






目录
都说图论数论,除了Offer必备算法专栏外,下面博客还有关于图论的内容:
其它高阶数据结构②_图(概念+存储+遍历+最小生成树)_图的概念与遍历-优快云博客
其它高阶数据结构③_图的最短路径(三种算法思想+代码实现)-优快云博客
下面来学习数论的内容,一些很简单的数论之前已经学习过了,比如辗转相除法求最大公约数GCD(Greatest Common Divisor).
1. 辗转相除法(欧几里得算法)
1.1 辗转相除法gcd
-
gcd:两个整数 a 和 b 的最大公约数是能同时整除它们的最大正整数,记为 gcd(a,b)。
-
欧几里得算法:基于以下定理递归求解 GCD:gcd(a,b)=gcd(b,a mod b)
终止条件:当 b=0 时,gcd(a,0)=a。
#include <iostream>
#include <algorithm>
using namespace std;
int GCD(int a, int b)
{
return b ? gcd(b, a % b) : a;
}
int main()
{
cout << gcd(4, 12) << endl;
cout << __gcd(4, 12) << endl; // algorithm
return 0;
}小公倍数LCM(Least Common Multiple)可以用公式算出:
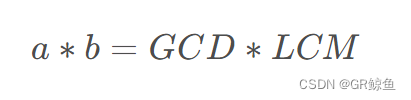
1.2 裴蜀定理ax+by=gcd(a,b)
裴蜀定理:对于整数 a 和 b,存在整数 x 和 y,使得:ax+by=gcd(a,b)
-
推论:方程 ax+by=c 有整数解,当且仅当 c 是 gcd(a,b)的倍数。
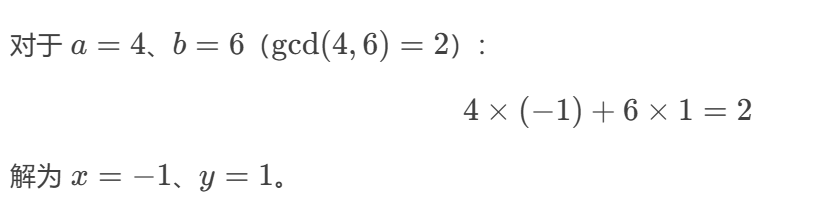
1.3 扩展欧几里得算法exgcd
标准欧几里得算法(辗转相除法)可以计算两个数的最大公约数。
而扩展欧几里得算法不仅能计算 gcd(a,b),还能找到整数 x 和 y,使得:a⋅x+b⋅y=gcd(a,b)
这个等式称为裴蜀定理(Bézout's Identity),而扩展欧几里得算法就是用来求解这个方程的整数解 (x,y) 的。
int exgcd(int a, int b, int &x, int &y) // 参数:a, b 为输入,x, y 为引用传递(用于返回解)
{
if (b == 0) // 递归终止条件:当 b=0 时,gcd(a,0)=a,此时 x=1, y=0
{
x = 1;
y = 0;
return a;
}
int gcd = exgcd(b, a % b, y, x); // 递归调用,交换 x 和 y 的位置
y -= (a / b) * x; // 更新 y 的值
return gcd; // 返回 gcd(a, b)
}关键点:

2. 判定素数和线性筛素数
定义:质数(素数)是指在大于 1 的自然数中,除了 1 和它本身以外不再有其他因数的自然数。素数首先满足条件是要 大于等于 2。例如 2、3、5、7 等都是素数。
2.1 试除法判定素数
根据定义判断 n 是否为素数:若区间 [2,n−1][中存在能整除 n 的数,则 n是合数;否则为素数。时间复杂度:O(n)。
a 是 n 的因数(即 a ∣ n),则 n/a 也必定是 n 的因数。若设 a ≤ n/a ,则有: a² ≤ n ⇒ a ≤ √n
因此,只需在区间 [2, ⌊√n⌋] 内检查是否有因数即可。时间复杂度优化为: O(√n)
示例代码(C++):
bool is_prime(int n)
{
for (int i = 2; i <= sqrt(n); i++)
{
if (0 == n % i)
{
