






图是数据结构中最复杂、难掌握的一种存储结构,图结构常用来存储逻辑关系为“多对多”的数据。比如说,一个学生可以同时选择多门课程,而一门课程可以同时被多名学生选择,学生和课程之间的逻辑关系就是“多对多”。
再举个例子,{V1, V2, V3, V4} 中各个元素之间具有的逻辑关系如下图所示:

图 1 "多对多" 的逻辑关系
A->B 表示 A 和 B 之间存在单向的联系,由 A 可以找到 B,但由 B 找不到 A。
图 1 中,从 V1 可以找到 V3、V4、V2,从 V3、V4、V2 也可以找到 V1,因此元素之间具有“多对多”的逻辑关系,存储它们就需要用到图结构。
存储图的方式有 4 种,分别是:
- 图的顺序存储结构(C语言实现)
- 图的邻接表存储结构(C语言实现)
- 图的十字链表存储结构(C语言实现)
- 图的邻接多重表存储结构(C语言实现)

图的顺序存储结构(C语言实现)
使用图结构表示的数据元素之间虽然具有“多对多”的关系,但是同样可以采用顺序存储,也就是使用数组有效地存储图。
使用数组存储图时,需要使用两个数组,一个数组存放图中顶点本身的数据(一维数组),另外一个数组用于存储各顶点之间的关系(二维数组)。
存储图中各顶点本身数据,使用一维数组就足够了;存储顶点之间的关系时,要记录每个顶点和其它所有顶点之间的关系,所以需要使用二维数组。
不同类型的图,存储的方式略有不同,根据图有无权,可以将图划分为两大类:图和网 。
图,包括无向图和有向图;网,是指带权的图,包括无向网和有向网。存储方式的不同,指的是:在使用二维数组存储图中顶点之间的关系时,如果顶点之间存在边或弧,在相应位置用 1 表示,反之用 0 表示;如果使用二维数组存储网中顶点之间的关系,顶点之间如果有边或者弧的存在,在数组的相应位置存储其权值;反之用 0 表示。
结构代码表示:
#define MAX_VERtEX_NUM 20 //顶点的最大个数
#define VRType int //表示顶点之间的关系的变量类型
#define InfoType char //存储弧或者边额外信息的指针变量类型
#define VertexType int //图中顶点的数据类型
typedef enum{DG,DN,UDG,UDN}GraphKind; //枚举图的 4 种类型
typedef struct {
VRType adj; //对于无权图,用 1 或 0 表示是否相邻;对于带权图,直接为权值。
InfoType * info; //弧或边额外含有的信息指针
}ArcCell,AdjMatrix[MAX_VERtEX_NUM][MAX_VERtEX_NUM];
typedef struct {
VertexType vexs[MAX_VERtEX_NUM]; //存储图中顶点数据
AdjMatrix arcs; //二维数组,记录顶点之间的关系
int vexnum,arcnum; //记录图的顶点数和弧(边)数
GraphKind kind; //记录图的种类
}MGraph;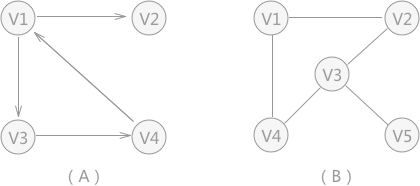
图1 有向图和无向图
例如,存储图 1 中的无向图(B)时,除了存储图中各顶点本身具有的数据外,还需要使用二维数组存储任意两个顶点之间的关系。
由于 (B) 为无向图,各顶点没有权值,所以如果两顶点之间有关联,相应位置记为 1 ;反之记为 0 。构建的二维数组如图 2 所示。

