



 博主记录了学习LVI - SAM的过程及问题。介绍了LVI - SAM论文,其是激光雷达 - 视觉 - 惯导紧密融合框架,由VIS和LIS子系统构成。还进行了实验,在不同数据集上验证框架性能。此外,分享了实验数据集运行步骤、代码阅读情况等。
博主记录了学习LVI - SAM的过程及问题。介绍了LVI - SAM论文,其是激光雷达 - 视觉 - 惯导紧密融合框架,由VIS和LIS子系统构成。还进行了实验,在不同数据集上验证框架性能。此外,分享了实验数据集运行步骤、代码阅读情况等。
最近开始搞LVI-SAM,简单记录一下学习过程和遇到的问题。(准备从以下五个方面展开)
1. 论文
摘要:
实现了一种平滑映射的激光雷达-视觉-惯导紧密融合的框架,能够高精度和鲁棒性实现实时状态估计和地图构建,该框架建立在一个因子图上,由两个子系统构成,分别是:视觉惯性系统和激光雷达惯性系统。视觉惯导系统利用激光雷达测量提取视觉特征的深度信息,提高了视觉惯导的精度;反过来,激光惯导系统利用视觉惯导估计进行初始猜测用来支持扫描匹配。闭合回路首先由视觉惯导系统识别,然后由激光惯导完善,当其中一个子系统出现故障时,另一个子系统也能正常工作。
引言
本文利用因子图进行全局优化,通过闭环检测定期消除机器人!产生的漂移。
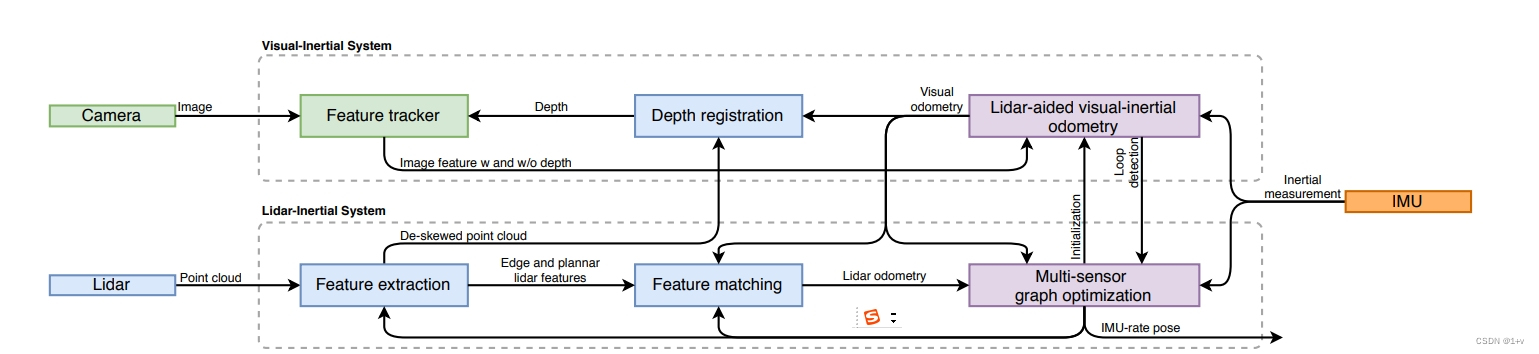
图1: LVI-SAM 的系统结构。该系统接收来自三维激光雷达、摄像头和 IMU 的输入,可分为两个子系统:视觉-惯性系统(VIS)和激光雷达-惯性系统(LIS)。视觉-惯性系统和激光雷达-惯性系统可以独立运行,同时利用彼此的信息来提高系统的精度和鲁棒性。该系统以 IMU 速率输出姿态估计值。
视觉惯导系统执行视觉特征跟踪,可选择使用激光雷达帧提取特征深度。视觉里程计通过优化视觉重投影和 IMU 测量误差获得的视觉里程测量值可作为激光雷达匹配的初始值估计,并在因子图中引入约束条件。点云在使用 IMU 测量进行点云纠偏后,激光惯导系统将提取激光雷达的边缘和平面特征,并将这些特征纳入因子图中,并将其与一个特征图匹配。LIS系统状态可发送至 VIS,以方便其初始化。在闭环过程中,候选匹配首先由 VIS 确定,然后由 LIS 进一步优化。来自视觉里程测量、激光雷达里程测量、IMU 预集成的约束条件、 IMU预集成和环路闭合的约束条件在因子图中进行联合优化。最后,优化后的 IMU 偏置项被用于传播 IMU 测量值,以便以 IMU 速率进行姿态估计。我们的工作的主要贡献可总结如下:
1. 建立在因子图之上的紧密耦合 LVIO 框架,实现多传感器融合,并在地点识别的辅助下进行全局优化。
2. 通过故障检测绕过失效的子系统,使其对传感器退化具有鲁棒性。
3. 通过在不同规模、平台和环境下收集的数据进行了广泛验证。
从系统角度看,代表了 VIO 和 LIO 最先进技术的独特整合,从而实现了 LVIO 系统,提高了鲁棒性和准确性。
视觉激光惯导slam系统
系统概述
该框架由两个关键子系统组成:视觉-惯性系统(VIS)和激光雷达-惯性系统(LIS)。视觉惯性系统处理图像和 IMU 测量值,激光雷达测量值为可选项。视觉里程测量是通过最小化视觉和 IMU 测量的联合残差获得。LIS 可提取激光雷达特征,通过将提取的特征与特征图匹配来进行激光雷达测距。特征图以滑动窗口方式进行维护,以实现实时性能。最后,状态估计问题可表述为最大后验(MAP)问题,使用iSAM2通过在因子图中联合优化 IMU 预集成约束、视觉里程测量约束、激光雷达里程测量约束和闭环约束的贡献来解决。
视觉惯导系统
为VIS调整了来自[8]的处理惯导数据,如图2所示。视觉特征使用角点检测器检测,并由Kanade–Lucas–Tomasi算法跟踪。在VIS初始化后,利用视觉里程计对齐激光帧的点云得到一个稀疏的深度图来得到特征的深度完成视觉惯导初始化。系统在滑窗中执行BA,其中系统状态x∈X可以写为:
x = [ R, p, v, b ].
