






Stable Diffusion作为AI绘画领域的“倚天剑”,凭借其开源特性和强大的跨平台能力,正成为创作者们的必备工具。本文详解如何在iOS、macOS、Windows PC及云服务器上快速搭建和使用Stable Diffusion。从Draw Things App的本地运行,到WebUI的模型部署,再到LoRA模型的高效微调,全方位覆盖不同设备的使用场景和技巧,助你轻松玩转Stable Diffusion,释放创作潜力
话不多说,先列本文提纲和要点:
-
1、Stable Diffusion 的优势和出图效果
-
2、在各种设备上把 Stable Diffusion 玩起来
-
- 苹果 iOS 手机和平板
- 苹果 macOS 电脑
- Windows PC 电脑
- 云服务器
-
3、不同方案的优势和限制
-
4、基于 Stable Diffusion 如何商业变现
1、Stable Diffusion 的优势和出图效果
我们在前面的文章中介绍过 Midjourney:一款架设在 Discord 社区的优秀 AI 绘画工具,我把它称作 AI 绘画界的『屠龙刀』。而今天我们要介绍的 Stable Diffusion,我则愿意称它为 AI 绘画界的『倚天剑』。
Midjourney 屠龙宝刀厉害之处在于它通过 Discord 来构建自己 AI 绘画社区的巧思,这个策略一方面使得用户能够在社区互相学习提示词的使用技巧、快速生成高质量美图,从而激发用户的兴趣、刺激了产品的传播;另一方面通过庞大的用户积累了独有的数据集,从而可以根据用户需求针对性地训练模型并快速进行产品迭代,形成了正反馈循环。
那 Stable Diffusion 又厉害在什么地方呢?
Stable Diffusion 是一款 2022 年发布的支持由文本生成图像的 AI 模型。它主要用于根据文本的描述产生详细图像,也可以应用于其他任务,如:内补绘制(Inpainting)、外补绘制(Outpainting)、在英文提示词(Prompt)指导下支持图生图。这些是一款 AI 绘画工具的基础能力,这里不多讲。
我认为 Stable Diffusion 能成为与 Midjourney 并驾齐驱的倚天神剑,主要原因则在于它可以在大多数配备有适度 GPU 的电脑硬件上运行,并且项目代码和模型权重是开源的。