






本篇重点
Stable Diffusion-webui-forge的整合包下载,安装,基础知识和软件的使用技巧,webui-forge在原有的webui的基础上进行了升级,支持sd3.5和flux生图,FLUX需要的F1模型,双clip,VAE已放置到相应文件夹内,下载后可以直接调用,演示所使用的麦橘写实大模型和冰雪奇缘lora也放到了对应文件夹下,下载后可以直接调用,演示的提示词搭配大模型及lora可以在软件上直接复刻
评测
演示所使用的是笔记本4070显卡,8G显存,FLUX会爆显存,没办法测试,所以演示的是使用麦橘写实大模型完成绘图,参数可以参照我的进行调整,如果结束绘图显示黑色的图片,大概率是爆显存了,调整图片大小再尝试,如果出现了噪点图,可能是VAE的问题,VAE栏空置再尝试。出一张1024*1024的图大概需要12.3秒左右
效果展示



整合包获取
这份完整版的SD整合包已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

一:整合包下载及安装
将整合包解压到无中文路径的文件夹内,如图所示
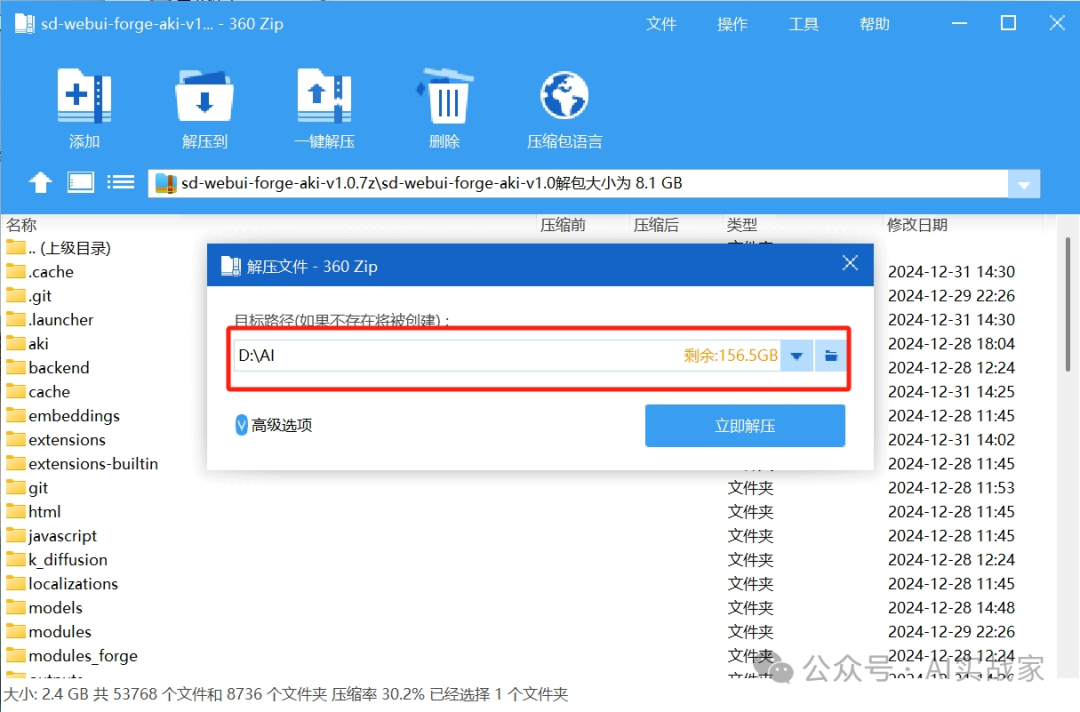
二:基础配置
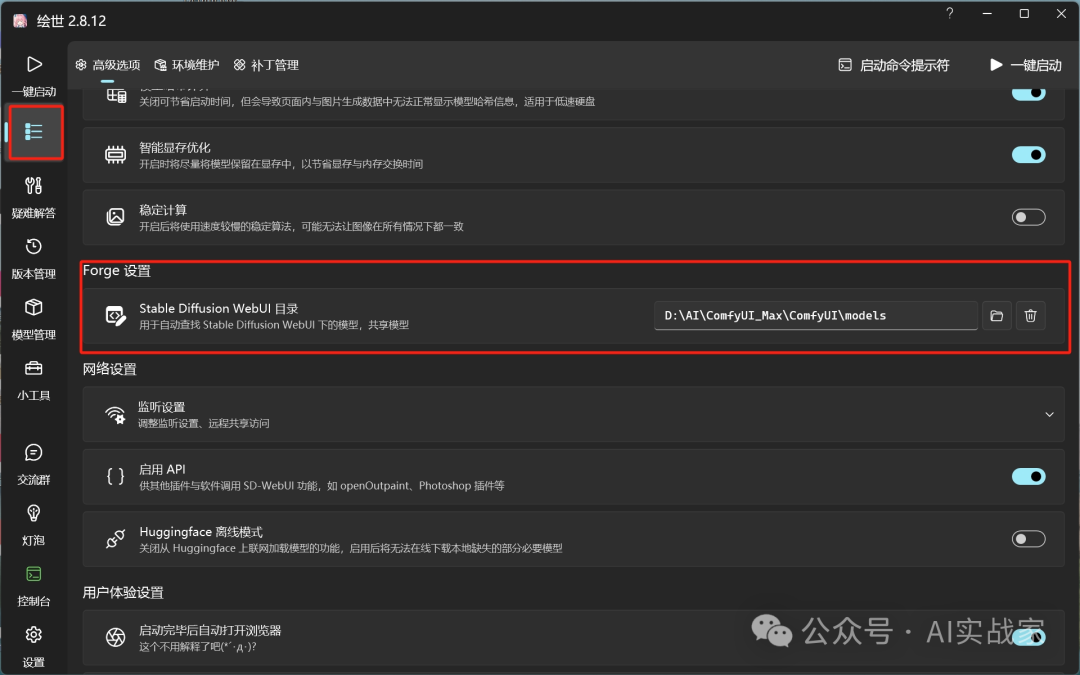
基本保持默认即可,如果你使用的是comfyui,可以在高级选项>Forge设置>选择comfyui的models,使两个软件共用一套模型
三:模型放置(常用的放置地址)
大模型:根目录\models\Stable-diffusion
lora:根目录\models\Lora
VAE:根目录\models\VAE
clip:根目录\models\text_encoder
ControlNet:根目录\models\ControlNet
四:实操演示
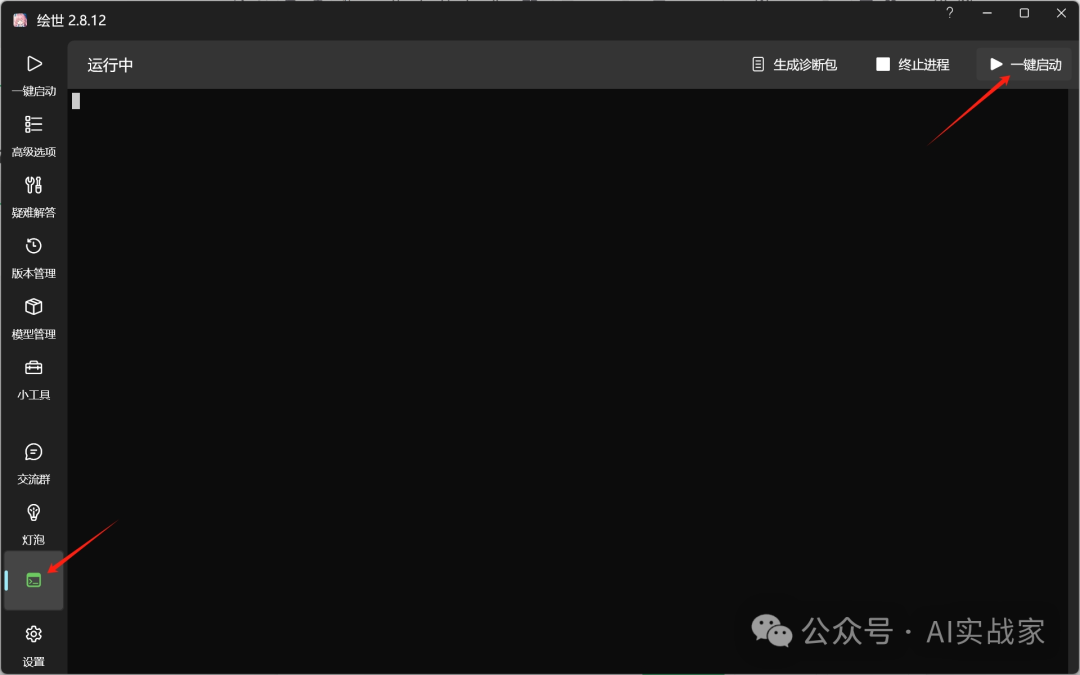
1:配置完后,点击控制台,一键启动,等待加载,加载完后会自动跳转网页
2:UI选择全部,大模型,VAE(有些大模型自带VAE,可以不选)

3:输入提示词添加Lora,并且修改权重
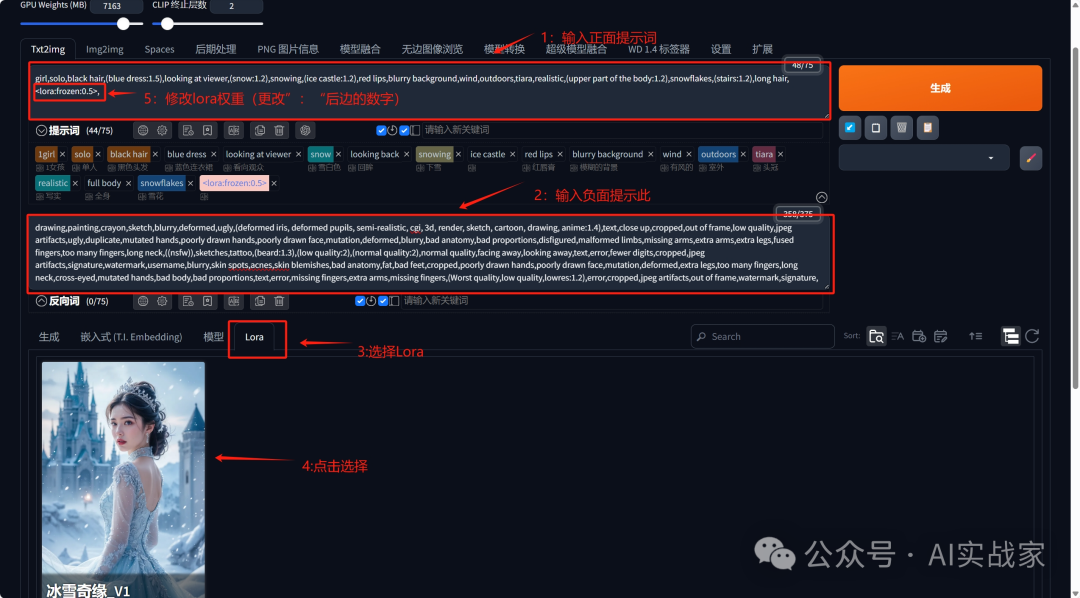
正向提示词
