 社会商业智能流式架构
社会商业智能流式架构




信息学
文章为社会商业智能建模分析流
因迪拉·兰扎‐克鲁兹 1 ID,拉斐尔·贝尔兰加 1,* ID和玛丽亚·何塞·阿拉姆布鲁 2
1哈乌梅一世大学计算机语言与系统系,西班牙卡斯特利翁‐德拉普拉纳12071;lanza@uji.es2哈乌梅一世大 学计算机工程与科学系,西班牙卡斯特利翁‐德拉普拉纳12071;aramburu@uji.es*通讯作者: berlanga@uji.es;电话:+34‐964‐72‐8367
收到日期:2018年6月25日;接受日期:2018年7月23日;发布日期:2018年8月1日
摘要:
社会商业智能(SBI)使企业能够从公开的社交网络中获取战略信息。与传统的商业智能 (BI)不同,SBI必须应对社交网络内容和企业分析请求的高度动态性,以及海量的噪声数据。要 有效利用这些连续的数据源,需要对流式数据进行高效处理,并将其语义化为具有洞察力的事实。
本文提出一种多维形式化方法,用于直接从事实流(由社交网络数据衍生而来)中表示和评估社会 指标。该方法基于两个核心方面:通过关联开放数据实现事实的语义化表示,以及支持类OLAP的多 维分析模型。与传统的BI形式化方法不同,我们首先根据企业的战略目标建模所需的社会指标;基 于这些规范,对所有必要的事实流进行建模并部署,以追踪相关指标。该方法的主要优势在于可便 捷地定义按需社会指标,并通过流式事实处理变化的维度和指标。我们通过引入汽车行业中的一个 真实用户案例场景,验证了该方法的有效性。
关键词
:社会商业智能;数据流模型;关联数据
1.引言
商业智能(BI)的主要目标是从不同数据源提供的信息中提取战略知识,以支持决策过程并帮助 企业实现其战略目标。面向BI的海量数据处理与分析在近年来不断发展。传统上,最常用的方法结合 了数据仓库(DW)、在线分析处理(OLAP)和多维(MD)技术[1],,应用于非常特定的场景,依 赖静态且结构良好的企业级数据源,所有信息都被完全物化,并以批处理模式定期处理,供后续分析 使用。最近,探索式OLAP的新技术被引入,旨在利用半结构化的外部数据源(例如,XML、RDF), 用于发现和获取可与企业数据结合以支持决策过程的相关数据。
如今,与决策相关的商业智能流程受到社交媒体趋势的影响,后者为产品和服务提供了即时的用 户反馈。社交网络是信息生态系统的基本组成部分,社交媒体平台在用户、消费者和企业中实现了前 所未有的覆盖,为任何专业环境提供了有用的信息渠道。由于上述原因,从商业和科学角度开发解决 方案的兴趣日益增长。然而,存在一些特殊性,使得无法直接
信息学2018,5,33;doi:10.3390/informatics5030033 www.md p i.com/ j ournal/informatics
本文档由funstory.ai的开源PDF翻译库BabelDOCv0.5.10(http://yadt.io)翻译,本仓库正在积极的建设当中,欢迎star和关注。
信息学2018, 5, 33 2共17页
直接采用传统的商业智能技术的原因是,待分析的社交数据被视为大数据(即数量大、无边界、异构、 半结构化和非结构化数据、易变性以及高速或流式特性)。
用于大数据分析的新方法和架构也得到了发展。目前,我们可以明确区分两种趋势,即:传统和 流式分析架构用于大数据。第一种在文献中应用最为广泛,它将各种大数据源集成到基于多维方案 (数据仓库/联机分析处理)的原始数据存储库中。所有信息都存储在历史存储库中,尽管有时数据的 动态性会导致资源浪费。数据处理以批处理方式进行,导致商业智能系统发出警报较晚,并延迟了决 策过程。
一种更新的方法,符合当前大数据处理的需求,更加注重信息的速度和即时性,通过流式处理数 据,并根据设计的模型,结合批处理分析过程以生成知识模型。这样,它们可以提供来自模型的新鲜 分析数据和丰富信息。仅存储知识模型所需的信息,从而优化内存使用。
然而,这些方法仍处于开发阶段,文献中探讨的方法主要针对解决非常具体的问题,将流处理引 擎(SPE)与OLAP系统等技术相结合。遇到的主要困难在于独立开发的技术的部署,以及通过临时流 程进行连接,这可能导致信息不必要的重复和性能下降。分析维度以静态方式处理,而大数据的本质 具有动态性和无限的多维性。这些方法既不是整体解决方案,也不具备可扩展性或可伸缩性。
因此,本文的目标是提出一种用于大数据分析的通用架构,以支持对流式动态多维数据的处理。
本工作的主要贡献可概括如下:
- 我们对社会商业智能提出的主要方法进行了全面的修订。
- 我们提出了一种专门面向社会商业智能的流式架构。
- 我们提出了一种用于社会商业智能的分析流建模新方法。
本文其余部分组织如下。在第2节中,我们回顾了与社会分析解决方案相关的工作,识别出文献 中所涉及的主要分析方法和任务。第3节介绍提出的架构,第4节介绍基于汽车领域的用例的原型实 现。最后,第5节给出了主要结论。
2.社交分析的方法与任务
大数据的处理与分析仍是一个非常年轻的研究领域。最近,一些作者提出了用于流数据处理的若 干架构,其中包括流式分析、Lambda、Kappa和统一架构[2]。迄今为止,这些提案尚未成为标 准,因为它们尚未经过充分评估,也未在多个领域得到验证。在选择架构时,必须明确了解需要建模 的使用场景。为了开发一种能够覆盖广泛大数据分析任务的通用架构,我们开展了一项最新进展 研究,识别出主要任务及用于处理这些任务的最常用方法论。我们的综述重点关注那些提出流式处理 社交数据解决方案的相关文章,特别是那些由推特的API服务提供的数据。
表1总结了与分析任务相关的研究发现。在回顾的文献中,我们确定了一组被划分为六个主要类 别的分析任务:情感分析、用户画像、帖子画像、事件检测、用户网络交互和系统推荐。这些任务大 多关注行为模式和特征的分析,这些特征可以被编码并采用机器学习技术进行分类。不同类型的特征
