






Stable Diffusion作为一款文本生成图像的AI绘画工具,其核心功能之一就是文生图(txt2img)。打开WebUI页面,首先映入眼帘的就是文生图功能面板。该面板包含提示词输入区、采样设置、分辨率设置等关键组件。提示词输入区分为提示词和负向提示词,用于精确控制生成内容及避免不想要的效果。采样设置中的采样方法和步数对图像质量有显著影响。分辨率设置则决定了生成图像的尺寸。通过合理配置这些参数,用户可以轻松生成高质量的图像。这份教程将带你深入了解如何利用Stable Diffusion的文生图功能,开启你的AI绘画创作之旅。
Stable Diffusion 作为一款文本生成图像的 AI 绘画工具,其最核心的能力就是『文生图(txt2img)』,我们打开 WebUI 页面的第一个栏目就是文生图的功能面板。如图:
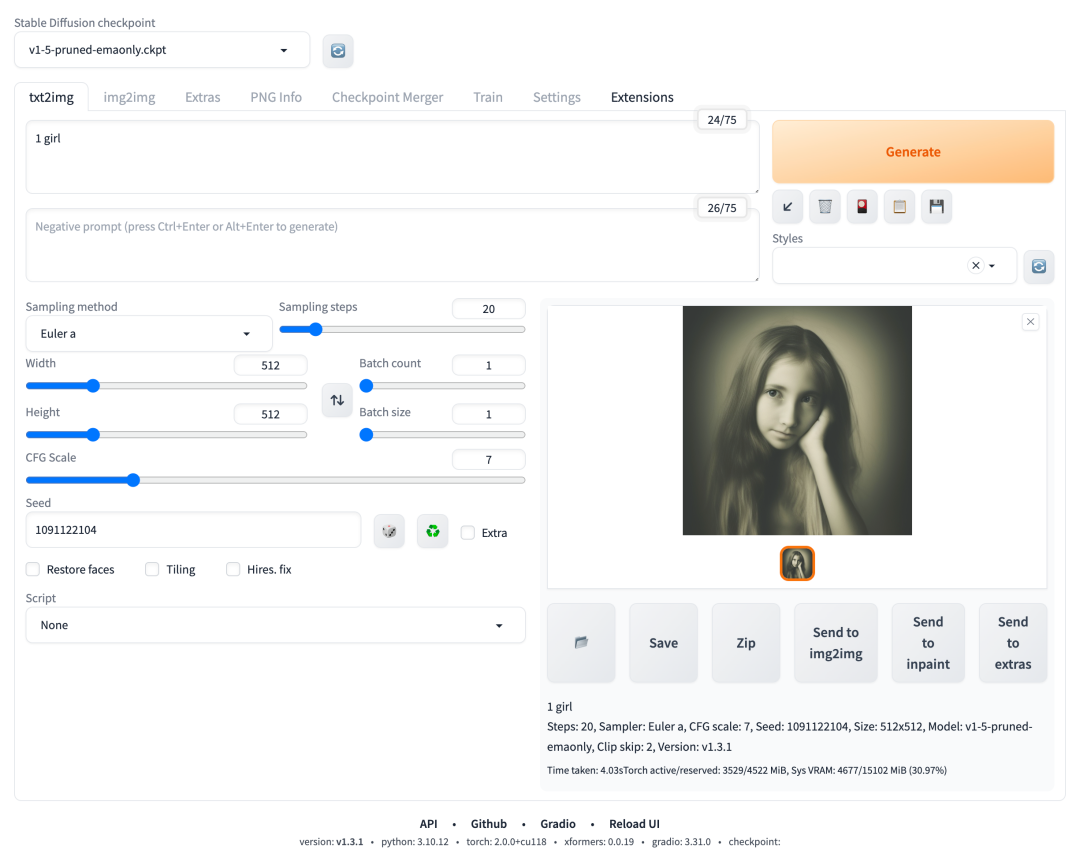 文生图(txt2img)功能面板
文生图(txt2img)功能面板
图中展示了跟文生图相关的功能组件:
-
1、提示词输入区
-
- 1.1、提示词(Prompt)
- 1.2、负向提示词(Negative prompt)
-
2、采样设置
-
- 2.1、采样方法(Sampling method)
- 2.2、采样步数(Sampling steps)
-
3、分辨率设置
-
- 3.1、宽(Width)
- 3.2、高(Height)
-
4、任务批次设置
-
- 4.1、生成图片次数(Batch count)
- 4.2、一次生成图片数量(Batch size)
-
5、提示词相关性(CFG Scale)
-
6、种子设置
-
- 6.1、种子(Seed)
- 6.2、额外种子参数(Extra Seed Options)
-
7、重建人脸(Restore faces)
-
8、无缝贴片(Tiling)
-
9、高分辨率修复(Hires. fix)
-
10、生成任务启动(Generate)
-
11、生成图预览和功能区
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

这份完整版的AI新手入门资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

我们接下来一一介绍它们。
1、提示词输入区
提示词输入区包括两个部分:
- 1.1、提示词(Prompt)
- 1.2、负向提示词(Negative prompt)
 提示词输入区
提示词输入区
**提示词(Prompt)**是告诉 Stable Diffusion 你想要生成的内容。提示词的写法和效果与模型训练时使用的提示词数据有关,不同的模型所用的提示词可能有差异。有些提示词在当前的模型下可能不生效,导致结果不如预期,所以还需要多多尝试。另外,编写提示词还需要遵循一定的规则,比如使用 () 调整提示词的权重来影响模型的生成结果。此外,当我们编写提示词时,最好也能按照一定的结构来组织词语,通常提示词中可以包含主体描述、主体特征、背景描述、光线、视角、画风等部分。对于提示词的编写,涉及到的技巧还是比较多的,这里先略作介绍,我们将在下一节专门用一篇内容来详细说明。
