




回顾昨天的一些填充缺失值方法
fillna()是填补缺失值的核心函数,下面是一些常用的统计函数
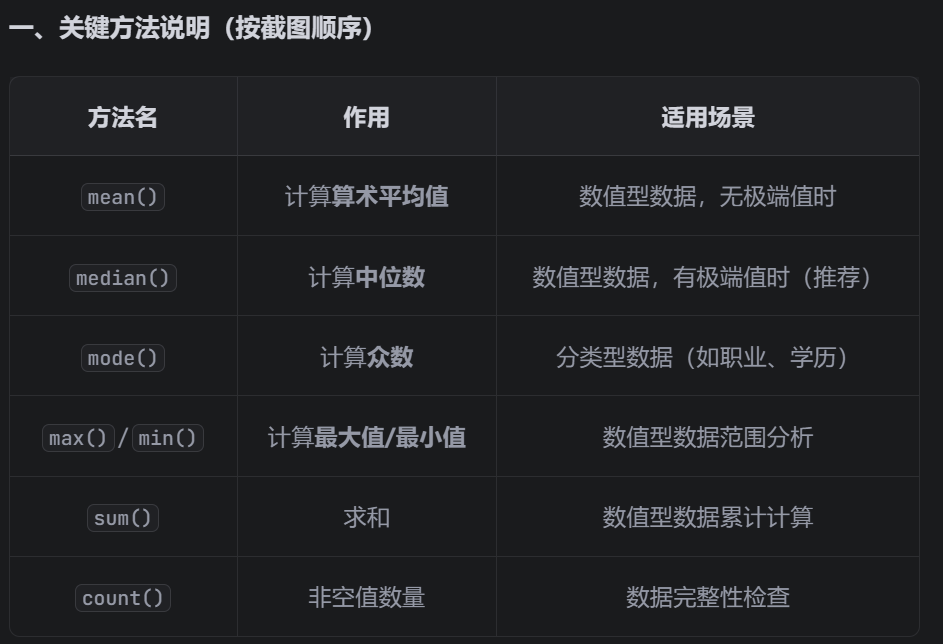
填补缺失值时,对数值型数据用中位数填补,用median()方法;填补分类型数据时,用众数填补,用mode()方法。
一些转换为列表的方法
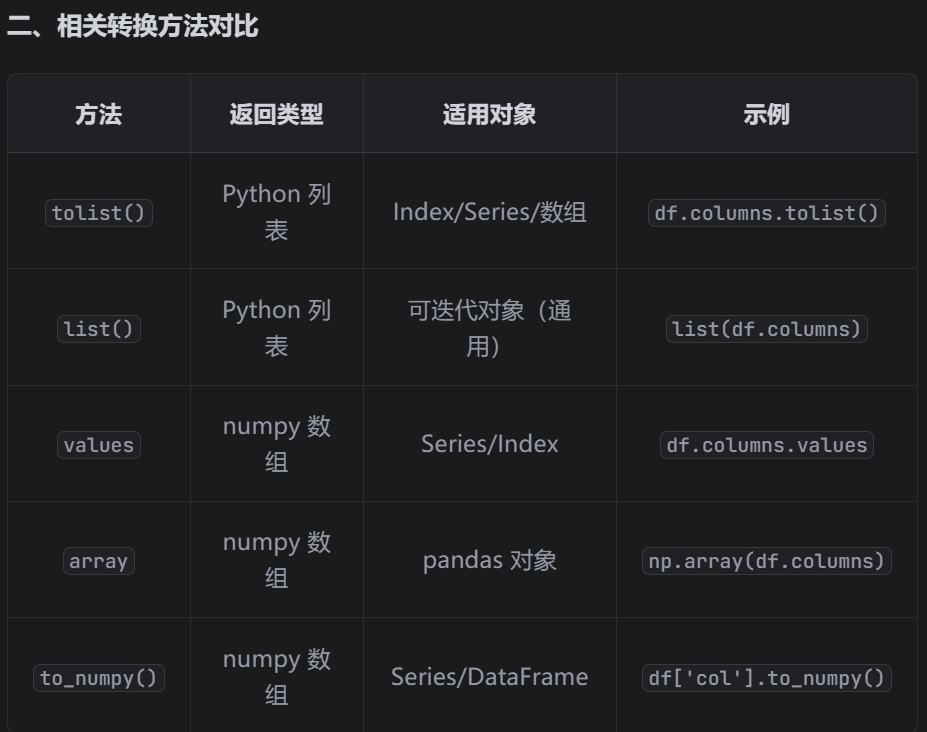
只遍历有缺失值的列,用循环填补
# 循环来遍历每一列,判断数据类型,数值型列用中位数填补,分类型列用众数填补。
# 因为前面处理发现有缺失的列不是很多,所以考虑在遍历的时候只去遍历有缺失值的列,可以减少不必要的内存消耗
missing_cols = data_csv.columns[data_csv.isnull().sum()>0]
print(f'需要处理的有缺失值的列:{missing_cols.tolist()}')
for column in missing_cols:
if data_csv[column].dtype in ['float64','int64']:
data_csv[column] = data_csv[column].fillna(data_csv[column].median)
else:
mode_val = data_csv[column].mode()
if not mode_val.empty:
data_csv[column] = data_csv[column].fillna(mode_val[0])
else:
data_csv[column] = data_csv[column].fillna(' ')
print('填补后的空值数量:\n',data_csv.isnull().sum())
需要处理的有缺失值的列:[]
填补后的空值数量:
Id 0
Home Ownership 0
Annual Income 0
Years in current job 0
Tax Liens 0
Number of Open Accounts 0
Years of Credit History 0
Maximum Open Credit 0
Number of Credit Problems 0
Months since last delinquent 0
Bankruptcies 0
Purpose 0
Term 0
Current Loan Amount 0
Current Credit Balance 0
Monthly Debt 0
Credit Score 0
Credit Default 0
dtype: int64正式开始今天的内容学习
今天的任务分成以下几步
1. 读取数据
2. 找到所有离散特征
# 1. 读取数据
import pandas as pd
data = pd.read_csv(r'data.csv')
print(data.columns)
# 2. 找到所有离散特征,为了便于后面对每个离散特征进行独热编码处理,用列表存储离散特征
# 需要先初始化一个空列表,不然就是字符串类型,这个要注意
discrete_feature = []
for feature in data.columns:
if data[feature].dtype == 'object':
discrete_feature.append(feature)
print(feature)
print(type(discrete_feature))
Index(['Id', 'Home Ownership', 'Annual Income', 'Years in current job',
'Tax Liens', 'Number of Open Accounts', 'Years of Credit History',
'Maximum Open Credit', 'Number of Credit Problems',
'Months since last delinquent', 'Bankruptcies', 'Purpose', 'Term',
'Current Loan Amount', 'Current Credit Balance', 'Monthly Debt',
'Credit Score', 'Credit Default'],
dtype='object')
Home Ownership
Years in current job
Purpose
Term
<class 'list'>3. 选择一个离散特征进行独热编码