信息学2018, 5, 33 17中的 3
类别通常用于捕捉分析对象(例如,用户、帖子、事件)的正交维度,如表2所示。
| 类别 | 分析任务 | 特征类别 | 参考文献 |
|---|---|---|---|
| 情感分析 | 情感指标。通信分析。用户,群组,社区,社会。特征描述 人类 ,社会和文化行为。帖子内容 | [3–6] | |
| 用户画像 | 作者画像,用户分类。推断用户属性(年龄、性别、收入、 教育等)。政治倾向、种族和商业 粉丝检测。用户兴趣识别。 | 用户指标,帖子内容, 帖子指标, 情感, 网络 | [7–10] |
| 垃圾邮件发送者、机器人检测、推广者、影响者 检测。 | All | [11–17] | |
| 帖子画像 | 活动、话题、垃圾信息、模因、讽刺、谣言, 恐怖主义检测 | 帖子、链接、突发 | [18–23] |
| 事件检测 | 基于位置和时间的实时事件检测, 事件分类,抗议和示威 疾病和灾难检测,研究 城市之间的人口迁移。趋势的实时分类。 | 帖子内容,帖子指标, 话题标签, 位置,时间,爆发 | [18–23] |
| 社交分析 网络和用户 互动 | 社交网络中的影响和相关性,社交 网络动态、网络和节点 分类 ,检测有影响力的节点。 | 图网络, 用户指标 | [24] |
| 推荐 系统 | 用户、新闻、媒体推荐。 | 用户指标,帖子指标, Time | [25] |
表2.社交分析不同任务中使用的特征类别[14]。
| 类别 | 描述 |
|---|---|
| 用户指标 | 用户特征指的是与社交网络上的用户账户相关的元数据。您可以 包括地理位置、好友列表、提及次数等数据。 |
| 帖子内容和指标 | 帖子特征可以分为两个主要部分:文本内容和帖子元数据。通过文本可以分析其内容,并基于语言识别线索 利用自然语言处理算法的特征。从文本中也可以 提取链接、话题标签或嵌入多媒体。另一方面,元数据指的是用户与帖子互动的记录,例如 回复数量、转发、点赞或发布日期。 |
| 网络 | 网络分析的最初目的是捕捉其宏观结构的基本特征。在微观层面,网络分析人员关注个体节点的重要性。网络 特征捕捉了信息传播模式的多个维度。统计特征可以 从转发、提及和话题标签约现中提取。从全局网络中, 可以提取节点数量、边数量、密度和直径等指标; 主要任务包括基于度、中介中心性和接近中心性的节点和边分类; 另一方面,进行分析以寻找社区并比较 典型节点[26]。 |
| 爆发 | 爆发是指推文数量突然急剧增加的特定时刻。突发性是一种时空特征。我们可以度量一个关键词在时间上的突发性程度 一个位置,以及在具体时间上成反比的情况下,我们可以度量空间突发性[15,19]。 |
| Time | 时间特征捕捉发帖及帖子互动(例如,回复、转发)的时间模式。点赞);例如,两次连续发布之间的平均时间。 |
| 情感 | 情感特征是通过情感分析算法从帖子内容中构建的。它也是 可以使用评分、情感和满意度得分等指标。 |
下面我们总结从推特处理大数据的主要方法。我们将现有方案分为智能数据处理的两种主要方法, 即:语义增强和归纳处理,分别如表3和4所示。由于某些方法同时包含这两种元素,因此我们也介 绍融合了这两种主要方法思想的方案,这些方案也列于表4中。
信息学2018, 5, 33 4of17
| 表3.使用语义增强的智能社会分析方法。 | ||||
|---|---|---|---|---|
| 模型类型 | KFC | LOD | 参考文献 | 任务类型 |
| 社会商业 智能, 批处理, 基于OLAP | 社会事实 本体,ETLink, OLAP,分析 Tool | RDF | [3,27,28] | 情感分析。实体抽取,关键词 抽取,事件,和话题检测。 |
| OLAP+ ETL+ 分析工具 | No | [29,30] | ||
| SMA 1, 立方体建模, 批处理 | OLAP | No | [23] | 社交媒体数据的时空分析。疾病和灾难检测。研究 人口迁移。 |
| 文本立方体 批处理 | OLAP | No | [4] | 情感分析。研究人类、社会和文化行为。 |
| RDF流。 流式 处理 | R2RML映射 | RDF流 | [31] | 在Web上发布和共享RDF流。 |
| 流式链接 数据服务器+ HTML5浏览器 | RDF流 | [32] | 情感分析 本地事件监控 话题排名 | 1社交媒体分析。 |
| 表4.使用归纳处理和混合方法的智能社会分析 | ||||
|---|---|---|---|---|
| 模型类型 | KFC 1 | 链接开放 数据 2 | 参考文献 | 任务类型 |
| 社会媒体情报 3 , 批处理 | 机器学习框架 | No | [8] | 政治倾向、种族和商业 粉丝检测 |
| SMI, 流式处理 在线模式 , 批处理模式,事件 排序器 | No | [19] | 实时本地事件检测 | |
| StreamCUBE批处理 处理 基于磁盘的存储 | 时空 聚合, 话题标签聚类, 事件排序器 | No | [18] | 用于事件探索的时空话题标签聚类 事件探索 |
| (混合)RDF 流式流 处理 | 数据流管理系统 4,抽象器 数据流管理系统,演绎 和归纳 推理机 | RDF流 OWL2‐RL | [25] | 用户画像和媒体推荐 使用演绎和归纳推理。 |
1关键框架组件。 2关联开放数据。 3社交媒体智能。 4选择器数据流管理系统。
提供语义增强是指提取帖子文本和元数据中隐藏的语义信息。语义增强通过结合不同的(可能 是替代性的)技术来实现[29]:爬虫元数据、信息检索、爬虫情感分析、自然语言处理分析以及领域 专家。
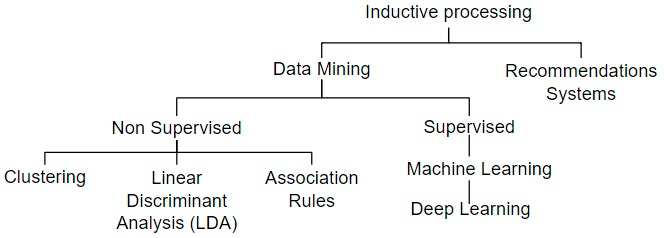
