









 本文介绍了Structure软件的下载与安装,适用于Windows、Mac OS X和Unix/Linux系统。还提及了示例数据类型,阐述了plink数据格式转化为structure的方法,以及如何将数据导入软件、定义参数、查看结果等操作,最后说明了使用admixture指定群体实现有监督学习。
本文介绍了Structure软件的下载与安装,适用于Windows、Mac OS X和Unix/Linux系统。还提及了示例数据类型,阐述了plink数据格式转化为structure的方法,以及如何将数据导入软件、定义参数、查看结果等操作,最后说明了使用admixture指定群体实现有监督学习。
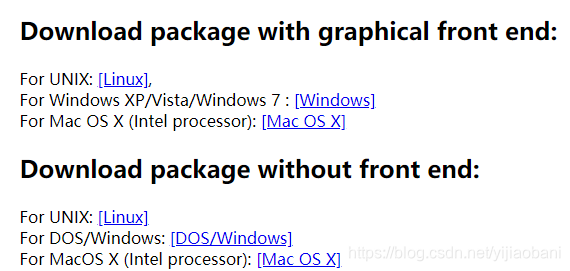
1. 软件下载
structure
Windows版建议安装桌面版(graphical front end), Linux建议安装终端版(without front end)
2. 安装指南
Windows
直接双击安装包, 进行安装即可. 安装完成后, 桌面上有快捷方式:

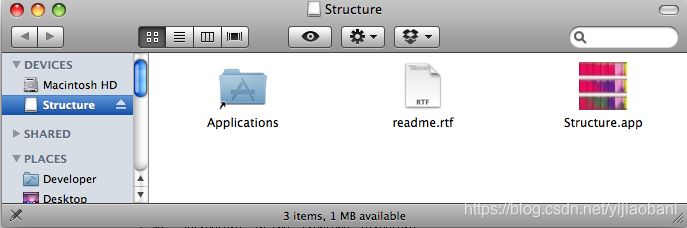
Mac OS X
软件包是一个可执行文件, 双击Structure.dmg, 会打开软件, 创建一个快捷方式即可.
Unix/Linux
下载软件包, 解压进入软件包文件夹, 会有structure可执行文件, 运行./structure即可.
wget https://web.stanford.edu/group/pritchardlab/structure_software/release_versions/v2.3.4/release/structure_linux_console.tar.gz
tar zxvf structure_linux_console.tar.gz
cd console/
./structure
出现下面代码, 说明运行成功:
(base) [dengfei@localhost console]$ ./structure
----------------------------------------------------
STRUCTURE by Pritchard, Stephens and Donnelly (2000)
and Falush, Stephens and Pritchard (2003)
Code by Pritchard, Falush and Hubisz
Version 2.3.4 (Jul 2012)
----------------------------------------------------
Reading file "mainparams".
datafile is
infile
Reading file "extraparams".
Note: RANDOMIZE is set to 1. The random number generator will be initialized using the system clock, ignoring any specified value of SEED.
Unable to open the file infile.
Exiting the program due to error(s) listed above.
3. 示例数据
示例数据

五种类型的数据:
- Simulated microsatellite test data
- AFLP data from whitefish.
- SNP and microsatellite data from the HGDP.
- Thrush data from original Structure paper
- Simulated microsatellite data with location information
4. plink数据格式转化为structure
.recode.strct_in (Structure format)
Produced by "--recode structure", for use by Structure. This format cannot be loaded by PLINK.
A text file with two header lines: the first header line lists all V variant IDs, while each entry in the second line is the difference between the current variant's base-pair coordinate and the previous variant's bp coordinate (or -1 when the current variant starts a new chromosome). This is followed by one line per sample with the following 2V+2 fields:
1. Within-family ID
2. Positive integer, unique for each FID
3-(2V+2). Genotype calls, with the A1 allele coded as '1', A2 = '2', and missing = '0'
用法:
使用参数--recode structure, 结果生成:.recode.strct_in的后缀文件.
plink --file name --recode structure --out result
还可以使用Mega2进行格式转化, 转化方法
5. 使用admixture的数据进行测试
查看数据:
(base) [dengfei@localhost test]$ ls
hapmap3.bed hapmap3.bim hapmap3.fam hapmap3.map
使用plink进行格式转化:
plink --bfile hapmap3 --recode structure --out test_structure
生成test_structure.recode.strct_in文件, 用这个文件进行操作.