R是SO3表示旋转矩阵,p表示位置,v表示速度,b=[b_a, b_w]是IMU的偏置。变换矩阵T是SE3,表示从机体坐标系到世界坐标系的变换 。下边将详细的介绍VIS的初始化和特征深度估计。
1)初始化:基于优化的VIO系统由于很强的非线性导致初始化发散。初始化的质量取决于两个主要因素:初始化的传感器运动和IMU参数的精度。在实际的实验中,VINS很容易在系统速度很小或者匀速的时候初始化失败。这是由于加速度激励不够大导致尺度不可观。IMU的参数包含缓慢变化的偏差和高斯白噪声,影响原始加速度和角速度的测量,在初始化的时候好的初值可以帮助系统快速的优化。为了改善VIS初始化的鲁棒性,利用LIS系统来估计系统的状态X和IMU的偏置b。通过雷达的观测得到深度信息。首先初始化LIS系统获得x和b。然后通过插值来把激光帧和视觉帧通过时间戳对齐。假设IMU的偏置在两个图象关键帧之间是常数,最后把LIS系统初始化得到的x和b作为VIS初始值,能够有效的改善初始化的速度和鲁棒性。
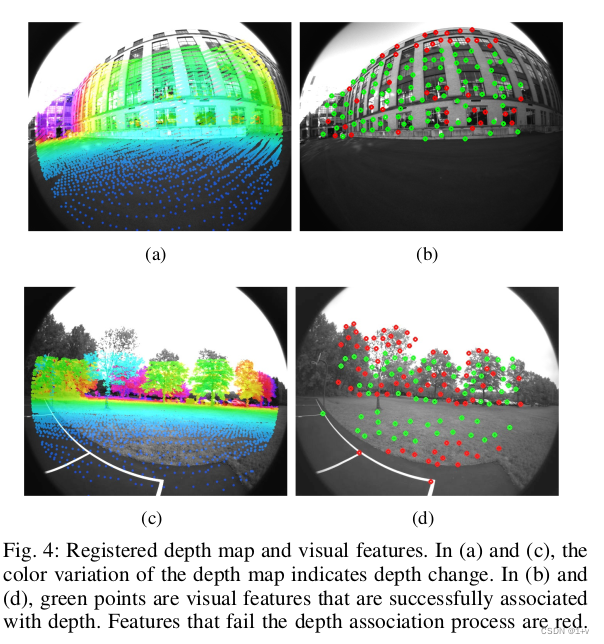
2)深度特征关联:根据VIS初始化的结果,利用视觉里程计对齐视觉帧和雷达帧。由于当前的3D lidar扫描的是稀疏点,将多帧激光点云组合起来得到一个稠密的深度图。为了把特征和深度值关联起来,视觉特征和雷达点投影到以相机为圆心的单位圆上。然后对深度点进行降采样并利用极坐标进行保存,保证点的密度是常数的。利用二维的KD-tree(极坐标)来找视觉特征点周围最近的三个点,最后特征点的深度计算的是相机中心和特征点的连线的长度,这条线和三个深度点得到的平面在笛卡尔坐标系中有交点。可视化如下图3(a)所示,特征深度是虚线的长度。(这段其实没看懂)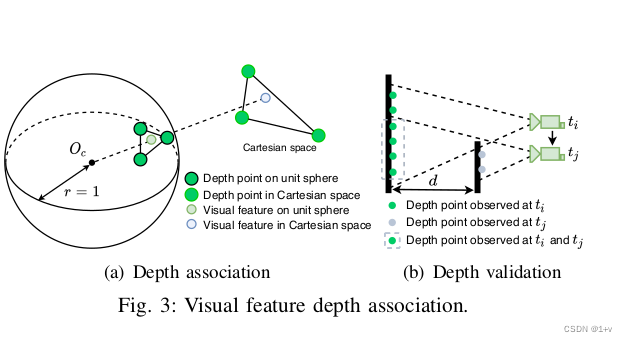 图4显示了对齐的深度图和视觉特征。图4的(a)和©,利用视觉里程计对齐点云得到深度图投影到了图像上。在图4(b)和(d)上,通过深度图恢复视觉特征的被标记成了绿色。需要注意的是,虽然图4(a)中深度点覆盖了图像的大部分区域,但是由于图4(b)中的很多特征落在窗户的角上导致深度关联检验失败。
图4显示了对齐的深度图和视觉特征。图4的(a)和©,利用视觉里程计对齐点云得到深度图投影到了图像上。在图4(b)和(d)上,通过深度图恢复视觉特征的被标记成了绿色。需要注意的是,虽然图4(a)中深度点覆盖了图像的大部分区域,但是由于图4(b)中的很多特征落在窗户的角上导致深度关联检验失败。
失败检测:如果运动变化剧烈,光照变化或者环境缺少纹理就会导致VIS系统失败。这是由于在这种场景中跟踪的特征点会显著减少,而特征太少会导致优化失败。当VIS系统失败的时候会导致IMU的bias很大,所以当VIS系统跟踪的特征点少于一个阈值或者IMU估计出来的bias大于一个阈值的时候我们认为VIS系统失败。主动失效检测对于本文的系统是必需的,以便其故障不会影响LIS系统。一旦检测到故障,VIS将重新初始化并通知LIS。
闭环检测:本文利用DBoW2来做闭环检测,对于每一个新来的图像关键帧,检测出BRIEF描述子并把他和原来检测的描述子匹配。通过DBoW2检测到的闭环候选帧的时间戳会给到LIS系统来做进一步的验证。
雷达惯导系统