图2 无向图对应的二维数组arcs
在此二维数组中,每一行代表一个顶点,依次从 V1 到 V5 ,每一列也是如此。比如 arcs[0][1] = 1 ,表示 V1 和 V2 之间有边存在;而 arcs[0][2] = 0,说明 V1 和 V3 之间没有边。
对于无向图来说,二维数组构建的二阶矩阵,实际上是对称矩阵,在存储时就可以采用压缩存储的方式存储下三角或者上三角。
通过二阶矩阵,可以直观地判断出各个顶点的度,为该行(或该列)非 0 值的和。例如,第一行有两个 1,说明 V1 有两个边,所以度为 2。
存储图 1 中的有向图(A)时,对应的二维数组如图 3 所示:
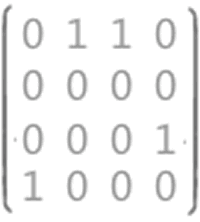
图 3 有向图对应的二维数组arcs
例如,arcs[0][1] = 1 ,证明从 V1 到 V2 有弧存在。且通过二阶矩阵,可以很轻松得知各顶点的出度和入度,出度为该行非 0 值的和,入度为该列非 0 值的和。例如,V1 的出度为第一行两个 1 的和,为 2 ; V1 的入度为第一列中 1 的和,为 1 。所以 V1 的出度为 2 ,入度为 1 ,度为两者的和 3 。
图的顺序存储结构C语言实现
/**
* 快速入门数据结构 https://xiecoding.cn/ds/
**/
#include <stdio.h>
#define MAX_VERtEX_NUM 20 //顶点的最大个数
#define VRType int //表示顶点之间的关系的变量类型
#define InfoType char //存储弧或者边额外信息的指针变量类型
#define VertexType int //图中顶点的数据类型
typedef enum { DG, DN, UDG, UDN }GraphKind; //枚举图的 4 种类型
typedef struct {
VRType adj; //对于无权图,用 1 或 0 表示是否相邻;对于带权图,直接为权值。
InfoType* info; //弧或边额外含有的信息指针
}ArcCell, AdjMatrix[MAX_VERtEX_NUM][MAX_VERtEX_NUM];
typedef struct {
VertexType vexs[MAX_VERtEX_NUM]; //存储图中顶点数据
AdjMatrix arcs; //二维数组,记录顶点之间的关系
int vexnum, arcnum; //记录图的顶点数和弧(边)数
GraphKind kind; //记录图的种类
}MGraph;
//根据顶点本身数据,判断出顶点在二维数组中的位置
int LocateVex(MGraph* G, VertexType v) {
int i = 0;
//遍历一维数组,找到变量v
for (; i < G->vexnum; i++) {
if (G->vexs[i] == v) {
break;
}
}
//如果找不到,输出提示语句,返回-1
if (i == G->vexnum) {
printf("no such vertex.\n");
return -1;
}
return i;
}
//构造有向图
void CreateDG(MGraph* G) {
int i, j;
//输入图含有的顶点数和弧的个数
scanf("%d,%d", &(G->vexnum), &(G->arcnum));
//依次输入顶点本身的数据
for (i = 0; i < G->vexnum; i++) {
scanf("%d", &(G->vexs[i]));
}
//初始化二维矩阵,全部归0,指针指向NULL
for (i = 0; i < G->vexnum; i++) {
for (j = 0; j < G->vexnum; j++) {
G->arcs[i][j].adj = 0;
G->arcs[i][j].info = NULL;
}
}
//在二维数组中添加弧的数据
for (i = 0; i < G->arcnum; i++) {
int v1, v2;
int n, m;
//输入弧头和弧尾
scanf("%d,%d", &v1, &v2);
//确定顶点位置
n = LocateVex(G, v1);
m = LocateVex(G, v2);
//排除错误数据
if (m == -1 || n == -1) {
printf("no this vertex\n");
return;
}
//将正确的弧的数据加入二维数组
G->arcs[n][m].adj = 1;
}
}
//构造无向图
void CreateDN(MGraph* G) {
int i, j;
scanf("%d,%d", &(G->vexnum), &(G->arcnum));
for (i = 0; i < G->vexnum; i++) {
scanf("%d", &(G->vexs[i]));
}
for (i = 0; i < G->vexnum; i++) {
for (j = 0; j < G->vexnum; j++) {
G->arcs[i][j].adj = 0;
G->arcs[i][j].info = NULL;
}
}
for (i = 0; i < G->arcnum; i++) {
int v1, v2;
int n, m;
scanf("%d,%d", &v1, &v2);
n = LocateVex(G, v1);
m = LocateVex(G, v2);
if (m == -1 || n == -1) {
printf("no this vertex\n");
return;
}
G->arcs[n][m].adj = 1;
G->arcs[m][n].adj = 1;//无向图的二阶矩阵沿主对角线对称
}
}
//构造有向网,和有向图不同的是二阶矩阵中存储的是权值。
void CreateUDG(MGraph* G) {
int i, j;
scanf("%d,%d", &(G->vexnum), &(G->arcnum));
for (i = 0; i < G->vexnum; i++) {
scanf("%d", &(G->vexs[i]));
}
for (i = 0; i < G->vexnum; i++) {
for (j = 0; j < G->vexnum; j++) {
G->arcs[i][j].adj = 0;
G->arcs[i][j].info = NULL;
}
}
for (i = 0; i < G->arcnum; i++) {
int v1, v2, w;
int n, m;
scanf("%d,%d,%d", &v1, &v2, &w);
n = LocateVex(G, v1);
m = LocateVex(G, v2);
if (m == -1 || n == -1) {
printf("no this vertex\n");
return;
}
G->arcs[n][m].adj = w;
}
}
//构造无向网。和无向图唯一的区别就是二阶矩阵中存储的是权值
void CreateUDN(MGraph* G) {
int i, j;
scanf("%d,%d", &(G->vexnum), &(G->arcnum));
for (i = 0; i < G->vexnum; i++) {
scanf("%d", &(G->vexs[i]));
}
for (i = 0; i < G->vexnum; i++) {
for (j = 0; j < G->vexnum; j++) {
G->arcs[i][j].adj = 0;
G->arcs[i][j].info = NULL;
}
}
for (i = 0; i < G->arcnum; i++) {
int v1, v2, w;
int m, n;
scanf("%d,%d,%d", &v1, &v2, &w);
m = LocateVex(G, v1);
n = LocateVex(G, v2);
if (m == -1 || n == -1) {
printf("no this vertex\n");
return;
}
G->arcs[n][m].adj = w;
G->arcs[m][n].adj = w;//矩阵对称
}
}
void CreateGraph(MGraph* G) {
//选择图的类型
scanf("%d", &(G->kind));
//根据所选类型,调用不同的函数实现构造图的功能
switch (G->kind) {
case DG:
return CreateDG(G);
break;
case DN:
return CreateDN(G);
break;
case UDG:
return CreateUDG(G);
break;
case UDN:
return CreateUDN(G);
break;
default:
break;
}
}
//输出函数
void PrintGrapth(MGraph G)
{
int i, j;
for (i = 0; i < G.vexnum; i++)
{
for (j = 0; j < G.vexnum; j++)
{
printf("%d ", G.arcs[i][j].adj);
}
printf("\n");
}
}
int main() {
MGraph G;//建立一个图的变量
CreateGraph(&G);//调用创建函数,传入地址参数
PrintGrapth(G);//输出图的二阶矩阵
return 0;
}注意:在此程序中,构建无向网和有向网时,对于之间没有边或弧的顶点,相应的二阶矩阵中存放的是 0。目的只是为了方便查看运行结果,而实际上如果顶点之间没有关联,它们之间的距离应该是无穷大(∞)。
例如,使用上述程序存储图 4(a)的有向网时,存储的两个数组如图 4(b)所示:
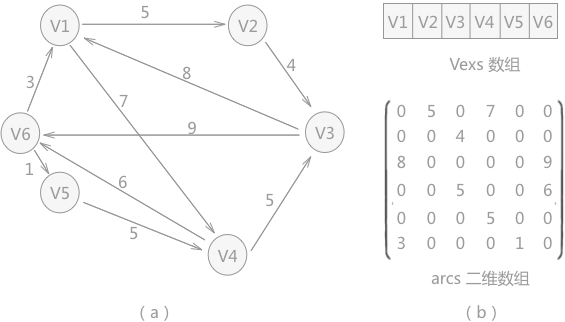
图 4 有向网
相应地运行结果为:
2
6,10
1
2
3
4
5
6
1,2,5
2,3,4
3,1,8
1,4,7
4,3,5
3,6,9
6,1,3
4,6,6
6,5,1
5,4,5
0 5 0 7 0 0
0 0 4 0 0 0
8 0 0 0 0 9
0 0 5 0 0 6
0 0 0 5 0 0
3 0 0 0 1 0
总结一下,本节主要详细介绍了使用数组存储图的方法,在实际操作中使用更多的是链式存储结构,例如邻接表、十字链表和邻接多重表,这三种存储图的方式放在下一节重点去讲。
图的邻接表存储结构(C语言实现)
邻接表(Adjacency List)是图的一种链式存储结构,既可以存储无向图(网),也可以存储有向图(网)。
邻接表存储图的核心思想是:将图中的所有顶点存储到顺序表中(也可以是链表),同时为各个顶点配备一个单链表,用来存储和当前顶点有直接关联的边或者弧(边的一端是该顶点或者弧的弧尾是该顶点)。
举个简单的例子,下图是一张有向图和它对应的邻接表:

图 1 有向图和它对应的邻接表
以顶点 V1 为例,它对应的单链表中有两个结点,存储的值分别是 2 和 1。2 是 V3 顶点在顺序表中的位置下标,存储 2 的结点就表示 <V1, V3> 这条弧;同理,1 是 V2 顶点在顺序表中的位置下标,存储 1 的结点就表示 <V1, V2> 这条弧。
也就是说,邻接表中存储边或弧的方法,就是存储边或弧另一端顶点在顺序表中的位置下标。
继续分析图 1b) 中的另外 3 个单链表:
- V2:由于图中不存在以 V2 为弧尾的弧,所以不需要为 V2 构建链表;
- V3:以 V3 为弧尾的弧只有 <V3, V4>,V4 在顺序表对应的下标为 3,因此单链表中只有 1 个结点,结点中存储 3 来表示 <V3, V4>。
- V4:以 V4 为弧尾的弧只有 <V4, V1>,V1 在顺序表对应的下标为 0,因此单链表中只有 1 个结点,结点中存储 0 来表示 <V4, V1>。
邻接表的具体实现
实际上,邻接表就是由一个顺序表和多个单链表组成的,顺序表用来存储图中的所有顶点,各个单链表存储和当前顶点有直接关联的边或弧。
存储顶点的顺序表,内部各个空间的结构如下图所示:

图 2 顺序表内空间结构示意图
data 为数据域,用来存储各个顶点的信息;next 为指针域,用来链接下一个结点。
对于无向图或者有向图来说,单链表中存储边或弧的结点也可以用图 2 所示的结构来表示,data 数据域存储边或弧另一端顶点在顺序表中的下标,next 指针域用来链接下一个结点。对于无向网或者有向网来说,结点可以用下图所示的结构来表示:

图 3 存储网结构中边或弧的结点示意图
adjvex 数据域用来存储边或弧另一端顶点在顺序表中的下标;next 指针域用来链接下一个结点;info 指针域用来存储有关边或弧的其它信息,比如边或弧的权值。
用 C 语言表示邻接表的实现代码如下:
#define MAX_VERTEX_NUM 20//图中顶点的最大数量
#define VertexType int//图中顶点的类型
#define InfoType int*//图中弧或者边包含的信息的类型
typedef struct ArcNode{
int adjvex;//存储边或弧,即另一端顶点在数组中的下标
struct ArcNode * nextarc;//指向下一个结点
InfoType info;//记录边或弧的其它信息
}ArcNode;
typedef struct VNode{
VertexType data;//顶点的数据域
ArcNode * firstarc;//指向下一个结点
}VNode,AdjList[MAX_VERTEX_NUM];//存储各链表首元结点的数组
typedef struct {
AdjList vertices;//存储图的邻接表
int vexnum,arcnum;//记录图中顶点数以及边或弧数
int kind;//记录图的种类
}ALGraph;以上各个结构体中的成员并非一成不变,根据实际场景的需要,可以修改它们的数据类型,还可以适当地删减。
邻接表计算顶点的出度和入度
在有向图(网)中,顶点的入度指的是以当前顶点一端为弧头的弧的数量;顶点的出度指的是以当前顶点一端为弧尾的弧的数量。
例如,图 1a) 中顶点 V1 的入度为 1,出度为 2。
在邻接表中计算某个顶点的出度是非常简单的,只需要在顺序表中找到该顶点,然后计算该顶点所在链表中其它结点的数量,即为该顶点的出度。例如,图 1b) 中为 V1 构建的链表中有 2 个结点,因此 V1 的出度就是 2。
在邻接表中计算某个顶点的入度,有两种实现方案:
- 遍历顺序表,找到该顶点,获取该顶点所在顺序表中的下标(假设为 K)。然后遍历所有单链表中的结点,统计数据域为 K 的结点数量,即为该顶点的入度。
- 建立一个逆邻接表,表中各个顶点的链表中记录的是以当前顶点一端为弧头的弧的信息。比如说,图 1a) 对应的逆邻接表如下图所示:

图 4 逆邻接表
以 V1 顶点为例,数据域为 3 的结点记录的是 <V4, V1> 这条弧。
总结
对于具有 n 个顶点和 e 条边的无向图,邻接表中需要构建 n 个首元结点和 2e 个表示边的结点;对于具有 n 个顶点和 e 条弧的有向图,邻接表需要构建 n 个首元结点和 e 个表示弧的结点。
当图中边或者弧稀疏时,用邻接表比前一节介绍的邻接矩阵更加节省空间,边或弧相关信息较多时更是如此。
最后,用邻接表存储图 1a) 中有向图的 C 语言程序如下所示:
/**
* 快速入门数据结构 https://xiecoding.cn/ds/
**/
#include<stdio.h>
#include<stdlib.h>
#define MAX_VERTEX_NUM 20//最大顶点个数
#define VertexType char//图中顶点的类型
typedef struct ArcNode {
int adjvex;//存储弧,即另一端顶点在数组中的下标
struct ArcNode* nextarc;//指向下一个结点
}ArcNode;
typedef struct VNode {
VertexType data;//顶点的数据域
ArcNode* firstarc;//指向下一个结点
}VNode, AdjList[MAX_VERTEX_NUM];//存储各链表首元结点的数组
typedef struct {
AdjList vertices; //存储图的邻接表
int vexnum, arcnum;//图中顶点数以及弧数
}ALGraph;
void CreateGraph(ALGraph * graph) {
int i, j;
char VA, VB;
ArcNode* node = NULL;
printf("输入顶点的数目:\n");
scanf("%d", &(graph->vexnum));
printf("输入弧的数目:\n");
scanf("%d", &(graph->arcnum));
scanf("%*[^\n]"); scanf("%*c");
printf("输入各个顶点的值:\n");
for (i = 0; i < graph->vexnum; i++) {
scanf("%c", &(graph->vertices[i].data));
getchar();
graph->vertices[i].firstarc = NULL;
}
//输入弧的信息,并为弧建立结点,链接到对应的链表上
for (i = 0; i < graph->arcnum; i++) {
printf("输入弧(a b 表示弧 a->b):\n");
scanf("%c %c", &VA, &VB);
getchar();
node = (ArcNode*)malloc(sizeof(ArcNode));
node->adjvex = '#';
node->nextarc = NULL;
//存储弧另一端顶点所在顺序表中的下标
for (j = 0; j < graph->vexnum; j++) {
if (VB == graph->vertices[j].data) {
node->adjvex = j;
break;
}
}
//如果未在顺序表中找到另一端顶点,则构建图失败
if (node->adjvex == '#') {
printf("弧信息输入有误\n");
exit(0);
}
//将结点添加到对应的链表中
for (j = 0; j < graph->vexnum; j++) {
if (VA == graph->vertices[j].data) {
//将 node 结点以头插法的方式添加到相应链表中
node->nextarc = graph->vertices[j].firstarc;
graph->vertices[j].firstarc = node;
break;
}
}
if (j == graph->vexnum) {
printf("弧信息输入有误\n");
exit(0);
}
}
}
//计算某个顶点的入度
int InDegree(ALGraph graph, char V) {
int i, j, index = -1;
int count = 0;
//找到 V 在顺序表中的下标
for (j = 0; j < graph.vexnum; j++) {
if (V == graph.vertices[j].data) {
index = j;
break;
}
}
if (index == -1) {
return -1;
}
//遍历每个单链表,找到存储 V 下标的结点,并计数
for (j = 0; j < graph.vexnum; j++) {
ArcNode* p = graph.vertices[j].firstarc;
while (p) {
if (p->adjvex == index) {
count++;
}
p = p->nextarc;
}
}
return count;
}
//计算某个顶点的出度
int OutDegree(ALGraph graph, char V) {
int j;
int count = 0;
for (j = 0; j < graph.vexnum; j++) {
if (V == graph.vertices[j].data) {
ArcNode* p = graph.vertices[j].firstarc;
while (p) {
count++;
p = p->nextarc;
}
break;
}
}
//如果查找失败,返回 -1 表示计算失败
if (j == graph.vexnum) {
return -1;
}
return count;
}
int main(void) {
ALGraph graph;
CreateGraph(&graph);
if (OutDegree(graph, 'A') != -1) {
printf("%c 顶点的出度为 %d\n", 'A', OutDegree(graph, 'A'));
}
if (InDegree(graph, 'A') != -1) {
printf("%c 顶点的入度为 %d", 'A', InDegree(graph, 'A'));
}
return 0;
}假设我们用 A、B、C、D 分别表示 V1、V2、V3、V4,程序的执行过程为:
输入顶点的数目:
4
输入弧的数目:
4
输入各个顶点的值:
A B C D
输入弧(a b 表示弧 a->b):
A B
输入弧(a b 表示弧 a->b):
A C
输入弧(a b 表示弧 a->b):
C D
输入弧(a b 表示弧 a->b):
D A
A 顶点的出度为 2
A 顶点的入度为 1
图的十字链表存储结构(C语言实现)
存储有向图(网),可以使用邻接表或者逆邻接表结构,也可以使用本节讲解的十字链表结构。
代码
用邻接表存储有向图(网),可以快速计算出某个顶点的出度,但计算入度的效率不高。反之,用逆邻接表存储有向图(网),可以快速计算出某个顶点的入度,但计算出度的效率不高。
那么有没有一种存储结构,可以快速计算出有向图(网)中某个顶点的入度和出度呢?答案是肯定的,十字链表就是这样的一种存储结构。
十字链表(Orthogonal List)是一种专门存储有向图(网)的结构,它的核心思想是:将图中的所有顶点存储到顺序表(也可以是链表)中,同时为每个顶点配备两个链表,一个链表记录以当前顶点为弧头的弧,另一个链表记录以当前顶点为弧尾的弧。
举个简单的例子,用十字链表结构存储图 1a) 中的有向图,图的存储状态如图 1b) 所示:

图 1 十字链表结构存储有向图
观察图 1b),顺序表中的各个存储空间分为 3 部分,各个链表中的结点空间分为 4 部分。
顺序表中的空间用来存储图中的顶点,结构如下图所示:

图 2 存储顶点的结构
各部分的含义分别是:
- data 数据域:用来存储顶点的信息;
- firstin 指针域:指向一个链表,链表中记录的都是以当前顶点为弧头的弧的信息;
- firstout 指针域:指向另一个链表,链表中记录的是以当前顶点为弧尾的弧的信息。
链表的结点用来存储图中的弧,结构如下图所示:

图 3 存储弧信息的结点结构
各部分的含义分别是:
- tailvex数据域:存储弧尾一端顶点在顺序表中的位置下标;
- headvex 数据域:存储弧头一端顶点在顺序表中的位置下标;
- hlink 指针域:指向下一个以当前顶点作为弧头的弧;
- tlink 指针域:指向下一个以当前顶点作为弧尾的弧;
- info 指针:存储弧的其它信息,例如有向网中弧的权值。如果不需要存储其它信息,可以省略。
在十字链表结构中,如果想计算某个顶点的出度,就统计 firstout 所指链表中的结点数量,每找到一个结点,再根据它的 tlink 指针域寻找下一个结点,直到最后一个结点。同样的道理,如果想计算某个顶点的入度,就统计 firstin 所指链表中的结点数量,每找到一个结点,再根据它的 hlink 指针域寻找下一个结点,直到最后一个结点。
以图 1b) 中的 V1 顶点为例,计算出度的过程是:
- 根据 V1 顶点的 firstout 指针,找到存储 <V1, V2> 弧的结点;
- 根据 <V1, V2> 弧结点中的 tlink 指针,找到存储 <V1, V3> 弧的结点;
- 由于 <V1, V3> 弧结点的 tlink 指针为 NULL,因此只找到了 2 个弧,V1 顶点的出度就为 2。
计算 V1 顶点入度的过程是:
- 根据 V1 顶点的 firstin 指针,找到存储 <V4, V1> 弧的结点;
- 由于 <V4, V1> 弧结点的 hlink 指针为 NULL,因此只找到了 1 个弧,V1 顶点的入度就为 1。
如果你已经学会了邻接表和逆邻接表,可以将十字链表想象成邻接表和逆邻接表的结合体。
构建图的十字链表结构,对应的 C 语言代码如下:
/**
* 快速入门数据结构 https://xiecoding.cn/ds/
**/
#define MAX_VERTEX_NUM 20 //图中顶点的最大数量
#define InfoType int* //表示弧额外信息的数据类型
#define VertexType char //图中顶点的数据类型
//表示链表中存储弧的结点
typedef struct ArcBox {
int tailvex, headvex; //弧尾、弧头对应顶点在顺序表中的位置下标
struct ArcBox* hlik, * tlink; //hlik指向下一个以当前顶点为弧头的弧结点;
//tlink 指向下一个以当前顶点为弧尾的弧结点;
//InfoType info; //存储弧相关信息的指针
}ArcBox;
//表示顺序表中的各个顶点
typedef struct VexNode {
VertexType data; //顶点的数据域
ArcBox* firstin, * firstout; //指向以该顶点为弧头和弧尾的链表首个结点
}VexNode;
//表示十字链表存储结构
typedef struct {
VexNode xlist[MAX_VERTEX_NUM]; //存储顶点的顺序表
int vexnum, arcnum; //记录图的顶点数和弧数
}OLGraph;十字链表结构的具体实现
以图 1a) 为例,十字链表结构存储此图的完整 C 语言程序如下所示:
/**
* 快速入门数据结构 https://xiecoding.cn/ds/
**/
#include<stdio.h>
#define MAX_VERTEX_NUM 20 //图中顶点的最大数量
#define InfoType int* //表示弧额外信息的数据类型
#define VertexType char //图中顶点的数据类型
//表示链表中存储弧的结点
typedef struct ArcBox {
int tailvex, headvex; //弧尾、弧头对应顶点在顺序表中的位置下标
struct ArcBox* hlik, * tlink; //hlik指向下一个以当前顶点为弧头的弧结点;
//tlink 指向下一个以当前顶点为弧尾的弧结点;
//InfoType info; //存储弧相关信息的指针
}ArcBox;
//表示顺序表中的各个顶点
typedef struct VexNode {
VertexType data; //顶点的数据域
ArcBox* firstin, * firstout; //指向以该顶点为弧头和弧尾的链表首个结点
}VexNode;
//表示十字链表存储结构
typedef struct {
VexNode xlist[MAX_VERTEX_NUM]; //存储顶点的顺序表
int vexnum, arcnum; //记录图的顶点数和弧数
}OLGraph;
int LocateVex(OLGraph* G, VertexType v) {
int i;
//遍历一维数组,找到变量v
for (i = 0; i < G->vexnum; i++) {
if (G->xlist[i].data == v) {
break;
}
}
//如果找不到,输出提示语句,返回 -1
if (i > G->vexnum) {
printf("no such vertex.\n");
return -1;
}
return i;
}
//构建十字链表存储结构
void CreateDG(OLGraph* G) {
int i, j, k;
VertexType v1, v2;
ArcBox* p = NULL;
//输入有向图的顶点数和弧数
scanf("%d %d", &(G->vexnum), &(G->arcnum));
getchar();
//使用一维数组存储顶点数据,初始化指针域为NULL
for (i = 0; i < G->vexnum; i++) {