数据格式如下:
rs10458597 rs12562034 rs2710875 rs11260566 rs1312568 rs35154105 rs16824508 rs2678939 rs7553178 rs133763
-1 203827 209332 200465 206966 213697 200280 201401 204163 202132 226411 200445 201484 200329 205708 20
NA19916 1 2 2 2 2 1 1 2 2 2 2 2 2 1 2 1 2 2 2 1 2 2 2 2 2 1 1 2 2 2 2 2 2 2 2 1 2 1 1 1 2 1 2 1 2 1 2 1
NA19835 2 2 2 1 2 1 2 1 2 2 2 2 2 2 2 1 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 2 1 2 2 2 2 2 1 2 1
NA20282 3 2 2 2 2 1 2 1 2 1 2 2 2 2 2 1 1 1 2 2 2 2 2 2 2 1 2 2 2 2 2 1 2 2 2 1 2 2 2 2 2 1 2 1 1 2 2 1
NA19703 4 2 2 2 2 1 2 2 2 1 2 2 2 2 2 1 2 2 2 1 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 1 2 1 2 2 2 1 2 1 2 2 2 2
NA19901 5 2 2 2 2 1 2 1 2 2 2 2 2 2 2 1 1 2 2 1 2 2 2 2 2 2 2 2 2 1 2 2 2 2 2 1 2 2 2 1 2 1 1 1 2 1 1 2
NA19908 6 2 2 1 2 2 2 2 2 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 2 1
NA19914 7 2 2 2 2 2 2 2 2 1 1 2 2 2 2 1 1 1 2 2 2 2 2 1 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 1 2 2 2 1
NA20287 8 2 2 2 2 1 1 2 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 1 2 2 2 1 2 2 2 2 2 1 2 1 2 1 2 1 1 2 2 2 2 2
NA19713 9 2 2 2 2 1 2 1 2 2 2 2 2 2 2 1 1 2 2 2 2 2 2 2 2 1 1 2 2 1 2 2 2 2 2 1 2 1 1 2 2 1 2 1 2 2 2 2