对离散特征进行编码通常分为两种情况,一种是变量之间有顺序关系,称为定序变量;另一种是没有任何等级顺序关系的变量
可以通过标签编码定序变量
对于无任何顺序关系的变量可以进行,独热编码,就是用01矩阵来表示离散特征,如果有k个类别,那么只需要给出k-1个类别的二进制编码,那么就对所有类别完成了编码
`value_counts()`` 是pandas Series的一个方法,用于统计每个唯一值出现的次数,返回一个按降序排列的Series。这对了解数据分布非常重要,尤其是在处理分类数据时。
将分类数据转换为数值型,比如独热编码。在进行编码之前,了解每个类别的分布情况很关键,因为这会影响后续的处理方式。例如,如果某个类别占比过高,可能需要特殊处理,或者确认是否存在不平衡数据的问题。
接下来,我需要解释为什么要使用这个方法。主要原因包括:1. 了解数据分布,判断是否需要合并稀有类别;2. 检查是否有异常值或缺失值;3. 为特征工程提供依据,比如决定是否使用独热编码或其他编码方式。
# 3. 选择一个离散特征进行独热编码
print('选择的离散特征为:',discrete_feature[0])
print(data[discrete_feature[0]])
print(data[discrete_feature[0]].value_counts())
Home Ownership
Home Mortgage 3637
Rent 3204
Own Home 647
Have Mortgage 12
Name: count, dtype: int64发现不是顺序类别,没有什么关联
按理应该考虑一下这边数据的实际意义来去判断是否需要合并稀有类别,不过不太清楚背景,就先不进行额外的操作,先熟悉如何进行独热编码的操作即可
if discrete_feature and len(discrete_feature)>0:
data = pd.get_dummies(data,columns = [discrete_feature[0]],prefix=discrete_feature[0],drop_first=True)
# drop_first=True 可避免多重共线性
print("独热编码后的前5行数据:\n", data.head())
else:
print("离散特征列表为空,无法进行独热编码")
print(data.columns)
独热编码后的前5行数据:
Id Annual Income ... Home Ownership_Own Home Home Ownership_Rent
0 0 482087.0 ... True False
1 1 1025487.0 ... True False
2 2 751412.0 ... False False
3 3 805068.0 ... True False
4 4 776264.0 ... False True
[5 rows x 20 columns]
Index(['Id', 'Annual Income', 'Years in current job', 'Tax Liens',
'Number of Open Accounts', 'Years of Credit History',
'Maximum Open Credit', 'Number of Credit Problems',
'Months since last delinquent', 'Bankruptcies', 'Purpose', 'Term',
'Current Loan Amount', 'Current Credit Balance', 'Monthly Debt',
'Credit Score', 'Credit Default', 'Home Ownership_Home Mortgage',
'Home Ownership_Own Home', 'Home Ownership_Rent'],
dtype='object')输出的bool类型要转化为int类型,为了便于后续的一些运算
类型转换的常用方法如下:
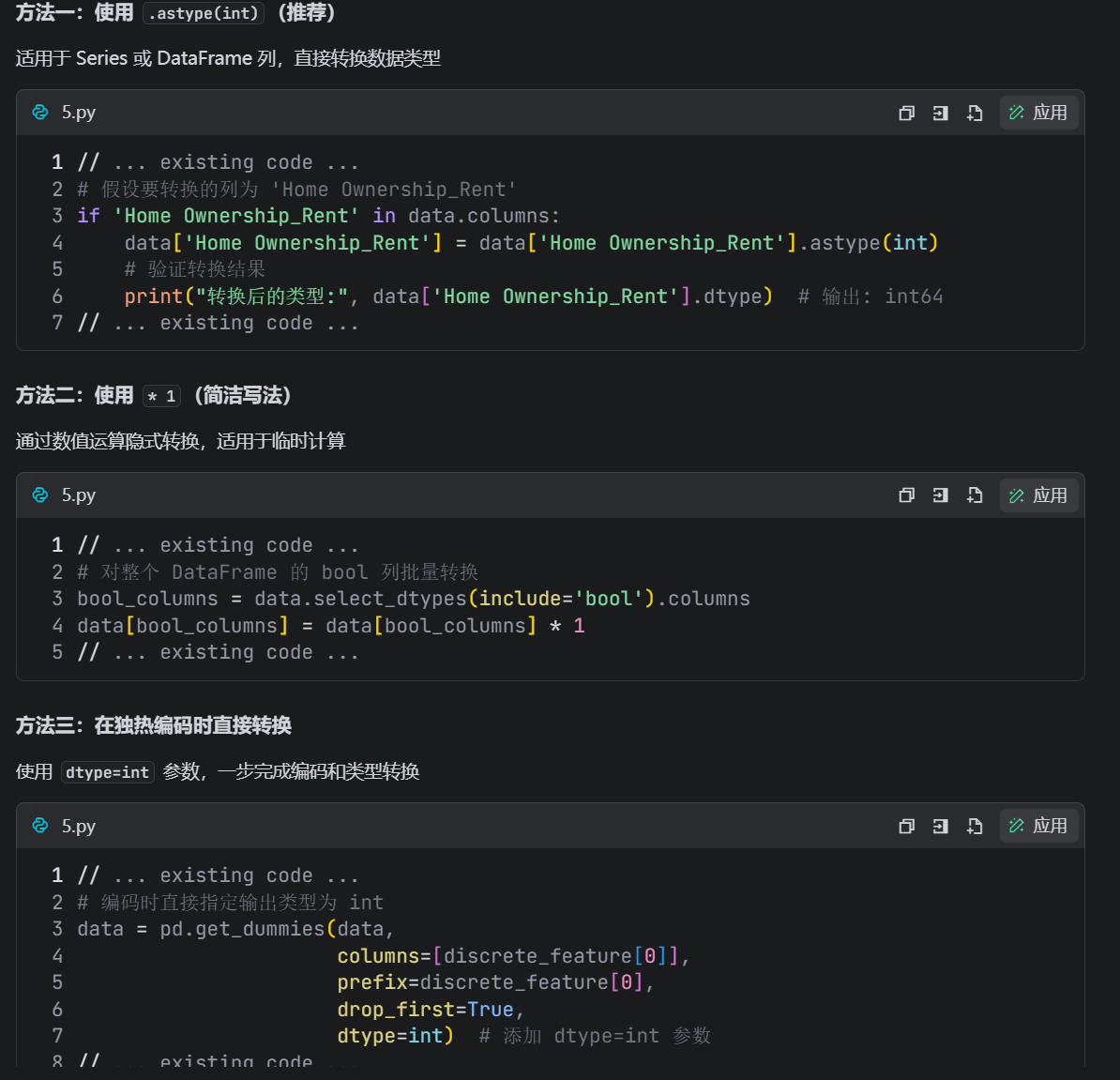
显然2是不推荐使用的,为了方便,我在这边使用方法3。更改后代码如下,完成了类型转换
if discrete_feature and len(discrete_feature)>0:
data = pd.get_dummies(data,columns = [discrete_feature[0]],prefix=discrete_feature[0],drop_first=True,dtype=int)