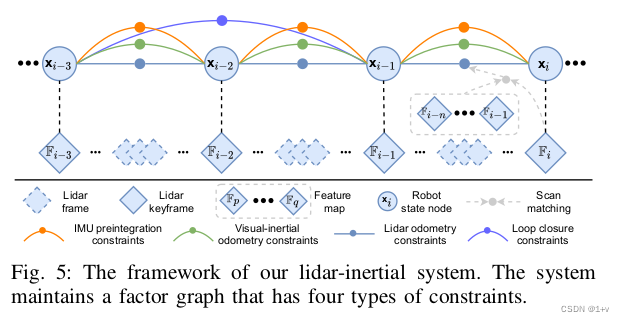
如图5所示,雷达惯导系统是基于LIO-SAM的,利用因子图来做全局的位姿优化。主要有四种约束,IMU的预积分约束,视觉里程计的约束,雷达里程计的约束和闭环检测的约束加入到因子图中参与优化。激光雷达里程计约束来自扫描匹配,将当前的激光雷达关键帧与全局特征图进行匹配。闭环检测的约束候选帧首先由VIS提供,然后通过扫描匹配进一步优化。为特征图维护了一个激光雷达关键帧的滑动窗口,这保证了有限的计算复杂性。当机器人位姿变化超过阈值时,将选择一个新的激光雷达关键帧。丢弃位于关键帧之间的普通激光雷达帧。选择新的激光雷达关键帧后,新的机器人状态x将作为节点添加到因子图中。以这种方式添加关键帧,不仅可以在内存消耗和地图密度之间取得平衡,而且还有助于维护相对稀疏的因子图以进行实时优化。可以通过LIO-SAM的论文了解细节。在以下各节中,重点介绍提高系统鲁棒性的新策略。
初始值估计:通过实验发现初始值对于连续的扫描匹配有着重要的作用,尤其是在剧烈运动的情况下。在LIS系统初始化之前和之后初值的来源是不同的。在LIS系统初始化之前,我们假设机器人在初始位置静止,然后假设IMU的bias和噪声都为0,对IMU原始值积分得到两个雷达关键帧的位置和姿态信息作为scan-match的初值。
经过实验发现这种方法能在有挑战的场景(初始速度小于10m/s,角速度小于180°/s)中初始化系统。一旦LIS系统初始化完成,我们估计因子图中的IMU的bias,机器人的位姿,速度。然后把这些量传到VIS系统中完成其初始化。在LIS系统初始化完成之后,可以通过两个途径得到Scan-match的初值:IMU的积分和VIS系统。当VIS系统的里程计可以输出位姿时我们以他为初值,如果VIS系统报告失效的时候,我们利用IMU的积分作为初值。这个过程在纹理丰富和缺乏纹理的环境中都增加了初值的精度和鲁棒性。
失败检测:尽管激光雷达可以得到场景中很远范围内的细节,但是也会在一些场景中导致扫描匹配失败,如图6所示。利用[26]论文中介绍的方法来检测LIS系统是不是失败了。扫描匹配中的非线性优化问题可以表示为迭代求解一个线性问题:
min k AT − b k 2
其中A和b是由T处的线性化得到的。当 A T A A^TA ATA的最小特征值小于第一次优化迭代时的阈值时,LIS报告失败。当发生故障时,激光雷达里程计约束不会添加到因子图中。我们请读者参考[26]进行这些假设所基于的详细分析。
三、实验
我们现在描述了一系列的实验,以在三个自收集的数据集上验证所提出的框架,这些数据集被称为Urban, Jackal, and Handheld.。以下各部分提供了这些数据集的详细信息。我们用于数据收集的传感器套件包括一个弹性差Velodyne VLP-16 lidar, a FLIR BFS-U3-04S2M-CS相机、一个MicroStrain 3DM-GX5-25 IMU和一个ReachRS+GPS(为地面真相)。我们将所提出的框架与开源解决方案进行了比较,其中包括VINS-Mono、LOAM、LIO-mapping、LINS和LIO-SAM。所有的方法都是在C++中实现的,并在UbuntuLinux中使用Inteli7-10710U的笔记本电脑上执行。我们的LVI-SAM和数据集的实现可在下面的链接中获得.