girl,solo,black hair,(blue dress:1.5),looking at viewer,(snow:1.2),snowing,(ice castle:1.2),red lips,blurry background,wind,outdoors,tiara,realistic,(upper part of the body:1.2),snowflakes,(stairs:1.2),long hair,lora:frozen:0.5,
负面提示词
drawing,painting,crayon,sketch,blurry,deformed,ugly,(deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime:1.4),text,close up,cropped,out of frame,low quality,jpeg artifacts,ugly,duplicate,mutated hands,poorly drawn hands,poorly drawn face,mutation,deformed,blurry,bad anatomy,bad proportions,disfigured,malformed limbs,missing arms,extra arms,extra legs,fused fingers,too many fingers,long neck,((nsfw)),sketches,tattoo,(beard:1.3),(low quality:2),(normal quality:2),normal quality,facing away,looking away,text,error,fewer digits,cropped,jpeg artifacts,signature,watermark,username,blurry,skin spots,acnes,skin blemishes,bad anatomy,fat,bad feet,cropped,poorly drawn hands,poorly drawn face,mutation,deformed,extra legs,too many fingers,long neck,cross-eyed,mutated hands,bad body,bad proportions,text,error,missing fingers,extra arms,missing fingers,(Worst quality,low quality,lowres:1.2),error,cropped,jpeg artifacts,out of frame,watermark,signature,
4:调节参数
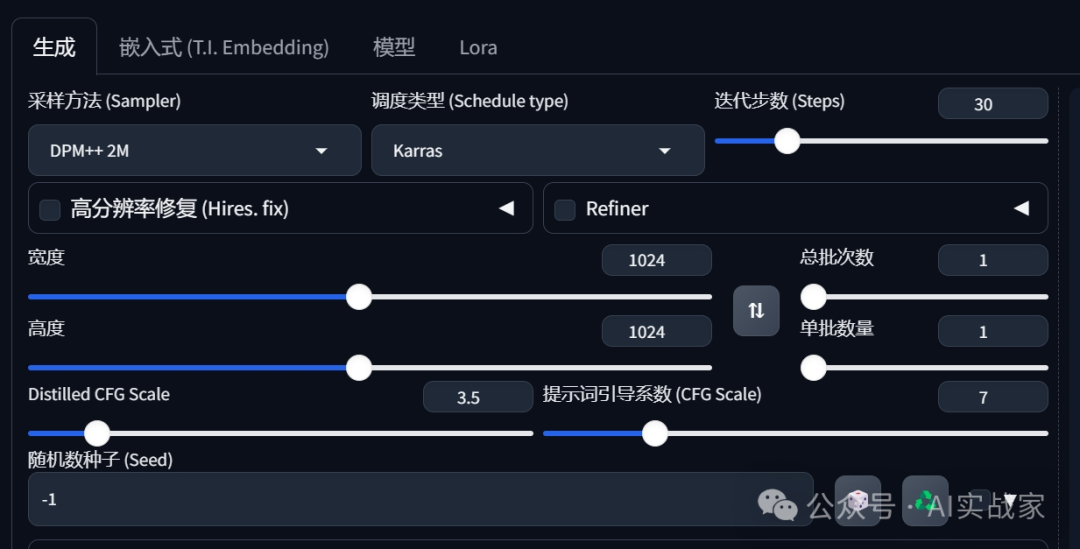
5:点击生成
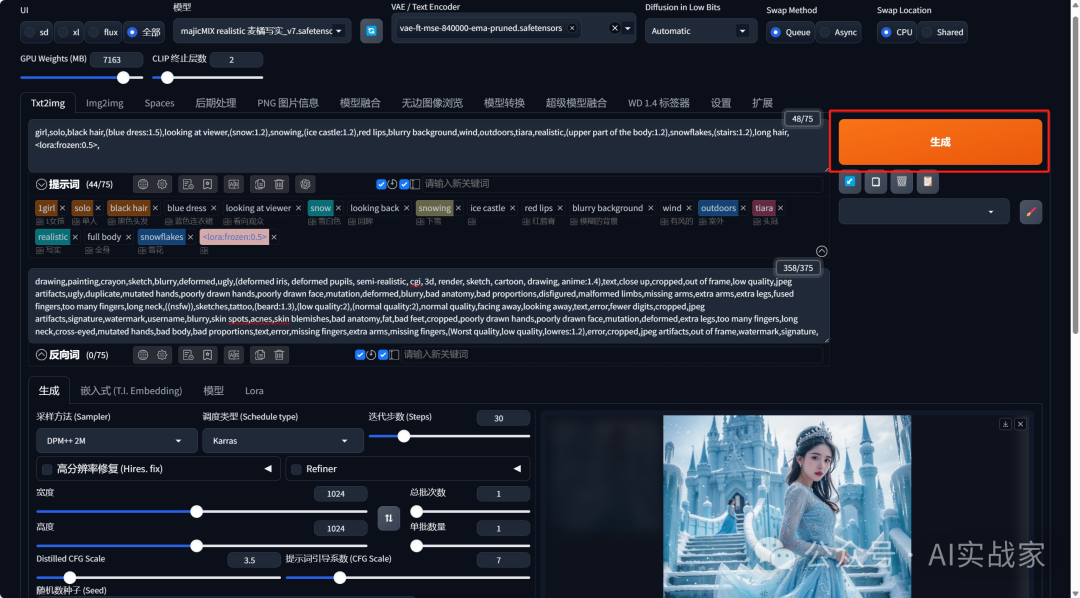
五:客户端问题解答
| 问题 | 备注 |
|---|---|
| embedding提示词集合 | 常用在反向提示词,防止崩坏等,省去了填写大量提示词的问题, |
| 反向提示词 | nsfw降低不该出现的图概率,图片崩坏建议使用embedding(例如NG-DeepNegative-V1-75T崩坏的人体结构,badhandv4改善手部细节) |
| CFG | Classifier Free Guidance scale(分类器自由指导比例)是一个参数,用于控制模型应尊重你的提示的程度。如果CFG值太低,稳定扩散将忽略你的提示。太高时图像的颜色会饱和。 1–大多忽略你的提示。3–更有创意。7–遵循提示和自由之间的良好平衡。15–更加遵守提示,图片的对比度和饱和度增加。30–严格按照提示操作,但图像的颜色会过饱和。 CFG在4-10之间都非常适合,但最佳的还是建议将迭代步数还有采样方法结合起来看。 |
| 图片无损放大 | 二次元算法采用:R-ESRGAN 4X+Anime6B;处理真人 高清化/extras |
| <>尖括号 | 主要用来调用lora,lora:文件触发:权重 |
| clip终止层数 | ClipSkip为1:处理到最后一层(即所有层)ClipSkip为2:处理到倒数第二层(忽略最后一层)ClipSkip为3:处理到倒数第三层(忽略最后和倒数第二层)值较小,生成含有丰富提示词的插图;ClipSkip的值较大,生成忽略提示词的插图(被丢掉的提示词就越多) |
| 放大模型 | 相片类的:LDSR(但速度很慢),或者ESRGAN_4x(如果你想要超级清晰的细节和/或速度)。绘画类的:ESRGAN_4x(写实)提供高油漆纹理和细节,General-WDN提供更好的整体外观动漫类的:Anime6B,也适合将某些东西变成动画。 |