NA19904 10 2 2 2 2 1 2 2 2 2 2 2 2 2 2 1 1 2 2 2 2 2 2 1 2 2 2 2 2 2 2 1 2 2 2 1 2 2 2 2 2 2 2 2 2 0 0
NA19917 1 2 2 2 2 1 2 2 2 2 2 2 2 2 2 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 1
6. 导入数据到structure软件中
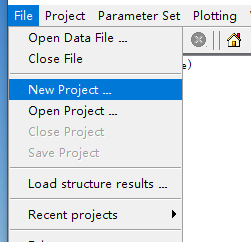
双击打开软件

点击File, 点击New Project
键入名称: name1(自己命名即可)
选择文件所在的文件夹
选择文件
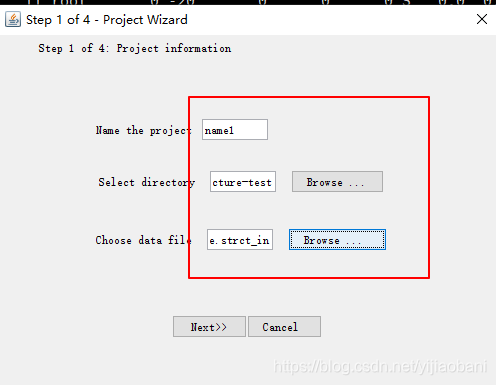
数据可以提前预览, 可以看到:
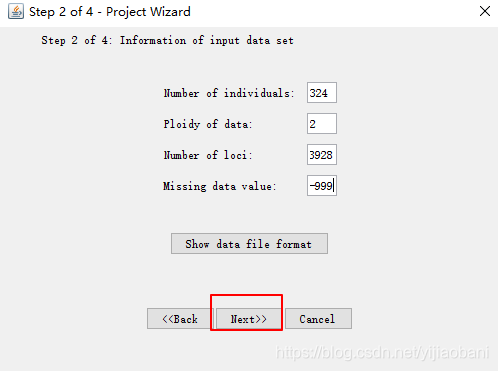
个体数为: 324
SNP个数为: 13928
缺失定义为 -999
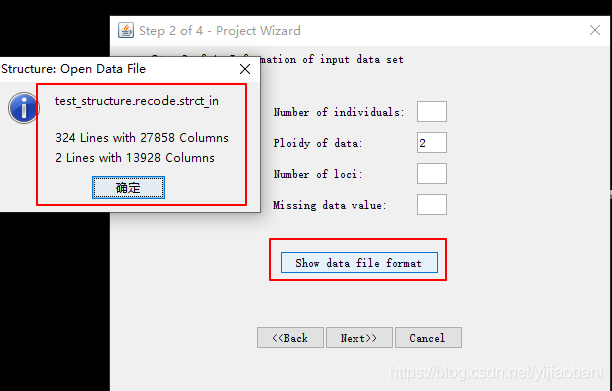
定义好之后:点击Next
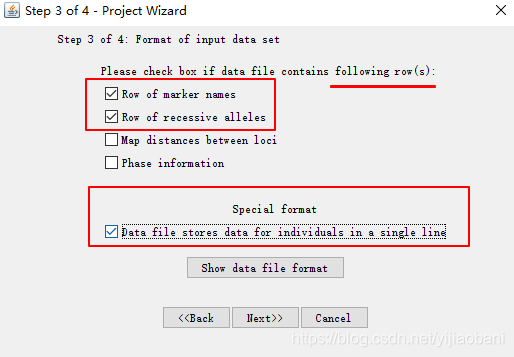
定义行
- 勾选: Row of marker names
- 勾选: Row of recessive alleles