**负向提示词(Negative prompt)**则是告诉 Stable Diffusion 在生成图像时要避免的内容或影响。比如通常大家会用 worst quality、low quality、grayscale、monochrome 等词来避免生成低质量的图像,也会用 missing arms、extra legs、fused fingers、too many fingers、unclear eyes 等词来避免生成一些不合理的内容。
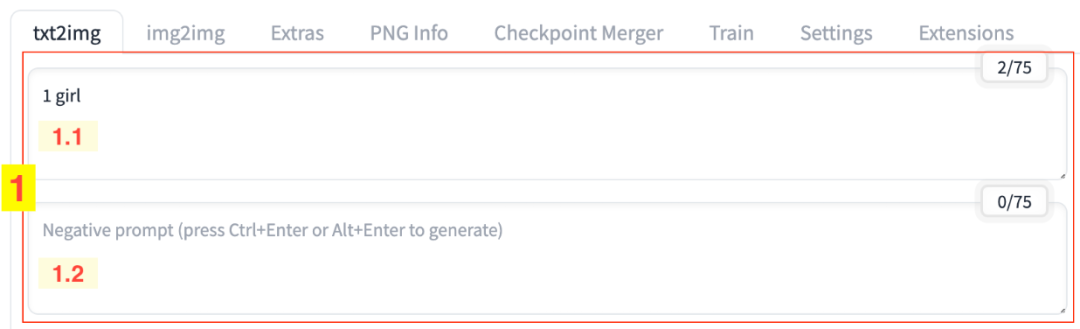
我们这里将提示词前面 1 girl 按结构来做一些优化,注意提示词内容不包括括号内的说明:
a young girl with brown eyes(主体描述), wearing a white outfit(主体特征), sitting outside cafe(背景描述), side light(光线), full body shot(视角), by Vincent van Gogh(画风)
同时,我们增加负向提示词:
worst quality, low quality, grayscale, monochrome, missing arms, extra legs, fused fingers, too many fingers, unclear eyes
点击生成,我们得到的图像效果如下:
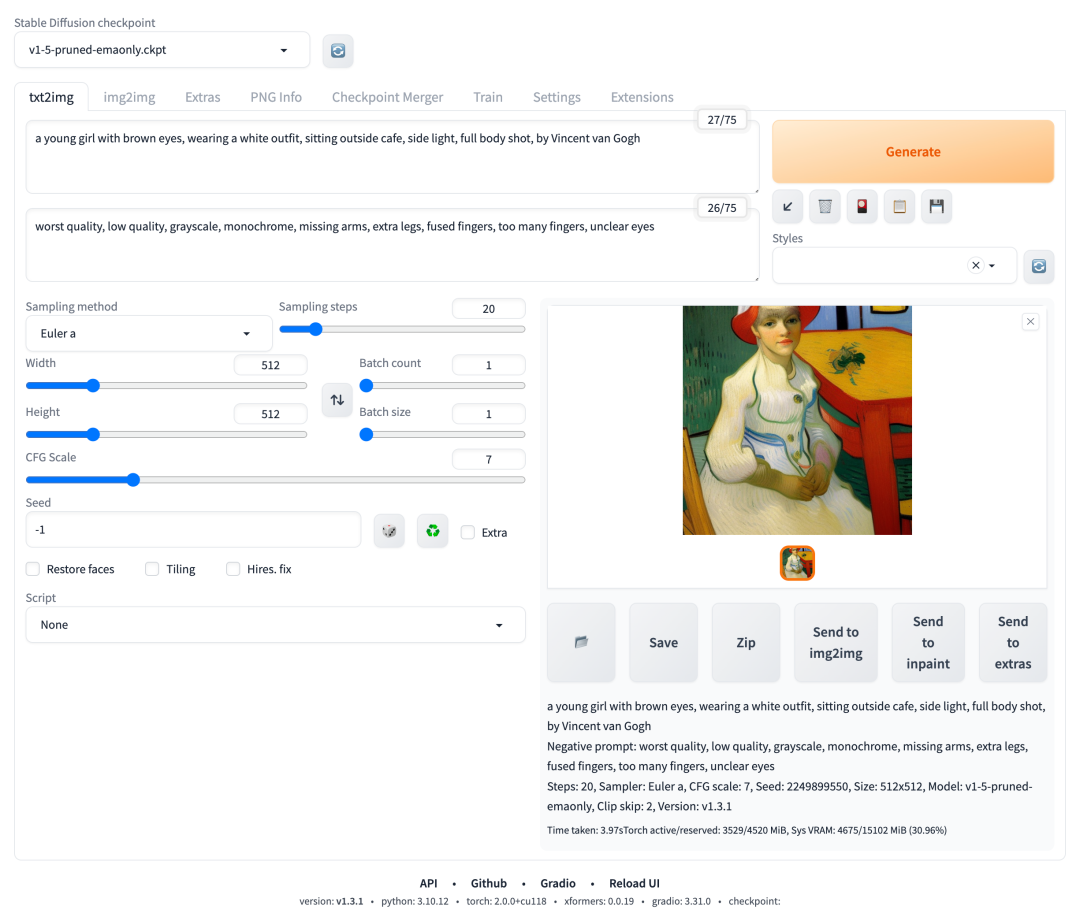 提示词和负向提示词优化后的尝试
提示词和负向提示词优化后的尝试
可以看到提示词起到了一些效果,但是还有不少的优化空间。关于提示词的编写技巧,我们将在后面进一步探索。
下方2000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
2、采样设置
采样设置包括两个部分:
- 2.1、采样方法(Sampling method)
- 2.2、采样步数(Sampling steps)
 采样设置
采样设置
Stable Diffusion 的绘画过程是一个对随机噪声一步一步进行降噪的过程,这里每一步降噪称为一次采样(Sampling)。
**采样方法(Sampling method)**则是 Stable Diffusion 在每次采样时使用的算法,这里的算法有很多种,我们在 WebUI 中可以在下拉框中选择,如图:
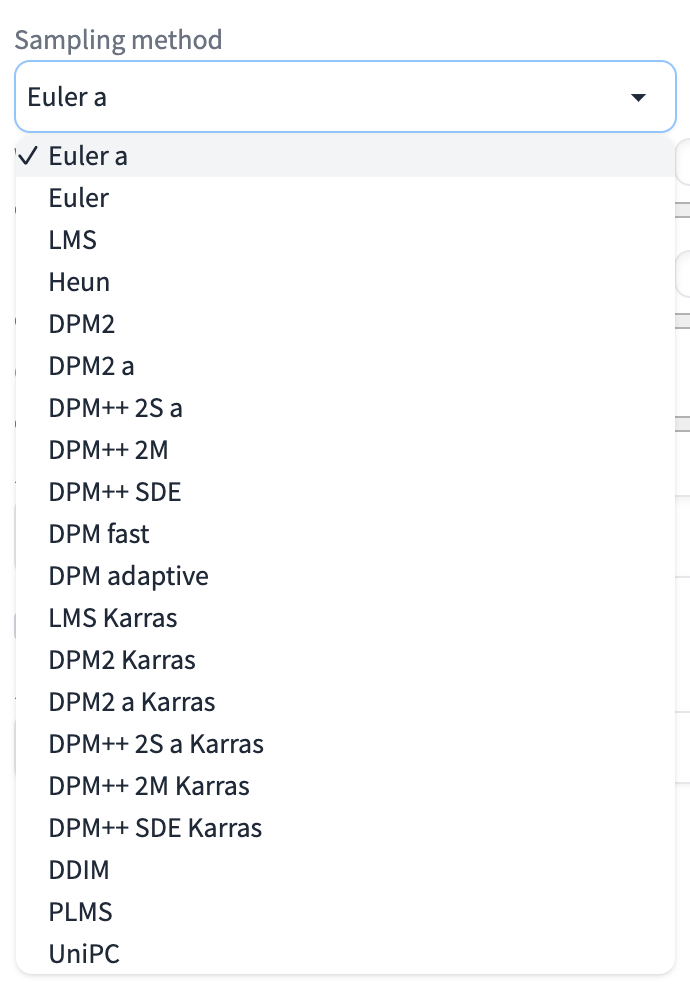 采样方法
采样方法
**采样步数(Sampling steps)**则是设置 Stable Diffusion 在绘图时使用你选择的采样方法进行降噪的步数。
下图是一名用户在 Reddit 网站上发布的部分采样方法在不同采样步数时的生成图效果对比图:
 不同采样方法和采样步数的生成图效果
不同采样方法和采样步数的生成图效果
从这张图中可以一目了然的看到采样方法和采样步数对 Stable Diffusion 绘图的影响。
采样步数这个参数还是比较好理解的,总体上来讲,采样步数设置太低,会导致出图模糊效果较差,设置太高,则会绘图耗时较长,而且步数超过一个阈值后也不会对图像质量有更大的提升,所以大部分情况下可以根据不同的场景按需设置:
