为一个单词“information”。对于包含多个单词的秘密消息,其操作流程相同。此处,假设私钥为数字50,文本集合为从互联网收集的3571个普通文本组成的集合。信息隐藏的操作流程介绍如下:
首先,发送方计算文本集合的秩图以及其中每篇文章的秩图,如图3和4所示。由于私钥为50,发送方可以得到排名前50的词语集合$W_{top50} = {w_i \mid i = 1, 2, 3, …, 50}$,其中$w_i$是文本集合秩图中的词语,i是其排名。该$W_{top50}$为:
f的;的;到;在;和;一个;在;说;那个;为了;是;与;作为; 在;;是;由;从;有;他;它;美国;将;有;中国;一个;是;是; 它的;他的;是;不;哪个;这;之后;但;政府;人们;被;总统; 也;新;中国人;两个;他们的;谁;我们;更多;有;部长g:
发送方通过使用私钥执行变换协议计算出转换后的消息M’,并令M’为单词“us”。
其次,发送方计算$W_{top50}$中每个单词的秩图,如图4所示,并得到秩图矩阵$RW = [rw_{ij}]$,其中$rw_{ij}$表示单词$w_i$在文章中根据其出现次数所对应的排名,Z为单词$w_i$出现的文章数量。秩图矩阵如下所示:
$$
\begin{pmatrix}
1 & 2 & 2 & 19 & 1 & \cdots & 1 & 1 & 1 & 1 & 2 \
\vdots & \vdots & \vdots & \vdots & \vdots & \ddots & \vdots & \vdots & \vdots & \vdots & \vdots \
142 & 214 & 63 & 175 & 35 & \cdots & 12 & 124 & 5 & 8 & 79
\end{pmatrix}
$$
值得一提的是,由于$W_{top50}$中每个词出现的文章数量不相等,因此矩阵每行的元素数量不同,而列数为50。发送方计算该矩阵各行的排名交集,得到的交集为:
$$
IR = {11, 13, 14, 15, 16, 17, 18, 19, 20, 22, 23, 24, 26, 31, 35, 37, 42}
$$
显然,交集中有17个元素,对于其中的每个元素,必然存在一些文章,在这些文章中,$W_{top50}$中每个词的排名都是它。
第三,发送方通过执行排名定位协议来计算M’的秩表。例如,假设排名定位函数只是一个将发送消息日期映射到交集IR中元素序列号的函数。那么,如果序列号为2,则发送方可以得到秩表为13。
最后,发送方检索由秘密消息“information”转换得到的单词“us”的秩图,并在文本集合中找到一篇名为“G20 urges US to act quickly to avoid default”的文章,其中单词“us”的排名为13。然后,发送方将该文章发送给接收方。
由于文本集合对所有用户开放,信息提取过程是信息隐藏过程的逆过程,这里不再赘述。然而值得一提的是,为了提高抗检测性能,必须完成两项工作:一是定期更换私钥,以确保转换后的词是最高排名词语的不同子集;二是建立一个大型文本数据库(文本大数据),以确保秩表有更多的选择。
5 结论
对于常用的文本信息隐藏方法,秘密信息被嵌入到隐写文本中,该隐写文本对接收方而言是异常的,但对其他人来说是正常的。由于隐写文本经过修改,接收方可以通过分析这些异常来提取秘密信息,这些异常是发送方修改的结果。因此,这类方法很难逃避隐写分析。本文首次提出了词序图的概念,并利用词序图设计了一种无覆盖文本信息隐藏方法。所提出的方法仅需正常文本且无需任何修改即可实现信息隐藏,因此接收方无需分析异常之处即可提取隐藏信息。因此,所提出的方法能够抵抗所有现有的隐写分析方法。

















 2279
2279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









