









前言
本文回顾一下MHA、GQA、MQA,详细解读下MHA、GQA、MQA这三种常见注意力机制的原理。
self-attention
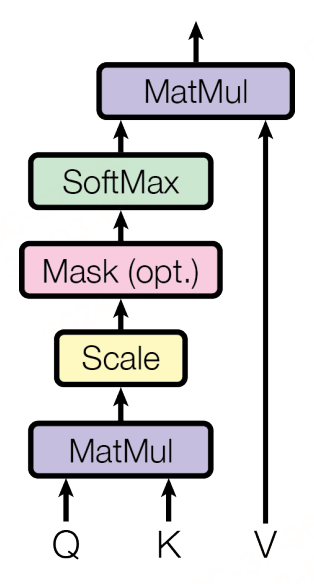
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
在自注意力机制中,输入通常是一个统一的输入矩阵 X X X,而这个矩阵后续会通过乘以不同的权重矩阵来转换成三个不同的向量集合:查询向量 Q Q Q、键向量 K K K和值向量 V V V。这三组向量是通过线性变换方式生成:
1.查询向量 (Q): Q = X W Q Q=XW^Q Q=XWQ
2.键向量 (K): K = X W K K=XW^K K=XWK
3.值向量 (V): V = X W V V=XW^V V=XWV
W
Q
,
W
K
W^Q,W^K
WQ,WK,和
W
V
W^V
WV 是可学习的权重矩阵,分别对应于查询、键和值。这些矩阵的维度取决于模型的设计,通常它们的输出维度(列数) 是预先定义的,以满足特定的模型架构要求。
在Transformer模型中,使用不同的权重矩阵
W
Q
,
W
K
W^Q,W^K
WQ,WK,和
W
V
W^V
WV来分别生成查询向量
Q
Q
Q、键向量
K
K
K 和值向量
V
V
V 的目的是为了允许模型在不同的表示空间中学习和抽取特征。这样做增加了模型的灵活性和表达能力,允许模型分别优化用于匹配(Q 和K)和用于输出信息合成(V)的表示。
在自注意力和多头注意力机制中,使用 d k \sqrt{d_k} dk作为缩放因子进行缩放操作是为了防止在计算点积时由于维度较高导致的数值稳定性问题。这里的 d k d_k dk是键向量的维度。**如果不进行缩放,当 d k d_k dk较大时,点积的结果可能会变得非常大,这会导致在应用softmax函数时产生的梯度非常小。**因为softmax函数是通过指数函数计算的,大的输入值会使得部分输出接近于1,而其他接近于0,从而导致梯度消失,这会在反向传播过程中造成梯度非常小,使得学习变得非常缓慢。
通过点积结果除以 d k \sqrt{d_k} dk ,可以调整这些值的范围,使得它们不会太大。这样,softmax的输入在一个合适的范围内,有助于避免极端的指数运算结果,从而保持数值稳定性和更有效的梯度流。这个操作确保了即使在 d k d_k dk很大的情况下, 注意力机制也能稳定并有效地学习。
代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class SelfAttention(nn.Module):
def __init__(self, seq_length):
super(SelfAttention, self).__init__()
self.input_size = seq_length
# 定义三个权重矩阵:Wq、Wk、Wv
self.Wq = nn.Linear(seq_length, seq_length) # 线性变换
self.Wk = nn.Linear(seq_length, seq_length)
self.Wv = nn.Linear(seq_length, seq_length)
def forward(self, input):
# 计算Q,K,V 三个矩阵
q = self.Wq(input)
k = self.Wk(input)
v = self.Wv(input)
# 计算QK^T,即向量之间的相关度
attention_scores = torch.matmul(q, k.transpose(-1, -2)) / torch.sqrt(torch.tensor(float(self.input_size)))
