









前 言
通过 Amazon Bedrock,开发者可以轻松使用多种最新领先基础模型(FM)进行构建。本实验中,您将了解和体验到在 Amazon Bedrock 中模型的基础使用方法,以便您快速构建强大安全的大语言模型(LLM)应用,其中包括:
- 使用 Amazon Bedrock - Chat 模式来提出问题并获得高质量回答,包括代码生成以及不同模型之间结果的对比。
- 使用 Amazon Bedrock - Text 模式来体验基本文字处理功能。
- 使用 Amazon Bedrock - Image 模式体验文字生成图像功能,让您在几秒钟内得到您描述的图片。
Amazon Bedrock 是一项完全托管的服务,通过单个 API 提供来自 AI21 Labs、Anthropic、Cohere、Meta、Stability AI 和 Amazon 等领先人工智能公司的高性能基础模型(FM),以及通过安全性、隐私性和负责任的 AI 构建生成式人工智能应用程序所需的一系列广泛功能。使用 Amazon Bedrock,您可以轻松试验和评估适合您的使用案例的热门 FM,通过微调和检索增强生成(RAG)等技术利用您的数据对其进行私人定制,并构建使用您的企业系统和数据来源执行任务的代理。由于 Amazon Bedrock 是无服务器的,因此您无需管理任何基础设施,并且可以使用已经熟悉的亚马逊云科技服务将生成式人工智能功能安全地集成和部署到您的应用程序中。

环境介绍
点击 “开始实验” 按钮,即可扫码进入实验环境。测试账号有效期仅为一天,过期后系统将自动回收清理,请不要上传您的重要数据。
同时,点击 “注册海外账号” 按钮即可免费注册属于你的亚马逊云科技海外区账号,开启个性化的系统构建之旅,进一步探索更广泛、更深入的云服务领域并保留实验中构建的系统应用,尽情享受云上构建的无限可能!

一、访问 Amazon Bedrock UI

并同意试用体验条款与条件后,您将进入到 Amazon Bedrock 的 UI 控制台。
点击设置,将网页设置为中文(简体):

点击入门:

在这里我们可以看到 Amazon Bedrock 支持多个基础模型(foundation model),其中包括 Amazon Titan,Claude,Jurassic,Command,Mistral,Stable Diffusion 以及 Llama2:

点击右上角的区域,选择 us-west-2(美国西部 - 俄勒冈州)

二、申请账号模型权限
(注:本次测试环境已为大家预置相应权限,请略过此步骤,如使用个人或企业账号且未申请过相关模型权限的开发者,需参考如下操作:)
左侧的导航栏中点击模型访问权限,如下图所示:

点击管理模型访问权限:

选择左上角的 CheckBox 选中所有模型,之后点击请求模型访问权限(如果在请求中出现报错的情况,重新勾选模型进行请求即可):



部署完模型,并等待一段时间后刷新页面,确认如下模型都已经是已授予访问权限状态:

请注意:本实验环境仅提供 Amazon Titan,Llama 系列、Mistral AI 系列以及 Stable Diffusion 等模型权限。如您希望测试 Claude3 以及其他在 Amazon Bedrock 上提供的模型,可通过自行注册亚马逊云科技海外区账号,并根据实际业务需求填写账户信息、使用场景后获取。
三、与 Amazon Bedrock 聊天
首先在左侧的导航栏中点击操场 – 聊天:

点击选择模型来选择我们要使用的基础模型(大语言模型):

我们选择任意一个模型来体验其强大的推理能力和中文处理能力,点击应用:

然后我们通过 Chat 来让 Amazon Bedrock 来帮助“安排一个上海 2 日游的行程”。将该问题输入到聊天窗口中,将响应长度调整到 2048(防止返回结果因为 token 限制被截断;UI 上的限制为 2048 token,API 支持最大 token 为 200k),点击运行:

我们可以在对话区域看见大模型的返回结果;同时也可以在最下方看见我们这次调用的耗时,输入输出 token 数以及花费(本实验不会对您产生任何花费或账单):

下面我们先清除本次对话,点击下图所示的图标:

接下来我们让 Amazon Bedrock 为我们生成代码,输入如下内容:
Write a short and high-quality python script for the following task, something a very skilled python expert would write. You are writing code for an experienced developer so only add comments for things that are non-obvious. Make sure to include any imports required. NEVER write anything before the \`\`\`python\`\`\` block. After you are done generating the code and after the \`\`\`python\`\`\` block, check your work carefully to make sure there are no mistakes, errors, or inconsistencies. If there are errors, list those errors in tags, then generate a new version with those errors fixed. If there are no errors, write "CHECKED: NO ERRORS" in tags. Here is the task: A web scraper that extracts data from multiple pages and stores results in a SQLite database. Double check your work to ensure no errors or inconsistencies.
我们可以看到 Amazon Bedrock 为我们生成了带有注释的可读性很强的代码;当然您可以与 Amazon Bedrock 继续进行多轮对话来提升回答质量或者帮您解决代码运行过程中遇到的问题,您可以自行尝试:

四、对比 Amazon Bedrock 不同基础模型
如下图所示选聊天界面的比较模式:

点击右侧的 + 号继续添加对比模型(最多支持 2 个对比模型):

分别点击第一个和第二个窗口的选择模型选项,来添加您想要对比的基础模型:

选择好相应的模型之后,显示如下:

之后我们在聊天窗口输入问题例如“2 days trip to Shanghai”,点击运行,就可以轻松直观的对比不同模型的返回结果:

五、让 Amazon Bedrock 处理文本
接下来我们通过左侧的导航栏切换到操场 – 文本:
同样我们需要先选择基础模型,同样注意需要把响应长度调整到 2048:
这次让我们使用 COT (Chain of Thought) - Let's think step by step 让大模型帮我们处理问题;可以看到 Amazon Bedrock 可以把它每一步的思考以及结果都返回。输入内容:
You are a a very intelligent bot with exceptional critical thinking. I went to the market and bought 10 apples. I gave 2 apples to your friend and 2 to the helper. I then went and bought 5 more apples and ate 1. How many apples did I remain with? Let's think step by step.
点击运行:

六、利用 Amazon Bedrock 生成图片
在左侧的导航栏中点击操场 – 图像:
同样需要先选择一个模型:
之后我们输入如下 prompt 来让 Amazon Bedrock 为我们生成图片,点击运行:
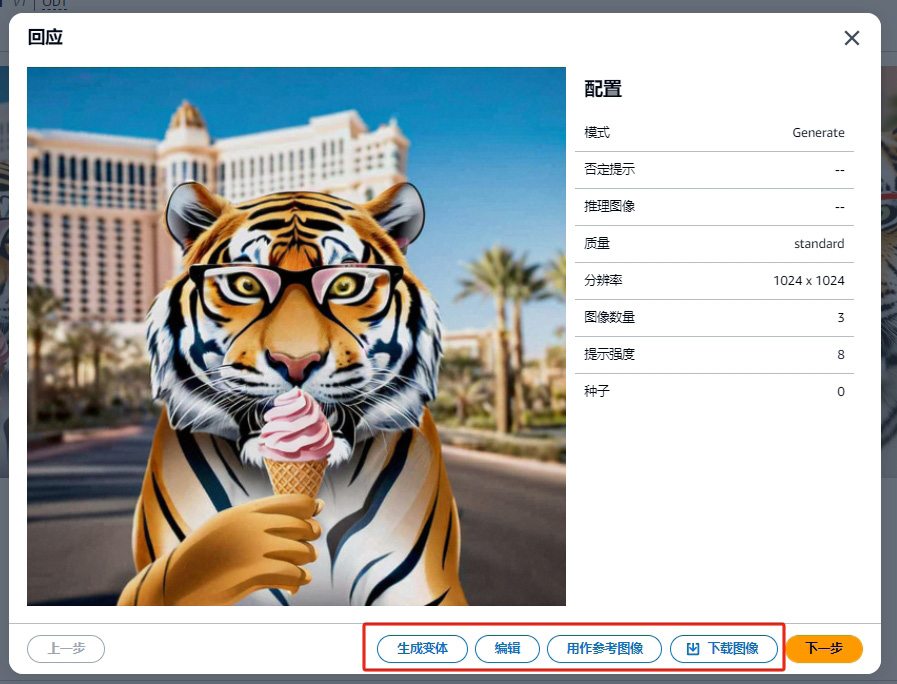
a Tiger wearing glasses and eating an ice cream in Las Vegas.

模型会为我们生成 3 张图片用来供我们选择;点击其中一张您认为效果最好的图片,您可以下载此图片或者继续编辑:
七、体验完成
恭喜您在 Amazon Bedrock 上体验了本次所有实验内容,成功“通关”!
通过此次试验,相信您已经对 Amazon Bedrock 上模型的文字处理以及图片生成功能有了初步了解,但该模型的强大远不止于此。经过训练的模型,可对图表、技术示意图等不同格式的结构化和非结构化数据进行理解;同时该模型在数学问题、编程练习和科学推理等标准化评估方面也超越现有模型;此外也可通过人工智能技术减轻幻觉,为模型推理提供透明度,提高准确性。
现在,是时候将所学付诸实践了。轻轻一点,注册海外账号,立即免费踏入属于您的云端构建世界。作为新注册的您,更能体验到长达 12 服务等 100 余种云产品与服务。更值一提的是,您还将全面享受亚马逊云科技的海外区域节点,为您的实战构建之旅铺设坚实的基石。不再等待,立即开启您的云上探索之旅吧!
同时,在云上探索实验室中,我们还有更多丰富多彩的实验内容,让您的学习之旅永不止步。期待您的热情参与,共同体验这场技术的盛宴,一起成长,一起探索更广阔的科技天地。

















 508
508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