scanf("%c", &(G->xlist[i].data));
getchar();
G->xlist[i].firstin = NULL;
G->xlist[i].firstout = NULL;
}
//存储图中的所有弧
for (k = 0; k < G->arcnum; k++) {
scanf("%c %c", &v1, &v2);
getchar();
//确定v1、v2在数组中的位置下标
i = LocateVex(G, v1);
j = LocateVex(G, v2);
//建立弧的结点
p = (ArcBox*)malloc(sizeof(ArcBox));
p->tailvex = i;
p->headvex = j;
//采用头插法插入新的p结点
p->hlik = G->xlist[j].firstin;
p->tlink = G->xlist[i].firstout;
G->xlist[j].firstin = G->xlist[i].firstout = p;
}
}
//计算某顶点的入度
int indegree(OLGraph* G, VertexType x) {
int i;
int num = 0;
//遍历整个顺序表
for (i = 0; i < G->vexnum; i++) {
//找到目标顶点
if (x == G->xlist[i].data) {
//从该顶点的 firstin 指针所指的结点开始遍历
ArcBox* p = G->xlist[i].firstin;
while (p)
{
num++;
//遍历 hlink 指针指向的下一个结点
p = p->hlik;
}
break;
}
}
if (i == G->vexnum) {
printf("图中没有指定顶点\n");
return -1;
}
return num;
}
//计算某顶点的出度
int outdegree(OLGraph* G, VertexType x) {
int i;
int num = 0;
//遍历整个顺序表
for (i = 0; i < G->vexnum; i++) {
//找到目标顶点
if (x == G->xlist[i].data) {
//从该顶点的 firstout 指针所指的结点开始遍历
ArcBox* p = G->xlist[i].firstout;
while (p)
{
num++;
//遍历 tlink 指针指向的下一个结点
p = p->tlink;
}
break;
}
}
if (i == G->vexnum) {
printf("图中没有指定顶点\n");
return -1;
}
return num;
}
//删除十字链表结构
//每个顶点配备两个链表,选定一个链表(比如 firstout 所指链表),删除每个顶点中 firstout 所指链表上的结点
void DeleteDG(OLGraph* G) {
int i;
ArcBox* p = NULL, * del = NULL;
for (i = 0; i < G->vexnum; i++) {
p = G->xlist[i].firstout;
while (p) {
del = p;
p = p->tlink;
free(del);
}
//将第 i 个位置的两个指针全部置为 NULL,能有效避免出现野指针
G->xlist[i].firstout = NULL;
G->xlist[i].firstin = NULL;
}
}
int main() {
OLGraph G;
CreateDG(&G);
printf("A 顶点的入度为 %d\n", indegree(&G, 'A'));
printf("A 顶点的出度为 %d\n", outdegree(&G, 'A'));
DeleteDG(&G);
return 0;
}分别用 A、B、C、D 表示 V1、V2、V3 和 V4,程序的运行结果为:
4 5
A B C D
A B
A C
C D
D A
D B
A 顶点的入度为 1
A 顶点的出度为 2
图的邻接多重表存储结构(C语言实现)
存储无向图(网),既可以使用邻接表结构,也可以使用本节讲解的邻接多重表结构。
以图 1a) 的无向图为例,如果用邻接表存储它,存储状态如图 1b) 所示:
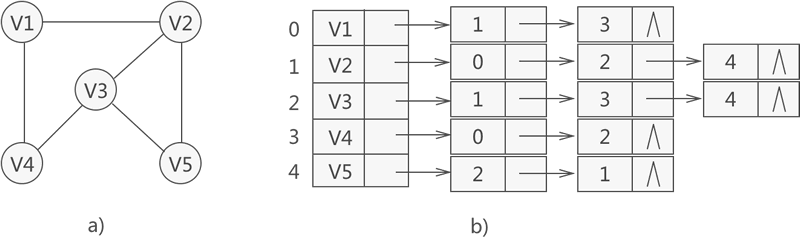
图 1 邻接表存储无向图
观察图 1b) 的邻接表:
- V1 的链表中有两个结点,记录着 (V1, V2) 和 (V1, V4) 这两条边;
- V2 的链表中有三个结点,记录着 (V2, V1)、(V2, V3) 和 (V2, V5) 这三条边;
- V3 的链表中有三个结点,记录着 (V3, V2)、(V3, V4) 和 (V3, V5) 这三条边;
- V4 的链表中有两个结点,记录着 (V4, V1) 和 (V4, V3) 这两条边;
- V5 的链表中有两个结点,记录着 (V5, V3) 和 (V5, V2) 这两条边。
在无向图里,(Vi, Vj) 和 (Vj, Vi) 表示的其实是同一条边,比如 (V1, V2) 和 (V2, V1) 就是同一条边。无向图的邻接表存储结构中,每条边都会存储两份,比如我们可以在 V1 顶点的链表中找到 (V1, V2) 这条边,也可以在 V2 的链表中找到 (V2, V1) 这条边。
实际场景中,如果需要对无向图中的边做大量的插入或删除操作,不推荐使用邻接表存储结构,因为每条边在邻接表都存有两份,同样的操作需要处理两次。这种情况下,可以优先考虑邻接多重表存储结构。
邻接多重表是什么
邻接多重表(Adjacency Multilist)是一种专门存储无向图(网)的结构。
邻接多重表存储无向图的方式,可以看作是邻接表和十字链表的结合体,具体来讲就是:将图中的所有顶点存储到顺序表(也可以用链表)中,同时为每个顶点配备一个链表,链表的各个结点中存储的都是和当前顶点有直接关联的边。
举个简单的例子,用邻接多重表存储图 1a) 的无向图,存储状态如下图所示:

图 2 邻接多重表存储无向图
观察图 2b),顺序表的各个存储空间分为 2 部分,链表中的结点空间分为 5 部分。
顺序表用来存储图中的各个顶点,各个存储空间的结构如下图所示:

图 3 顺序表中存储空间的结构
data 数据域用来存储顶点的数据;firstedge 指针域用来指向为当前顶点配备的链表。
邻接多重表中的链表用来存储和当前顶点有直接关联的边,结点的结构如下图所示:

图 4 链表中的结点结构
各个部分的含义分别是:
- mark 标志域:实际场景中,可以为每个结点设置一个标志域,记录当前结点是否已经被操作过。例如遍历无向图中的所有边,借助 mark 标志域可以避免重复访问同一条边;
- ivex 和 jvec:都是数据域,分别存储边两端顶点所在顺序表中的位置下标;
- ilink 指针域:指向下一个与 ivex 顶点有直接关联的边结点;
- jlink 指针域:指向下一个与 jvex 顶点有直接关联的边节点;
- info 指针域:存储当前边的其它信息,比如存储无向网时,可以用 info 指针域存储边的权值。
在邻接多重表中,很容易可以找到和目标顶点有直接关联的所有边。以图 3 中的 V1 顶点为例,在邻接多重表中查找和它直接关联的边,具体过程是:
- 根据 V1 顶点的 firstedge 指针域,找到第一个和 V1 有直接关联的边结点 (V1, V2);
- 在 (V1, V2) 边结点中,ivex 数据域存储着 V1 顶点对应的顺序表下标,因此继续根据 ilink 指针域找到下一个边结点 (V1, V4);
- 在 (V1, V4) 边结点中,ivex 数据域存储着 V1 顶点对应的顺序表下标,但 ilink 指针域为 NULL,因此查找结束;
对比图 1 和图 2 不难发现,邻接多重表和邻接表最大的不同是:对于无向图中的每个边,邻接表需要存储两份数据,而邻接多重表只需要存储一份。因此,当需要在无向图中做大量的插入或删除边的操作时,选用邻接多重表存储无向图,可以提高程序的执行效率。
构建无向图的邻接多重表结构,对应的 C 语言代码为:
#define MAX_VERTEX_NUM 20 //图中顶点的最大数量
#define InfoType int* //边结点中info域的数据类型
#define VertexType int //顶点的数据类型
typedef enum { unvisited, visited }VisitIf; //边标志域
//表示链表中的各个结点
typedef struct EBox {
VisitIf mark; //标志域
int ivex, jvex; //边两边顶点在顺序表中的位置下标
struct EBox* ilink, * jlink; //分别指向与ivex、jvex相关的下一个边结点
InfoType* info; //边的其它信息
}EBox;
//存储图中的各个顶点
typedef struct VexBox {
VertexType data; //顶点数据域
EBox* firstedge; //指向当前顶点对应的链表
}VexBox;
//表示邻接多重表结构
typedef struct {
VexBox adjmulist[MAX_VERTEX_NUM]; //存储图中顶点的顺序表
int vexnum, edgenum; //记录图中的顶点数量和边数量
}AMLGraph;可以根据实现场景的需要,可以修改结构体中各个成员的数据类型,必要时还可以对某些成员进行删减,怎么方便怎么来。
邻接多重表的具体实现
如下是一个完整的 C 语言程序,实现了邻接多重表结构的创建和删除,以及对无向图中指定边的插入和删除操作,附带详尽的代码注释。
/**
* 快速入门数据结构 https://xiecoding.cn/ds/
**/
#include<stdio.h>
#define MAX_VERTEX_NUM 20 //图中顶点的最大数量
#define VertexType char //顶点的数据类型
#define Status int //设定一些函数的返回值类型
typedef enum { unvisited, visited }VisitIf; //边标志域
//表示链表中的各个结点
typedef struct EBox {
VisitIf mark; //标志域
int ivex, jvex; //边两边顶点在顺序表中的位置下标
struct EBox* ilink, * jlink; //分别指向与ivex、jvex相关的下一个边结点
}EBox;
//存储图中的各个顶点
typedef struct VexBox {
VertexType data; //顶点数据域
EBox* firstedge; //指向当前顶点对应的链表
}VexBox;
//表示邻接多重表结构
typedef struct {
VexBox adjmulist[MAX_VERTEX_NUM]; //存储图中顶点的顺序表
int vexnum, edgenum; //记录图中的顶点数量和边数量
}AMLGraph;
//获取 v 顶点在顺序表中的位置下标
int LocateVex(AMLGraph* G, VertexType v);
//创建邻接多重表
Status CreateDN(AMLGraph* G);
//将(V1,V2)插入到邻接多重表中
Status InsertEdge(AMLGraph* G, VertexType V1, VertexType V2);
//从邻接多重表中删除 (V1,V2)或者(V2,V1)
Status DeleteEdge(AMLGraph* G, VertexType V1, VertexType V2);
//输出邻接多重表中包含的所有边
void PrintEdges(AMLGraph* G);
//重置各个结点中的标志域
void InitMarks(AMLGraph* G);
//释放邻接多重表中申请的堆空间
Status DeleteDN(AMLGraph* G);
int main() {
AMLGraph G;
CreateDN(&G);
PrintEdges(&G);
printf("删除 A-B 边:\n");
DeleteEdge(&G, 'A', 'B');
PrintEdges(&G);
DeleteDN(&G);
return 0;
}
int LocateVex(AMLGraph* G, VertexType v) {
int i;
//遍历一维数组,找到变量v
for (i = 0; i < G->vexnum; i++) {
if (G->adjmulist[i].data == v) {
break;
}
}
//如果找不到,输出提示语句,返回 -1
if (i > G->vexnum) {
printf("no such vertex.\n");
return -1;
}
return i;
}
Status CreateDN(AMLGraph* G) {
int i, j, k;
VertexType V1, V2;
//输入无向图的顶点数和边数
scanf("%d %d", &(G->vexnum), &(G->edgenum));
getchar();
//使用一维数组存储顶点数据,初始化指针域为NULL
for (i = 0; i < G->vexnum; i++) {
scanf("%c", &(G->adjmulist[i].data));
getchar();
G->adjmulist[i].firstedge = NULL;
}
//存储图中的所有边
for (k = 0; k < G->edgenum; k++) {
scanf("%c %c", &V1, &V2);
getchar();
InsertEdge(G, V1, V2);
}
return 1;
}
Status InsertEdge(AMLGraph* G, VertexType V1, VertexType V2) {
int V1Add = LocateVex(G, V1);
int V2Add = LocateVex(G, V2);
EBox* node = NULL, * p = NULL, * q = NULL;
if (V1Add < 0 || V2Add < 0) {
printf("输入边信息有误\n");
exit(-1);
}
//构建一个新结点
node = (EBox*)malloc(sizeof(EBox));