# 计算向量权重,softmax归一化
attention_weight = F.softmax(attention_scores, dim=-1)
# 计算输出
output = torch.matmul(attention_weight, v)
return output
x = torch.randn(2, 3, 4)
Self_Attention = SelfAttention(4) # 传入输入向量的维度
output = Self_Attention(x)
print(output.shape)
MHA(多头注意力)
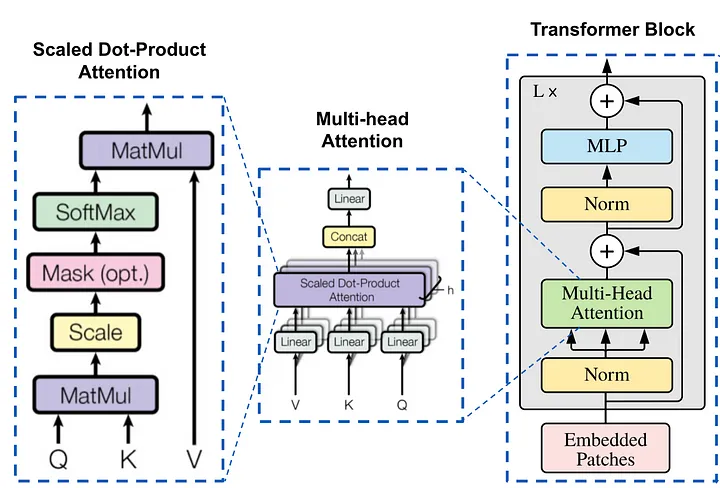
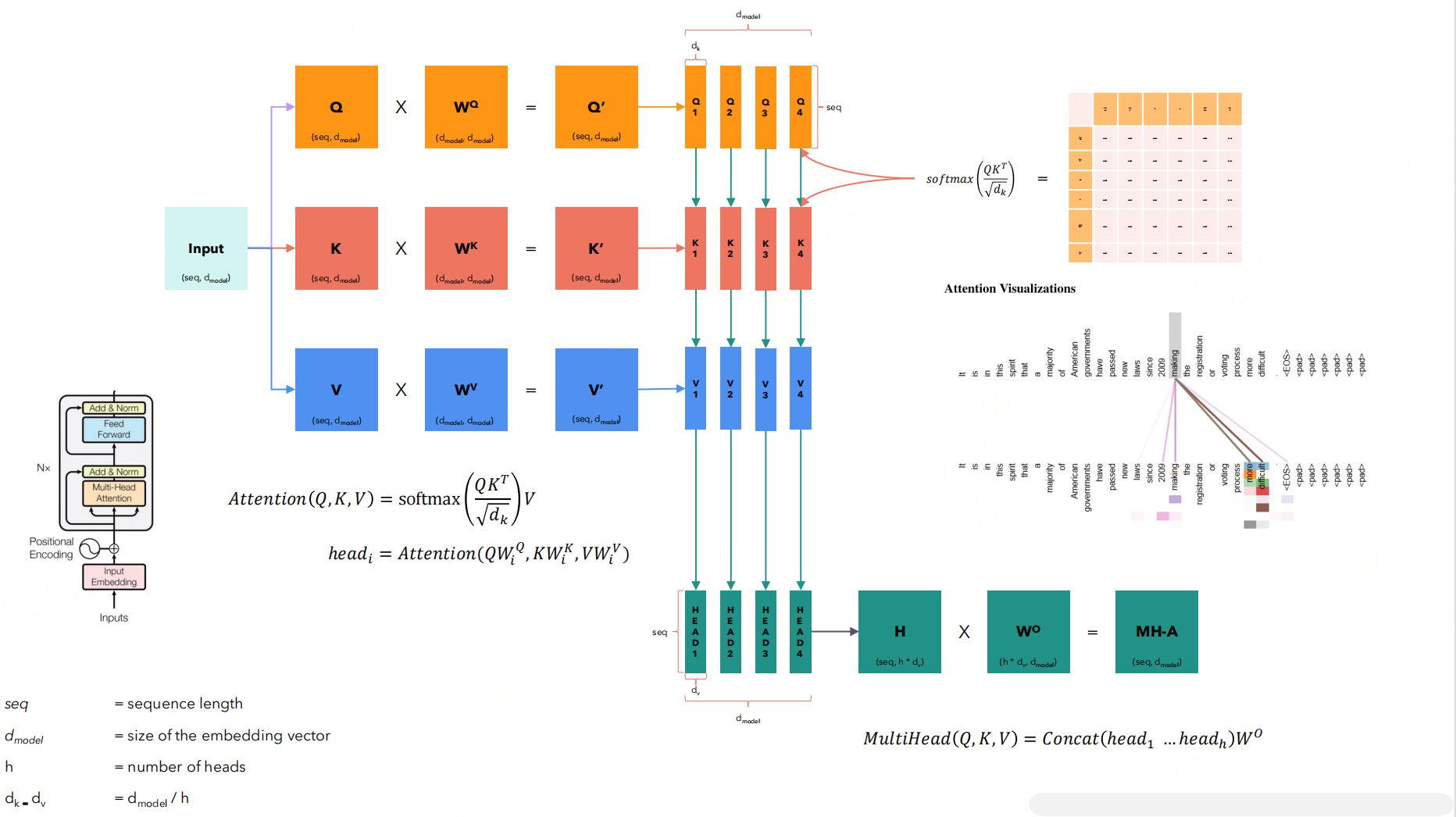
将 Q ′ Q^{^{\prime}} Q′分成了多个部分,每个部分进行注意力。比如 Q Q Q的形状 [ s e q , d i ] [seq,d_i] [seq,di]、 K T K^T KT的形状 [ d i , s e q ] [d_i,seq] [di,seq]、 V V V的形状 [ s e q , d i ] [seq,d_i] [seq,di],则有 Q k T Qk^T QkT的形状为 [ s e q , s e q ] , s o f t m a x ( Q K T d k ) V [seq,seq],softmax(\frac{QK^T}{\sqrt{d_k}})V [seq,seq],softmax(dkQKT)V的形状为 [ s e q , d i [seq,d_i [seq,di 也就是说每一个注意力之后的 h e a d i head_i headi的形状都是 [ s e q , d i ] [seq,d_i] [seq,di],这和 Q ‘ Q^{`} Q‘的形状一样,拼接起来得到的 H H H的形状和直接使用自注意力机制的形状是一样的。这里使用了一个 W O W^O WO,进行整合(合并头:将所有头的输出合并回一个大的张量)。最后一个线性层:对合并后的输出应用另一个线性变换。
其中权重矩阵 Q , K , V Q,K,V Q,K,V变化概括就是:将 Q , K , V Q,K,V Q,K,V划分成多头,并行处理。但这里的头并不是对 X X X进行多次线性变换,而是对之后的 Q , K , V Q,K,V Q,K,V划分成多个部分,每个部分进行计算,最后拼接。
h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) head_i=Attention(QW_i^Q,KW_i^K,VW_i^V) headi=Attention(QWiQ,KWiK,VWiV),每个头对 Q , K , V Q,K,V Q,K,V进行变换后进行注意力机制
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , h e a d 2 , … , h e a d h ) W O MultiHead(Q,K,V)=Concat(head_1,head_2,\ldots,head_h)W^O MultiHead(Q,K,V)=Concat(head1,head2,…,headh)WO
代码实现
import torch
import torch.nn as nn
class MultiHeadAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.wq = nn.Linear(embed_dim, embed_dim)
self.wk = nn.Linear(embed_dim, embed_dim)
self.wv = nn.Linear(embed_dim, embed_dim)