A.消融研究
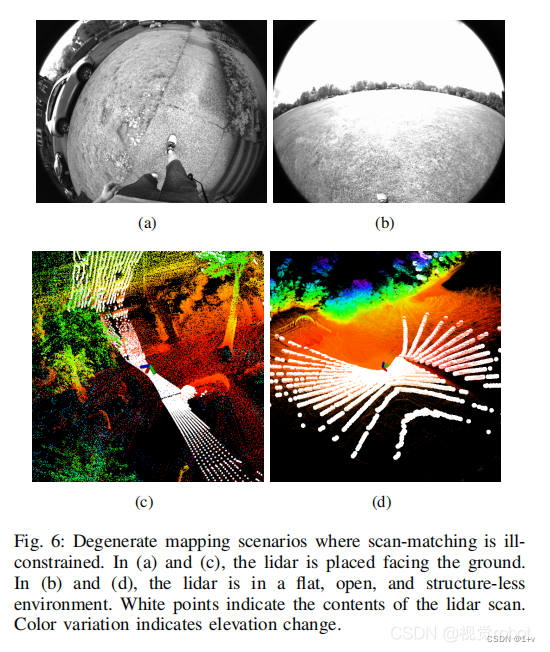
我们展示了系统中每个模块的设计如何影响使用城市数据集的提议框架的性能。该数据集以建筑物、停放和移动的汽车、行人、骑自行车者和植被为特色,由操作员步行和携带传感器套件收集。我们还故意将传感器套件放置在具有挑战性的位置(图6(a)),以验证系统在退化场景下的鲁棒性。由于头顶植被茂密,该地区gps无法访问。我们在相同的位置开始和结束数据收集过程,以验证端到端平移和旋转错误,如表1所示。
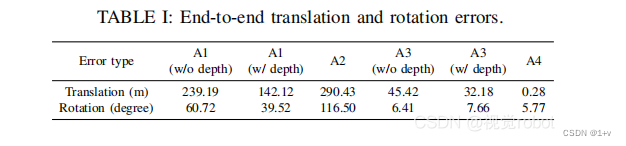
1)A1-包含激光雷达特征深度信息的视觉惯性测里程计的影响:我们禁用LIS中的扫描匹配,并依靠VIS只执行姿态估计.启用和不启用深度配准的结果轨迹在图7中被标记为A1。运动轨迹的方向是按时钟计算的。当将深度与视觉特征相关联时,如表一所示的端到端姿态误差大大减少。
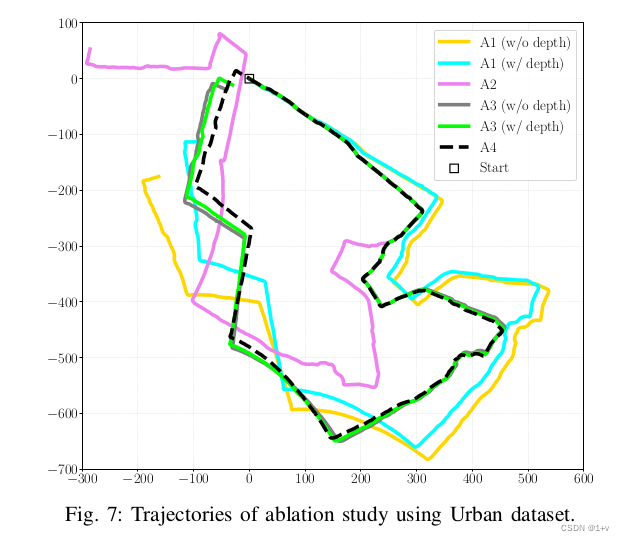
2)视觉惯性里程计的影响:我们禁用VIS,只使用LIS进行姿态估计。图7中标记为A2,当遇到退化场景时,轨迹会发散几次。
3)A3-激光雷达视觉惯性里程计中的激光雷达的特征深度信息的影响:我们现在一起使用VIS和LIS,切换VIS中的深度配准模块来比较得到的LVIO轨迹。借助视觉特征的深度,翻译误差进一步降低了29%,从45.42米降低到32.18米。注意,在此测试中禁用环路闭合检测,以纯测速模式验证系统。
4)A4-视觉环闭合检测的影响:通过在VIS中启用环闭合检测功能来消除系统的漂移。当在框架中启用每个模块时,最终的轨迹在图7中被标记为A4。
B. Jackal Dataset
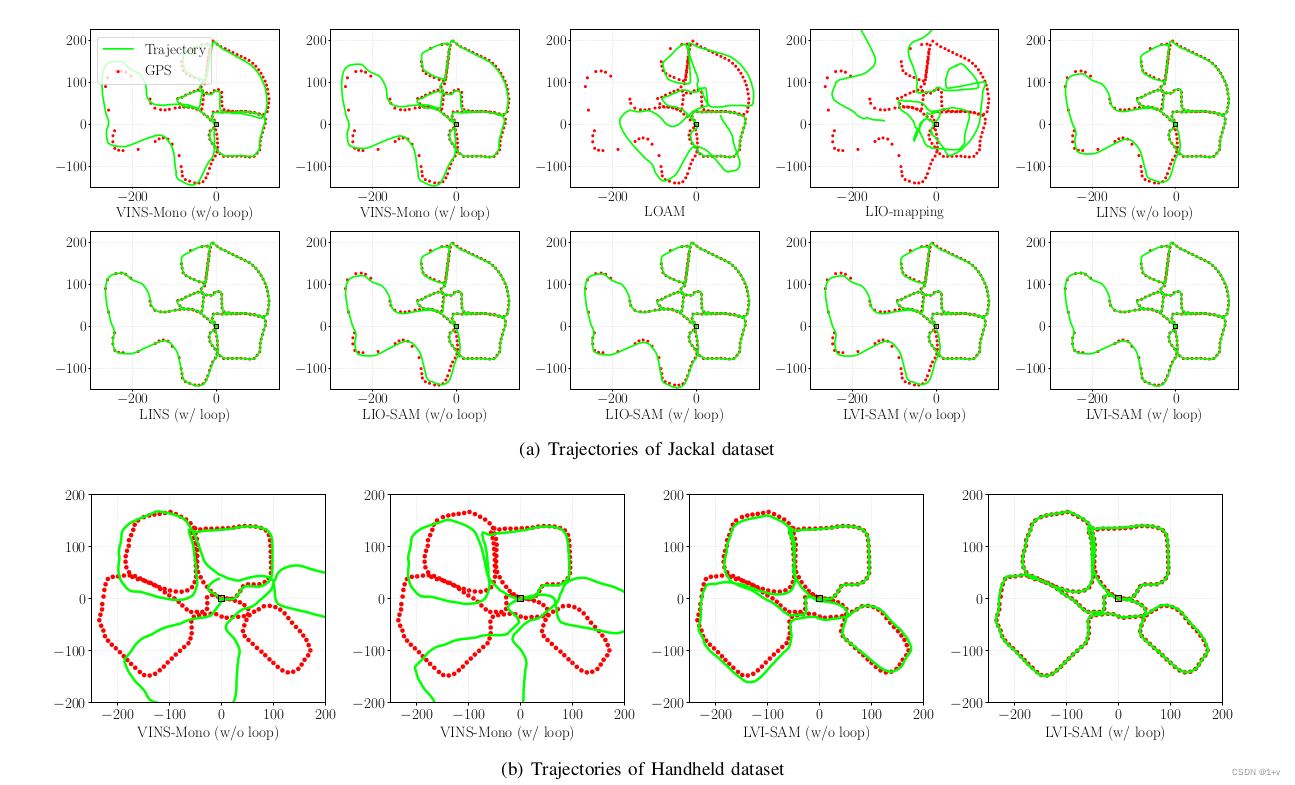
Jackal Dataset是通过将传感器套件安装在Clearpath Jackal无人驾驶地面车辆(UGV)上来收集的。我们在一个功能丰富的环境中手动驱动机器人,开始和结束在同一位置。如图8(a)所示的环境以结构、植被和各种路面为特征。GPS接收可用的区域用白点标记。

我们比较了各种方法,并在图9(a)中显示了它们的轨迹。我们通过手动禁用和启用它,进一步验证了具有循环闭包功能的方法的准确性。基准测试结果见表二。与GPS测量相比,LVI-SAM的平均均方根误差(RMSE)最低,这被视为地面真值。最低的端到端平移误差是由LINS实现的,它改编LeGOLOAM[11],是专门为UGV操作设计的。LVI-SAM再次实现了最低的端到端旋转误差。