| Tiled diffusion | 方案:指的是两种算法以供选择;覆盖图像尺寸:指的是能够做出超出原有SD模型的限制,做出更大的图像(比如类似于清明上河图的那种超宽影像)潜空间分块宽/高度:就是那个图里面的小框宽高度,一般来说选64-160之间的值(最佳的数值选取其实取决于你选的潜空间分块单批数量,以及你所用模型的最佳生成图片大小【模型最好使用未剪枝的】,一般的建议选择是96或128)潜空间分块单批数量:类似于生成图中的“单批数量”参数,这个看显卡性能,一般来说越大越快,这里的可供选择区间是1到8。潜空间分块重叠:重叠数值提高会减少融合中的接缝。显然,较大的重叠值意味着更少接缝,但会显著降低速度,因为需要重新绘制更多的小块。(一般建议使用MultiDiffusion时选择32或48,使用MixtureofDiffusers选择16或32) |
| Tiled VAE | 这个是有关电脑性能的选项,勾选这个将会极大降低VAE编解大图所需的显存开销,几乎无成本的降低显存使用。以highres.fix为例,如果你之前只能进行1.5倍的放大,则现在可以使用2.0倍的放大。 不过一般来说你不需要更改默认参数,只有在以下情况下才需要更改参数: 一是当生成之前或之后看到CUDA内存不足错误时,请降低tile大小;二是当你使用的tile太小且图片变得灰暗和不清晰时,请启用编码器颜色修复。 |
| 采样器 | 老牌采样器经典Euler a (加a的是在每一次去操的时候增加一点新的噪点进去,每次生成都会变动,不收敛,去掉a的画面生成最后会趋近于稳定,可收敛)Euler DPM采样器DPM2算法的画面有提升,但是时长增加一倍,不推荐,带有Karras算法的采样器,8步后噪点更少,所以直接选择带有Karras的算法即可2S和2M的区别:S代表单步算法,M代表多步算法增加了相邻层之间的信息传递,所以选择带有M算法的即可,所以最后筛选:DMP++2M Karras 最推荐的算法,收敛,速度快,质量不错DMP++SDE Karras 随机微分方程,不收敛,高品质,速度慢,真实系追求画面可以选DMP++2M SDE Karras 2M和SDE的这种算法,不收敛,速度有所提升DMP++2M SDE Exponential 