




题目:初识pandas库与缺失数据的补全
按照示例代码的要求,去尝试补全信贷数据集中的数值型缺失值
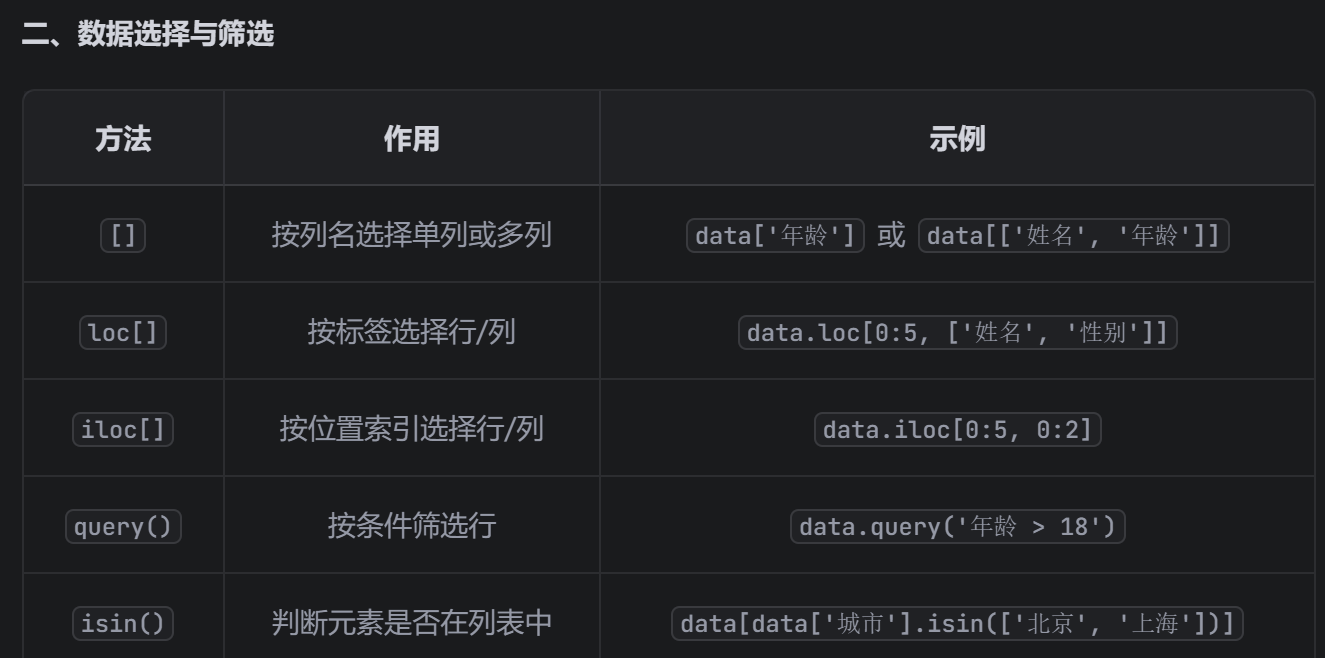
- 打开数据(csv文件、excel文件)
- 查看数据(尺寸信息、查看列名等方法)
- 查看空值
- 众数、中位数填补空值
- 利用循环补全所有列的空值
完成后在py文件中独立完成一遍,并且利用debugger工具来查看属性(不借助函数显式查看)----养成利用debugger工具的习惯
常见的转义字符
#单引号和双引号在功能上是完全等效的,但在字符串本身包含双引号时,使用单引号可以避免使用转义字符
# \n 换行符;\t 制表符; \" 双引号; \' 单引号; \\ 反斜杠本身
# 方法1: 使用双反斜杠转义
path1 = "C:\\Users\\Desktop\\data.csv"
# 方法2: 使用原始字符串(r前缀)
path2 = r"C:\Users\Desktop\data.csv"一、打开数据(csv文件、excel文件)
当使用 pd.read_excel() 读取 .xlsx 文件时,pandas 需要 openpyxl 库的支持。记得提前安装
import pandas as pd
data_csv = pd.read_csv(r'data.csv')
#单引号和双引号在功能上是完全等效的,但在字符串本身包含双引号时,使用单引号可以避免使用转义字符
data_xlsx = pd.read_excel(r'data.xlsx')二、查看数据(尺寸信息、查看列名等方法)
DataFrame类型常用的一些方法


用type函数查看数据类型
type(data_csv)
type(data_xlsx)
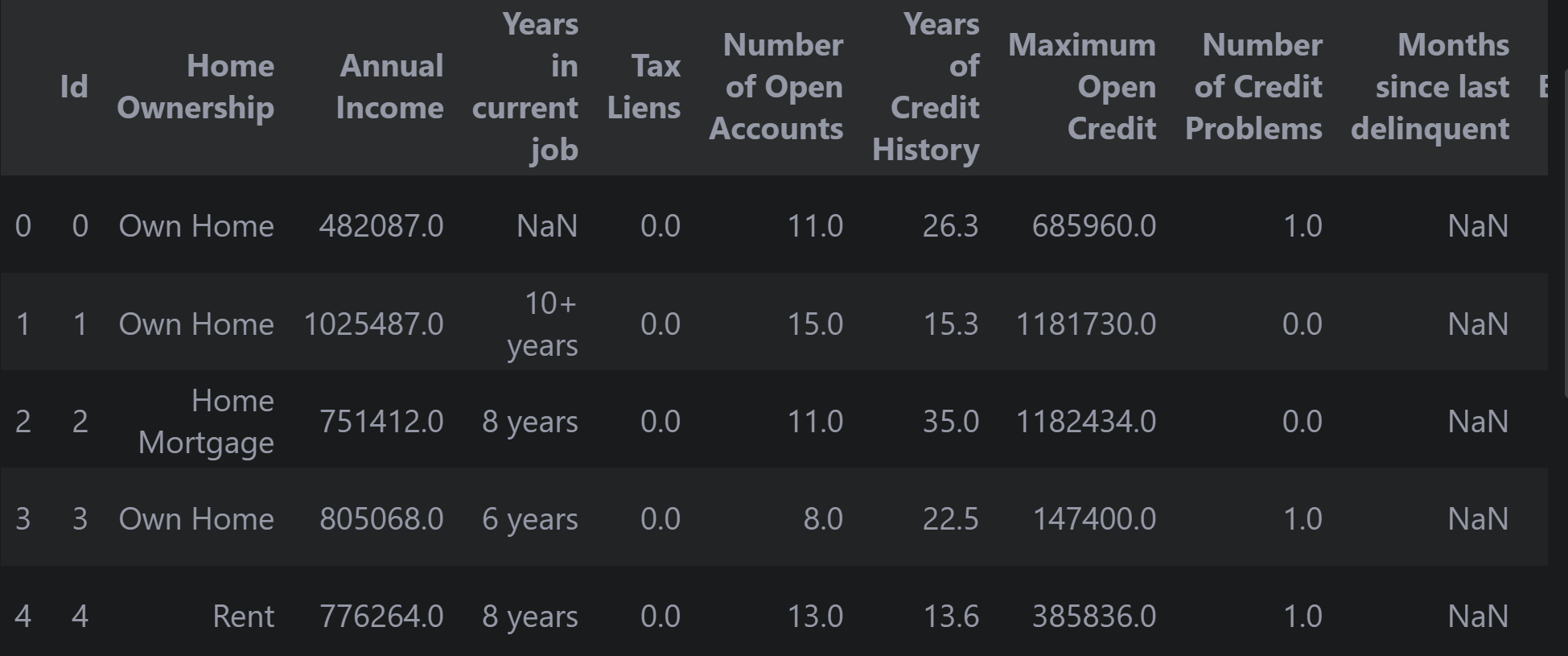
pandas.core.frame.DataFramedata_csv.head()显示前5行的数据内容,可以对数据有一个大致的了解,去初步看有哪些特征,和标签