return false;
}
}
return true;
}2.2 筛法(埃氏筛)
基本思路:
-
正向思维:传统方法是判断每个数
x是否为素数(检查是否有因子)。 -
逆向思维:用已知素数去标记其倍数为非素数,剩下的未被标记的数即为素数。
实现步骤需要两个数组:
-
primes数组:存储所有找到的素数 -
st数组(标记数组):st[i]=true表示i是合数,初始为false
看下面代码,由于全局变量未初始化时默认值为0,因此st[2]=0(表示2是素数)。程序会通过if判断将i=2加入primes数组,随后标记2的所有倍数(如4、6、8等)为true(即非素数)。当第一层循环遍历到4时,由于st[4]=true,if判断不会通过,因此4不会被当作素数处理。若某个数始终未被标记过(即st[x]=0),则说明它没有比自身小的因数,从而被确认为质数。
int primes[N], cnt; // primes存储素数,cnt为素数个数
bool st[N]; // st[i] = true表示i是合数
void get_primes(int n)
{
for (int i = 2; i <= n; i++)
{
if (!st[i]) // 若i是素数
{
primes[cnt++] = i; // 加入素数数组
for (int j = i + i; j <= n; j += i)
{
st[j] = true; // 标记i的所有倍数为合数
}
}
}
}示例演示(n=10):
| 当前i | 操作 | primes数组 | 被筛除的合数 |
|---|---|---|---|
| 2 | 加入素数,标记4,6,8,10 | [2] | 4,6,8,10 |
| 3 | 加入素数,标记6,9 | [2,3] | 6,9 |
| 4 | 已被标记为合数,跳过 | 不变 | 无 |
| 5 | 加入素数,标记10 | [2,3,5] | 10 |
| 6-10 | 均被标记为合数,跳过 | 最终结果:[2,3,5,7] | 无 |
筛选 n 以内的素数用试除法的时间复杂度约为 O(n^{1.5}),远高于埃氏筛法的 O(n log log n)。
但埃氏筛法有一个问题,比如6被2标记,也被3标记,浪费了很多时间。
| n | logn以2为底) | loglogn | nlogn | nloglogn |
|---|---|---|---|---|
| 2^16 | 16 | 4 | 16n | 4n |
| 2^256 | 256 | 8 | 256n | 8n |
| 2^1024 | 1024 | 10 | 1024n | 10n |
nloglogn 的值远小于 nlogn,且差距随着 n 的增大急剧扩大。
这时就用到了欧拉线性筛。
2.3 筛法(欧拉筛/线性筛)
线性筛法(又称欧拉筛)是一种高效生成素数的算法,时间复杂度为O(n),能够快速筛选出从2到n之间的所有素数。相比传统的埃拉托斯特尼筛法(时间复杂度O(n log log n)),线性筛法的效率更高。
线性筛法的关键在于:每个合数只被它的最小质因数筛掉一次。这样就避免了重复筛选,提高了效率。
int primes[N], cnt; // primes存储素数,cnt为素数个数
bool st[N]; // st[i] = true表示i是合数
void get_primes(int n) // 线性筛法求n以内的所有素数
{
for (int i = 2; i <= n; i++)
{
if (!st[i]) // 如果i未被筛除(i是素数)
{
primes[cnt++] = i; // 将i加入素数数组
// primes[0]=2, primes[1]=3, primes[2]=5...