- 如果是测试提示词的出图效果,希望快速看到生成图,可以设置采样步数为 10-15 区间;
- 如果是正式出图,可以设置采样步数为 20-30 区间;
- 如果想要生成的图像会包含丰富的细节,比如动物毛皮、材质纹理、复杂光线等,可以设置采样步数为 30-40 区间。
但是作为一名普通使用者,要去理解不同采样方法的原理可能就有些难度了。我们这里不做过多探讨,直接给大家几条选择采样方法的建议:
- 如果想兼顾生成速度和生成质量,可以选择
DPM++ 2M Karras(采样步数 20-30)、UniPC(采样步数 15-25); - 如果想要高质量的生成图不关心生成速度,可以考虑
DPM++ SDE Karras(采样步数 10-15)、DDIM(采样步数 10-15); - 如果想要快速出图,生成的图比较简单,质量过得去就行,可以选择
Euler、Heun,采样步数按需选择就行,步数越少,耗时越短; - 如果想让生成图多点随机和惊喜,可以试试这几个带
a的采样器:Euler a、DPM2 a、DPM++ 2S a、DPM2 a Karras、DPM++ 2S a Karras; - 如果想尽量保持生成图稳定可复现,则不要使用:
Euler a、DPM2 a、DPM++ 2S a、DPM2 a Karras、DPM++ 2S a Karras。
3、分辨率设置
分辨率设置包括两个部分:
- 3.1、宽(Width)
- 3.2、高(Height)
 分辨率设置
分辨率设置
这个很好理解,就是生成结果图像的宽高。但是虽然看起来简单,由于 Stable Diffusion 模型设计的限制,其实这里隐藏了一些限制是需要我们了解的:
- 可设置的最低分辨率是 512x512;
- 如果设置的分辨率过大或者宽高比例悬殊,生成图可能出现奇怪的结果。比如画人物时,可能出现身体叠加。但画风景时,也可能出现惊喜的效果。
- 如果确实想生成高分辨率图像,可以先将分辨率设置为同比例但宽高数值较小的尺寸,然后再用
Hires. fix来生成对应的高分辨率图像。Hires. fix我们会在后面介绍。 - 通过提示词生成图时,也要注意搭配合适的分辨率。比如,你想画一个站立的人物画,但是把分辨率设置宽高比 1:1 或者大于 1:1 的数值,那大概率是画不出想要的结果。
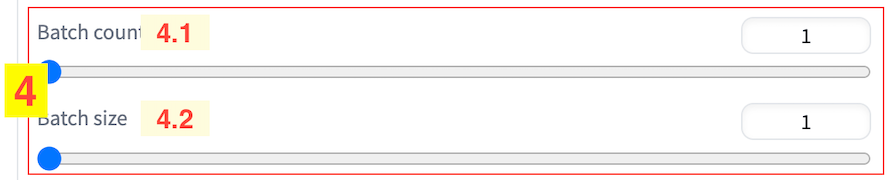
4、任务批次设置
任务批次设置包括两个参数:
- 4.1、生成图片次数(Batch count)
- 4.2、一次生成图片数量(Batch size)
 任务批次设置
任务批次设置
**生成图片次数(Batch count)**表示的是当前生成任务要跑几次。
**一次生成图片数量(Batch size)**表示的是当次生成任务要生成几张图片。
所以这两个设置项主要是提供根据当前提示词批量生成多张图像的能力。生成图片次数(Batch count)是通过将任务运行多次的方式来实现,是以时间换空间。一次生成图片数量(Batch size)则是通过在一次任务里生成多张图来实现,这样会需要更多显卡内存和计算资源,不过耗时会更短,是以空间换时间。