self.wo = nn.Linear(embed_dim, embed_dim)
def mh_split(self, hidden):
batch_size = hidden.shape[0]
x = hidden.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
return x
def forward(self, hidden_states, mask=None):
batch_size = hidden_states.size(0)
# 线性变换
q, k, v = self.wq(hidden_states), self.wk(hidden_states), self.wv(hidden_states)
# 多头切分
q, k, v = self.mh_split(q), self.mh_split(k), self.mh_split(v)
# 注意力计算
scores = torch.matmul(q, k.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.head_dim, dtype=torch.float32))
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
attention = torch.softmax(scores, dim=-1)
output = torch.matmul(attention, v)
# 拼接多头
output = output.transpose(1, 2).contiguous().view(batch_size, -1, self.num_heads * self.head_dim)
# 线性变换
output = self.wo(output)
return output
x = torch.rand(2, 3, 36)
print(x)
output = MultiHeadAttention(36, 6)
y = output(x)
print(y.shape)
MHA 能够理解输入不同部分之间的关系。然而,这种复杂性是有代价的——对内存带宽的需求很大,尤其是在解码器推理期间。主要问题的关键在于内存开销。在自回归模型中,每个解码步骤都需要加载解码器权重以及所有注意键和值。这个过程不仅计算量大,而且内存带宽也大。随着模型规模的扩大,这种开销也会增加,使得扩展变得越来越艰巨。
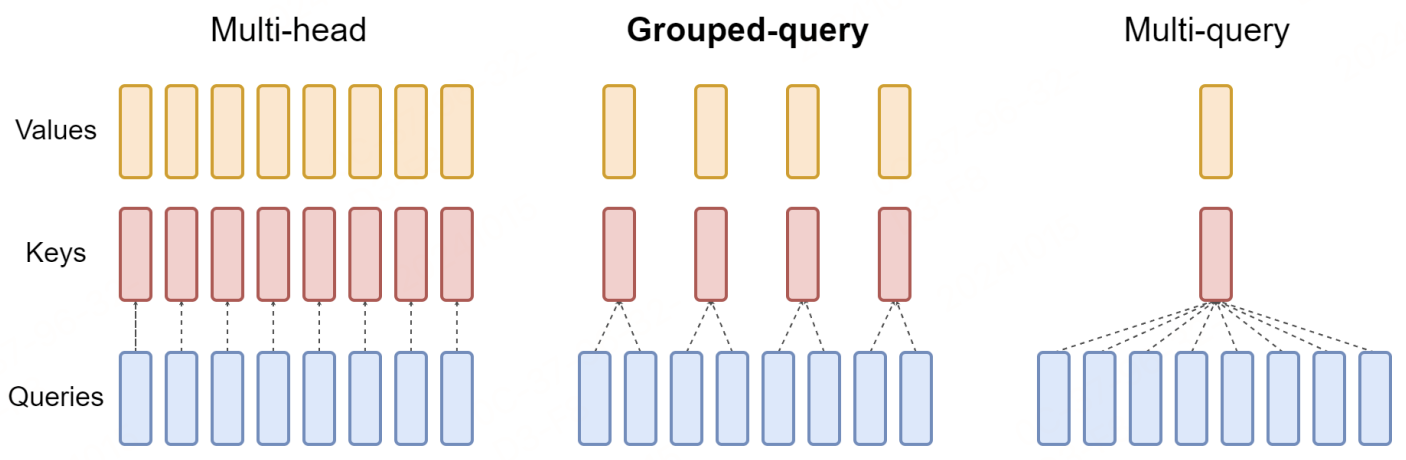
因此,多查询注意 (MQA) 应运而生,成为缓解这一瓶颈的解决方案。其理念简单而有效:使用多个查询头,但只使用一个键和值头。这种方法显著减少了内存负载,提高了推理速度。
MQA(多查询注意力)
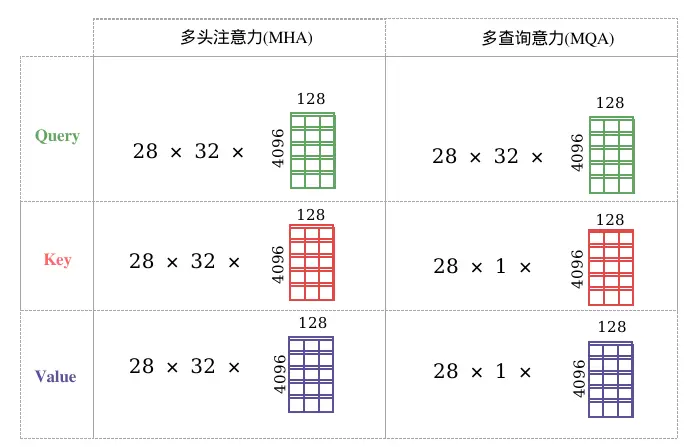
MQA是MHA的一种变体,也是用于自回归解码的一种注意力机制。,图1、图2很形象的描绘了MHA和MQA的对比,与MHA 不同的是,MQA 让所有的Head之间共享同样的一份 K 和 V 矩阵(意味K和V的计算唯一),只让 Q 保留了原始多头的性质(每个Head存在不同的转换),从而大大减少 K 和 V 矩阵的参数量以及KV Cache的显存占用,以此来达到提升推理速度,但是会带来精度上的损失。MQA被大量应用于LLM中,如ChatGLM2。
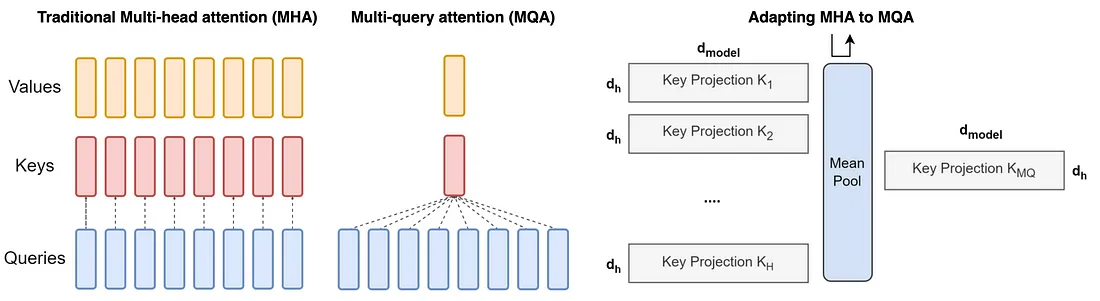
**如何将现有的预训练多头注意力模型转换为多查询注意力模型 (MQA)?**从现有的多头模型创建多查询注意力模型涉及两个步骤:模型结构的转换和随后的预训练。
-