}
for (int j = 0; primes[j] <= n / i; j++) // 用当前素数primes[j]筛除合数
{
st[primes[j] * i] = 1; // 筛除primes[j]的i倍数
// 示例:i=2时:st[4]=1, i=3时:st[6]=1, st[9]=1...
if (i % primes[j] == 0) // 保证每个合数只被最小质因子筛除
{
break; // 关键优化:当i能被primes[j]整除时立即终止内层循环
}
}
}
}primes[j] <= n / i 可以理解为 primes[j] * i <= n,但乘法可能整数溢出,所以写除法。
示例分析(n=10):
i | n/i | 有效的 primes[j] 范围 | 实际筛除的合数 |
|---|---|---|---|
| 2 | 5 | primes[j] ≤ 5(2,3,5) | 4(2×2)、6(2×3)、10(2×5) |
| 3 | 3 | primes[j] ≤ 3(2,3) | 6(2×3)、9(3×3) |
| 4 | 2 | primes[j] ≤ 2(2) | 8(2×4) |
| 5 | 2 | primes[j] ≤ 2(2) | 10(2×5) |
| 筛法类型 | 时间复杂度 | 核心特点 |
|---|---|---|
| 埃氏筛 | O(n log log n) | 标记所有倍数 |
| 欧拉筛(线性筛) | O(n) | 每个合数仅被最小质因数标记一次 |
关键点解析:
-
素数判断:
if (!st[i])判断i是否为素数,如果是就加入primes数组 -
筛除合数:对于每个数i,用已知的素数primes[j]来筛除合数primes[j]*i
-
关键优化:
if (i % primes[j] == 0) break确保:-
每个合数只被它的最小质因数筛除
-
避免重复筛除,保证O(n)的时间复杂度
-
示例演示(n=10):
| 当前i | 操作 | primes数组 | 被筛除的合数 |
|---|---|---|---|
| 2 | 加入素数 | [2] | 4 |
| 3 | 加入素数 | [2,3] | 6,9 |
| 4 | 筛除合数 | [2,3] | 8(被2筛除) |
| 5 | 加入素数 | [2,3,5] | 10 |
| 6-10 | 筛除合数 | [2,3,5,7] | 无新筛除 |
最终结果:primes = [2, 3, 5, 7]
上面表格看起来6是被3筛除的,6的最小质因数不是2吗,实际是下面这样的:
当前 i | 操作 | primes 数组 | 具体筛除操作 | 最小质因子验证 |
|---|---|---|---|---|
| 2 | 加入素数 2 | [2] | 2*2=4 | 4 → 2 |
| 3 | 加入素数 3 | [2,3] | 2*3=6,3*3=9 | 6 → 2,9 → 3 |
| 4 | 跳过(合数) | [2,3] | 2*4=8(break) | 8 → 2 |
| 5 | 加入素数 5 | [2,3,5] | 2*5=10 | 10 → 2 |
| 6-10 | 跳过(合数或超范围) | [2,3,5,7] | 无 | —— |
为什么是线性的?:
-
每个合数只会被它的最小质因数筛除一次
-
每个数i都会遍历所有primes[j]≤i的素数
-
内层循环的break确保了不重复筛除
适用场景:
-
需要一次性获取大量素数(如n≤10^7)
-
算法竞赛中需要快速预处理素数
-
需要同时获取素数表和最小质因数表
3. 欧拉函数
3.1 欧拉函数的概念
欧拉函数 φ(n) 表示:小于等于 n 的正整数中,与 n 互质的数的个数。
-
互质:两个数的最大公约数是 1(比如 3 和 5 互质,但 4 和 6 不互质)。
-
示例:
-
φ(5) = 4(1, 2, 3, 4 都与 5 互质)。
-
φ(6) = 2(只有 1, 5 与 6 互质)。
-
3.2 欧拉函数的计算原理
欧拉函数的公式:
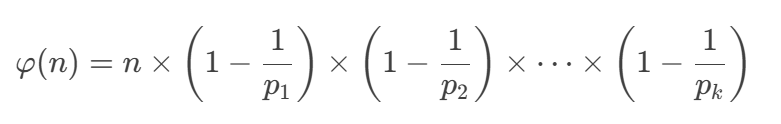
其中 p1,p2,…,pk是 n 的所有不同质因数。
为什么这样算?