需要注意的是,虽然在生成过程中任务参数都是一样的,但是通过设置这两个参数批量生成的多张图片是不同的,这是怎么做到的呢?其实,你仔细观察一下生成的图片会发现,它们有着不一样的 Seed 值,原因就在于此。对于种子(Seed)我们会在后面详细介绍。
5、提示词相关性(CFG Scale)
**提示词相关性(CFG Scale)**里的 CFG 是 Classifier Free Guidance 的缩写,这个参数指的是生成图与输入提示词的相关性。
 提示词相关性
提示词相关性
提示词相关性(CFG Scale)可设置的数值范围是 1-30。该参数值越大,生成的图像越符合输入提示词的意图,但可能出现过于粗犷的线条和过度锐化的效果,导致图像失真;反之,这个参数值越小,生成的图像就越脱离输入提示词的限定,但图像质量和多样性可能会更好。一般来讲,将提示词相关性(CFG Scale)数值设置在 5-15 的区间是比较保险的。
不过,当提示词相关性(CFG Scale)数值设置较高,同时把采样步数(Sampling steps)也设置较高时,这时候可以缓解甚至抵消图像失真的问题,但是生成图像的耗时会比较久,大家可以自己尝试一下。
下图是不同提示词相关性(CFG Scale)和采样步数(Sampling steps)数值的示例效果图:
 提示词相关性和采样步数
提示词相关性和采样步数
6、种子设置
种子设置是 AI 绘画中比较重要的参数之一,在 WebUI 中对种子的设置包含两个部分:
- 6.1、种子(Seed)
- 6.2、额外种子参数(Extra Seed Options)
 种子设置
种子设置
6.1、种子(Seed)
我们在前面介绍过,Stable Diffusion 的绘画过程是将一个随机噪声一步一步进行降噪的过程,种子(Seed)则对应着这个随机噪声,它是 Stable Diffusion 构图的起源。种子值一般是一个整型的数值。
对于种子(Seed),这里有几点值得大家注意:
- 在绘图任务中,就算使用同样的提示词、采样设置、分辨率等等参数,只要 Seed 不一样,生成的图就不一样。
- 如果设置 Seed 数值一样,那么就会增加生成图的相似性,这时候其他参数不做大幅度的修改,一般可以生成比较近似的图。
- 如果所有的参数,包括使用的模型、绘图相关参数设置、Seed 值都设置为一样时,会复刻生成出一模一样的图。
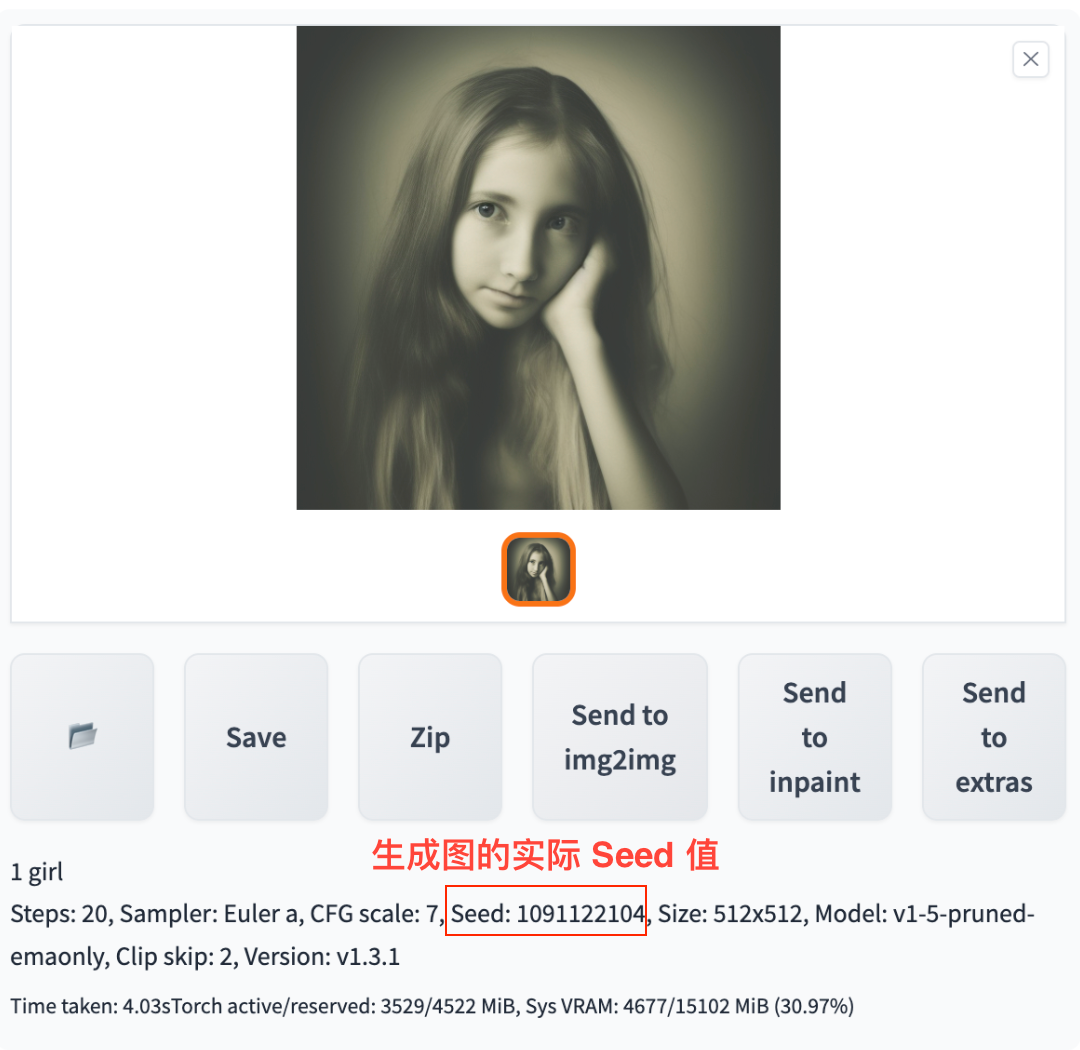
- 在批处理的任务中(设置了 Batch count 或 Batch size),就算你填入了 Seed 数值,最终生成图的 Seed 值也不一定是你指定的值,一般会是你填入的 Seed 值相差不大的值。批处理就是通过改变 Seed 值来保证生成多图时每张都不一样的。
- 最终生成图的实际 Seed 值可以在生成图预览区的图像信息中看到。见下图。
 生成图的实际 Seed 值
生成图的实际 Seed 值
在种子(Seed)输入框边上还有两个按钮:『🎲』和『♻️』。
点击『🎲』会设置种子值为 -1,表示当前绘图任务会使用一个随机的种子值。
点击『♻️』则会设置种子值为上一次生成任务所使用的种子值,如果你想生成和上次任务近似的图,这个按钮会很有用。