# drop_first=True 可避免多重共线性
print("独热编码后的前5行数据:\n", data.head())
else:
print("离散特征列表为空,无法进行独热编码")
print(data.columns)
独热编码后的前5行数据:
Id ... Home Ownership_Rent
0 0 ... 0
1 1 ... 0
2 2 ... 0
3 3 ... 0
4 4 ... 1
[5 rows x 20 columns]
Index(['Id', 'Annual Income', 'Years in current job', 'Tax Liens',
'Number of Open Accounts', 'Years of Credit History',
'Maximum Open Credit', 'Number of Credit Problems',
'Months since last delinquent', 'Bankruptcies', 'Purpose', 'Term',
'Current Loan Amount', 'Current Credit Balance', 'Monthly Debt',
'Credit Score', 'Credit Default', 'Home Ownership_Home Mortgage',
'Home Ownership_Own Home', 'Home Ownership_Rent'],
dtype='object')4. 采取循环对所有离散特征进行独热编码
因为第一个离散特征已经处理过了,在后面进行全部处理的时候,会因为已经被处理过而发生报错,需要把前面第三步的操作注释掉
# 前面已经将离散特征存储在列表中了,现在只需进行独热编码操作即可,因为get_dummies本身支持传入多个列名,所以无需循环操作,函数内部本身就有
if discrete_feature and len(discrete_feature)>0:
data = pd.get_dummies(data,columns = discrete_feature,prefix=discrete_feature,drop_first=True,dtype=int)
# drop_first=True 可避免多重共线性
print("独热编码后的前5行数据:\n", data.head())
else:
print("离散特征列表为空,无法进行独热编码")
print("编码后的所有列名:\n", data.columns.tolist())
独热编码后的前5行数据:
Id Annual Income Tax Liens ... Purpose_vacation Purpose_wedding Term_Short Term
0 0 482087.0 0.0 ... 0 0 1
1 1 1025487.0 0.0 ... 0 0 0
2 2 751412.0 0.0 ... 0 0 1
3 3 805068.0 0.0 ... 0 0 1
4 4 776264.0 0.0 ... 0 0 1
[5 rows x 42 columns]
编码后的所有列名:
['Id', 'Annual Income', 'Tax Liens', 'Number of Open Accounts', 'Years of Credit History', 'Maximum Open Credit', 'Number of Credit Problems', 'Months since last delinquent', 'Bankruptcies', 'Current Loan Amount', 'Current Credit Balance', 'Monthly Debt', 'Credit Score', 'Credit Default', 'Home Ownership_Home Mortgage', 'Home Ownership_Own Home', 'Home Ownership_Rent', 'Years in current job_10+ years', 'Years in current job_2 years', 'Years in current job_3 years', 'Years in current job_4 years', 'Years in current job_5 years', 'Years in current job_6 years', 