-
假设
n的质因数是p,那么所有p的倍数(如p, 2p, 3p, ...)都不与n互质。 -
公式中
(1 - 1/p)表示去掉这些不互质的数。
例子:计算 φ(12)
-
12 的质因数:2, 3。
-
φ(12) = 12 × (1 - 1/2) × (1 - 1/3) = 12 × 0.5 × 0.666... = 4。
-
验证:1, 5, 7, 11 与 12 互质,确实是 4 个。
3.3 欧拉函数的代码
int phi(int x)
{
int res = x; // 初始化为x
for (int i = 2; i <= x / i; i++) // 枚举所有可能的质因数i
{
if (x % i == 0) // 如果i是x的质因数
{
res = res / i * (i - 1); // 套用欧拉公式
while (x % i == 0)
{
x /= i; // 去掉x中所有的i因子
}
}
}
if (x > 1)
res = res / x * (x - 1); // 处理剩余的最后一个质因数
return res;
}代码步骤:
-
初始化:
res = x(假设所有数都与x互质)。 -
分解质因数:
-
找到
x的一个质因数i。 -
更新
res:res = res / i * (i - 1)(即乘以(1 - 1/i))。 -
去掉
x中所有i的因子(while (x % i == 0) x /= i)。
-
-
处理最后一个质因数:如果剩下的
x > 1,说明它本身是质数,也要参与计算。
示例:计算 φ(12)
-
i=2:res = 12 / 2 * (2-1) = 6,x变成 3。 -
i=3:res = 6 / 3 * (3-1) = 4,x变成 1。 -
结果:φ(12) = 4。
代码为什么这样写?
-
i <= x / i:优化质因数分解,只需检查i ≤ √x(因为大于√x的因数一定是未被除尽的质数)。 -
res / i * (i - 1):避免浮点数运算,用整数除法保证精度。 -
while (x % i == 0):确保每个质因数只处理一次。
欧拉函数的用途:
-
密码学:RSA 加密算法中用到 φ(n)。
-
数论问题:如欧拉定理(若
a与n互质,则a^φ(n) ≡ 1 mod n)。 -
算法竞赛:快速计算模运算或组合数学问题。
3.4 线性筛欧拉函数
线性筛法求欧拉函数的优势
-
传统方法:对每个数单独计算 φ(n),时间复杂度高(O(n√n))。
-
线性筛法:在筛素数的同时计算 φ(n),时间复杂度 O(n),效率极高。
代码:(花括号对齐就太高了,所以格式就这样了)
int prime[1000010], phi[1000010], cnt = 0; // prime存素数,phi存欧拉函数值