这样一来,开源社区的开发者就可以在它的基础上进行二次开发、做插件、做工具,这就有了如今结合 Stable Diffusion 玩的飞起的 Stalbe Diffusion WebUI、ChillOutMix、LoRA、ControlNet 等开源项目(先不用管这些项目是干什么用的,教程走到对应的情节,自然会给大家介绍)。这就相当于给 Stable Diffusion 的发展增加了大量的盟友,让这把倚天剑变成了组合套剑,还有了万剑归宗的招式。
话不多说,直接看剑招:
1)港口




2)底下洞穴的水晶沉积物




1、2 图片来自:PromptHero[1]
3)川濑巴水的意大利之旅


<<< 左右滑动见更多 >>>
4)印象派的北京团建


看完你是不是觉得:『还行、还凑合,没有之前的 Midjourney 出图那么厉害嘛。』
那接下来,当 Stable Diffusion 组合上 LoRA 插件后,事情变得不一样了:
1)甜美风小姐姐



2)韩风小姐姐



3)二次元小姐姐




图片来自:小红书博主:扑扑画画不用笔[5]
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

**温馨提示:篇幅有限,已打包文件夹,获取方式在

我第一次见到这种 AI 绘画的效果我是被震撼到了:『难道福利姬不存在了?Coser 不存在了?摄影师不存在了?插画师不存在了?』