# 查看数据尺寸(行数, 列数)
print("数据尺寸:", data_csv.shape)
# 查看列名
print("列名:", data_csv.columns.tolist())
# 查看数据详细信息(包括数据类型和空值情况)
data_csv.info()
# 查看数值型列的统计描述
print("数据统计描述:\n", data_csv.describe())
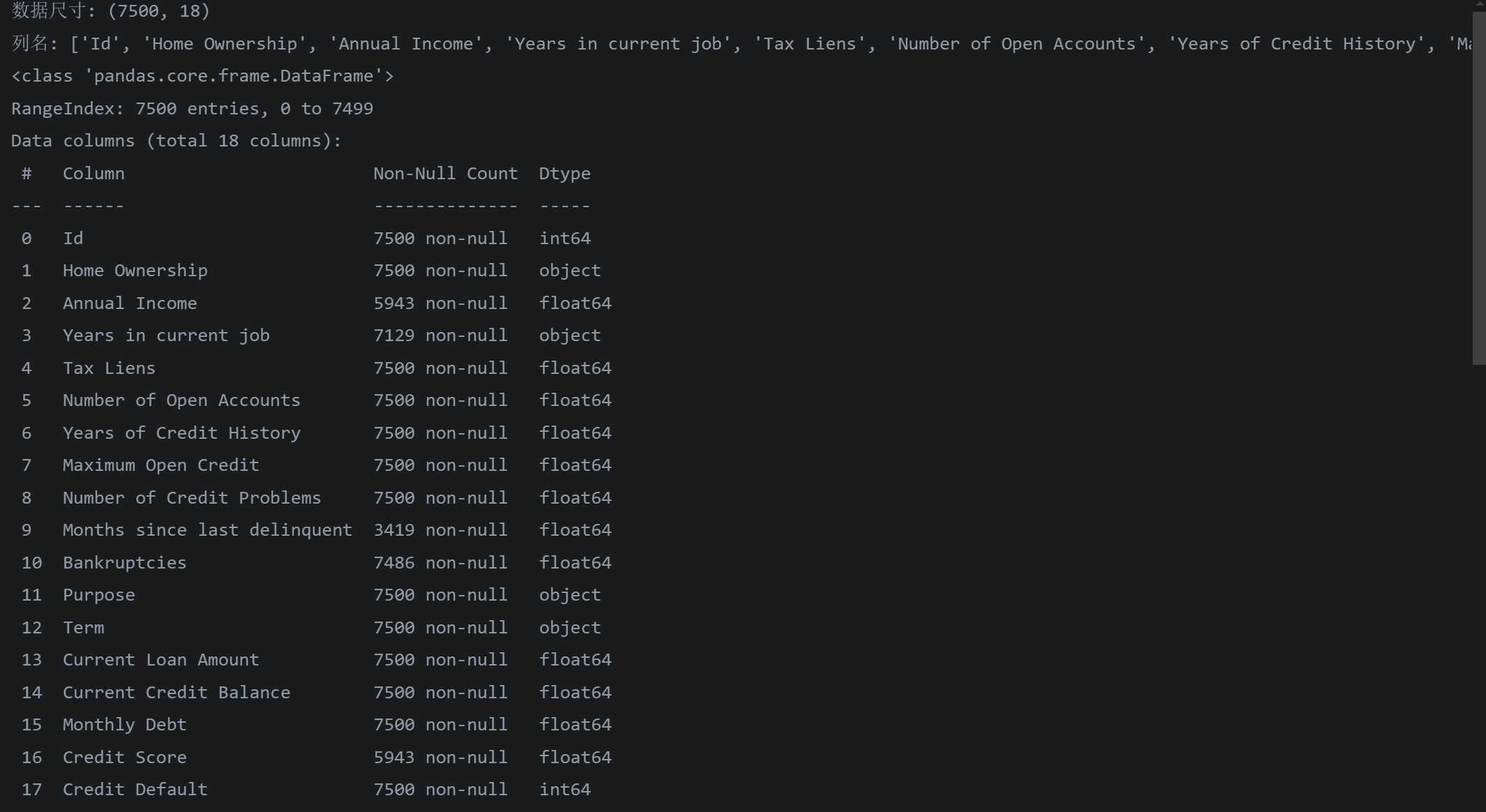
数据处理第一步:
总览缺失值与数据类型情况,发现Annual Income、years in current job、months since last delinquent 、bankruptcies和credit score 这几个特征是有缺失的 ,想办法补全
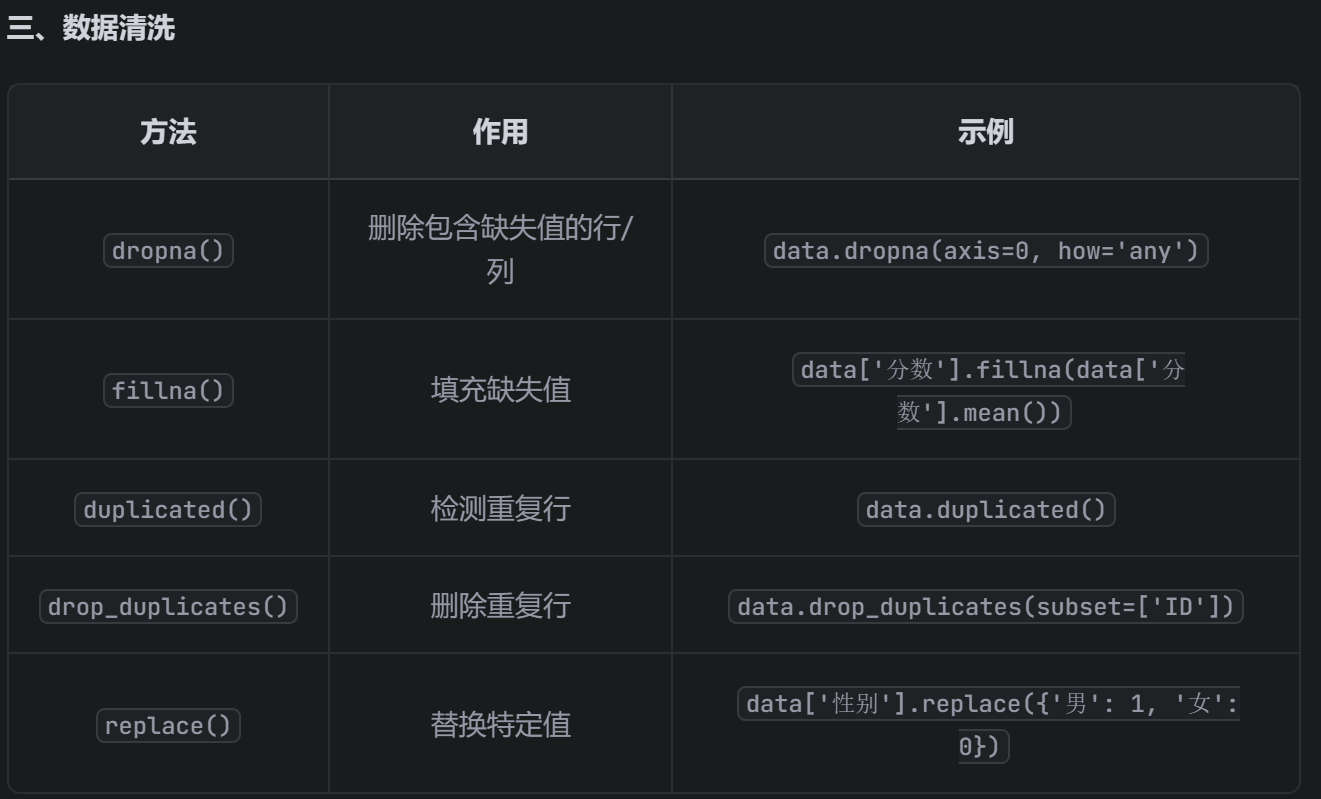
三、查看空值
# 查看每列空值数量
print("每列空值数量:\n", data_csv.isnull().sum())
# 查看空值占比
print("每列空值占比:\n", data_csv.isnull().mean().round(4) * 100)
每列空值数量:
Id 0
Home Ownership 0
Annual Income 1557
Years in current job 371
Tax Liens 0
Number of Open Accounts 0
Years of Credit History 0
Maximum Open Credit 0
Number of Credit Problems 0
Months since last delinquent 4081
Bankruptcies 14
Purpose 0
Term 0
Current Loan Amount 0
Current Credit Balance 0
Monthly Debt 0
