






 本文探讨了多种减小模型大小和提升预测速度的方法,包括数字精度降低(如float32到float16)、LadderSide-Tuning(在大模型上构建轻量级旁支)、P-tuning裁剪、Adapter技术、模型蒸馏(如Response-Based、Feature-Based、Relation-Based知识转移)、动态预测加速(如DeeBERT和Early Exit策略)、矩阵分解、操作融合和模块替换。这些策略旨在应对日益庞大的模型,提高计算效率和运行速度。
本文探讨了多种减小模型大小和提升预测速度的方法,包括数字精度降低(如float32到float16)、LadderSide-Tuning(在大模型上构建轻量级旁支)、P-tuning裁剪、Adapter技术、模型蒸馏(如Response-Based、Feature-Based、Relation-Based知识转移)、动态预测加速(如DeeBERT和Early Exit策略)、矩阵分解、操作融合和模块替换。这些策略旨在应对日益庞大的模型,提高计算效率和运行速度。
主要讲讲有哪些方法可以减少模型大小,提升预测推理速度。尤其是现在的模型越来越大。
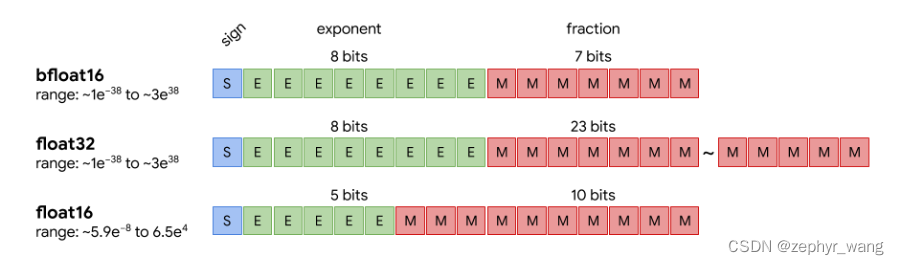
1.数字精度降低
主要是float32变成float16,这样内存使用变小,增加处理的数据量,提高了运行效率和速度。
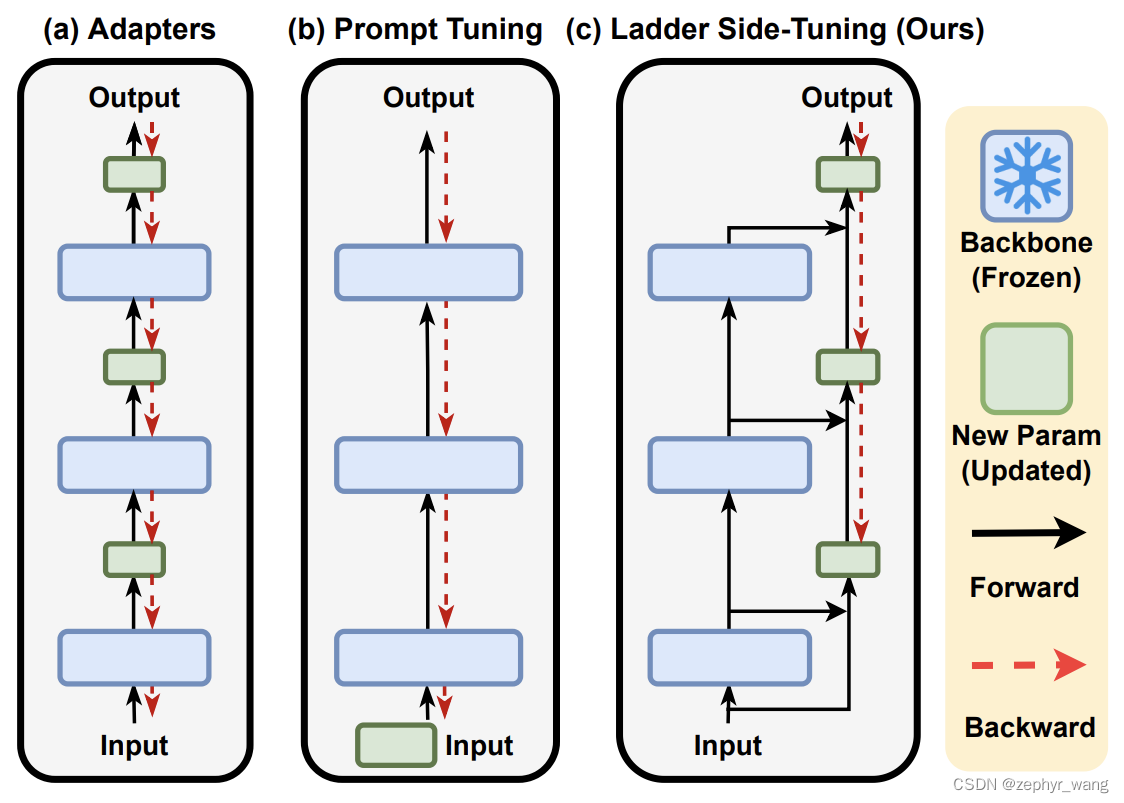
2.Ladder Side-Tuning(LST)
LST,它是在原有大模型的基础上搭建了一个“旁支”(梯子),将大模型的部分层输出作为旁枝模型的输入,所有的训练参数尽在旁枝模型中,由于大模型仅提供输入,因此反向传播的复杂度取决于旁枝模型的规模,并不需要直接在原始大模型上执行反向传播,因此是可以明显提升训练效率的。
3.P-tuning 裁剪
识别和去掉模型中不必要的部分
4.Adapter
基于预训练模型,adapter 给出了一个新的思路,即能否在模型中插入一些少量的参数,在下游某个任务微调时只对这些参数进行训练,而保持预训练模型原有的参数不变
5.蒸馏
训练一个小的学生模型来模拟大的老师模型。
1)蒸馏的知识类型:
包括三种,一种是Response-Based Knowledge,主要利用老师模型的最后一层;第二种是Feature-Based Knowledge,除了利用老师模型的最后一层,还利用中间层;第三种是Relation-Based Knowledge,进一步探索不同层或数据样本间的关系。