文献中基于归纳处理修订的方法采用了不同的技术,如图1所示,用于解决需要更深入学习的更 复杂任务,例如实时事件检测、用户和帖子画像、营销活动、垃圾信息发送者或机器人检测,以及推 荐系统的开发。
信息学2018,5,x5of16

我们还确定了一些重要的分析维度,用于对各项内容进行分组和区分 已审阅的工作,即:模型类型、系统是否进行流式处理、关键框架 组件(KFC),以及它们是否使用了关联开放数据(LOD)技术。最后几列 在每个表格中列出每种提出的方法所开发的具体分析任务。
尽管在表3和表4中我们指出了几种车型,但其中三种是
会
信息学2018, 5, 33 17中的 5
我们还确定了一些重要的分析维度,用于对所综述的工作进行分类和区分,即:模型类型、系统 是否进行流式处理、关键框架组件(KFC),以及是否使用关联开放数据(LOD)技术。每个表格的最后 一列列出了每种提出的方法中所开发的具体分析任务。
尽管在表3和4中我们指出了多种类型的车型,但其中有三种值得提及,因为它们真正代表了处 理大数据的技术解决方案的演进:首先是社交媒体分析(SMA),然后是朝着社交媒体智能发展的方案, 直至达到社交媒体商业智能。
与SMA相关的工作主要提出了用于捕获、监控、汇总和可视化社交指标及情感分析的工具和框架, 通常旨在解决特定的用例。需要强调的是,已有的研究工作已逐步发展出更高效的机制来组织信息: 社交数据被建模在多维方案内,将语言特征和情感指标组织成立方体数据模型,从而便于从多个角度 进行查询和可视化。这些方法通常集成多个引擎以实现对演变的数据流的OLAP,计算和聚合通过批 处理完成,因此数据分析是延迟进行的。
另一方面,社交媒体智能的目标是从上下文丰富的应用环境中获取社交媒体中的可操作信息,开 发相应的决策支持框架,并为能够利用社交对话内在知识的应用提供架构设计和解决方案框架[33]。
本研究综述的解决方案主要在批处理中使用归纳过程,因此无法实时获得洞察。最常用的分析任 务包括事件检测、用户和帖子画像以及非常简单的推荐系统。尽管企业及不同专业领域对此类研究的 兴趣日益增长,社交媒体智能的研究仍处于发展的早期阶段。
在社交商业智能领域,文献中的相关方法非常少。在这方面,我们强调[3,29],的贡献,他们提出 了通过整合社交数据来利用商业智能的框架。在研究[29],中,作者提出开发一种用于社交媒体分析的 OLAP架构,而[3]则提供了一种基于语义LOD的数据基础设施,用于以RDF格式捕获、处理、分析 和发布社交数据,使其能够被BI系统轻松消费。这两者都采用了传统方法,因为它们的架构不对数据 进行流式(实时)处理,而是将所有信息物化到存储中,因此适用于高延迟使用场景。
在所回顾的文献中,实际上进行流式处理的解决方案很少,分析任务主要面向事件检测[19]和推 荐系统[25]。值得注意的是,这两项工作都利用了语义网(SW)技术对处理的数据进行结构化增强, 从而支持在其上执行推理任务,并便于与外部资源建立链接。它们通过提出以RDF流的形式共享语义 信息,将LOD技术提升到了一个新的水平。然而,系统性的研究和经过充分评估的结果仍然缺乏。
文献[34]提出了一种用于大数据处理的扩展Lambda架构,该架构包含一个语义数据处理层,并 且与我们的方案类似,建立了利用来自不同源的元数据对原始数据进行语义增强的机制。批数据处理 与流式处理并行执行。在速度层,事件经过验证后被路由至实时处理或批处理。与先前的解决方案相 比,我们的架构允许两个并行阶段之间相互反向优化(见第3节),以提升各自的过程性能。此外,我 们增加了一个由数据科学家实现的智能数据处理算法的集成层。我们对流类型和流工作流进行建模, 以促进数据处理和面向社交商业智能的分析。另外,查询只需在一个单一服务位置进行搜索,而无需 分别在批处理视图和实时视图中查找。
社交媒体数据是数量快速增长的动态流,因此有必要为其处理创建高效机制。目前大多数方案都 集中在解决封闭情境下问题的社交媒体分析,而未能解决动态性问题。
信息学2018,5,33 6of17
社交数据的多样性与速度。从这个意义上说,仍然有必要建立机制,以动态地发现和添加新的分析维 度以及新型事实。有必要创建根据上下文对数据进行分类的机制。有必要解决语义一致性检查、冲突 检测、结构缺失以及在相同基础设施中集成不同类型数据和组件的困难等问题。
为了解决上述问题情况,本文提出了一种统一的通用架构,以促进易于与BI系统集成的智能社交 分析系统的部署。在此意义上,利用语义网技术将数据流建模为多维模型,有助于系统间结构与数据 的集成。
遵循[35],的指导方针,我们现在将列出提出的架构必须满足的需求:
- 保持数据流动。为了支持实时流处理,消息必须以流方式处理。由于社交数据的延迟较低,系统必 须能够动态处理数据,并避免高成本的存储操作。
- 支持即席流查询以过滤出感兴趣事件并执行实时分析。支持高级查询语言以获得连续结果,并设置原 语和运算符来管理常见流属性(如数据窗口大小和计算频率)。一些流式语言包括StreamSQL和 C‐SPARQL。
- 建立处理流缺陷的机制。在实际应用中,流数据可能乱序到达,存在延迟,出现信息缺失或以错误 格式到达。系统必须能够识别错误类型,并为每种情况提供自动解决方案。
- 它必须是健壮且容错的。第一个特性涉及处理执行错误和错误输入的可能性,从而确保输出符合预期 结果。此外,必须保证数据的可用性与安全性,以便在任何模块发生故障时,系统能够继续运行(为 此,最好在后台保留进程,并经常与主进程同步状态)。
- 支持静态数据与流数据的集成。流式架构必须支持来自两种基本状态的数据集成:用于存储和批处 理历史信息的长期阶段,以及用于生成流数据的短期阶段。在许多场景中,需要将当前状态与过去状 态进行比较,以从数据中获得更深入的洞察(例如,用于机器学习任务)。因此,有必要高效管理先 前状态的存储与访问。另一方面,并非总是需要永久存储历史数据,建议设置一个时间窗口以保留最 近的关注时间段,以便在发生流程故障时能够从最新的历史数据重新计算所有数据,从而实现容错支 持。