'Years in current job_7 years', 'Years in current job_8 years', 'Years in current job_9 years', 'Years in current job_< 1 year', 'Purpose_buy a car', 'Purpose_buy house', 'Purpose_debt consolidation', 'Purpose_educational expenses', 'Purpose_home improvements', 'Purpose_major purchase', 'Purpose_medical bills', 'Purpose_moving', 'Purpose_other', 'Purpose_renewable energy', 'Purpose_small business', 'Purpose_take a trip', 'Purpose_vacation', 'Purpose_wedding', 'Term_Short Term']5. 加上昨天的内容 并且处理所有缺失值
# 5. 加上昨天的内容 并且处理所有缺失值
data2 = pd.read_csv(r'data.csv')
list_final = list(set(data.columns) - set(data2.columns)) # 集合差集运算,更高效
print(list_final)
print(data.dtypes)
data.isnull().sum()
# 用均值填补缺失值
for i in data.columns:
if data[i].isnull().sum()>0:
data[i] = data[i].fillna(data[i].mean())
print(data.isnull().sum())
['Purpose_vacation', 'Purpose_buy a car', 'Purpose_moving', 'Purpose_educational expenses', 'Years in current job_10+ years', 'Years in current job_2 years', 'Purpose_medical bills', 'Purpose_take a trip', 'Years in current job_8 years', 'Purpose_major purchase', 'Years in current job_3 years', 'Years in current job_4 years', 'Purpose_debt consolidation', 'Purpose_renewable energy', 'Years in current job_9 years', 'Purpose_home improvements', 'Home Ownership_Rent', 'Years in current job_7 years', 'Home Ownership_Home Mortgage', 'Term_Short Term', 'Years in current job_6 years', 'Purpose_wedding', 'Years in current job_< 1 year', 'Purpose_other', 'Purpose_buy house', 'Home Ownership_Own Home', 'Years in current job_5 years', 'Purpose_small business']
Id int64
Annual Income float64
Tax Liens float64
Number of Open Accounts float64
Years of Credit History float64
Maximum Open Credit float64
Number of Credit Problems float64
Months since last delinquent float64
Bankruptcies float64
Current Loan Amount float64
Current Credit Balance float64
Monthly Debt float64
Credit Score float64
Credit Default int64
Home Ownership_Home Mortgage int64
