







23年5月来自华盛顿大学等多家学校和研究机构的论文“Self-Instruct: Aligning Language Models with Self-Generated Instructions“。
大型“指令调优”语言模型(即经过微调以响应指令)已经表现出将零样本推广到新任务的非凡能力。 然而,它们严重依赖于人类编写的指令数据,而这些数据通常在数量、多样性和创造力方面受到限制,因此阻碍了调优模型的通用性。
SELF-INSTRUCT,一个通过引导自己的生成来提高预训练语言模型指令跟从能力的框架。 其流水线从生成指令、输入和输出语言模型的样本、过滤掉无效或相似的样本、到最后微调原始模型。 应用于普通 GPT3,证明在SUPER-NATURALINSTRUCTIONS上比原始模型有 33% 的绝对改进,与使用私人用户数据和人工注释进行训练的 InstructGPT00的性能相当。
为了进一步评估,为新任务策划了一组专家编写的指令,并通过人工评估表明,使用 SELF-INSTRUCT 调整 GPT3 的性能大幅优于现有公共指令数据集,仅与 InstructGPT001 相比有 5% 的绝对差距。 SELF-INSTRUCT 提供了一种几乎无需标注的方法,用于将预训练语言模型与指令对齐,并且发布了大型综合数据集以促进未来指令调优的研究。
如图是SELF- INSTRUCT高级概述。 该过程从一个小的任务种子集作为任务池开始。 从任务池中抽取随机任务,用于提示现成的语言模型生成新指令和相应实例,然后过滤低质量或相似的生成结果,然后添加回初始任务存储库。 所得数据可用于稍后对语言模型本身进行指令调优,以更好地跟从指令。 图中所示的任务由GPT3生成。
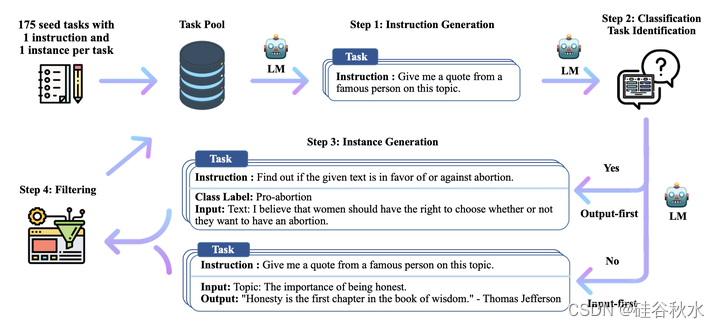
数据生成流程包括四个步骤:1)生成任务指令,2)确定指令是否代表分类任务,3)使用输入优先或输出优先的方法生成实例,4)过滤低质量数据。
指令生成。第
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 5840
5840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