- 该系统必须可自动分区与扩展。也就是说,它必须能够自动地平衡进程过载,在线程中透明地分配 进程,而无需用户干预。
- 高速处理和响应。必须支持对大数据量的极低延迟流式数据进行高性能处理。
最后,我们引入了与链接开放数据技术的集成,以对数据的输入和输出进行语义增强。语义网技术能 够实现外部资源的链接与探索,用于相关数据的发现与获取(例如,发现新的分析维度)。另一方面, 将流数据按照链接开放数据的标准进行发布也很有必要,以便外部应用能够轻松理解。
3.提出的架构
在本节中,我们将根据前几节讨论的任务和需求,描述用于社交商业智能分析处理的提出的架构。
信息学2018, 5, 33 7(共17页)
首先,我们在架构中包含两类参与者,即:数据科学家和数据分析师。前者负责在数据流上定义 智能数据处理任务,而后者则负责在生成的度量流上定义分析任务,以追踪组织目标和指标。在此场 景下,数据分析师会向数据科学家提出请求,以从数据中推断出新的视角(例如,分类器),而数据 科学家则可以要求获取新的数据流来支持其分析过程。数据科学家的角色是定义、开发、实现和测试 归纳处理算法。如后文所示,分析数据流将由数据分析师定义,因为它们由分析事实组成。
另一方面,支持将流数据以某种标准形式发布也是很有用的 以便链接开放数据能够被外部应用轻松理解。
3.建议的架构架构
在本节中,我们描述了用于社交商业智能分析处理的提出的架构 根据前几节讨论的任务和需求,我们首先在架构中包含两类参与者,即:数据科学家和数据分析师。
前者负责在数据流上定义智能数据处理任务,而后者则负责在生成的度量流上定义分析任务,以追踪 组织目标和指标。在此场景中,数据分析师向数据科学家提出请求,以从数据中推断出新的视角(例 如分类器),而数据科学家可以要求获取新的数据流来支持其分析过程。数据科学家的角色是定义、 开发、实现和测试归纳处理算法。如后续所示,数据分析师将定义分析数据流,因为这些流由分析事 实组成。

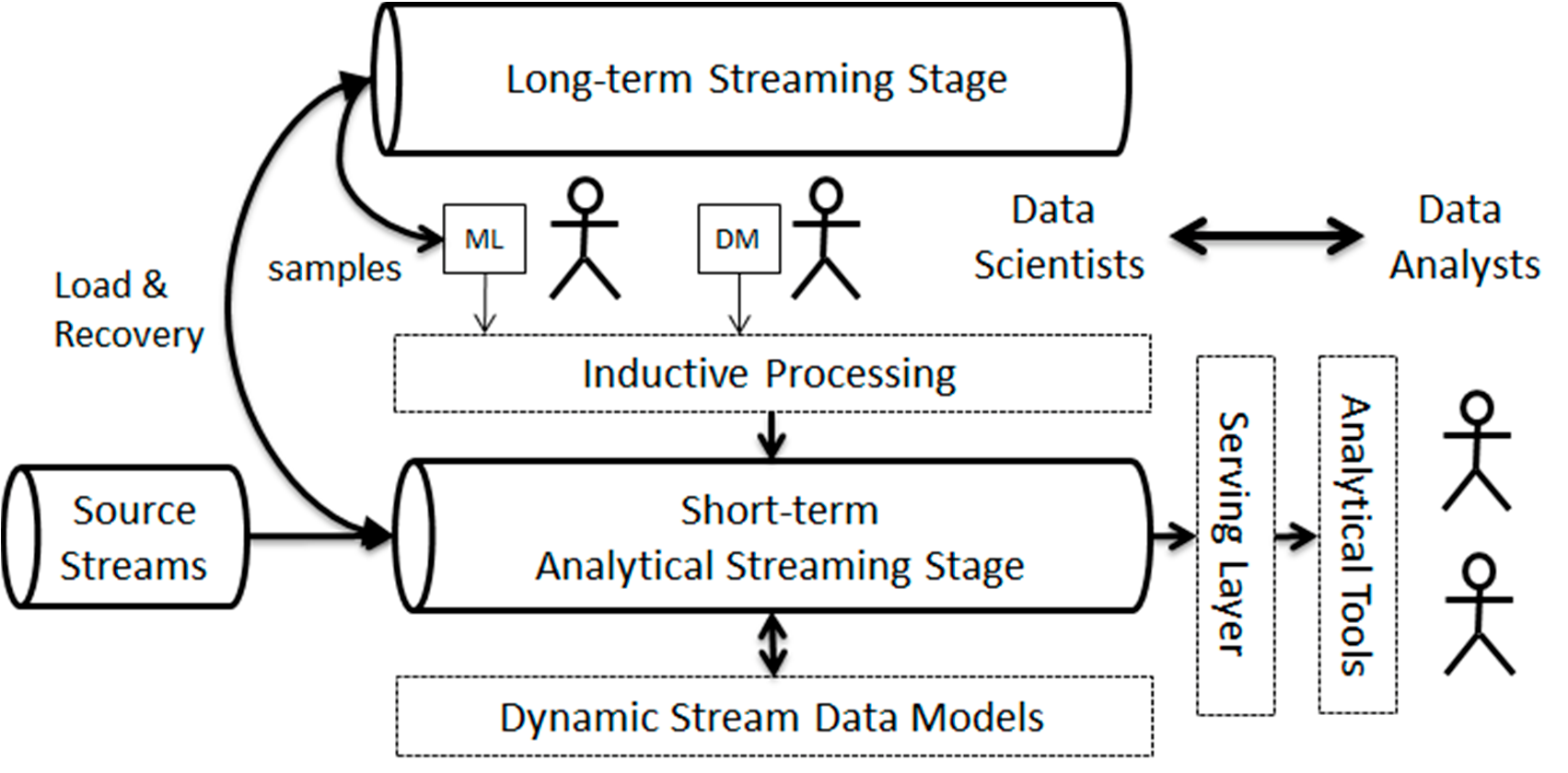
如图2所示,提出的架构允许在需要应用新逻辑时对历史数据进行分析的再处理。该架构大致对 应于Kappa流式架构[2,36], ,这是Lambda架构[37]的一种演进,旨在避免为批处理和实时流分别实 现两次功能。我们的架构基本上由两个流式阶段组成:一个长期阶段,用于将近期的历史信息作为持 续时间较长的数据流保存;另一个短期阶段,包含一些工作流,用于实时生成所需的分析数据。在我 们的场景中,数据科学家从长期阶段获取训练数据样本用于其算法,并在短期阶段的数据上进行测试。
数据分析师通常通过服务层消费来自短期阶段的数据。长期阶段还用于在流工作流需要重新配置或更 新时恢复数据。在这种情况下,当短期阶段停止生成数据并重新启动时,需要重新计算存储在长期阶 段的所有收入数据。
在我们的 proposal,源数据流是语义的 y通过丰富 g一系列词汇表 为分析任务生成有用的数据。同样,所有生成和消耗的数据流都是事实性和语义性的,因为它们由与 多维分析模型元素相关联的事实和维度数据组成。这使得整个系统能够维护流数据模型。

在我们的方案中,源数据流通过一系列词汇表进行语义增强,以生成适用于分析任务的有用数据。
类似地,所有生成和消费的数据流都具有事实性和语义性,因为它们由与多维分析模型元素相关联的 事实和维度数据组成。这使得整个系统能够根据输入数据和分析模型保持流数据模型的更新。任何两 者之间的差异都将触发相应工作流的更新和重新配置。
在Lambda架构中,批处理层是一个存储原始数据的仓库,这些数据在到达后将按一定时间间隔 由批处理过程进行处理,并且这些过程是长周期的。所存储的数据将通过迭代算法进行处理,并根据 分析需求进行转换[34]。而速度层用于计算实时视图,以补充服务层中的批处理视图。批处理层主要 用于生成没有严格延迟约束的结果,并纠正速度层中产生的错误。在需要时,采用Kappa架构,
信息学2018, 5, 33 17中的8
批处理层还为实时层提供数据,因此实时和批处理均由同一个实时数据处理模块执行。
相比之下,在提出的架构中,数据始终作为连续流进行处理。与Kappa架构类似,其思想是在单 一的流处理引擎中同时处理实时数据处理和重新处理。与Lambda和Kappa架构不同的是,长期阶段 是一个可用于两个目的的临时数据缓冲区:第一,作为机器学习算法的连续输入,其输出在短期阶段 的预处理和后处理过程中被使用;第二,它也可用于系统故障或流工作流重新配置时的数据恢复。短 期阶段对应于与Lambda和Kappa架构相同的速度层。
提出的架构为每种参与者提供了许多优势。首先,它明确建立了与系统及参与者之间信息交换的 流程和渠道。其次,由于预处理和后处理过程(见第3.1节),它大大加快了通信和信息交换速度,减 少了数据准备和数据收集的时间。第三,它便利了参与者的工作,使其能够按需获得符合其需求的结 果。许多数据准备和集成过程通常需要手动执行,而我们的架构可以实现这些过程的自动或半自动执 行。
在下一节中,我们将讨论如何对这些架构的元素进行建模,以构建满足社交商业智能任务的复杂 工作流。
3.1.流建模
在架构中,我们基本上区分两类数据流:源流和事实流。源流又分为数据流和链接数据流。数据 流直接连接到流入的社交数据源(例如,帖子、用户更新等),而链接数据流则利用语义上的流入数 据丰富化来适当地为分析准备数据。事实流位于短期阶段,主要目的是生成可直接使用的分析数据。
换句话说,事实流通过处理和聚合源数据,为数据分析师提供有价值的洞察。