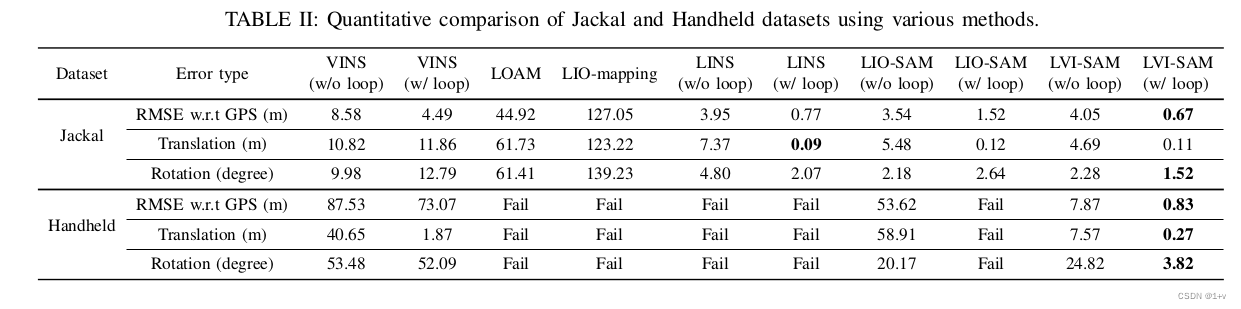
C. Handheld Dataset
Handheld dataset是由带着传感器套件的操作员在几个开放区域中收集的,如图8(b)所示。该数据集也在相同的位置开始和结束。我们通过一个位于图像顶部中心的一个开放棒球场来增加这个数据集的挑战。当通过这个领域时,相机和激光雷达收集的主要观测结果分别是草和地面(图6(b)和(d))。由于上述简并性问题,所有基于激光雷达的方法都不能产生有意义的结果。提出的框架LVI-SAM成功地在启用了或没有循环闭包的情况下完成了测试,并在表二中所有三个基准标准中实现了最低的误差。
四、总结
提出了LVI-SAM,一个通过SAM紧密耦合激光雷达-视觉-惯性里程计的框架,用于在复杂环境中进行实时状态估计和地图构建。该框架由视觉惯性系统和激光雷达惯性系统两个子系统组成。这两个子系统被设计成以紧密耦合的方式交互,以提高系统的鲁棒性和准确性。通过对不同规模、平台和环境上的数据集进行评估,我们的系统显示出与现有公开可用方法可比有更好的准确性。我们希望我们的系统将作为一个坚实的基线,其他人可以很容易地建立,以推进激光视觉惯性测速的技术。
小结:论文阅读到此结束,其实还有很多东西没有看懂,主要是实验部分有些复杂。论文阅读和翻译参考这篇博文进行:https://blog.youkuaiyun.com/JaydenQ/article/details/119929789(感谢大佬)
后续学习会不定期更新,因为自己懒。
2.实验数据集
电脑配置:Ubuntu 18.04 + ROS Melodic + GTSAM 4.0.2 + CERES 1.14.0(本来ceres是2.00,但是编译失败,换成了1.14,成功)
我下载了两个数据集:garden.bag.baiduyun.p 和 handheld。先上结果图:
handheld数据集
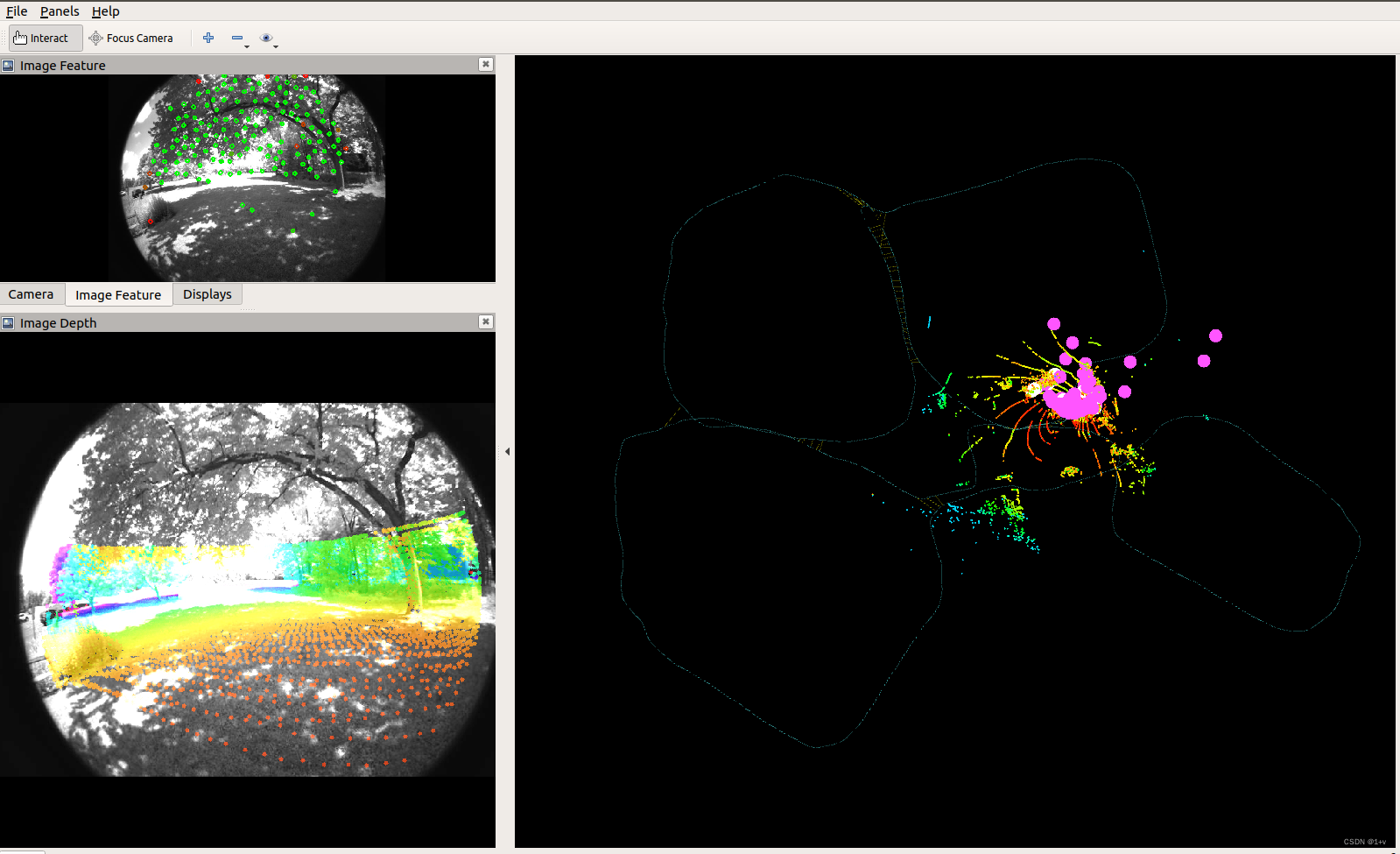 这里不知道为什么会有多余的点云,后续精读代码希望能找到原因。
这里不知道为什么会有多余的点云,后续精读代码希望能找到原因。
运行方式:
1:创建工作空间
mkdir -p ~/catkin_ws/src
cd ~/catkin_ws/src
catkin_init_workspace
2:编译
git clone https://github.com/TixiaoShan/LVI-SAM.git(如果网速太慢,也可以下载压缩包然后进入目录)