指数算法,不收敛,细节少一些,但是画面更柔和干净, DPM++3M SDE Karras DPM++3M SDE Exponential 这两个3M速度和2M一样,需要更多采样步数,调低CFG采样步数>30步效果更好,也就是采样步数超过30,可以尝试使用这一类算法 2023采样器Unipc 2023新采样器,统一预测矫正器,兼容性很好,收敛,10步左右就能生成可用画面Restart 每步渲染时间长些,但只需很少的采样步数,就能生成质量相当不错的图片,有潜力 如果你想使用快速且质量不错的东西,那么最好的选择是DPM++2M Karras,UniPC如果你想要高质量的图像并且不关心收敛,那么不错的选择是DPM++SDE Karras如果你喜欢稳定、可重复的图像,请避免使用任何ancestral samplers(加a的东西)。如果你喜欢简单的东西,Euler和Heun是不错的选择。 |
六:使用技巧及案例展示
| 描述词格式 | 1,画质词+画风词2,画面主题描述3,环境,场景,灯光,构图4,lora5,负面词 |
|---|---|
 | |
| ()关键词权重 | 默认词的权重都是1,词越靠前权重越大,每层()权重增加0.1倍,每层{}权重增加0.01倍,每层[]权重降低0.1倍,括号最多套三层,也可以(关键词:1.1)来进行权重的加减,权重值建议设置在0.3~1.5之间 |
| 交替采样 | [提示词1|提示词2],意思就是交替采样,案例 1 girl,upper body,[blue | red] hair,意思就是红色和蓝色交替采样,会生成一个红蓝相间头发的女孩 |
 | |
| 渐变 | [提示词1:提示词2:0~1数值],案例:forest,lots of trees,[stones:flowers:0.7],表示前70%石头采样后30%花朵采样,这样就会生成以石头为主,花朵为点缀的森林图片, |
 | |
| 控制采样 | 1:[提示词:0~1的数值],案例:forest,lots of trees and stones,[flowers:0.7],表示整体采样值到达70%时开始进行花的描述,这样就会出现花会很少的森林图像2:[提示词::0~1的数值],案例:forest,lots of trees and stones,[flowers::0.7],表示从开始就进行花的采样,到达70%的进程后停止采样,这样出现的花会比上一个语法多出来一些 |