事实流由源数据流提供支持。为此,它们需要将输入数据转换为多维事实。我们将这些转换称为 ETLink过程。ETLink这一名称源于传统的提取/转换/加载阶段,但与加载转换后的数据不同, ETLink会动态地生成关联数据图[3]。该过程需要领域本体和受控词汇表来对数据进行标注、标准化 和链接。由于这些语义源也可能随时间演化,因此我们需要第三种类型的流:链接数据流。
链接数据流直接连接到关联开放数据(LOD)端点,通过SPARQL查询[38]进行访问。尽管许多 LOD源是静态的,但目前存在向动态LOD(例如实时DBPedia[39]或实时BabelNet[40])发展的显 著趋势,从而确保提供新鲜的语义数据。如果一个LOD源在短期阶段为某个事实流提供数据,则必须 将其转换为多维模型。我们将此过程称为MD‐star过程。在文献中可以找到多种旨在将链接数据融入 多维模型的方法[28,41],,这些方法均可用于实现MD‐star过程。
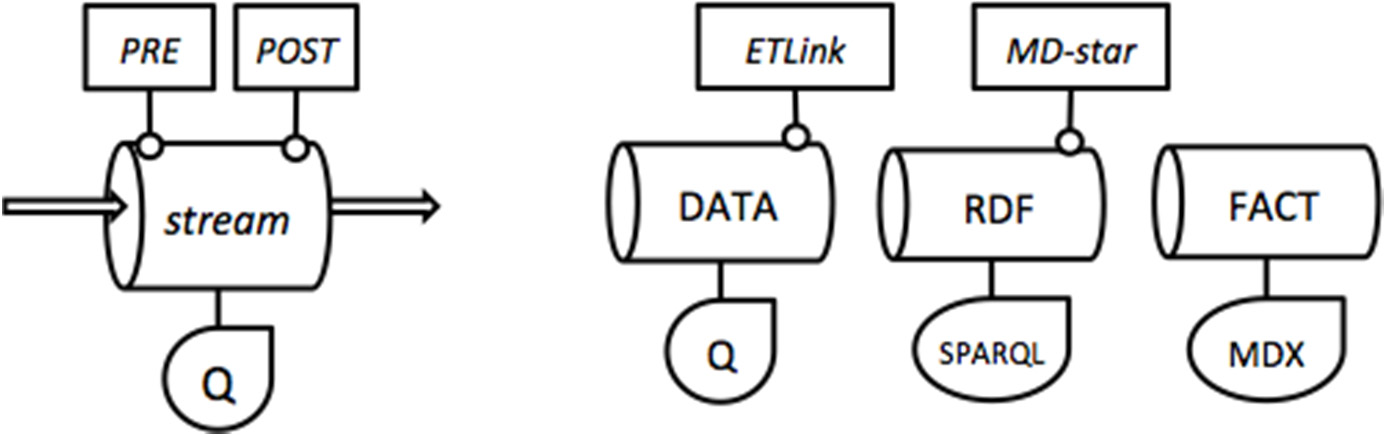
在图3中,我们展示了所提出的架构中前述流类型的图形表示。我们使用三个主要组件对每个流 进行建模:一个查询Q和两个可选过程(PRE和POST)。输入数据可以通过预处理操作进行预处理, 然后在得到的数据上执行查询Q,最后可以应用后处理操作以生成输出数据。先前定义的ETLink和 MD‐star过程是两种类型的后处理操作。
信息学2018,5,33 17中的第9个
信息学2018, 5, x 16中的9
在重新执行的结果数据,最终可以应用后处理操作来生成 输出 数据。先前定义的ETLink和MD‐星过程是两种后处理操作。
In the情况o f factst reams, PRE and POST operations can only增加 new measures and dimension 在执行分析查询(MDX)之前(PRE)或之后(POST)的属性。PRE过程的一个示例是计算推文属 于该领域的推文概率。POST过程则基于聚合数据进行推理和计算,例如,在聚合相关帖子的指标后 确定用户画像。如图4所示,某些过程可以通过其他流获取其算法所需的新鲜数据。这包括k均值、 LDA等持续学习算法以及神经网络等一些机器学习方法。
此外,任何流 m以其时间行为为特征 行为。基本上,每条流 定义了一个时间窗口和一个滑动间隔。时间窗口指明数据在流中需要保留的时长,而滑动间隔则表示 输出的周期性或频率。例如,一个时间为一周、滑动间隔为一天的时间窗口意味着该流保留过去七天 的收入数据,并每天生成一次输出。这两个参数取决于当前的分析任务,可以从MDX查询的规范中 推导得出。必须指出,在此场景下,MDX查询必须通过使用“现在”等相对标签针对时间维度进行 调整。这一问题同样存在于任何连续查询语言中,例如C‐SQL和C‐SPARQL[42]。采用此方法进行流 工作流建模具有多个优势:可以在执行前检查组件之间的一致性,且所得到的模型可以动态地
在处理数据时进行更新。例如,当源流中出现新维度属性/成员或新度量时,就需要进行模型更新。
3.2.多维一致性
检查多维度 一致性基本上意味着为每个推断出两个数据模式
流:输入数据模式(IS)和输出数据模式(OS)。注意,流转换过程包含三个步骤:(IS)PRE→Q→
POST→(OS)。从流定义中可以推断出IS是如何被转换为OS的,从而分析整个工作流的处理过程。

对于事实流,PRE和POST操作只能在分析查询(MDX)执行之前(PRE)或之后(POST)添加新的度量和维度属性。PRE‐处理的一个示例是计算推文属于某一领域的推文概率。后处理操作则基于聚合数据进行推断和计算,例如,在聚合相关帖子的指标后确定用户画像。如图4所示,某些过程可由其他流提供数据,以获取其算法所需的新鲜数据。持续学习算法(如k均值、LDA)以及某些机器学习方法(如神经网络)即属于此类情况。
信息学2018, 5, x 16中的9
在得到的数据上执行,最终可以应用后处理操作以生成输出 数据。先前定义的ETLink和MD‐星过程是两种后处理操作。
For fact streams, PREandPOSToperations can only add new measures and dimension attributes before (PRE) or after (POST) executing the analytical query (MDX). A PREprocess example is calculating the probability of a tweet belonging to a specific domain. The POSToperation infers and calculates based on aggregated data, for example, determining a user profile after aggregating metrics from related posts. As shown in Figure 4, certain processes can be fed by other streams to obtain fresh data required by their algorithms. Continuous learning algorithms (such ask-means, LDA) and some machine learning methods (such as neural networks) fall into this category.