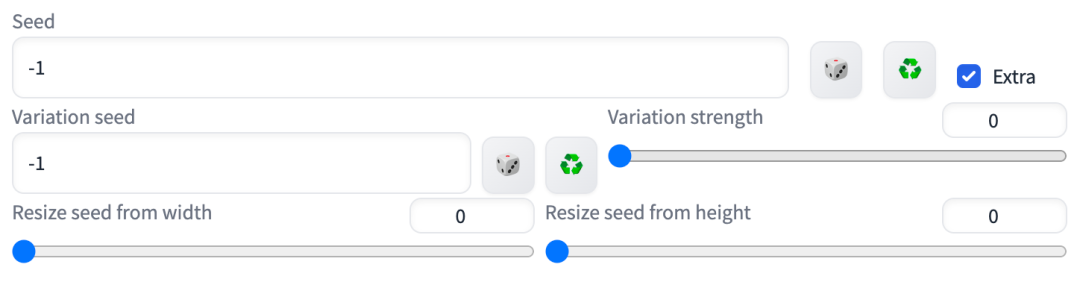
6.2、额外种子参数(Extra Seed Options)
在『♻️』按钮边上有一个 Extra 的可选框,选中它之后会展开一些额外选项的界面,我们就可以开始设置额外种子参数(Extra Seed Options)了。如图:
 额外种子参数
额外种子参数
这里包含几个参数:
- 基于种子渐变(Variation seed)
- 基于种子渐变强度(Variation strength)
- 基于种子更新宽度(Resize seed from width)
- 基于种子更新高度(Resize seed from height)
从字面上比较难理解它们是干嘛用的,我们就直接从使用场景的角度来介绍它们吧:
场景 1):我们固定提示词以及其他参数,通过改变 Seed 值的方式生成了两张图,现在我们觉得这两张图各有优点,想各取其长来生成一张更好的新图,这时候要怎么办呢?
这时候,基于种子渐变(Variation seed)和基于种子渐变强度(Variation strength)这两个参数就可以派上用场了。
比如,下面两张图就是同样的提示词和参数,但是 Seed 值不同。图 1 Seed 值:2249899550;图 2 Seed 值:951816086。
 图 1:2249899550
图 1:2249899550
 图 2:951816086
图 2:951816086
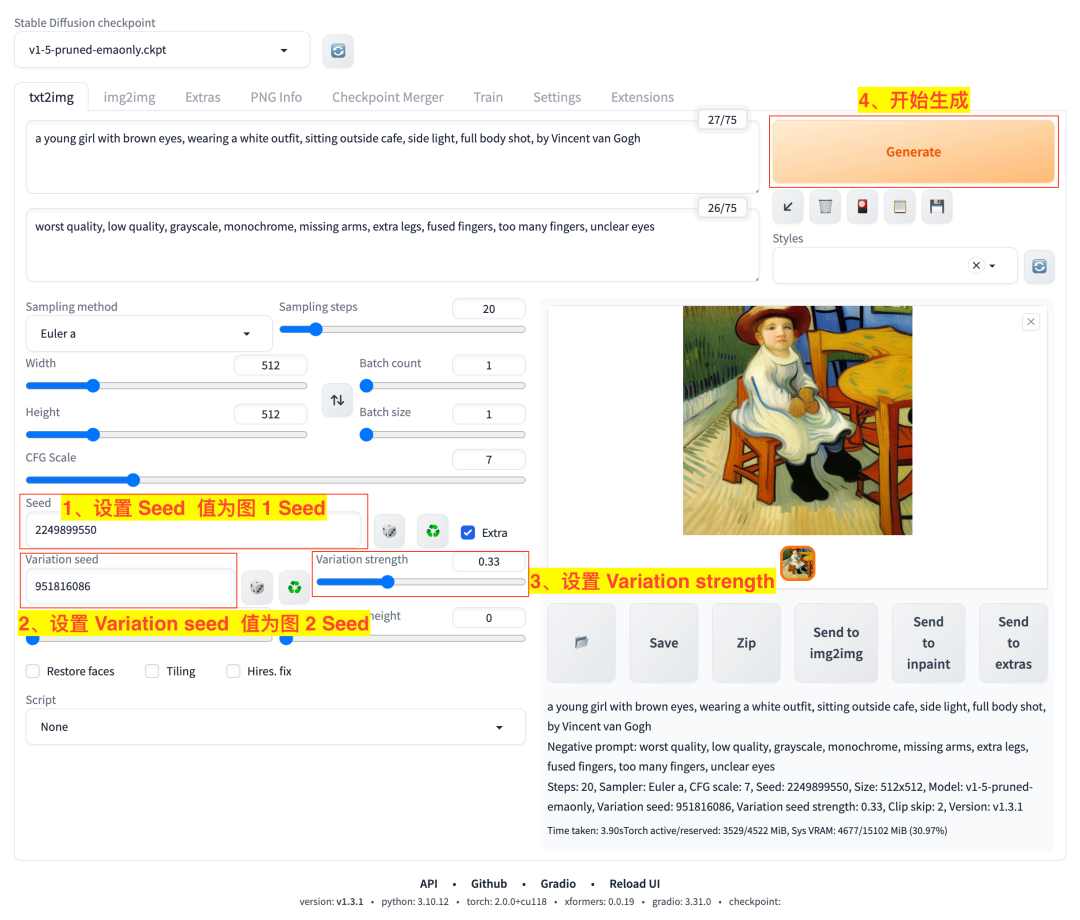
我们现在想把这两张图做一些特点融合,这时候我们可以如下图这样做:
 使用 Variation seed
使用 Variation seed
- 1)设置 Seed 值为图 1 的 Seed:2249899550;
- 2)设置 Variation seed 值为图 2 的 Seed:951816086;
- 3)调整 Variation strength 来决定融合倾向,该参数值的取值范围是 0-1,值越小则生成图像越接近图 1,值越大则生成图像越接近图 2。
- 4)点击生成按钮开始生成任务。
下面四张图分别是我们设置 Variation strength 为 0、0.33、0.66、1 得到的生成结果:
 Variation strength = 0
Variation strength = 0
 Variation strength = 0.33
Variation strength = 0.33
 Variation strength = 0.66
Variation strength = 0.66
 Variation strength = 1
Variation strength = 1
可以看到,当 Variation strength 为 0 时,生成图和图 1 一样,当 Variation strength 为 1 时,生成图和图 2 一样。Variation strength 值越接近 0,生成图的结构越接近图 1,反之则越接近图 2。
场景 2):用 Stable Diffusion 绘画时,分辨率也会影响图像的内容,那当我们生成了一张不错的图之后,想要调整它的分辨率,但是又希望尽量不去改变它的内容,要怎么办呢?