cd …
catkin_make
3:打开终端运行launch文件
cd ~/catkin_ws/devel
source setup.bash
roslaunch lvi_sam run.launch(到这里已经可以看到rviz显示窗口)
4:运行数据集开始建图
rosbag play handheld.bag(需要重新打开一个终端运行数据,数据集名称是自己下载文件的名称,一定记得把数据集放在devel文件夹下)
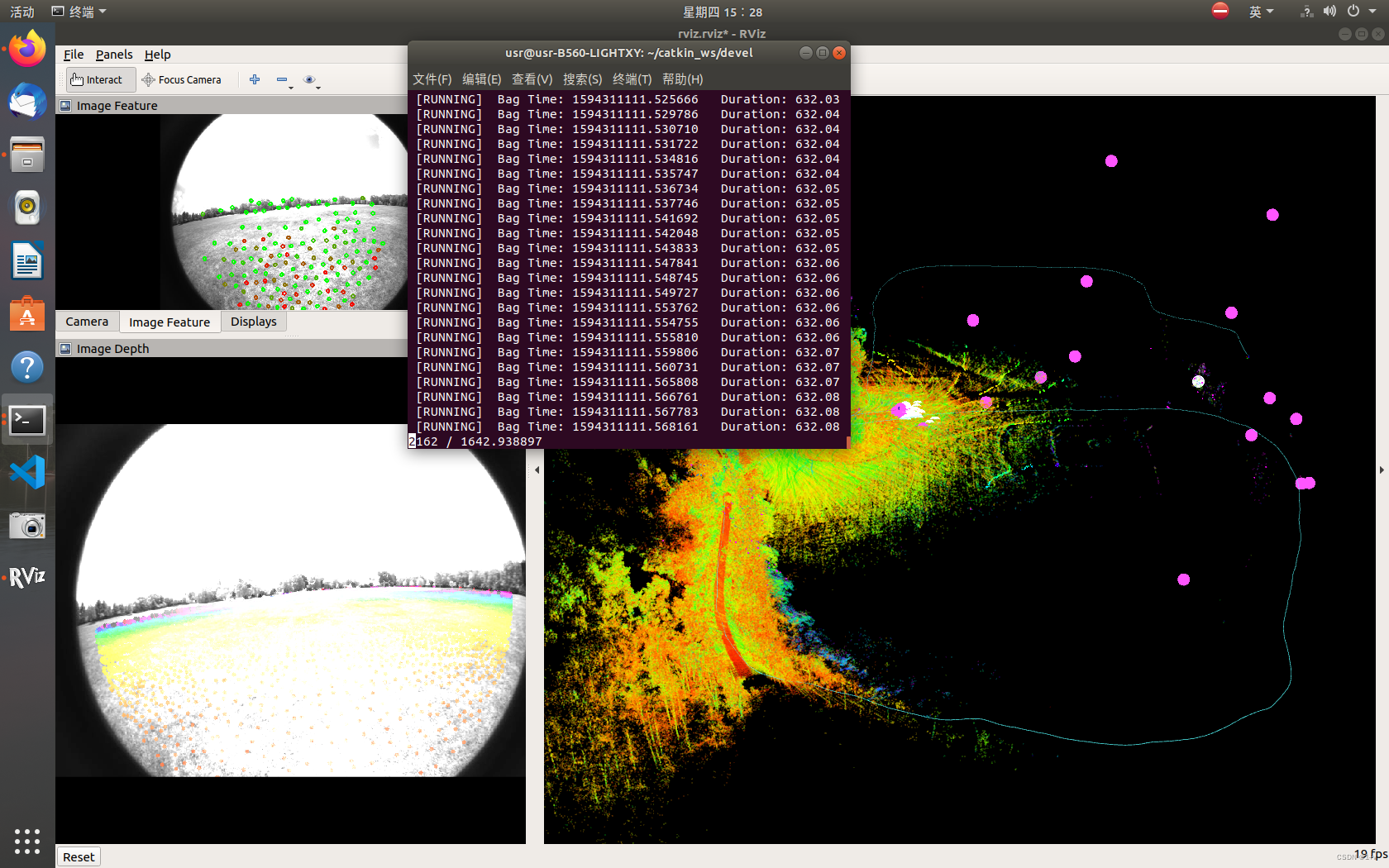
可以看到已经开始建图,最终这个数据集的结果已经放在最上面了
3. 代码阅读
 代码主要分为雷达和激光部分,先看的是utiliy.h。
代码主要分为雷达和激光部分,先看的是utiliy.h。
这个文件主要定义了一大堆的变量,初始函数,包括系统各个部分的参数。包括了三paramserver函数
第一个:定义了很多ROS 的参数变量。
 第二个:进行paramServer函数重载,用于处理ROS 相关参数。
第二个:进行paramServer函数重载,用于处理ROS 相关参数。
第三个:用于从ROS 中读取和初始化参数

在P函数之后:
/定义转换IMU数据函数,接受一个 sensor_msgs::Imu 类型的输入消息 imu_in,
//对输入消息中的线性加速度、角速度以及方向(四元数)进行转换
//最后返回转换后的 sensor_msgs::Imu 消息。
sensor_msgs::Imu imuConverter(const sensor_msgs::Imu& imu_in)
{
sensor_msgs::Imu imu_out = imu_in;
// 创建acc对象存储线性加速度
Eigen::Vector3d acc(imu_in.linear_acceleration.x, imu_in.linear_acceleration.y, imu_in.linear_acceleration.z);
acc = extRot * acc;
//rotate acceleration将经过旋转矩阵 extRot 变换后的线性加速度向量的各个分量分别赋值给输出IMU消息 imu_out 的线性加速度字段。
imu_out.linear_acceleration.x = acc.x();
imu_out.linear_acceleration.y = acc.y();
imu_out.linear_acceleration.z = acc.z();