模型结构的转换:此步骤将多头模型的结构转换为多查询模型。它是通过将原始模型的多个头的键和值的投影矩阵(线性层)合并(均值池化)为键和值的单个投影矩阵来实现的。这种均值池化方法被发现比选择现有键和值头之一或从头开始初始化新的键和值头更有效。生成的结构具有合并的键和值投影,这是多查询模型的特征。
-
对转换后的模型进行预训练:结构转换后,模型将接受额外的训练。此训练不像原始模型训练那样广泛;它只是原始模型训练步骤的一小部分(表示为 α)。此预训练阶段的目的是让模型根据其新的简化注意力机制调整和优化其性能。训练遵循与原始相同的方法,确保学习动态的一致性。
代码实现
import torch
import torch.nn as nn
class MultiQuerySelfAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super(MultiQuerySelfAttention, self).__init__()
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.wq = nn.Linear(embed_dim, embed_dim)
# MHA
# self.wk = nn.Linear(embed_dim, embed_dim)
# self.wv = nn.Linear(embed_dim, embed_dim)
# MQA
self.wk = nn.Linear(embed_dim, self.head_dim)
self.wv = nn.Linear(embed_dim, self.head_dim)
self.wo = nn.Linear(embed_dim, embed_dim)
def q_h_split(self, hidden, head_num=None):
batch_size, seq_len = hidden.size()[:2]
# q拆分多头
if head_num == None:
x = hidden.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
return x
else:
# 这是MQA: 需要拆分k和v,这里面的head_num =1 的
# 最终返回维度(batch_size, 1, seq_len, head_dim)
return hidden.view(batch_size, seq_len, head_num, self.head_dim).transpose(1, 2)
def forward(self, hidden_states, mask=None):
batch_size = hidden_states.size(0)
# 线性变换
q, k, v = self.wq(hidden_states), self.wk(hidden_states), self.wv(hidden_states)
# 多头切分
# 这是MHA的
# q, k ,v = self.split(q), self.split(k), self.split(v)
# 这是MQA的
q, k, v = self.q_h_split(q), self.q_h_split(k, 1), self.q_h_split(v, 1)
# 注意力计算
scores = torch.matmul(q, k.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.head_dim, dtype=torch.float32))
print("scores:", scores.shape)
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
attention = torch.softmax(scores, dim=-1)
output = torch.matmul(attention, v)