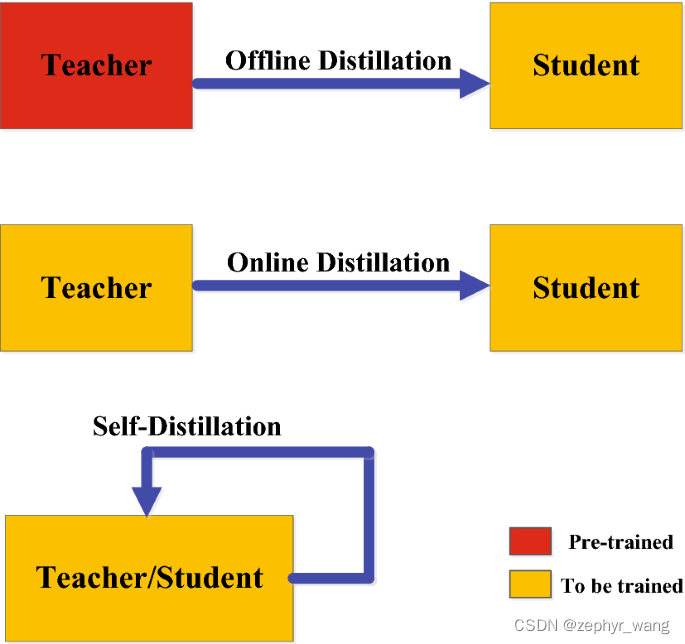
2)蒸馏的策略:
offline distillation:先训练老师,再训练学生
online distillation :老师和学生一起训练
selfdistillation:也可以说online distillation一个特例
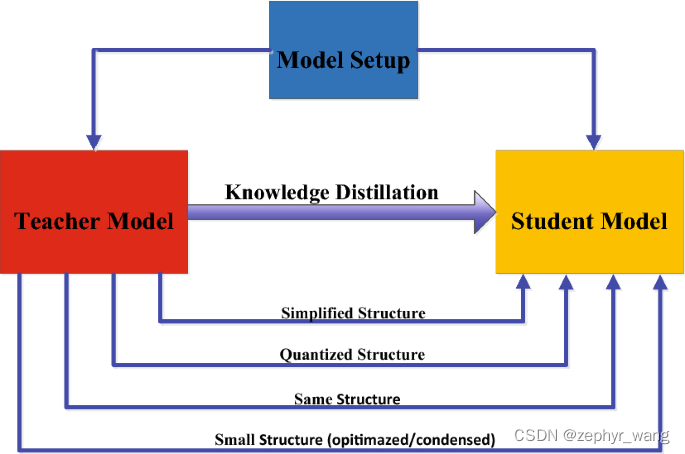
3)模型的架构:
老师和学生的架构可以类似,也可以不一样,如BERT来蒸馏LSTM。
6.动态预测加速(Dynamic Inference Acceleration)
利用一些技巧减少在预测时花的时间。
DeeBERT: Dynamic Early Exiting for Accelerating BERT Inference
BERT Loses Patience: Fast and Robust Inference with Early Exit
Accelerating BERT Inference for Sequence Labeling via Early-Exit
FastBERT: a Self-distilling BERT with Adaptive Inference Time
7.矩阵分解
将大的矩阵分解成两个小的矩阵相乘,如AB变成AC、C*B,其中C远小于A、B。
8.操作融合Operation Fusion
一些数字技巧来合并计算图中的节点
9.模块替换
通过替代模块减少模型复杂度或者深度。
参考:
1.苏剑林. (Jun. 20, 2022). 《Ladder Side-Tuning:预训练模型的“过墙梯” 》[Blog post]. Retrieved from https://kexue.fm/archives/9138
2. All The Ways You Can Compress Transformers
https://www.kaggle.com/code/rhtsingh/all-the-ways-you-can-compress-transformers


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