// rotate gyroscope创建Eigen向量 gyr,包含imu_in 中的角速度数据。
Eigen::Vector3d gyr(imu_in.angular_velocity.x, imu_in.angular_velocity.y, imu_in.angular_velocity.z);
//使用3x3旋转矩阵 extRot 来旋转角速度向量 gyr
gyr = extRot * gyr;
//将旋转后的角速度向量的分量赋值给输出IMU消息 imu_out 的角速度字段
imu_out.angular_velocity.x = gyr.x();
imu_out.angular_velocity.y = gyr.y();
imu_out.angular_velocity.z = gyr.z();
// rotate roll pitch yaw旋转俯仰,偏航,滚转。
//创建四元数对象
Eigen::Quaterniond q_from(imu_in.orientation.w, imu_in.orientation.x, imu_in.orientation.y, imu_in.orientation.z);
//qform乘以四元数,表示两次旋转组合
Eigen::Quaterniond q_final = q_from * extQRPY;
//将四元数q_final的各个分量(x,y,z,w)赋值给输出IMU数据
imu_out.orientation.x = q_final.x();
imu_out.orientation.y = q_final.y();
imu_out.orientation.z = q_final.z();
imu_out.orientation.w = q_final.w();
//如果四元数的模(长度)小于0.1,则打印错误消息并调用 ros::shutdown() 来关闭ROS节点
if (sqrt(q_final.x()*q_final.x() + q_final.y()*q_final.y() + q_final.z()*q_final.z() + q_final.w()*q_final.w()) < 0.1)
{
ROS_ERROR("Invalid quaternion, please use a 9-axis IMU!");
ros::shutdown();
}
return imu_out;
}
};
//定义一个模板函数publishCloud,用于将点云数据转换为sensor_msgs::PointCloud2.