基于种子更新宽度(Resize seed from width)和基于种子更新高度(Resize seed from height)这对参数就提供了一种选择。
比如我们现在已经生成了一张分辨率为 512x512 的图,想把它改成 512x768 的分辨率,我们可以如下图这样做:
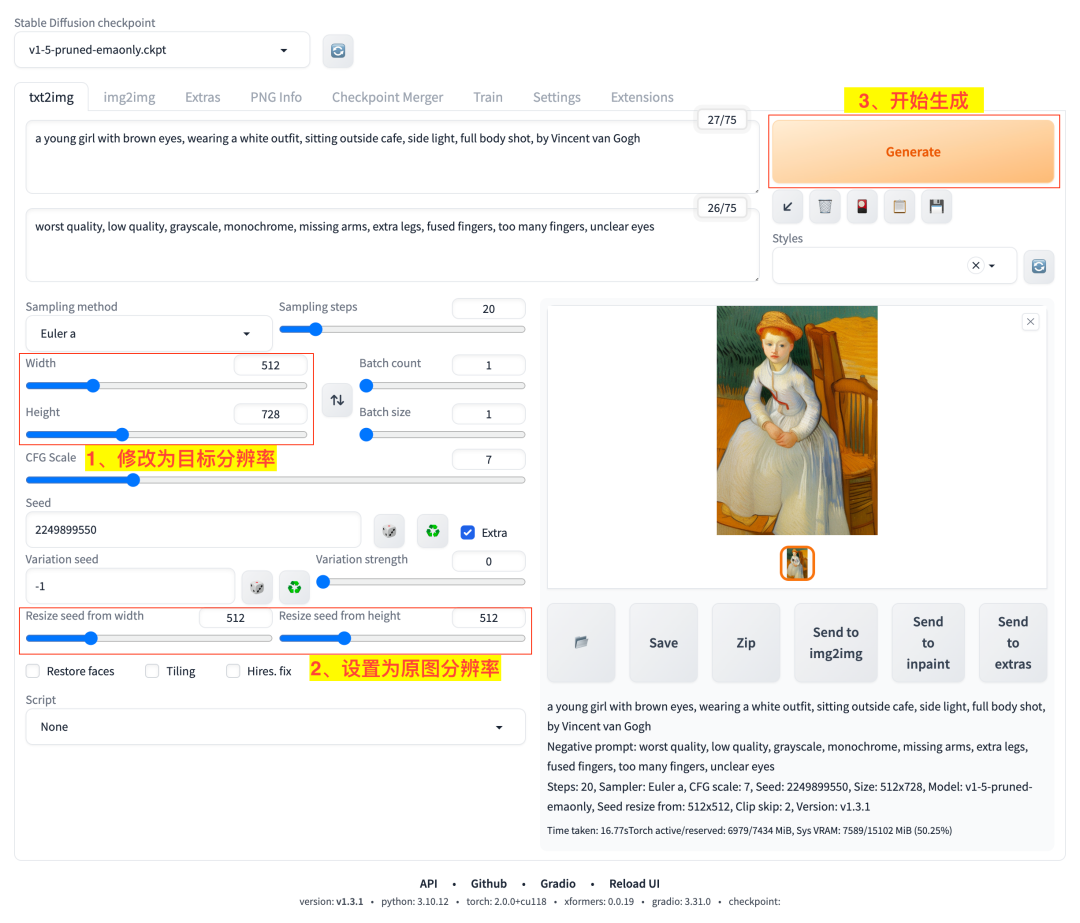 使用 Resize seed from width/height
使用 Resize seed from width/height
- 1)修改原来的分辨率 512x512 为目标分辨率 512x768;
- 2)设置基于种子更新宽度(Resize seed from width)和基于种子更新高度(Resize seed from height)为原图的宽高:512x512;
- 3)点击生成按钮开始生成任务。
下面是原图和修改分辨率后生成的新图:
 原图
原图
 新图
新图
当然,额外种子参数(Extra Seed Options)的功能听上去很美好,但是实际使用也可能会不及预期,还需要多多调整参数尝试。
7、重建人脸(Restore faces)
**重建人脸(Restore faces)**是针对怪异的人脸五官进行修复的一项功能。
 重建人脸功能
重建人脸功能
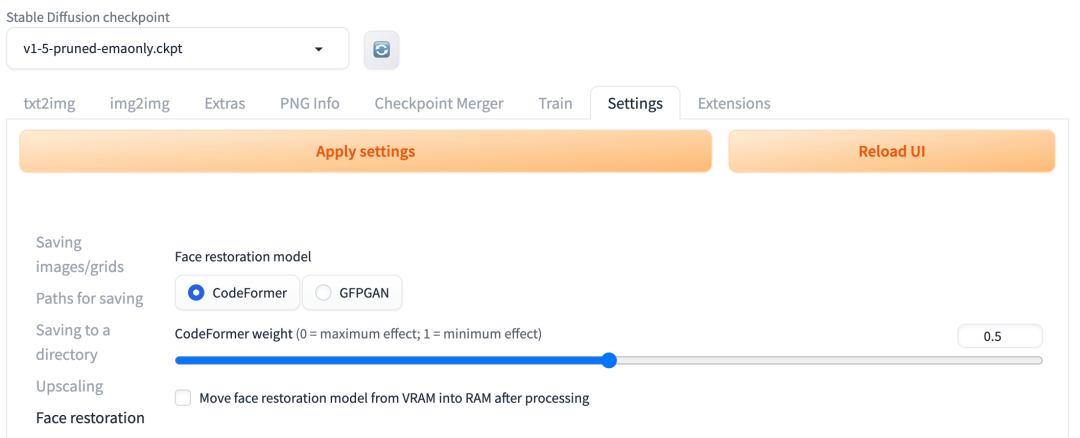
要使用这项功能比较简单,勾选 Restore faces 选择框即可。不过,重建人脸还有更细节的参数可以调整,需要到切换到 Settings 上栏的,再选择左边的 Face restoration 边栏,这样在右边的页面就可以看到相关参数设置了。如下图:
 重建人脸参数设置
重建人脸参数设置
这里可以选择 CodeFormer 和 GFPGAB 两种重建人脸的模型。
如果选择使用 CodeFormer 模型,还可以调整权重参数,取值范围是 0-1,不过需要注意的是 0 表示最大效果,1 表示最小效果。
下面是一个使用重建人脸功能的示例效果:
 重建人脸效果示例
重建人脸效果示例
8、无缝贴片(Tiling)
无缝贴片(Tiling)功能可以让 Stable Diffusion 生成可以无限无缝拼接的图像。
 无缝贴片功能
无缝贴片功能
比如,下面是生成的一张贴片:
 无缝贴片示例
无缝贴片示例
下面是将该贴片拼接的效果,可以看到拼接的结果没有破绽,确实无缝。
 无缝贴片拼接示例
无缝贴片拼接示例
这个功能可以用于制作壁纸、纺织品等。
9、高分辨率修复(Hires. fix)
高分辨率修复(Hires. fix)这个功能可以对生成图像提升分辨率。
 高分辨率修复功能
高分辨率修复功能
当我们勾选该功能时,会展开细节参数的设置 UI,如下图:
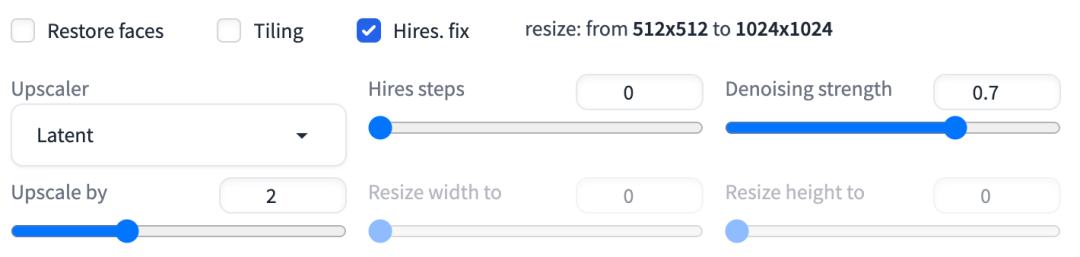 高分辨率修复功能
高分辨率修复功能
这里新出现了 2 组参数,包括:
-
1)上采样器设置:
-
- 上采样器(Upscaler)
- 上采样步数(Hires steps)
- 降噪强度(Denoising strength)
-
2)上采样分辨率设置:
-
- 上采样倍数(Upscale by)
- 更新宽度(Resize width)
- 更新高度(Resize height)
1)上采样器设置
上采样器(Upscaler)对应的是采样算法。目前可选的算法如下图:
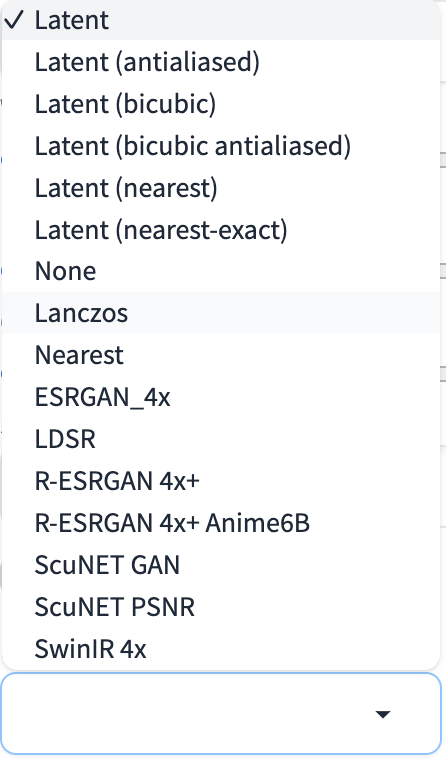 上采样器
上采样器
除了这些可选算法外,还可以打开 Setting - Upscaling 栏,选择 Real-ESRGAN 的模型来用于分辨率提升。如图:
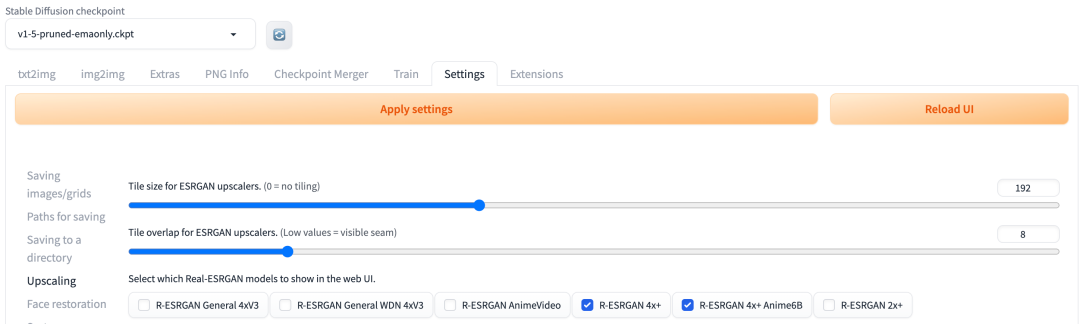 添加其他上采样器
添加其他上采样器
作为普通使用者,想要弄清楚这些算法的差别可能有些难度,那么该如何选择呢?下面是几条建议:
- 1)提升真实世界照片类图像效果,建议使用
R-ESRGAN 4x+模型; - 2)提升二次元漫画风格类图像效果,建议使用