bool vis[10000010]; // vis标记是否为合数
void Euler(int n) {
for (int i = 2; i <= n; i++) {
if (!vis[i]) { // i是素数
prime[++cnt] = i; // 存入素数表
phi[i] = i - 1; // 性质1:素数p的φ(p)=p-1
}
for (int j = 1; j <= cnt; j++) { // 用已得素数筛除合数
if (i * prime[j] > n) break; // 超过范围则终止
vis[i * prime[j]] = 1; // 标记合数
if (i % prime[j] == 0) { // 关键性质2
phi[i * prime[j]] = prime[j] * phi[i];
break;
} else { // 性质3:积性函数
phi[i * prime[j]] = phi[i] * (prime[j] - 1);
}
}
}
}核心性质与证明
性质1:素数的欧拉函数
-
φ(p) = p - 1(
p是素数)。
解释:素数的定义是只有 1 和自身两个因数,因此 1 到 p-1 都与 p 互质。
性质2:i 能被 prime[j] 整除时
-
若
i % prime[j] == 0,则 φ(i×prime[j]) = prime[j] × φ(i)。
证明:
设i包含prime[j]的幂次,即i = prime[j]^k × m(m与prime[j]互质)。
根据欧拉函数公式:
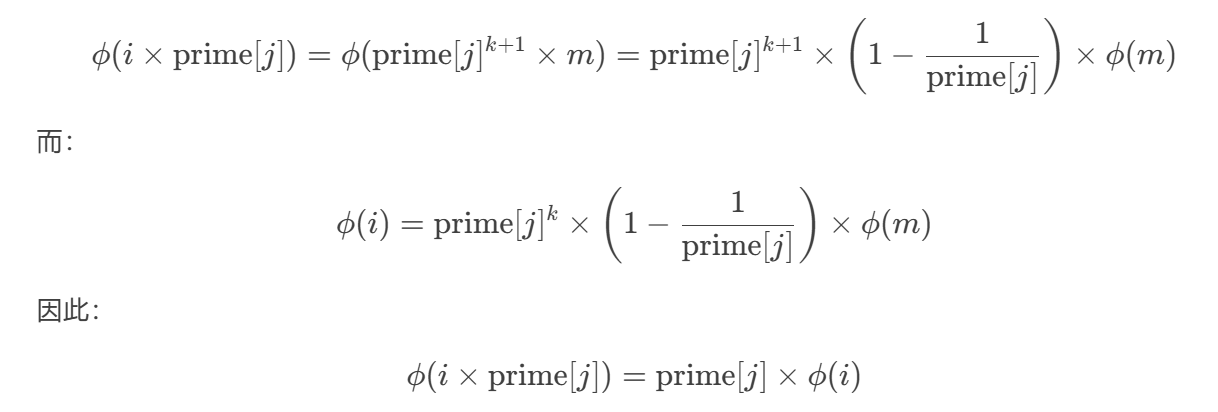
性质3:i 与 prime[j] 互质时
-
若
i % prime[j] ≠ 0,则 φ(i×prime[j]) = φ(i) × (prime[j] - 1)。
解释:
因为i和prime[j]互质,欧拉函数是积性函数,直接相乘即可。
示例演示(n=6)
i | 操作 | prime 数组 | phi 值变化 | 说明 |
|---|---|---|---|---|
| 2 | 发现素数2,φ(2)=1 | [2] | phi[2]=1 | 性质1 |
| 3 | 发现素数3,φ(3)=2 | [2,3] | phi[3]=2 | 性质1 |
| 4 | 4=2×2,φ(4)=2×φ(2)=2 | [2,3] | phi[4]=2 | 性质2(i=2, prime[j]=2) |
| 5 | 发现素数5,φ(5)=4 | [2,3,5] | phi[5]=4 | 性质1 |
| 6 | 6=2×3,φ(6)=φ(3)×(2-1)=2 | [2,3,5] | phi[6]=2 | 性质3(i=3, prime[j]=2) |
为什么能线性时间完成?