//T是类型参数
template<typename T>
sensor_msgs::PointCloud2 publishCloud(ros::Publisher *thisPub, T thisCloud, ros::Time thisStamp, std::string thisFrame)
{
//定义一个sensor_msgs::PointCloud2类型的变量tempCloud,用于存储转换后的点云消息。
sensor_msgs::PointCloud2 tempCloud;
//使用PCL中的toROSMsg函数将输入的点云数据thisCloud转换为sensor_msgs::PointCloud2格式并存储到tempCloud中。
pcl::toROSMsg(*thisCloud, tempCloud);
//设置tempCloud的时间戳为thisStamp。
tempCloud.header.stamp = thisStamp;
//设置tempCloud的坐标系(frame)为thisFrame。
tempCloud.header.frame_id = thisFrame;
if (thisPub->getNumSubscribers() != 0)
thisPub->publish(tempCloud);
return tempCloud;
}
//返回时间戳
template<typename T>
double ROS_TIME(T msg)
{
//
return msg->header.stamp.toSec();
}
template<typename T>
//imu坐标系数据转化为ros坐标系
void imuAngular2rosAngular(sensor_msgs::Imu *thisImuMsg, T *angular_x, T *angular_y, T *angular_z)
{
*angular_x = thisImuMsg->angular_velocity.x;
*angular_y = thisImuMsg->angular_velocity.y;
*angular_z = thisImuMsg->angular_velocity.z;
}
template<typename T>
//用于从ROS的sensor_msgs::Imu消息中提取线性加速度数据,并将其赋值给提供的指针参数。
//sensor_msgs::Imu是ROS中的一个标准消息类型,用于表示IMU(惯性测量单元)数据。
// `thisImuMsg`: 指向`sensor_msgs::Imu`消息的指针。
//`acc_x`, `acc_y`, `acc_z`: 指向要存储加速度值的变量的指针。
//函数内部,它将`thisImuMsg`中的`linear_acceleration.x`,`linear_acceleration.y`和`linear_acceleration.z`分别赋值给`acc_x`,`acc_y`和`acc_z`所指向的变量。
void imuAccel2rosAccel(sensor_msgs::Imu *thisImuMsg, T *acc_x, T *acc_y, T *acc_z)
{
*acc_x = thisImuMsg->linear_acceleration.x;
*acc_y = thisImuMsg->linear_acceleration.y;
*acc_z = thisImuMsg->linear_acceleration.z;
}
template<typename T>
//用于从ROS的sensor_msgs::Imu消息中提取四元数形式的姿态信息,并将其转换为欧拉角,然后赋值给提供的指针参数。
void imuRPY2rosRPY(sensor_msgs::Imu *thisImuMsg, T *rosRoll, T *rosPitch, T *rosYaw)
{
// `thisImuMsg`: 指向`sensor_msgs::Imu`消息的指针。
// `rosRoll`, `rosPitch`, `rosYaw`: 指向要存储欧拉角值的变量的指针。
// 首先使用`tf::quaternionMsgToTF`函数将ROS消息中的四元数转换为`tf::Quaternion`类型。
//使用`tf::Matrix3x3`和`getRPY`方法从四元数中提取欧拉角,将这些值赋给`rosRoll``rosPitch`和`rosYaw`所指向的变量。
double imuRoll, imuPitch, imuYaw;
tf::Quaternion orientation;
tf::quaternionMsgToTF(thisImuMsg->orientation, orientation);
tf::Matrix3x3(orientation).getRPY(imuRoll, imuPitch, imuYaw);
*rosRoll = imuRoll;
*rosPitch = imuPitch;
*rosYaw = imuYaw;
}
//计算点到原点的距离
float pointDistance(PointType p)
{
return sqrt(p.x*p.x + p.y*p.y + p.z*p.z);
}
//计算两点之间的距离
float pointDistance(PointType p1, PointType p2)
{
return sqrt((p1.x-p2.x)*(p1.x-p2.x) + (p1.y-p2.y)*(p1.y-p2.y) + (p1.z-p2.z)*(p1.z-p2.z));
}
以上代码注释基本是根据每一行的内容完成,因为自己水平不高,其中有好多指针指来指去,看得很难受,希望有大佬能对以上注释提出修改意见,感激不尽。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