Additionally, any stream is defined by its temporal behavior. Basically, each stream defines a time window and a sliding interval. The time window indicates how long data needs to be retained in the stream, while the sliding interval represents the periodicity or frequency of output. For example, a time window of one week with a sliding interval of one day means the stream retains incoming data from the past seven days and generates output once per day. These two parameters depend on the current analysis task and can be derived from the specification of the MDX query. It must be noted that in this scenario, the MDX query must be adjusted for the time dimension using relative labels such as “now”. This is the same issue faced by any continuous query language, such as C-SQL and C-SPARQL[42]. Modeling stream workflows in this way has several advantages. Consistency between components can be checked before execution, and the generated model can be dynamically updated as data is processed. For example, when new dimension attributes/members or new measures appear in the source stream, a model update is required.
3.2.多维一致性
检查多维一致性基本上意味着为每个流推断出两个数据模式:输入数据模式(IS)和输出数据模式(OS)。请注意,流转换过程包括三个步骤:(IS)PRE→Q→POST→(OS)。通过流定义可以推断出IS是如何被转换为OS的,从而分析整个工作流的处理过程。
图4.流的建模工作流。
此外,任何流都由其时态行为所定义。基本上,每个流都定义了一个时间窗口和一个滑动间隔。
时间窗口指明了数据在流中需要保留的时长,而滑动间隔则表示输出的周期性或频率。例如,一个时 间为一周、滑动间隔为一天的流,意味着该流保留过去七天的收入数据,并每天生成一次输出。这两 个参数取决于当前的分析任务,可从MDX查询的规范中推导得出。必须指出,在此场景下,MDX查 询必须通过使用诸如now之类的相对标签对时间维度进行调整。这与C‐SQL和C‐SPARQL等任何连续 查询语言所面临的问题相同[42]。
采用这种方法进行流工作流建模具有多个优势。在执行之前可以检查组件之间的一致性,且随着数据的处理,生成的模型可动态更新。例如,当源流中出现新的维度属性/成员或新度量时,就需要进行模型更新。
3.2.多维一致性
检查多维一致性基本上意味着为每个流推断出两个数据模式:输入数据模式(IS)和输出数据模
式(OS)。请注意,流转换过程包含三个步骤:(IS)PRE→Q→POST→(OS)。从流定义中可以推断 出IS是如何被转换为OS的,从而分析整个工作流的处理过程。
信息学2018, 5, 33 10/17
流的输入结构(IS)将取决于其所消耗的数据流。更具体地说,流的输入结构(IS)是其所消耗 流的输出结构(OS)的适当组合。对于事实流而言,根据多维范式,流的组合可以有多种解释:
- 组合流的输入结构表示将流A的输出结构中的属性注入到流B的输出结构的某些维度中。
- 组合流的输入结构表示具有互补维度和度量的两个事实流的输出结构的连接。
- 组合流的输入结构表示具有相同多维结构(即等效数据模式)的互补事实的并集。
该系统将仅接受根据先前解释具有数据流一致组合的工作流(见图4)。
3.3.时间一致性
在设计工作流时,必须检查组合数据流中的时间一致性。时间一致性与流的速度相关。例如,向 另一个事实流注入维度成员/属性的流必须比后者更慢,否则其聚合能力会降低。在事实流上执行连接 和联合操作也会影响时间一致性:连接流的速度不能快于输入流的速度。此外,为了合理起见,时间 窗口必须始终大于或等于时间滑块。最后,由于工作流旨在获取汇总事实,因此应在逐渐更粗的粒度 上执行聚合。
值得一提的是,所有这些限制的形式化表示超出了本文的范围。对所提出的车型建立可操作表示 的自然方法是使用OWL语言[43],,因为流中的大多数数据都表示为RDF图。
4.一个示例用例
在本节中,我们提出一个真实场景用例,以展示上述架构如何帮助我们表达复杂流式分析问题的 工作流。我们希望建模的问题是:通过考虑当前的汽车品牌和车型,从汽车行业相关参与者撰写的推 文中获取有价值的洞察。所选的应用场景与业务依赖于汽车工业的企业有关。具体而言,像租车公司 这类企业需要持续监控用户偏好和诉求,以便及时更新其提供的车队。通过所提出的解决方案,业务 分析师可以定义用户画像和特定指标,并在流式基础设施中快速部署和监控,从而显著减少在提取和 处理社交数据上花费的时间,直接使用设计的工作流所产生的事实。图5展示了针对该问题所提出的 工作流,下文将对其进行描述。