# 多头合并
output = output.transpose(1, 2).contiguous().view(batch_size, -1, self.num_heads * self.head_dim)
# 线性变换
output = self.wo(output)
return output
x = torch.rand(3, 12, 512)
atten = MultiQuerySelfAttention(512, 8)
y = atten(x)
print(y.shape)
GQA(分组查询注意力)
虽然MQA方式大幅减小了参数数量,但是,带来推理加速的同时会造成模型性能损失,且在训练过程使得模型变得不稳定(复杂度的降低可能会导致质量下降和训练不稳定),因此在此基础上提出了GQA,它将Query进行分组,每个组内共享一组Key、Value。(GQA在LLaMA-2 和 Mistral7B得到应用)
GQA 的数学原理:
分组:在 GQA 中,传统多头模型中的查询头 (Q) 被分成 G 组。每组分配一个键 (K) 和值 (V) 头。此配置表示为 GQA-G,其中 G 表示组数。
GQA 的特殊情况:
- GQA-1 = MQA:只有一个组(G = 1),GQA 等同于 MQA,因为所有查询头只有一个键和值头。
- GQA-H = MHA:当组数等于头数(G = H)时,GQA 退化为 MHA,每个查询头都有其唯一的键和值头。
对每个组中原始头部的键和值投影矩阵进行均值池化,以将MHA模型转换为 GQA 模型。此技术对组中每个头部的投影矩阵进行平均,从而为该组生成单个键和值投影。
通过利用 GQA,该模型在 MHA 质量和 MQA 速度之间保持平衡。由于键值对较少,内存带宽和数据加载需求被最小化。G 的选择代表了一种权衡:更多的组(更接近 MHA)可带来更高的质量但性能较慢,而更少的组(接近 MQA)可提高速度但有牺牲质量的风险。此外,随着模型规模的扩大,GQA 允许内存带宽和模型容量按比例减少,与模型规模相对应。相比之下,对于更大的模型,在 MQA 中减少到单个键和值头可能会过于严重。
代码实现
import torch
import torch.nn as nn
class GroupedQueryAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super(GroupedQueryAttention, self).__init__()
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.wq = nn.Linear(embed_dim, embed_dim)
# 这是MHA的
# self.wk = nn.Linear(embed_dim, embed_dim)
# self.wv = nn.Linear(embed_dim, embed_dim)
# 这是MQA的
# self.wk = nn.Linear(embed_dim, self.head_dim)
# self.wv = nn.Linear(embed_dim, self.head_dim)
# 这是GQA的
self.group_num = 4 # 这是4个组
self.wk = nn.Linear(embed_dim, self.group_num * self.head_dim)
self.wv = nn.Linear(embed_dim, self.group_num * self.head_dim)
self.wo = nn.Linear(embed_dim, embed_dim)
def split(self, hidden, group_num=None):
batch_size, seq_len = hidden.size()[:2]