 | |
| _下划线 | 起连接作用,比如banana cake图片可能会出现一根香蕉和1个蛋糕,如果是banana_cake图片会出现一个香蕉蛋糕 |
 |
| 脸崩的问题 |
|---|
| 采样分配不够,近景可以得到更多的采样分配,脸崩概率小,远景的采样分配少,所以会出现脸崩的情况, 解决方法1:图片分辨率保持较低合理的范围,然后开启高清修复,图片放大两倍,图片分辨率就上来了,可以解决脸崩的问题,但不是最优解,因为高清修复是提高了整体的分辨率,脸部只是增加了一点,但是会大幅增加渲染时间 解决方法2:发送到图生图,利用蒙版把脸遮住,然后选择仅蒙版区域,可以高效解决脸崩问题(适合单个人脸,如果出现很多,则会大大增加工作量) 解决方案3:拓展安装(从网站下载):https://github.com/Bing-su/adetailer.git插件,然后到https://huggingface.co/Bingsu/adetailer/tree/main中下载face_yolov8m.pt,face_yolov8n.pt,face_yolov8n_v2.pt,face_yolov8s.pt,这几个用来修复人脸的模型had是修复手部的模型,person是用来增加人物整体细节的模型,放到SD目录/models/adetailer中,使用的时候勾选启用ADetailer,选择修复模型(mediapipe_face_full只能对真人生效),选择后下方框框输入detail face即可修复脸部(关键词如果增加微笑,生气,闭眼等,图片也会进行微调),也可以组合使用,单元1增加人物整体细节,单元2mediapipe_face_full下方框框输入detail face,单元3选择手部修复不加词, |
| 手指的问题 |
| 解决方法1:在开始生成图片的时候输入负面提示词添加:残缺的手指,六个手指等,(找反向提示词集:bad-hands-5) 解决方法2:openpose骨骼图,打开文生图界面,通过controlnet,上传一张图片,然后通过openpose来获取同款手指姿势,点启用和完美像素模式,模型控制选择openpos(姿势),然后预处理器选择dw_openpose_full,模型选择openpose相同的,点击预处理结果(预处理器后边的爆炸标志),然后进行生