







 本文介绍了YOLO(You Only Look Once)目标检测算法,从基础知识开始,包括滑动窗口技术和全卷积网络。YOLO将图像分割成小方块,每个方块预测几个边界框及其类别概率。文章讨论了YOLOv1的局限性,如对紧密相邻物体和小物体的检测不足,以及YOLOv2和YOLOv3的改进,如Batch Normalization、Anchor Boxes和多尺度训练,提高了检测性能和泛化能力。
本文介绍了YOLO(You Only Look Once)目标检测算法,从基础知识开始,包括滑动窗口技术和全卷积网络。YOLO将图像分割成小方块,每个方块预测几个边界框及其类别概率。文章讨论了YOLOv1的局限性,如对紧密相邻物体和小物体的检测不足,以及YOLOv2和YOLOv3的改进,如Batch Normalization、Anchor Boxes和多尺度训练,提高了检测性能和泛化能力。
检测的基础知识:
在介绍Yolo算法之前,首先先介绍一下滑动窗口技术,这对我们理解Yolo算法是有帮助的。采用滑动窗口的目标检测算法思路非常简单,它将检测问题转化为了图像分类问题。其基本原理就是采用不同大小和比例(宽高比)的窗口在整张图片上以一定的步长进行滑动,然后对这些窗口对应的区域做图像分类,这样就可以实现对整张图片的检测了,如下图3所示,如DPM就是采用这种思路。但是这个方法有致命的缺点,就是你并不知道要检测的目标大小是什么规模,所以你要设置不同大小和比例的窗口去滑动,而且还要选取合适的步长。但是这样会产生很多的子区域,并且都要经过分类器去做预测,这需要很大的计算量,所以你的分类器不能太复杂,因为要保证速度。解决思路之一就是减少要分类的子区域,这就是R-CNN的一个改进策略,其采用了selective search方法来找到最有可能包含目标的子区域(Region Proposal),其实可以看成采用启发式方法过滤掉很多子区域,这会提升效率。

结合卷积运算的特点,我们可以使用CNN实现更高效的滑动窗口方法。这里要介绍的是一种全卷积的方法,简单来说就是网络中用卷积层代替了全连接层,如图4所示。输入图片大小是16x16,经过一系列卷积操作,提取了2x2的特征图,但是这个2x2的图上每个元素都是和原图是一一对应的,如图上蓝色的格子对应蓝色的区域,这不就是相当于在原图上做大小为14x14的窗口滑动,且步长为2,共产生4个字区域。最终输出的通道数为4,可以看成4个类别的预测概率值,这样一次CNN计算就可以实现窗口滑动的所有子区域的分类预测。这其实是overfeat算法的思路。之所可以CNN可以实现这样的效果是因为卷积操作的特性,就是图片的空间位置信息的不变性,尽管卷积过程中图片大小减少,但是位置对应关系还是保存的。这个思路也被R-CNN借鉴,继而有了Fast R-CNN算法。

尽管这样可以减少滑动窗口的计算量,但是只是针对一个固定大小与步长的窗口,这是远远不够的。Yolo算法很好的解决了这个问题,它不再是窗口滑动了,而是直接将原始图片分割成互不重合的小方块,然后通过卷积最后生产这样大小的特征图,基于上面的分析,可以认为特征图的每个元素也是对应原始图片的一个小方块,然后用每个元素来可以预测那些中心点在该小方格内的目标,这就是Yolo算法的基本思想。
One-tsage检测算法的代表之一:
v3很多东西是保留v2甚至v1的东西,先学习一下yolov1和yolov2
yolo 系列之 - yolo v1

