




项目简介
YAYI 2 是中科闻歌研发的新一代开源大语言模型,中文名:雅意,采用了超过 2 万亿 Tokens 的高质量、多语言语料进行预训练。

开源地址:https://github.com/wenge-research/YAYI2
YAYI2-30B是其模型规模,是基于 Transformer 的大语言模型。拥有300亿参数规模,基于国产化算力支持,数据语料安全可控,模型架构全自主研发。在媒体宣传、舆情感知、政务治理、金融分析等场景具有强大的应用能力。具有语种覆盖多、垂直领域深、开源开放的特点。
中科闻歌 此次开源计划是希望促进中文预训练大模型开源社区的发展,并积极为此做出贡献,共同构建雅意大模型生态。

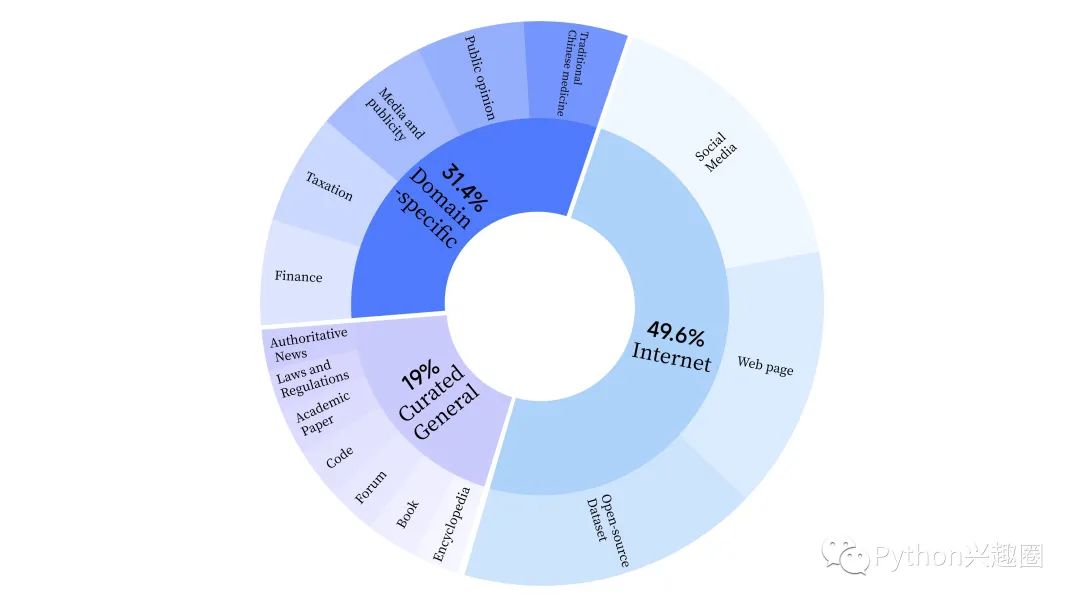
预训练数据
雅意2.0 在预训练阶段,采用了互联网数据来训练模型的语言能力,还添加了通用精选数据和领域数据,以增强模型的专业技能。
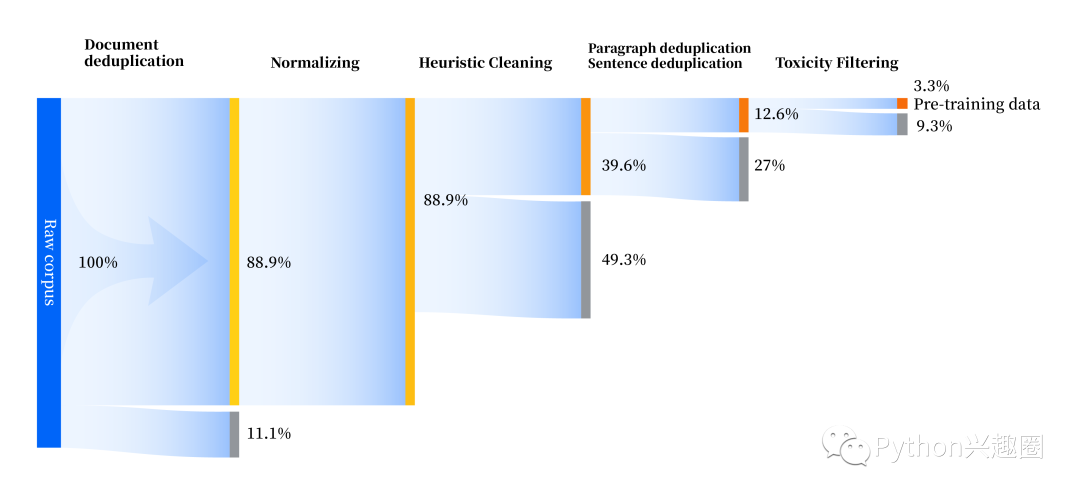
同时其还构建了一套全方位提升数据质量的数据处理流水线,包括标准化、启发式清洗、多级去重、毒性过滤四个模块。共收集 240TB 原始数据,预处理后仅剩 10.6TB 高质量数据。
分词器
-
YAYI 2 采用 Byte-Pair Encoding(BPE)作为分词算法,使用 500GB 高质量多语种语料进行训练,包括汉语、英语、法语、俄语等十余种常用语言,词表大小为 81920。
-
对数字进行逐位拆分,以便进行数学相关推理;同时,在词表中手动添加了大量HTML标识符和常见标点符号,以提高分词的准确性。同时还预设了200个保留位,以便未来可能的应用。
-
采样了单条长度为 1万 Tokens 的数据形成评价数据集,涵盖中文、英文和一些常见小语种,并计算了模型的压缩比。

- <
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 6583
6583

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