- 勾选: Data file storges data for individuals in a single line
定义列:
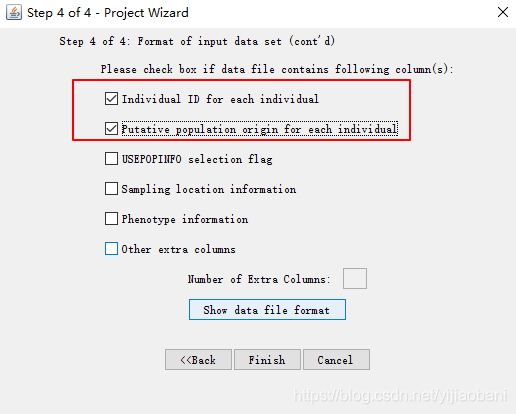
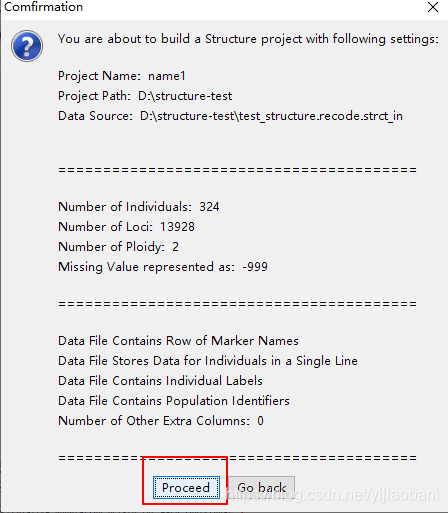
读入数据成功:
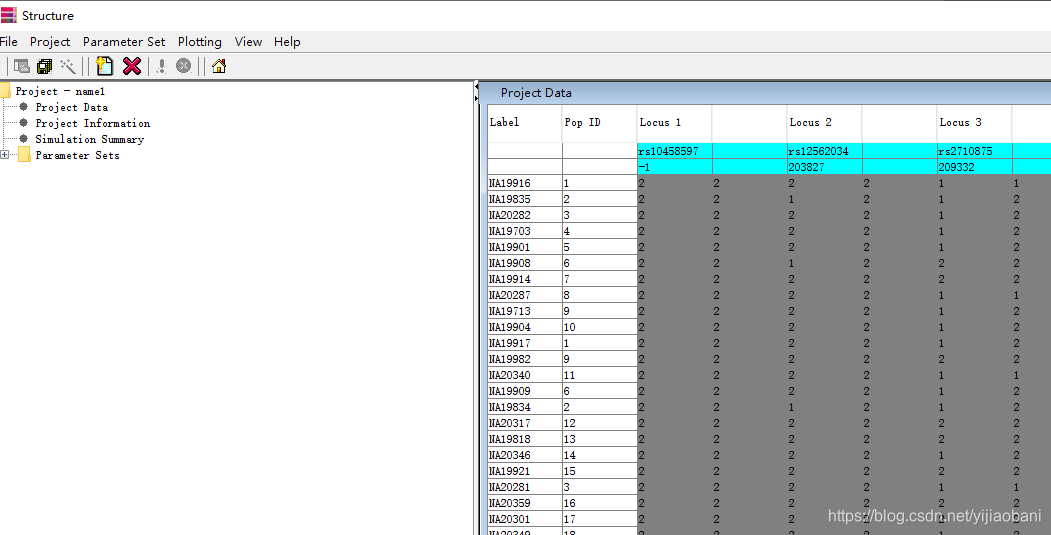
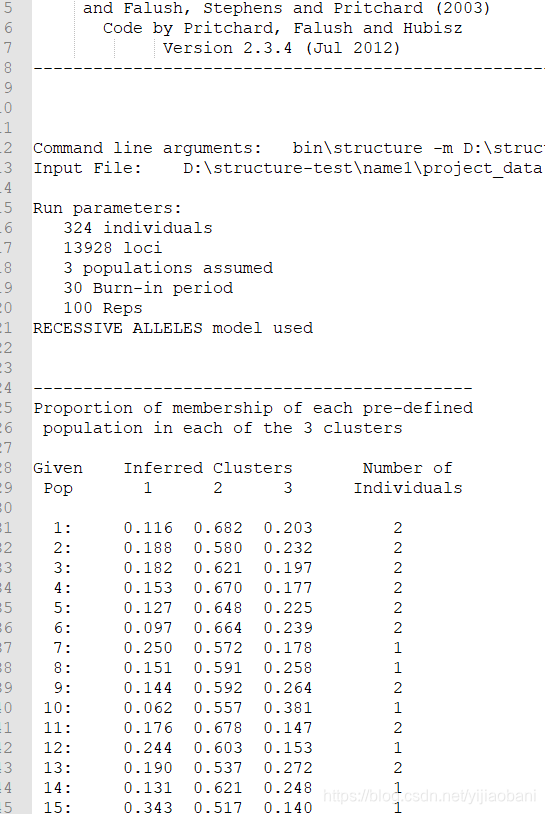
7. 定义参数
参数命名为t1
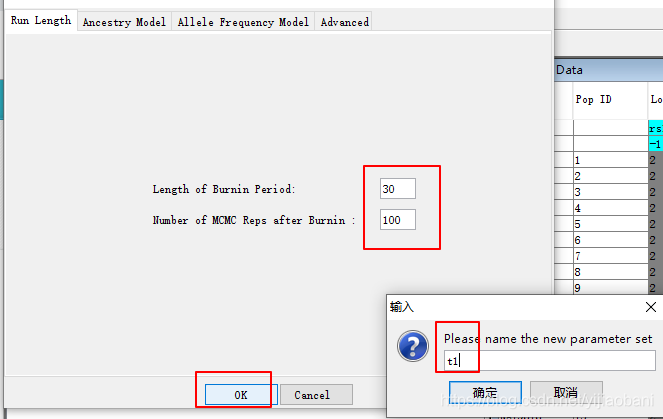
定义为3个群体.
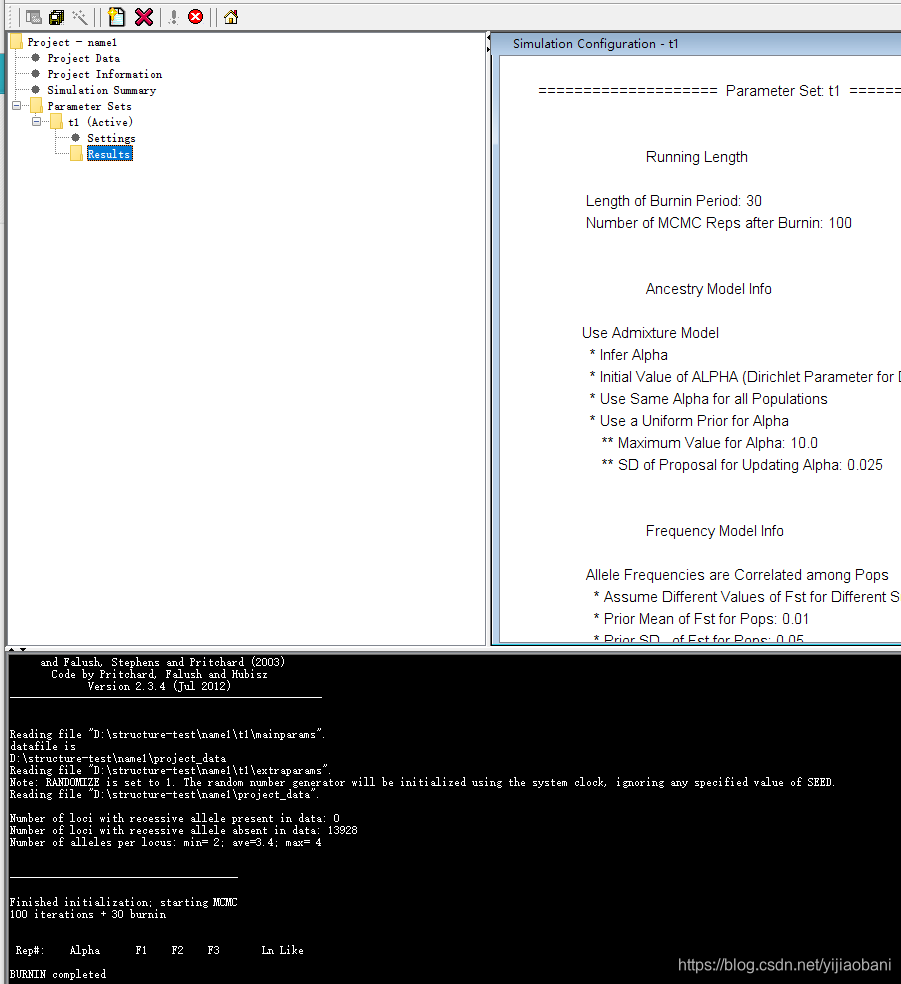
开始运行:
8. 查看结果
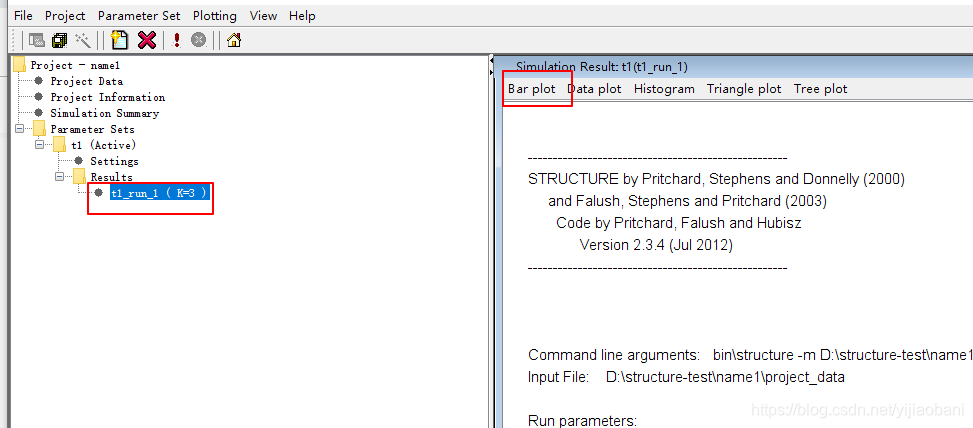
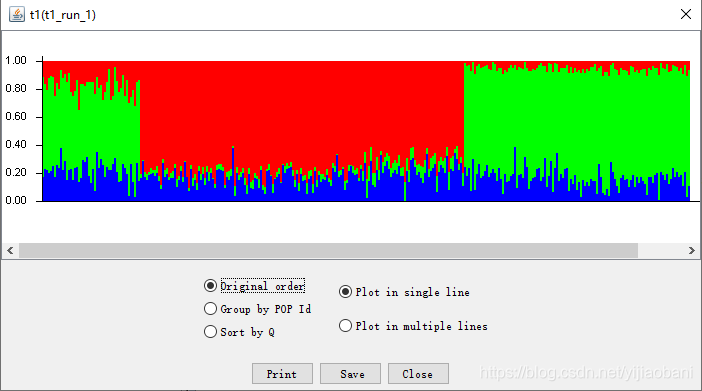
结果文件:
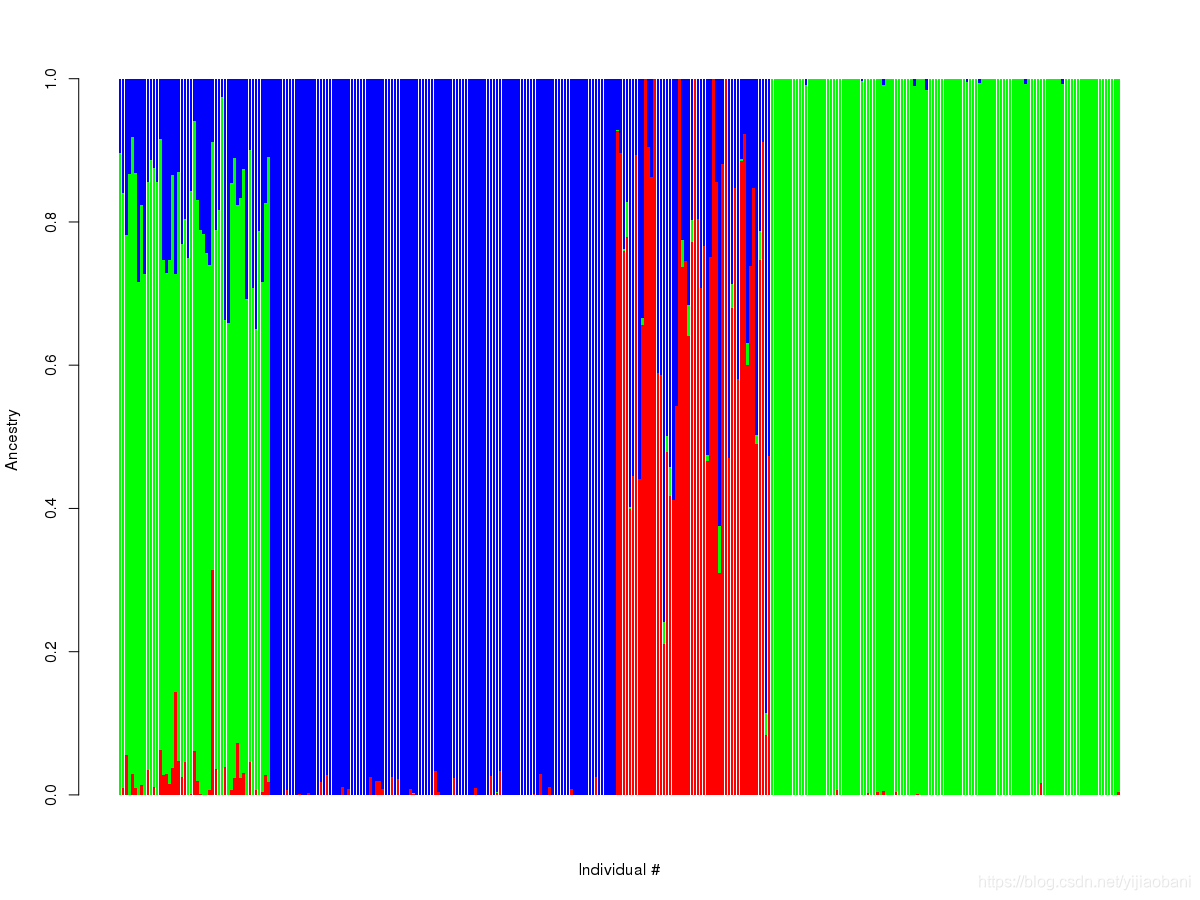
9. 使用admixture作为结果对比
admixture hapmap3.bed 3
10. 使用admixture指定群体

如果没有群体的信息, 是无监督的学习, 会根据G矩阵进行自分类. 但是, 这种情况很少见, 一般我们都有一些先验性的信息, 比如已知某些个体是属于某一类群的, 这样分析效果更好.