为什么 AI 绘画能做到这种地步呢?你是不是也对它的原理有一些好奇了,刚好到这里我们歇口气,我来尽量简要地介绍一下 Stable Diffusion 和 LoRA 的基础知识:
Diffusion 扩散算法技术要点:
1)目前主要流行的 AI 绘画工具 Midjourney、Stable Diffusion、DALL-E 2、Imagen 等本质上都是是基于
Diffusion 算法模型。2)Diffusion 算法训练需要先找到一堆高质量的图片,训练时对每张图片按照高斯噪声公式一步一步来加噪点,直到整张图片变成一张全是噪点的图像(如下图所示),这个训练的过程会记录所有步骤。接下来,就用神经网络的方式来反向学习如何从一个全是噪点的图像变成一张高清图片。
Diffusion 算法训练过程
3)一旦完成训练得到了 Diffusion 模型,机器就可以通过
噪点来对图像进行预测。这样一来,整个绘画的过程就是 AI 用一组随机噪点(随机数)来预测基于它们能画出一个什么样的图片。AI 就是从一堆凌乱的随机数中画出图片的,这个过程是一个大力出奇迹的过程,但厉害的是最终能产出清晰度和细节度非常高的图片。LoRA 技术要点:
1)大模型由于参数量巨大(百亿、千亿级别),如果要干特定领域的活、需要做微调时,成本非常高。
2)LoRA 全称 Low-Rank Adaptation of Large Language Models,是微软研究院引入的一项用于处理大模型微调问题的技术。LoRA 通过冻结预训练好的模型权重参数,然后在每个其中的一些模块注入可训练的层,则不需要对模型的权重参数重新计算梯度,大大减少了需要训练的计算量。研究发现,LoRA 的微调质量与全模型微调相当,而成本又很低,所以可以称为神器。
3)LoRA 本来是给大语言模型准备的,但把它用在 Stable Diffusion 的交叉注意层(Cross-Attention Layers)也能影响用文字生成图片的效果。这样一来,使得使用自定义数据集来微调 Stable Diffusion 模型变得非常容易。并且,使用 LoRA 可以支持发布单个 3.29MB 文件来让别人使用你的微调模型。这成为了各种特色 LoRA 疯狂流行的基础。
参考:
- Github LoRA[6]
- Using LoRA for Efficient Stable Diffusion Fine-Tuning[7]
- 使用 LoRA 进行 Stable Diffusion 的高效参数微调[8]