图片,如果手部需要调整怪,固定种子数,然后在拓展一行找到openpose编辑器(在线库搜索openpose-editor安装),点击姿势图右下角的编辑,对骨骼图进行调整,调整完发送到controlnet,然后生成,缺点:图片会有少许变动,可以将图片发送到图生图,然后把骨骼图保存下来,加载到图生图的controlnet,控制类型选择openpose(姿势),预处理器选择无(因为有了骨骼图),模型还是openpose,然后点击生成,在图片和图片会和原图非常接近,如果不希望图片有任何其他的变化,将图片发送到局部重绘,用画笔工具将图片手部涂鸦,然后打开controlnet,将骨骼图拖入,点击启用,控制类型选择openpose(姿势),预处理器选择无,选择重绘蒙版内容,蒙版区域内容处理选择填充,重绘区域选择整张图片,生成即可;进阶:多重控制(openpose骨骼图),比如爱心的手势,打开文生图界面,通过controlnet0,上传一张图片,然后通过openpose来获取同款手指姿势,点启用和完美像素模式,模型控制选择openpos(姿势),然后预处理器选择dw_openpose_full,模型选择openpose相同的,点击预处理结果(预处理器后边的爆炸标志),然后进行生图片,图片如果很奇怪,点击controlnet1启用,点击完美像素,控制类型选择深度,预处理器选择depth_midas,模型选择和depth相同的,控制权重0.6,然后将通过controlnet0(姿势控制)的权重也调整到0.6,点击生成,如果还是奇怪,点击controlnet2启用,点击完美像素,控制类型选择Softedge(软边缘),预处理器选择Softedge_pidinet,模型选择Softedge相关的,权重改成0.6,点击预处理结果(爆炸按钮),再次点击生成即可 解决方案3:安装Depth Library拓展插件,安装手部模型进行解决 |
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

这份完整版的AI新手入门资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 819
819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