Home Ownership_Own Home int64
Home Ownership_Rent int64
Years in current job_10+ years int64
Years in current job_2 years int64
Years in current job_3 years int64
Years in current job_4 years int64
Years in current job_5 years int64
Years in current job_6 years int64
Years in current job_7 years int64
Years in current job_8 years int64
Years in current job_9 years int64
Years in current job_< 1 year int64
Purpose_buy a car int64
Purpose_buy house int64
Purpose_debt consolidation int64
Purpose_educational expenses int64
Purpose_home improvements int64
Purpose_major purchase int64
Purpose_medical bills int64
Purpose_moving int64
Purpose_other int64
Purpose_renewable energy int64
Purpose_small business int64
Purpose_take a trip int64
Purpose_vacation int64
Purpose_wedding int64
Term_Short Term int64
dtype: object
Id 0
Annual Income 0
Tax Liens 0
Number of Open Accounts 0
Years of Credit History 0
Maximum Open Credit 0
Number of Credit Problems 0
Months since last delinquent 0
Bankruptcies 0
Current Loan Amount 0
Current Credit Balance 0
Monthly Debt 0
Credit Score 0
Credit Default 0
Home Ownership_Home Mortgage 0
Home Ownership_Own Home 0
Home Ownership_Rent 0
Years in current job_10+ years 0
Years in current job_2 years 0
Years in current job_3 years 0
Years in current job_4 years 0
Years in current job_5 years 0
Years in current job_6 years 0
Years in current job_7 years 0
Years in current job_8 years 0
Years in current job_9 years 0
Years in current job_< 1 year 0
Purpose_buy a car 0
Purpose_buy house 0
Purpose_debt consolidation 0
Purpose_educational expenses 0
Purpose_home improvements 0
Purpose_major purchase 0
Purpose_medical bills 0
Purpose_moving 0
Purpose_other 0
Purpose_renewable energy 0
Purpose_small business 0
Purpose_take a trip 0
Purpose_vacation 0
Purpose_wedding 0
Term_Short Term 0
dtype: int64大致掌握流程了,但是还是不太会用debugger
明天试着对项目二的数据进行一下同样的操作

















 273
273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