每个单元格需要预测(B*5+C)个值(B个bounding box)。输入的图片为S x S网络,因此最终的预测值为S x S x (B x 5 + C)大小的张量,在论文里给出的例子为S=7,B=2, 因此最终的张量大小为7 x 7 x 30

yolo v1的缺陷:
- YOLO对相互靠的很近的物体,还有很小的群体 检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类。
- 对测试图像中,同一类物体出现的新的不常见的长宽比和其他情况泛化能力偏弱。
yolo 系列之 - yolo v2
https://zhuanlan.zhihu.com/p/25052190
改进方面:
- Batch Normalization可以提高模型收敛速度,且不会出现过拟合;
- High Resolution Classifier在YOLOv2中,作者首先采用448×448分辨率的ImageNet数据finetune使网络适应高分辨率输入;然后将该网络用于目标检测任务finetune。高分辨率输入使结果提升;
- Convolutional With Anchor Boxes,去除了YOLO的全连接层,采用固定框(anchor boxes)来预测bounding boxes。首先,去除了一个pooling层来提高卷积层输出分辨率。然后,修改网络输入尺寸:由448×448改为416,使特征图只有一个中心。物品(特别是大的物品)更有可能出现在图像中心。YOLO的卷积层下采样率为32,因此输入尺寸变为416,输出尺寸为13×13;
- 通过聚类方式来选择最佳初始boxes的个数;
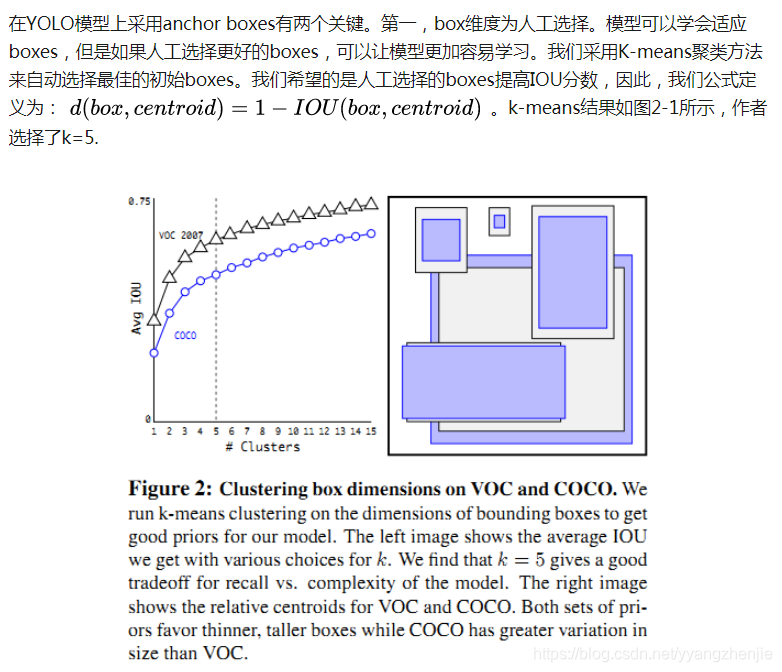
- 作者将预测偏移量改变为YOLO的预测grid cell的位置匹配性(location coordinate),将预测值限定在0-1范围内,增强稳定性。网络对feature map中的每个cell预测5个bounding boxes。对每一个bounding boxes,模型预测5个匹配性值(t_{x},t_{y} ,t_{w} ,t_{h} ,t_{o} )。采用聚类方法选择boxes维度和直接预测bounding boxes中心位置提高YOLO将近5%准确率。
- 多尺度训练,增强泛化能力。
作者:Miracle
链接:https://www.zhihu.com/question/269909535/answer/383693767
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
yolo 系列之 - yolo v3
YOLO v3主要改进点:
1、用逻辑回归层替代softmax二分类作为分类器。
2、使用金字塔网络,多尺度预测;
3、Darknet-53特征提取层,使用一个53层的卷积网络提取特征;
其他方面基本上和YOLO v2没有太大差别
总结
现在v3毫无疑问成为了工程界首选的检测算法之一了,结构清晰,实时性好。这是学者十分安利的目标检测算法,但是你可以很快的用上v3,但你不能很快地懂v3。毕竟好好理解算法比只会用算法难很多。

















 3743
3743

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