Credit Score 1557
Credit Default 0
dtype: int64
每列空值占比:
Id 0.00
Home Ownership 0.00
Annual Income 20.76
Years in current job 4.95
Tax Liens 0.00
Number of Open Accounts 0.00
Years of Credit History 0.00
Maximum Open Credit 0.00
Number of Credit Problems 0.00
Months since last delinquent 54.41
Bankruptcies 0.19
Purpose 0.00
Term 0.00
Current Loan Amount 0.00
Current Credit Balance 0.00
Monthly Debt 0.00
Credit Score 20.76
Credit Default 0.00
dtype: float64四、用众数,中位数填补缺失值
# 示例:填补数值型列(Annual Income)的空值(中位数)
data_csv['Annual Income'] = data_csv['Annual Income'].fillna(data_csv['Annual Income'].median())
# 示例:填补分类型列(Years in current job)的空值(众数)
# 众数可能有多个,取第一个众数[0]
data_csv['Years in current job'] = data_csv['Years in current job'].fillna(data_csv['Years in current job'].mode()[0])五、利用循环补全所有列的空值
# 循环遍历每一列
for column in data_csv.columns:
# 判断列数据类型
if data_csv[column].dtype in ['float64', 'int64']:
# 数值型列:使用中位数填补
data_csv[column].fillna(data_csv[column].median(), inplace=True)
else:
# 分类型列:使用众数填补
# 处理可能没有众数的情况(添加错误处理)
try:
data_csv[column].fillna(data_csv[column].mode()[0], inplace=True)
except IndexError:
# 如果众数不存在(所有值都是NaN),用'Unknown'填充
data_csv[column].fillna('Unknown', inplace=True)
# 验证所有空值是否已填补
print("填补后空值数量:\n", data_csv.isnull().sum())在py文件实践中,会发现有警告出现
这个警告是由于 pandas 中链式赋值结合 inplace=True 导致的潜在问题,主要涉及数据副本与原数据的修改机制。以下是具体解释和解决方案:
### 问题原因
当使用 data_csv[column].fillna(..., inplace=True) 时:
1. 1.
data_csv[column] 会返回原 DataFrame 的 副本 (而非视图)
2. 2.
inplace=True 尝试在这个副本上修改数据, 不会影响原始 DataFrame
3. 3.
pandas 3.0 会明确禁用这种无效操作,因此抛出警告
### 解决方案:移除 inplace=True,改用直接赋值
副本是不会影响原数据的,视图是在原数据的基础上进行修改,那数据处理的时候应该保留数据备份,然后采用直接赋值的形式会更高效一些吧。
明天试着自己敲一下4、5块的循环补充代码


















 1756
1756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