node->mark = unvisited;
node->ivex = V1Add;
node->jvex = V2Add;
//用头插法,将 node 结点链接到 V1 顶点的链表中
node->ilink = G->adjmulist[V1Add].firstedge;
G->adjmulist[V1Add].firstedge = node;
//用头插法,将 node 结点链接到 V2 顶点的链表中
node->jlink = G->adjmulist[V2Add].firstedge;
G->adjmulist[V2Add].firstedge = node;
return 1;
}
/*
* 删除(V1,V2) 或者(V2,V1)
* 实现思路:
* 1、从 V1 顶点的链表出发,找到目标结点的直接前驱结点;
* 2、从 V2 顶点的链表触发,找到目标结点的直接前驱结点;
* 3、将目标结点从 V1 顶点的链表中摘除,从 V2 顶点的链表中摘除
* 4、删除目标结点
*/
Status DeleteEdge(AMLGraph* G, VertexType V1, VertexType V2) {
int V1Add = LocateVex(G, V1);
int V2Add = LocateVex(G, V2);
EBox* icurNode = NULL, * ipreNode = NULL;
EBox* jcurNode = NULL, * jpreNode = NULL;
//1、从 V1 顶点的链表出发,找到目标结点的直接前驱结点;
icurNode = G->adjmulist[V1Add].firstedge;
while (icurNode && !(((icurNode->ivex == V1Add) && (icurNode->jvex == V2Add)) || ((icurNode->ivex == V2Add) && (icurNode->jvex == V1Add)))) {
ipreNode = icurNode;
if (icurNode->ivex == V1Add) {
icurNode = icurNode->ilink;
}
else
{
icurNode = icurNode->jlink;
}
}
if (!icurNode) {
printf("指定的边不存在,失败操作失败\n");
return -1;
}
//2、从 V2 顶点的链表触发,找到目标结点的直接前驱结点;
jcurNode = G->adjmulist[V2Add].firstedge;
while (jcurNode && !(((jcurNode->ivex == V1Add) && (jcurNode->jvex == V2Add)) || ((jcurNode->ivex == V2Add) && (jcurNode->jvex == V1Add)))) {
jpreNode = jcurNode;
if (jcurNode->ivex == V2Add) {
jcurNode = jcurNode->ilink;
}
else
{
jcurNode = jcurNode->jlink;
}
}
if (!jcurNode) {
printf("指定的边不存在,失败操作失败\n");
return -1;
}
//3、将目标结点从 V1 顶点的链表中摘除
if (ipreNode == NULL) {
if (icurNode->ivex == V1Add) {
G->adjmulist[V1Add].firstedge = icurNode->ilink;
}
else
{
G->adjmulist[V1Add].firstedge = icurNode->jlink;
}
}
else
{
if (ipreNode->ivex == V1Add) {
if (icurNode->ivex == V1Add) {
ipreNode->ilink = icurNode->ilink;
}
else
{
ipreNode->ilink = icurNode->jlink;
}
}
else
{
if (icurNode->ivex == V1Add) {
ipreNode->jlink = icurNode->ilink;
}
else
{
ipreNode->jlink = icurNode->jlink;
}
}
}
//3、将目标结点从 V2 顶点的链表中摘除
if (jpreNode == NULL) {
if (jcurNode->ivex == V2Add) {
G->adjmulist[V2Add].firstedge = jcurNode->ilink;
}
else
{
G->adjmulist[V2Add].firstedge = jcurNode->jlink;
}
}
else
{
if (jpreNode->ivex == V2Add) {
if (jcurNode->ivex == V2Add) {
jpreNode->ilink = jcurNode->ilink;
}
else
{
jpreNode->ilink = jcurNode->jlink;
}
}
else
{
if (jcurNode->ivex == V2Add) {
jpreNode->jlink = jcurNode->ilink;
}
else
{
jpreNode->jlink = jcurNode->jlink;
}
}
}
//4、删除目标结点
free(icurNode); //free(jcurNode),二选一
return 1;
}
//输出邻接多重表中包含的所有边
void PrintEdges(AMLGraph* G) {
int i;
EBox* p = NULL;
//重置所有结点的标志域
InitMarks(G);
for (i = 0; i < G->vexnum; i++) {
p = G->adjmulist[i].firstedge;
//如果当前结点存在,且标志域为 0
while (p && (p->mark == 0)) {
//输出该边,并将标志域置为 1
printf("%c-%c ", G->adjmulist[p->ivex].data, G->adjmulist[p->jvex].data);
p->mark = 1;
if (p->ivex == i) {
p = p->ilink;
}
else
{
p = p->jlink;
}
}
}
printf("\n");
}
//重置所有结点的标志域
void InitMarks(AMLGraph* G) {
int i;
EBox* p = NULL;
for (i = 0; i < G->vexnum; i++) {
p = G->adjmulist[i].firstedge;
while (p && (p->mark == 1)) {
p->mark = 0;
if (p->ivex == i) {
p = p->ilink;
}
else
{
p = p->jlink;
}
}
}
}
//释放邻接多重表中申请的堆空间
//直接调用DeleteEdge()删除各个结点
Status DeleteDN(AMLGraph* G) {
int i;
EBox* p = NULL, * del = NULL;
for (i = 0; i < G->vexnum; i++) {
p = G->adjmulist[i].firstedge;
while (p) {
del = p;
if (p->ivex == i) {
p = p->ilink;
}
else
{
p = p->jlink;
}
DeleteEdge(G, G->adjmulist[del->ivex].data, G->adjmulist[del->jvex].data);
}
}
return 1;
}以图 1a) 中的无向图为例,用 A~E 表示 V1~V5,程序的执行结果为:
5 6
A B C D E
A B
A D
B C
C D
C E
B E5 6
A-D A-B B-E B-C C-E C-D
删除 A-B 边:
A-D B-E B-C C-E C-D



















 7056
7056

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