-
每个合数只被筛一次:通过
if (i % prime[j] == 0) break确保。 -
欧拉函数同步计算:利用已计算的
phi[i]递推新值,避免重复计算。
3.5 欧拉定理与费马小定理
同余关系:在数论中表示模意义下的等价(如 5≡2(mod3))。
示例:
-
7≡2(mod5)(因为 7−2=5 被 5 整除)。
-
10≡1(mod3)因为 10−1=9 被 3 整除)。

欧拉定理(Euler's Theorem):

费马小定理(Fermat's Little Theorem)

4. 快速幂
快速幂是一种高效计算大数幂运算的算法,尤其适用于指数极大或需要取模的场景。其核心思想是通过指数分解和平方累乘,将时间复杂度从暴力计算的 O(N)降至 O(log N))。
4.1 快速幂算法原理
1. 二进制分解法
将指数 n 转换为二进制形式,逐位处理每一位的权值。例如:
11 的二进制为 1011,对应 2^3+2^1+2^0,因此 a^11=a^8×a^2×a^1。
-
核心步骤:
-
若当前二进制位为
1,将当前底数累乘到结果。 -
每次处理后将底数平方,指数右移一位。
-
2. 二分分治法
当指数为偶数时,将幂运算拆分为两个子问题;为奇数时,先分离出一个底数再拆分。例如:2^10=(2^5)^2=(2×2^4)^2,递归直至指数为 0。
4.2 快速幂代码实现
1. 迭代法(二进制分解)
typedef long long ll;
ll fast_pow(ll a, ll n, ll mod)
{
ll res = 1 % mod; // 初始化结果,防止mod=1时出错
a %= mod; // 预处理底数,防止溢出
while (n > 0)
{
if (n & 1) // 如果是基数
res = res * a % mod; // 当前位为1,累乘底数
a = a * a % mod; // 底数平方
n >>= 1; // (除2)右移一位,处理下一位
}
return res;
}2. 递归法(二分分治)
typedef long long ll;
ll fast_pow_recursive(ll a, ll n, ll mod)
{
if (n == 0)
return 1 % mod;
ll half = qpow_recursive(a, n / 2, mod) % mod;
ll res = half * half % mod; // 偶数情况
if (n % 2 == 1)
res = res * a % mod; // 奇数情况
return res;
}5. 逆元
逆元是数论中的重要概念,用于解决模运算下的“除法”问题。
5.1 逆元的定义
逆元的定义:

5.2 费马小定理求逆元

根据费马小定理, a 的逆元是 a^(p−2) mod p。
a^(p−2) mod p用快速幂求得即可:
typedef long long ll;
ll fast_pow(ll a, ll n, ll mod)
{
ll res = 1 % mod; // 初始化结果,防止mod=1时出错
a %= mod; // 预处理底数,防止溢出
while (n > 0)
{
if (n & 1) // 如果是基数
res = res * a % mod; // 当前位为1,累乘底数
a = a * a % mod; // 底数平方
n >>= 1; // (除2)右移一位,处理下一位
}
return res;
}
ll get_inv(ll x, ll p)
{
if (x % p == 0) return -1; // x是p的倍数时,逆元不存在
return fast_pow(x, p - 2, p); // 直接调用快速幂
}5.3 exgcd求逆元(通用方法)
扩展欧几里得算法(Extended Euclidean Algorithm)不仅能计算两个数的最大公约数(GCD),还能求解形如a⋅x+m⋅y=gcd(a,m)的整数解 (x,y)。
当 gcd(a,m)=1,方程变为a⋅x+m⋅y=1。
此时,x 即为 a 在模 m 下的逆元 a−1,因为:a⋅x≡1(mod m)
#include <iostream>
using namespace std;
int exgcd(int a, int b, int &x, int &y)
{
if (b == 0)
{
x = 1;
y = 0;
return a;
}
int gcd = exgcd(b, a % b, y, x);
y -= (a / b) * x;
return gcd;
}
int inverse(int a, int m)
{
int x, y;
int gcd = exgcd(a, m, x, y);
if (gcd != 1) // 逆元不存在的条件
return -1;
else // 调整x为正数
return (x % m + m) % m;
}
int main()
{
int a = 3, m = 5;
int inv = inverse(a, m);
if (inv == -1)
cout << "逆元不存在" << endl;
else
cout << a << " 在模 " << m << " 下的逆元是: " << inv << endl;
return 0;
}示例详解:

6. 数论其它知识_本篇完
数论其它知识比如逆序对,排列组合,之前的算法专栏也有介绍,可以点链接过去看看:
Offer必备算法10_分治归并_四道力扣题详解(由易到难)_力扣分治题-优快云博客
Offer必备算法31_DFS回溯剪枝_九道力扣题详解(由易到难)_力扣dfs经典题-优快云博客
本篇完。


















 1370
1370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