# q需要拆分多头
if group_num == None:
x = hidden.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
return x
else:
# 这是kv需要拆分的多头
x = hidden.view(batch_size, seq_len, group_num, self.head_dim).transpose(1, 2)
x = x[:, :, None, :, :].expand(batch_size, group_num, self.num_heads // group_num, seq_len,
self.head_dim).reshape(batch_size, self.num_heads, seq_len, self.head_dim)
return x
def forward(self, hidden_states, mask=None):
batch_size = hidden_states.size(0)
# 线性变换
q, k, v = self.wq(hidden_states), self.wk(hidden_states), self.wv(hidden_states)
# 多头切分
# 这是MHA的
# q, k ,v = self.split(q), self.split(k), self.split(v)
# 这是MQA的
# q, k ,v = self.split(q), self.split(k, 1), self.split(v, 1)
# 这是GQA的
q, k, v = self.split(q), self.split(k, self.group_num), self.split(v, self.group_num)
# 注意力计算
scores = torch.matmul(q, k.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.head_dim, dtype=torch.float32))
print("scores:", scores.shape)
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
attention = torch.softmax(scores, dim=-1)
output = torch.matmul(attention, v)
# 合并多头
output = output.transpose(1, 2).contiguous().view(batch_size, -1, self.num_heads * self.head_dim)
# 线性变换
output = self.wo(output)
return output
x = torch.ones(3, 12, 512)
atten = GroupedQueryAttention(512, 8)
y = atten(x)
print(y.shape)
参考文献
- GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints,https://arxiv.org/pdf/2305.13245
- Attention Is All You Need,https://arxiv.org/pdf/1706.03762
- Fast Transformer Decoding: One Write-Head is All You Need,https://arxiv.org/pdf/1911.02150v1

















 2133
2133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