信息学2018,5,33 17中的11
持续监控用户偏好和诉求,以更新他们应更换的车队 提供。通过所提出的解决方案,业务分析师可以提出用户画像和特定指标, 可以在流式基础设施中快速部署和监控。因此,分析师可以 大幅减少提取和整理社交数据的时间,直接使用事实
由…产生设计的工作流。图5展示了该问题的建议工作流 m,其中 依次进行描述。
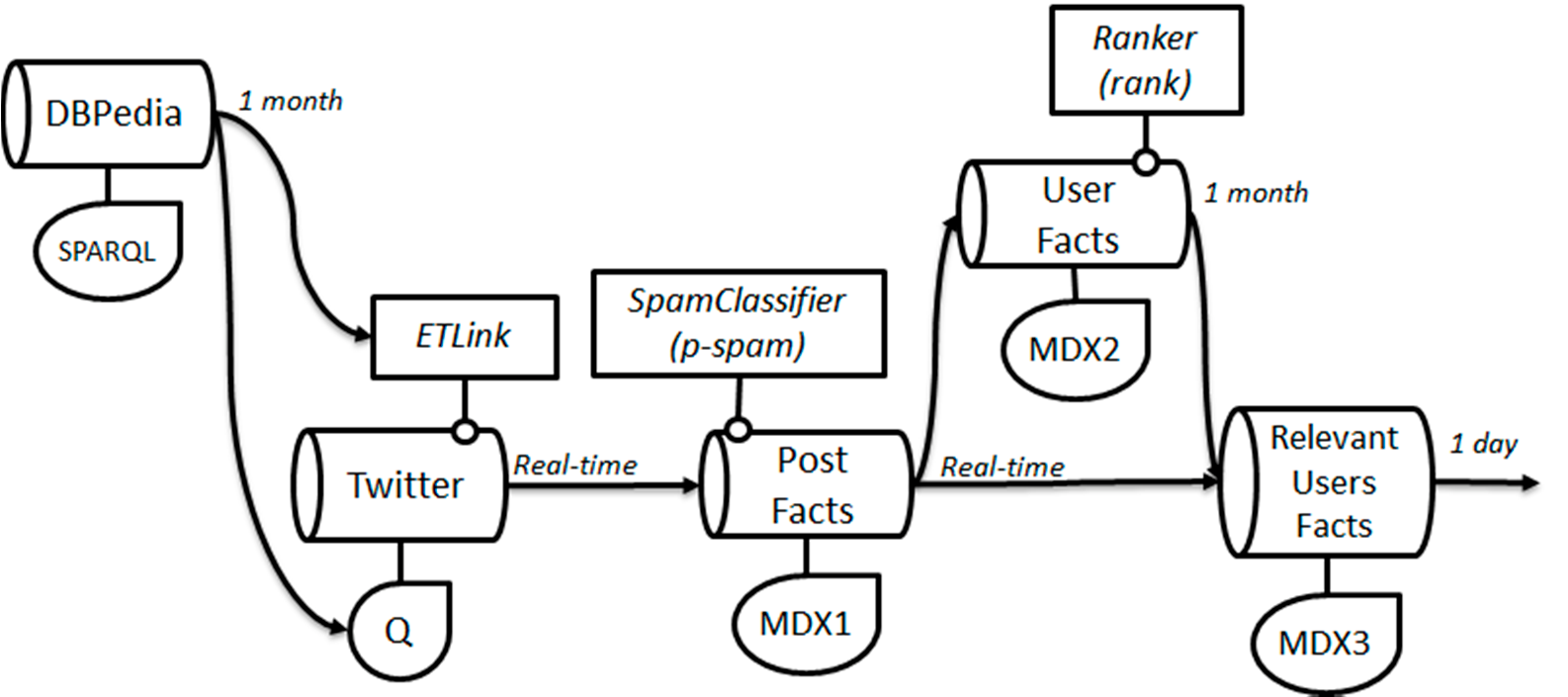
首先,我们定义一个用于识别新汽车品牌和车型的流,该流通过其SPARQL端点使用LiveDBPedia。
该查询以一个月前的日期(参数$one_month_ago$)作为参考进行参数化,该参数在向端点获取查询时 设置:
select?car,?date,?brand where{ ?car dbo:manufacturer?brand.
?car dbo:productionStartYear?date.
FILTER(?date>$one_month_ago$ˆˆxsd:dateTime) }
该流同时提供给ETLink过程和Twitter查询跟踪,前者用于对推文数据进行语义增强,后者包含 需要在推特上关注的汽车品牌和车型名称。每当DBPedia中出现新的汽车型号时,ETLink和 Twitter查询都会相应地更新。在此示例中,ETLink主要由一个字典组成,用于将文本片段映射到参 考本体中的实体[3]。一个有趣的度量指标可以衡量DBPedia更新与推文中提及汽车型号之间的时间延 迟。
一旦应用ETLink过程生成事实,就会对这些事实进行处理,以增量方式获得所需的分析数据。
第一个事实流包含一个预处理过程,用于自动为每个事实分配成为垃圾信息的概率。该过程主要由一 个使用近期历史数据预先训练的分类器组成。它会为每个事实添加一个新的度量,以反映其作为垃圾 信息的概率。随后,MDX1查询选择垃圾信息概率较低的事实。这些筛选后的事实被输入到两个具有 不同处理速度的流中。在图5中,我们展示了每个流输出端的流处理速度。在此示例中,时间窗口与 时间滑块一致。
用户事实流在月粒度上汇总一组关于用户的指标(例如,关注者、在领域内发布的推文、总发布 推文数等),以获得用户的排名。此过程体现在排序器后处理中,根据用户聚合的指标计算其相关性。
最后,另一个事实流将输入的帖子事实与用户事实流连接,以选择相关用户的非垃圾信息事实(该连 接将在MDX3查询中表示)。这是对帖子事实某一维度进行属性注入的示例。
生成的流工作流会在天级别生成汇总数据,这些数据存储在架构的服务层中,供适当的分析工具 进行消费和可视化。
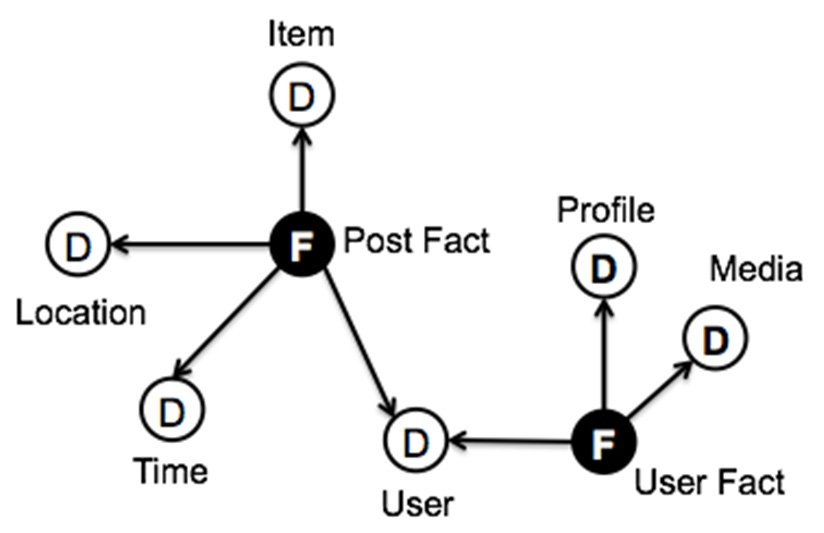
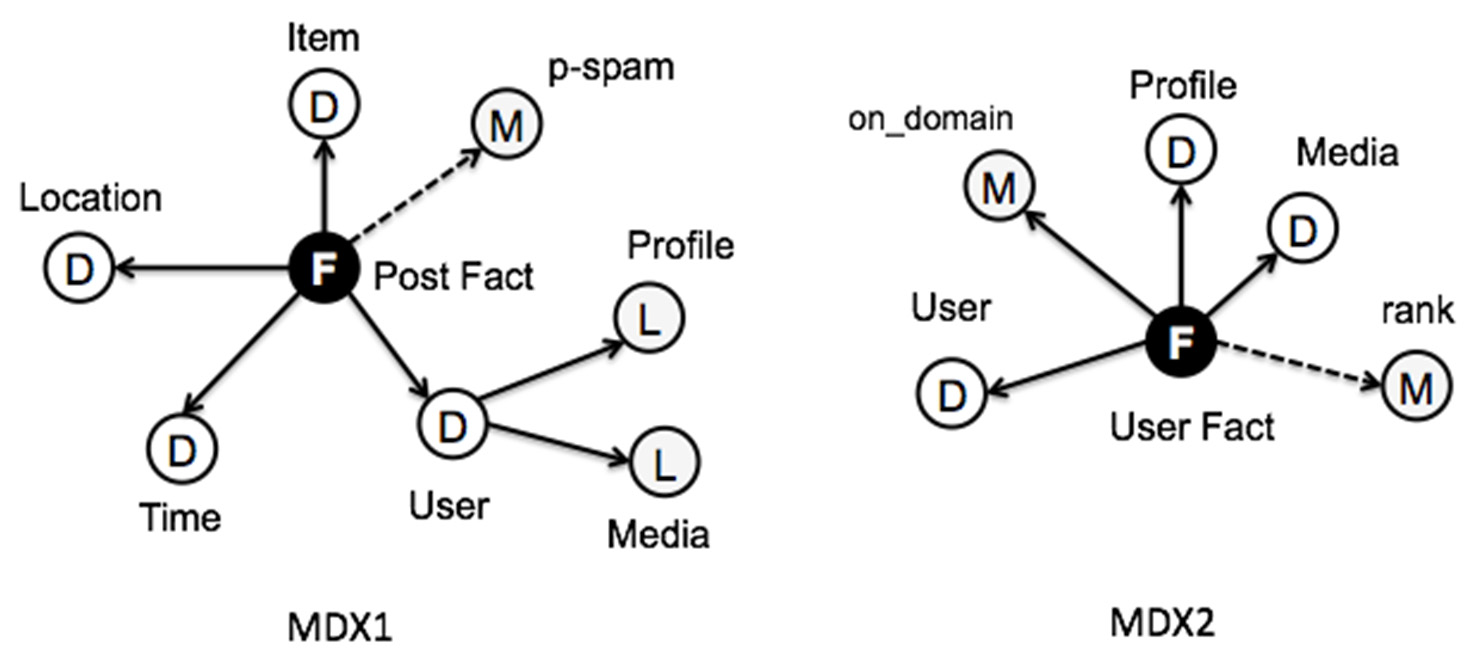
图6展示了应用ETLink后Twitter数据流的输出模式。我们可以看到由两种事实类型组成的星系模式, 它们可通过用户维度进行连接。多维查询MDX1输出了如图7所示的模式,其中用户事实的维度变为属性
信息学2018, 5, 33 17中的12
用户维度的帖子事实。这些事实在用户事实流中再次转换,其中多维查询MDX2将事实按如下方式构 造:在时间窗口内与每个用户相关联的发布事实数量被汇总为用户事实的一个度量(在_领域上)。
图7还通过虚线显示了前后处理生成的派生度量和属性。最终输出的多维模式(推送至服务层)如图 8所示。

5.原型实现
我们使用Python实现了一个小型原型,以展示采用此方法进行的一些分析。利用现有的推特库, 源流的实现相当直接。我们还采用了SLOD‐BI的库来实现ETLink过程,以生成如图5所示的推文事 实。值得一提的是,ETLink过程非常高效,因为它们依赖于自动语义标注方法,这些方法可将文本 片段和 数据到本体实体。此外,ETLink过程可以轻松地并行化,以便它们能够 适应流入帖子流的速度。
在当前原型中,每个流都实现为一个网络服务,其数据由 消费者流。这些网络服务为每个消费者流维护一个游标。在所有数据之后
图7.应用MDX1和MDX2后的输出模式。
信息学2018, 5, x 12of16
5.
Python 非常简单 SLOD‐BI ETLink 5 ETLink效率非常高,因为它们依赖于自动语义标注方法,这些方法可将文 本片段和 ETLink
条
5.原型实现
我们使用Python实现了一个小型原型,以展示采用此方法进行的一些分析。利用现有的推特库, 源流的实现非常直接。我们还采用了SLOD‐BI的库来实现ETLink过程,以生成如图5所示的推文事实。
值得一提的是,ETLink过程是
信息学2018, 5, 33 17中的1 3
非常高效,因为它们依赖于自动语义标注方法,可将文本片段和数据映射到本体实体。此外, ETLink过程可以轻松并行化,从而能够适应流入帖子流的速度。
在当前原型中,每个流都实现为一个网络服务,其数据由消费者流拉取。这些网络服务为每个消 费者流维护一个游标。当前时间窗口中的所有数据被提供给消费者流后,游标将关闭;一旦新时间窗 口的数据计算完成,游标将重新打开以进行进一步处理。这些流服务处理JSON数据,事实流以 JSON‐LD格式提供和消费数据[44]。通过这种方式,在未来的实现中,可以使用NoSQL数据库来支 持大型流缓冲区。我们还计划在一个完全可扩展的大数据框架(如Kafka和Spark)内自动执行这些 工作流。
关于垃圾信息分类器,它使用Anaconda框架(Pandas和ScikitLearn包)进行训练和测试[45],, 该框架同样基于Python实现,因此分类器可以轻松集成到流服务中。根据提出的架构,我们维护一 个为期一年的长期阶段存储,从中获取用于训练垃圾信息分类器所需的样本,采用线性SVM进行训练。
在应用垃圾信息分类器后,事实的数量减少了约40%。