R-ESRGAN 4x+ Anime6B模型。
上采样步数(Hires steps)表示二次生成的步数。跟 采样步数(Sampling steps) 概念类似。
降噪强度(Denoising strength)对 Latent 开头的采样器有效,表示生成高分辨率时的降噪强度。这个数值建议设置在 0.5-0.8 的区间,如果数值过小,生成结果可能会比较模糊,如果数值过大,则可能相比原图有较大的差异。
下面是使用不同降噪强度的效果对比:
 不同降噪强度的效果对比
不同降噪强度的效果对比
2)上采样分辨率设置
上采样分辨率设置中,上采样倍数(Upscale by)和更新宽度/高度(Resize width/height)的设置是互斥的。选择上采样倍数(Upscale by)即按设定的比例放大;选择设置更新宽度/高度(Resize width/height)则按照设定的宽高放大。
10、生成任务启动(Generate)
生成任务启动(Generate)是启动 Stable Diffusion 绘画任务的地方,这样直接点击 Generate 按钮即可。
 生成任务启动
生成任务启动
11、生成图预览和功能区
生成图预览和功能区包含以下几块功能:
- 预览生成图像以及图像对应的提示词和生成参数信息;
- 压缩、下载生成图像;
- 将图像发送到
img2img、inpaint、extras等功能页面做进一步处理,这些功能页面我们后面会继续介绍。
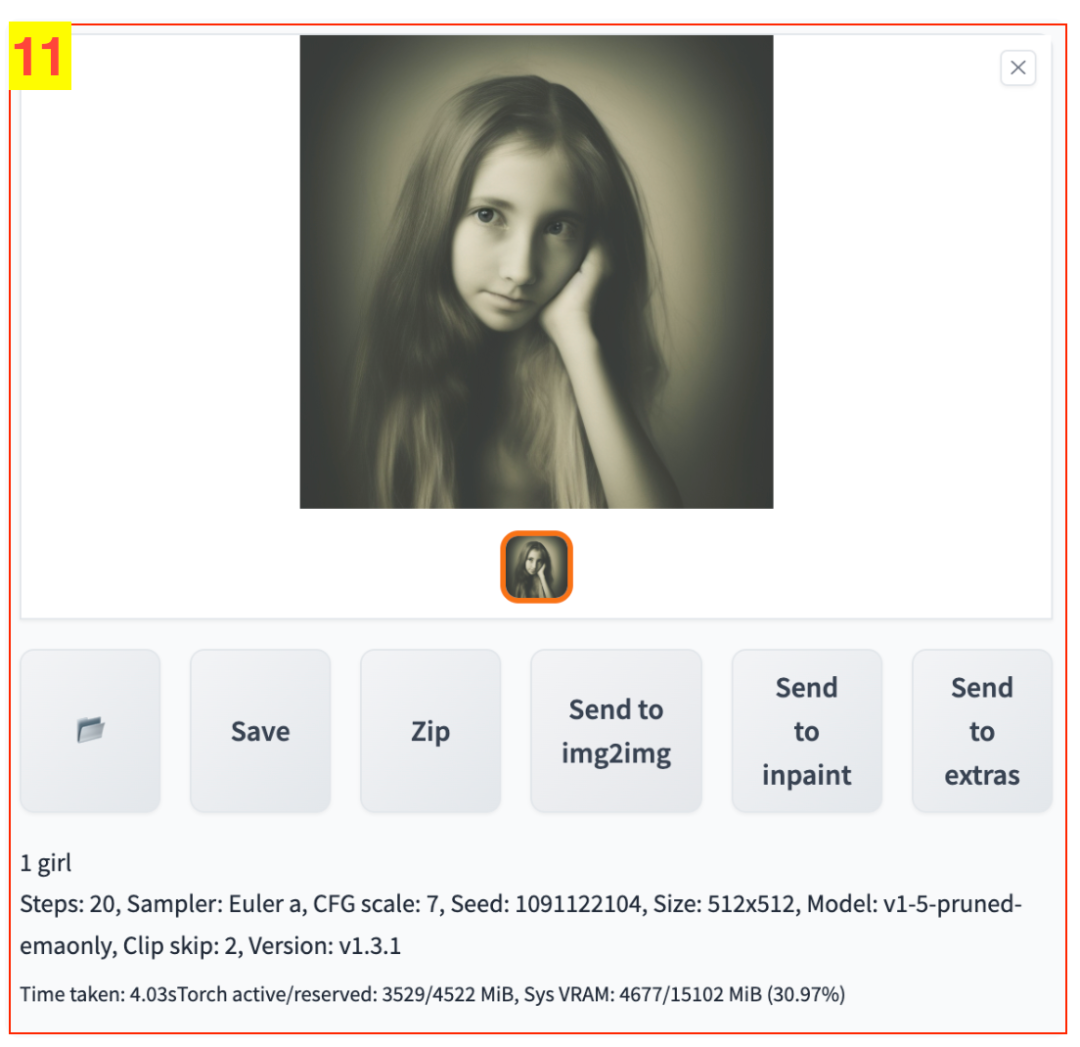 生成图预览和功能区
生成图预览和功能区
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

这份完整版的AIGC全套学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 2185
2185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