这样, 通过定义已知的个体的群体信息, 分类变为了有监督的学习(supervised learning ), admixture通过定义一个文件.pop,

pop文件特点, 前缀和ped或者bed前缀一样, 一行内容, 如果已知群体, 定义群体名称, 如果未知, 用-或者空格表示, 单独一行.
比如, 如果9个个体, 6个知道群体类型,3个不知道群体类型, 定义如下:
A
A
-
-
B
B
A
-
B
运行命令时, 加上参数: --supervised
这里, test.pop, 为手动生成的pop文件, 生成代码如下:
a = data.frame(V1 = rep(c("A","-","B","-","C","-"),each=54))
write.csv(a,"test.pop",row.names=F,quote=F)
admixture test.ped 3 --supervised
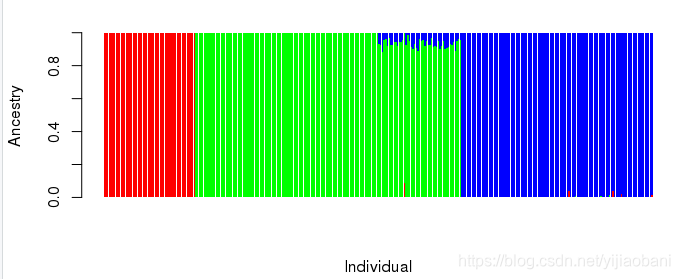
绘图:

PS
YouTube Structure 操作视频
GCTA PCA分析以及软件安装教程
Admixture使用说明文档cookbook

















 1
1

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