图5中所示的排序器过程已通过一个简单公式实现,该公式在用户事实聚合后应用。该度量对应 于按领域和每个用户的推文总数进行排序。_领域的用户事实以及每个用户的推文总数。
我们使用在2015年期间跟踪的关于汽车型号的历史推文序列模拟了流式工作流。图9展示了该年 度用户事实流生成的结果(仅考虑前15名)。可以看出,用户排名在每个月都不同,因此有必要维护 一个相关用户的稳定列表,以便利用帖子事实进行有意义的分析。如果无法获得稳定的用户列表,则 “用户”不是有效的分析维度。
信息学2018,5,x16中的13
我们使用一系列在2015年期间跟踪的关于汽车型号的历史推文模拟了流式工作流程。图9显示了 当年用户事实流生成的结果(仅考虑前15名)。可以看出,用户排名在每个月都不同,因此有必要维 护一个相对稳定的相关用户列表,以便利用帖子事实进行有意义的分析。如果无法获得稳定的用户列 表,则“用户”不是有效的分析维度。

图10显示了初始ETLink过程在周级别上聚合生成的每个品牌的领域内推文数量。从图中可以清楚地 识别出两个主要品牌主导了该领域内的已发布推文(即丰田,日本爱知县,和福特,密歇根州迪尔伯恩)。
, 美国)。必须指出的是,原始的帖子事实与汽车型号的名称相关联,这些型号按品牌分组以进行可视化。
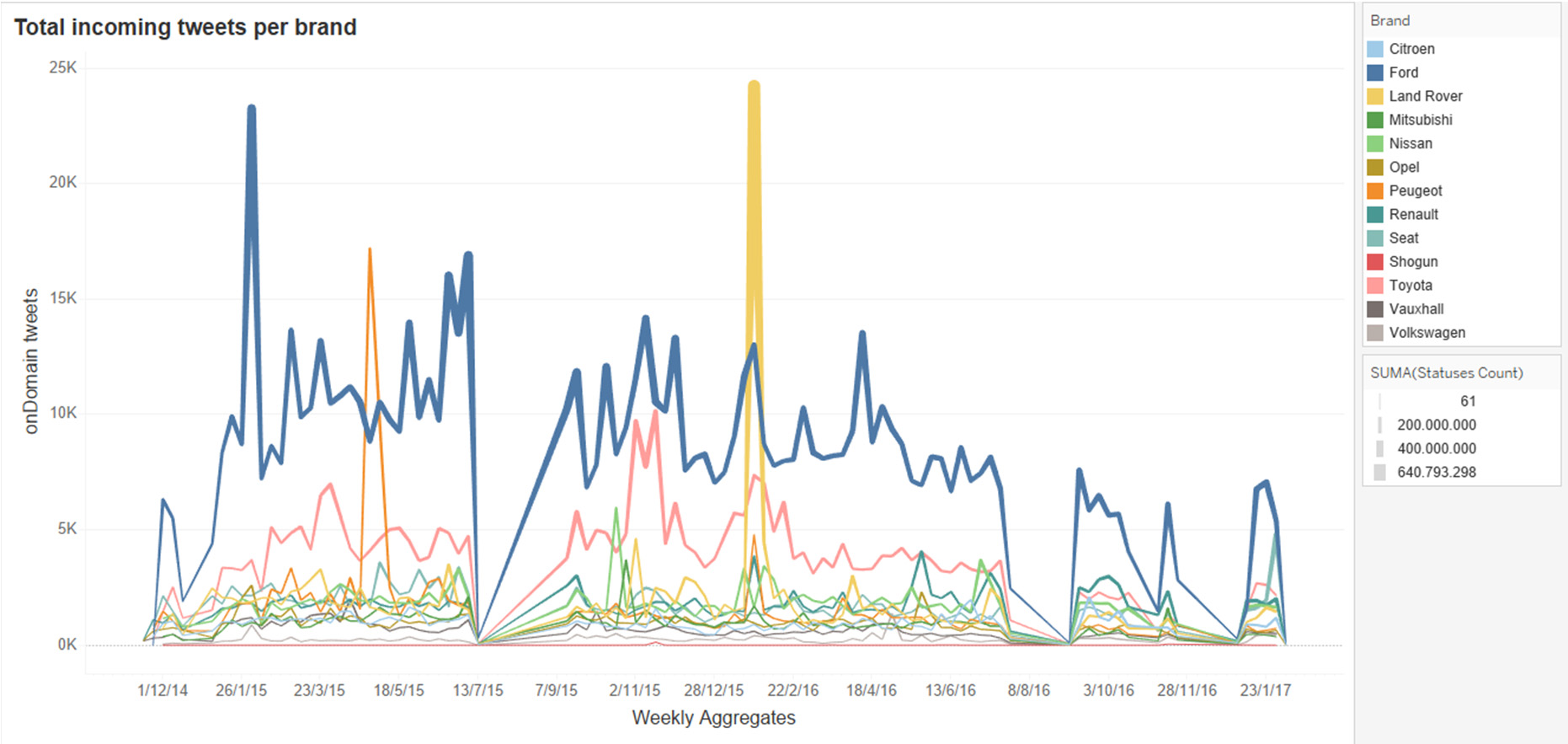
图11显示了在选择图9中所示的前15个相关用户后的最终输出,以及
在移除垃圾发布事实后。从该图可以看出,主要的相关用户关注的品牌与图10中的流入事实流中的品牌不同。例如,丰田品牌投入了大量资源
信息学2018,5,33 14of17
图10显示了初始ETLink为每个品牌生成的领域内推文数量 在周级别进行聚合处理。在图中我们可以清楚地识别出两个主要品牌 在该领域(即丰田、日本爱知县和福特、美国密歇根州迪尔伯恩)。需要说 明的是,原始帖子事实与汽车型号的名称相关联,为了可视化目的,这些型号按品牌进行了分组。
图11显示了在选择图9中所示的前15个相关用户并删除垃圾发布事实后的最终输出。从该图可以看出,主要相关用户关注的品牌 与图10中的流入事实流中的品牌有所不同。例如,丰田品牌在上半年受到极大关注,而其他品牌则在下半年与其展开竞争。
信息学2018,5,16页中的第14页,在上半年受到关注,而其他品牌在下半年与之竞争。
6.结论
在此本文中,我们分析了一套与社会商业相关的方法 智能(SBI)。我们得出结论:流式处理是处理社交数据的自然方式,它为分析任务带来了新的挑战。
主要挑战在于分析中涉及的所有元素的动态性,从数据源到分析指标都具有动态变化的特点。另一个 挑战是在大多数与社会商业智能相关的分析任务中需要进行智能处理,例如情感分析、垃圾信息检测 等。事实上,我们无法设想一个不包含多维分析和预测分析这两类分析的社会商业智能任务。我们提 出了一种新架构,旨在满足所有这些需求,并在同一工作区域内集成数据科学和数据分析任务。我们 采用类似Kappa的
流式架构以满足两类参与者的需要。该架构依赖于 关联数据和多维建模。前者便于语义数据增强 而后者则为了分析目的对它们进行塑造。采用语义也有助于 验证和已开发工作流的跟进。
未来工作有两个主要方向。一是实现架构的完整实施 在Python中及其与Kafka等高度可扩展流式框架的集成。另一个 方向是获得一个基于描述的流工作流的完整理论模型

6.结论
在本研究中,我们分析了一整套与社会商业智能(SBI)相关的方法。我们得出结论:流式处理 是处理社交数据的自然方式,这为分析任务带来了新的挑战。主要挑战在于分析所涉及的所有元素的 动态性,从数据源到分析指标均如此。另一个挑战是在大多数与SBI相关的分析任务中需要进行智能 处理,例如情感分析、垃圾信息检测等。事实上,我们无法设想一个不包含多维分析和预测分析这两 类分析的社会商业智能(SBI)任务。
信息学2018, 5, 33 15of17
我们提出了一种新架构,旨在满足所有这些需求,并在同一工作区域内集成数据科学和数据分析 任务。我们采用类Kappa流式架构来满足这两类参与者的需求。该架构基于关联数据和多维建模,前 者便于语义数据增强,后者则使其适用于分析目的。语义的引入也有助于所开发工作流的验证与跟踪。
未来工作有两个主要方向。一是使用Python实现该架构的完整开发,并将其集成到Kafka等高 度可扩展流式框架中。另一个方向是基于描述逻辑建立流工作流的完整理论模型。该模型的目标是保 持工作流最新且一致的逻辑表示,可用于验证流重用和组合,以及工作流的自动执行。
作者贡献:概念化,R.B.、I.L.‐C.和M.J.A.;方法论,R.B.、I.L.‐C.和M.J.A.;软件,R.B.;验证,R.B.和 I.L.‐C.;形式化分析,R.B.、I.L.‐C.和M.J.A.;调查,R.B.、I.L.‐C.和M.J.A.;资源,R.B.和I.L.‐C.;数据管 理,R.B.和I.L.‐C.;撰写‐初稿准备,I.L.‐C.撰写引言和第2节,R.B.撰写第3–5节及结论;撰写‐审阅与编辑, R.B.、I.L.‐C.和M.J.A.;可视化,R.B.和I.L.‐C.;监督,R.B.;项目管理,R.B.;资金获取,项目 TIN2017‐88805‐R的成员为R.B.、I.L.‐C.和M.J.A.,I.L.‐C.是获得“PREDOC/2017/28”资助的预博士生。
资助:本研究由西班牙工业和商业部资助,项目编号为TIN2017‐88805‐R,并由瓦伦西亚海梅一世大学的 PREDOC/2017/28号博士前奖学金资助。
利益冲突:作者声明不存在利益冲突。

















 1689
1689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