2、铸剑:在各种设备上把 Stable Diffusion 玩起来
你希望在什么设备上玩 Stable Diffusion?
大家可以投一下票,我们会根据大家的情况决定后续教程的侧重。
2.1、苹果 iOS 手机和平板
在手机上可以通过 Draw Things[9] 这款 App 来使用 Stable Diffusion,不用连网完全本地运行出图,不过目前对手机型号和系统版本有如下要求:
- 手机设备要求 iPhone XS、XS Max、Xr、11、11 Pro、11 Pro Max、SE 2nd Gen、12、12 Mini、12 Pro、12 Pro Max、SE 3rd Gen、13、13 Mini、13 Pro、13 Pro Max、14、14 Plus、14 Pro、14 Pro Max,要求系统在 iOS 15.4 及以上。
- 平板设备要求 iPad Air、Mini、Pro,要求系统在 iPadOS 15.4 及以上。
1)Draw Things 的基础功能:
Draw Things 有这些 AI 绘画的基础功能:
- 文字生成图片
- 文字+图片生成图片
- 内补绘制(Inpainting)
- 外补绘制(Outpainting)
下面是一些功能示例图:
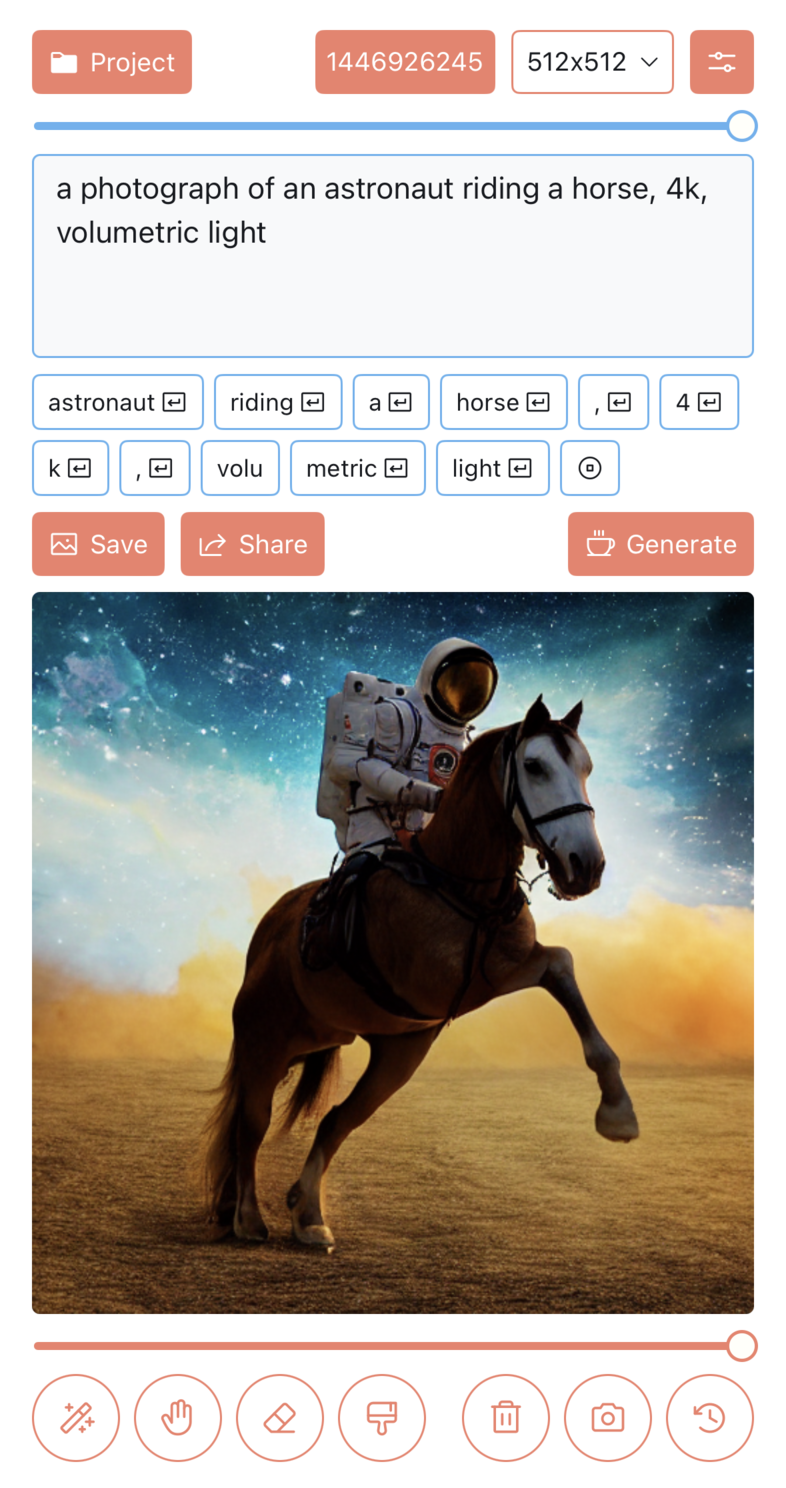
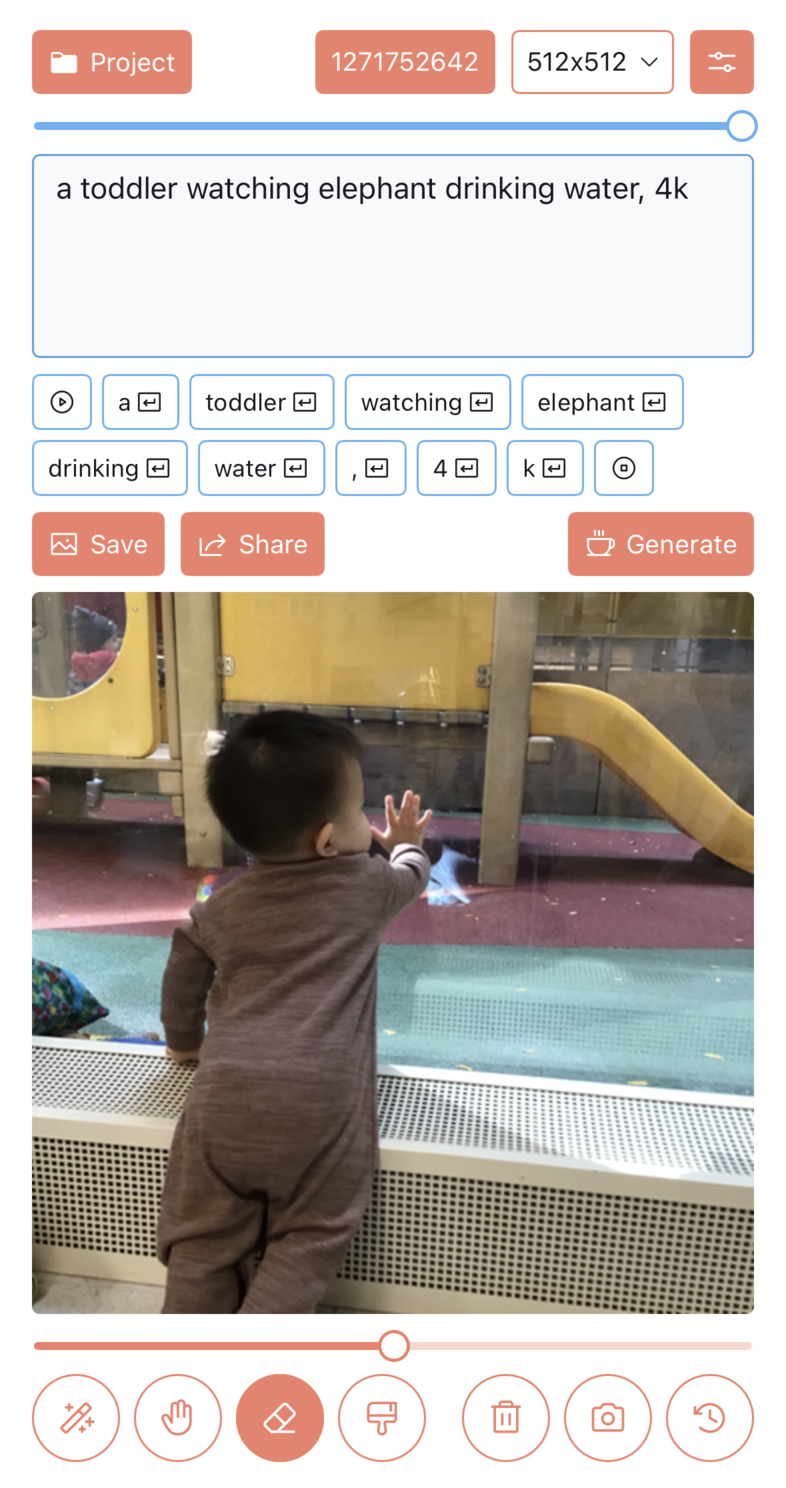
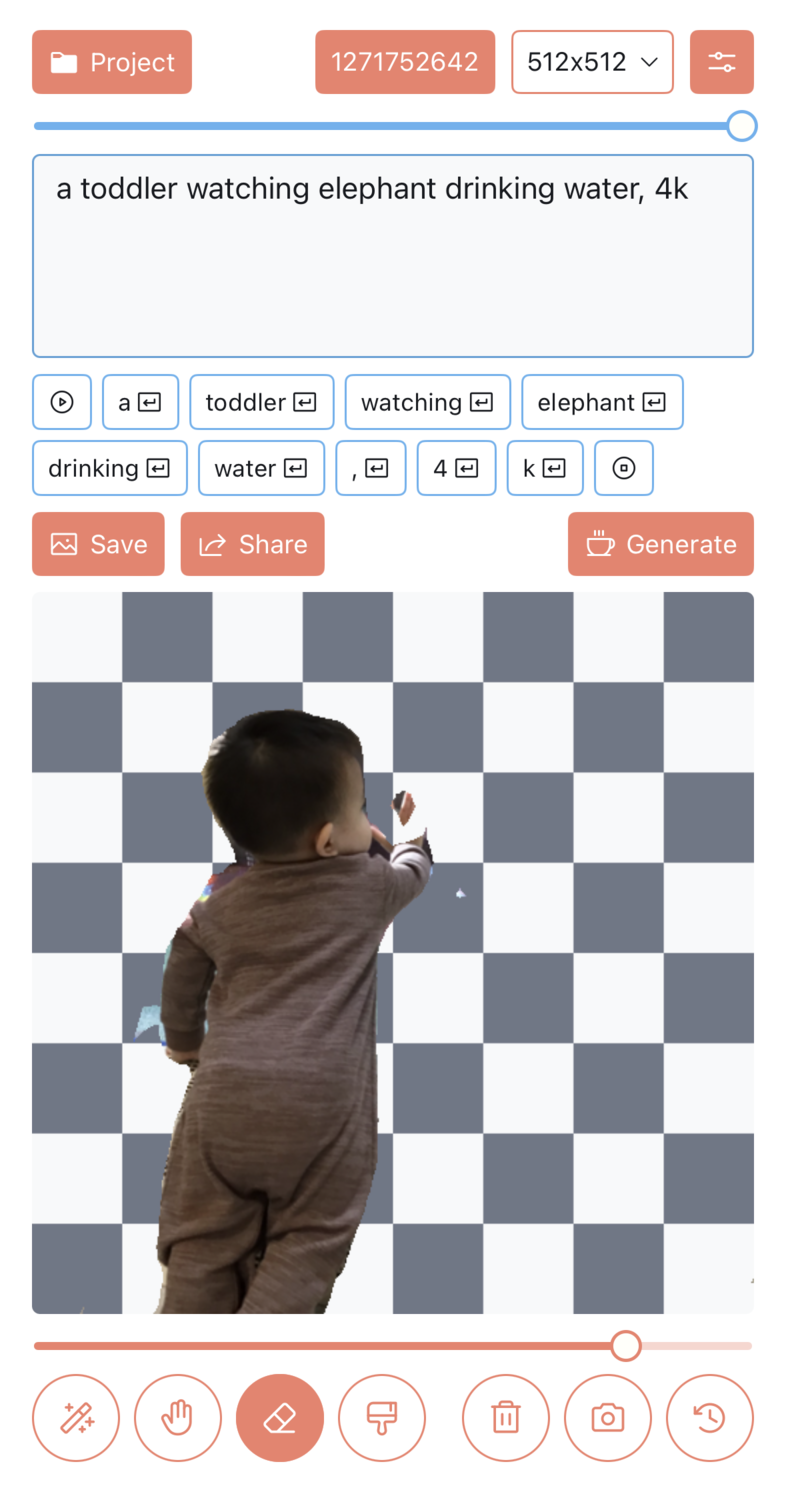
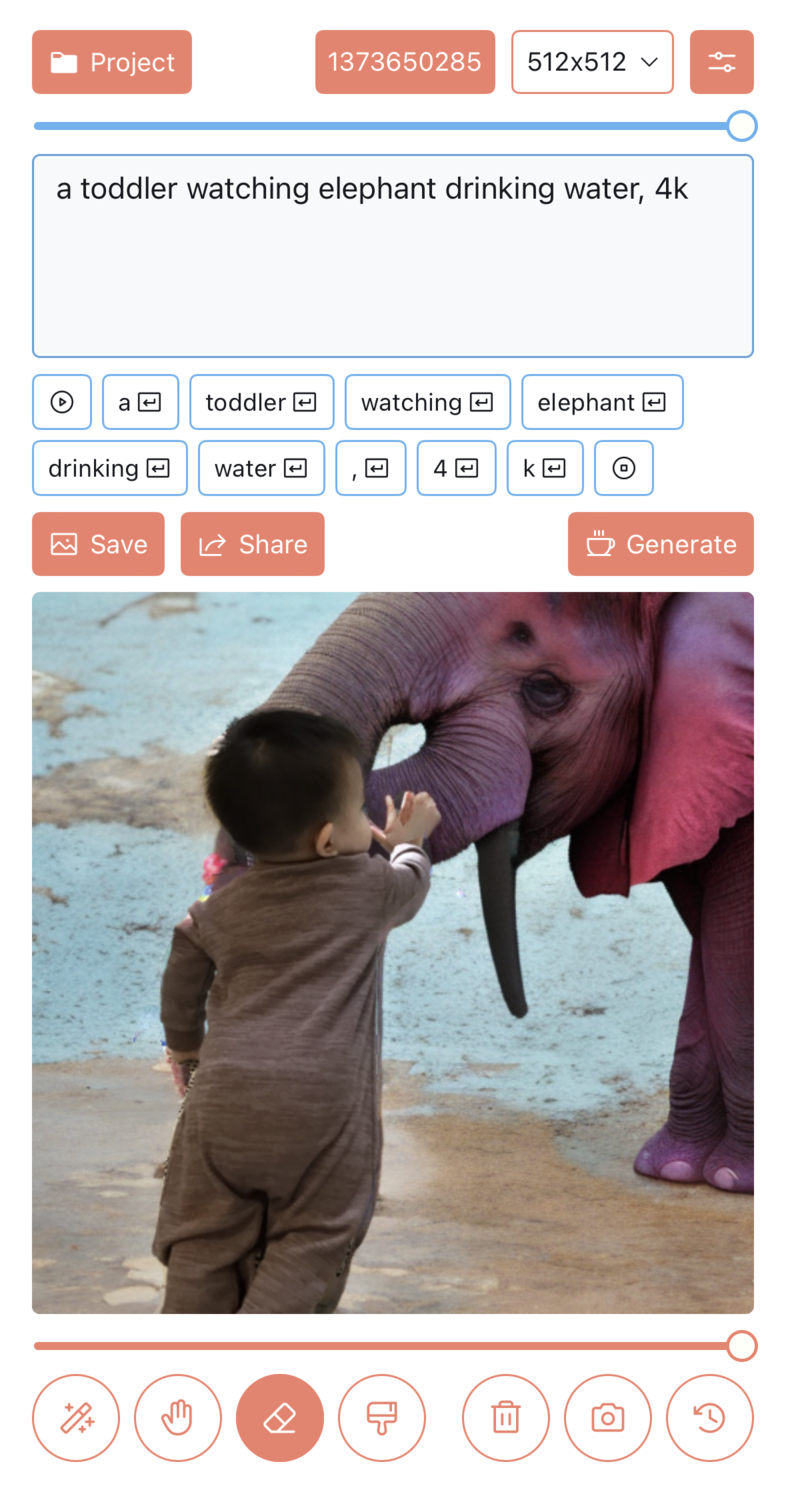
2)支持设置 Stable Diffusion 的各项参数
同时也支持设置 AI 绘画的各种参数,包括:出图分辨率、绘图步数、提示词引导权重、图生图引导权重、采样器等。如下图所示:
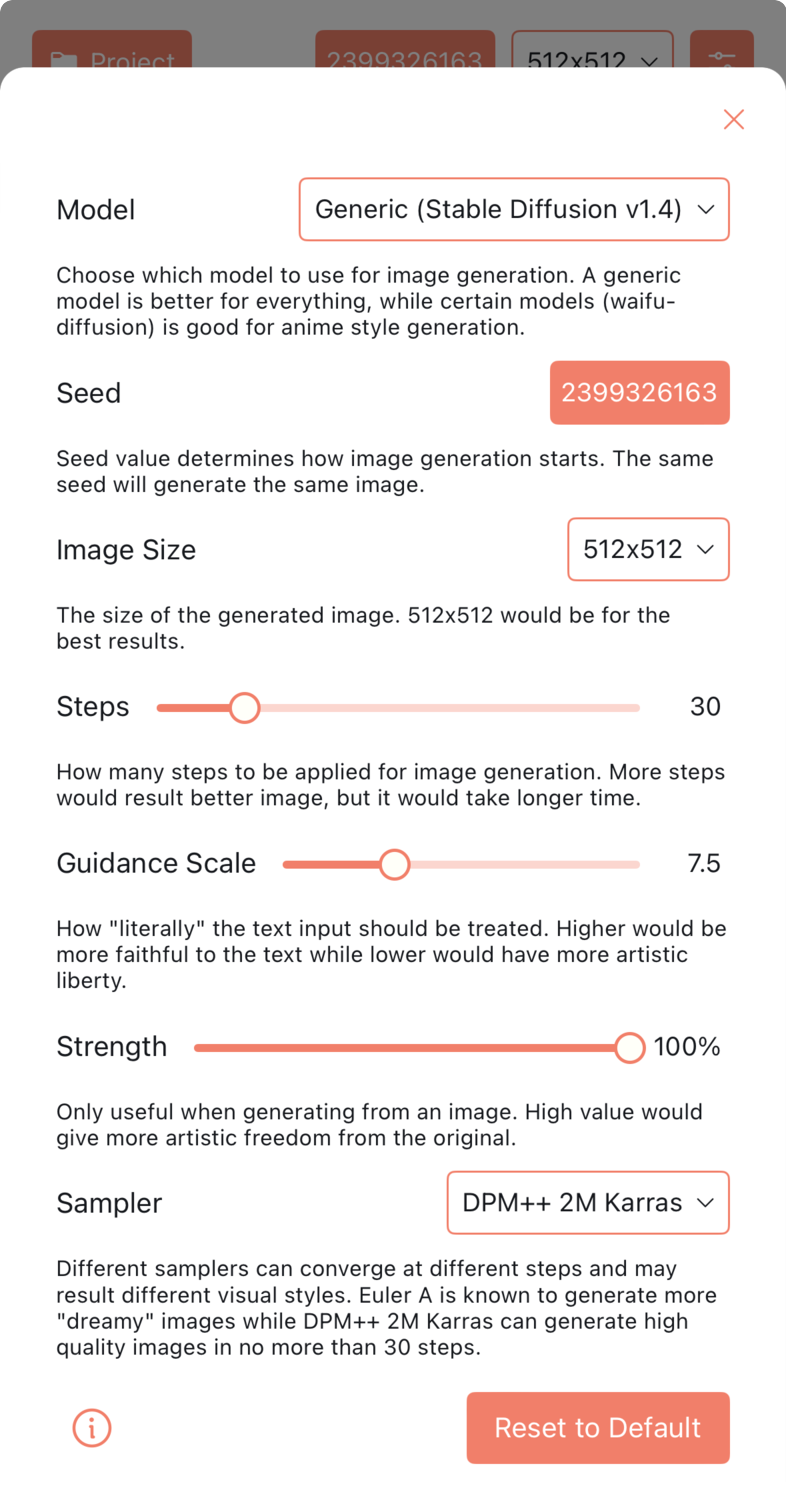 设置 AI 绘画参数
设置 AI 绘画参数
3)支持切换不同的 Stable Diffusion 的模型
比如下面就是用 Waifu Diffusion v1.3 for Anime 出图的效果:
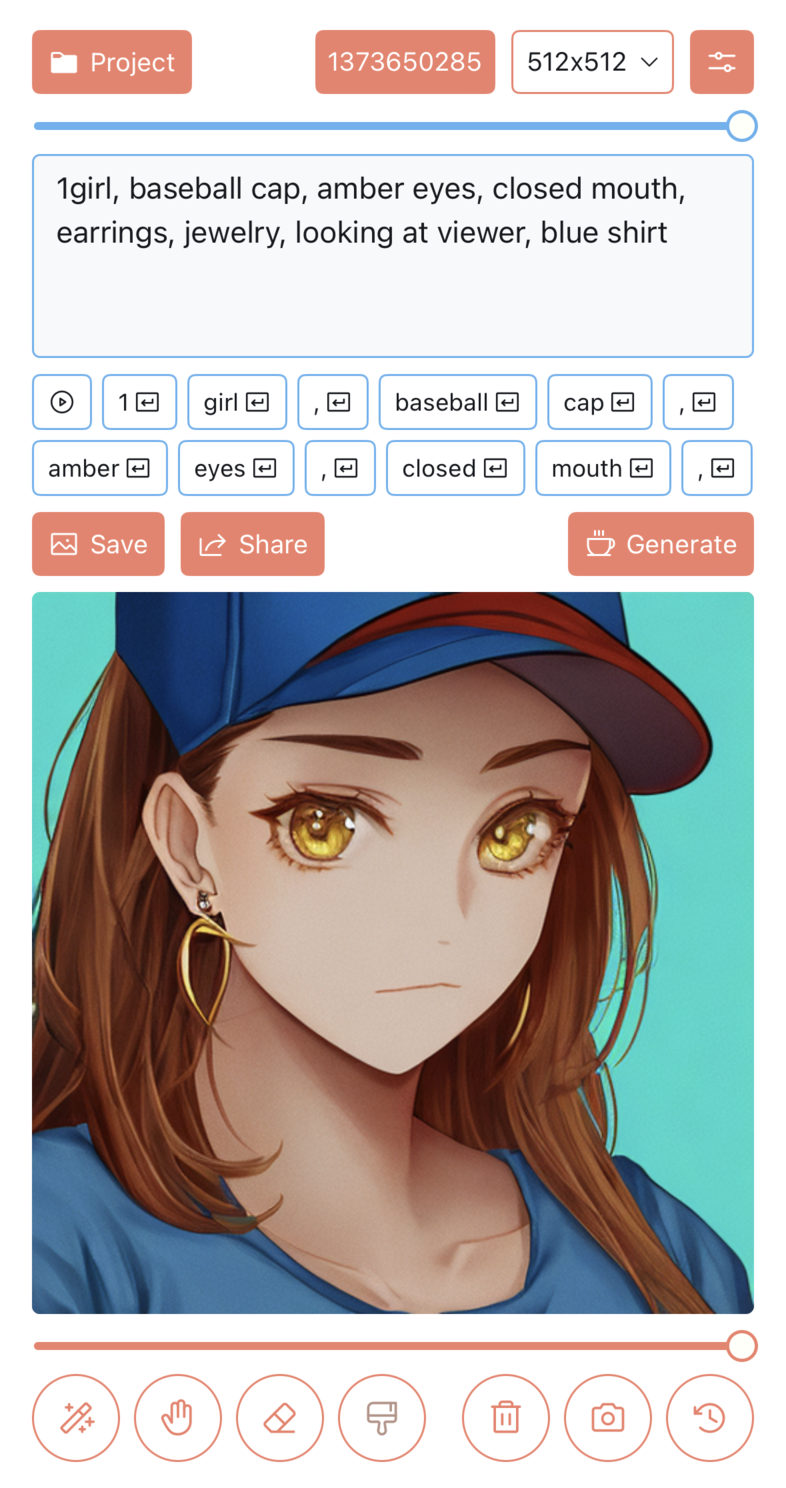 使用不同的模型
使用不同的模型
Draw Things 有内置一些模型选项可以点击下载使用,如果内置的不够用,还可以点击 Customize 来下载其他支持 Draw Things 的模型来用,如下图所示:


要下载其他非内置的模型,首先你得找到它们,这里就不得不提一下著名的 C 站(https://civitai.com/)[10]了。这里是一个各路大神无私共享各自模型的地方,著名的 ChilloutMix、亚洲三姐妹 LoRA(koreanDollLikeness、japaneseDollLikeness、taiwanDollLikeness)等模型都可以在这里找到。这里有一些模型是支持 Draw Things 的,比如:ChilloutMix[11],但遗憾的是,到本文写作时 Draw Things 还不支持 LoRA。
在下载模型之前,你需要检查一下你找到的模型是否支持 Draw Things,可以按下图处理:


<<< 左右滑动见更多 >>>
如图 1 点击模型下载按钮边上的绿底三角按钮,可以在弹出的信息框中看到是否支持 Draw Things(如图 2)。如果是在 Safari 浏览器打开的 C 站,如图 2 中点击蓝底箭头按钮可以直接跳转到 Draw Things 进行下载。当然,你也可以在图 1 中,复制蓝底模型下载按钮的链接地址获得模型的下载地址,把它填到 Draw Things 的自定义模型下载地址中来下载。
4)支持 LoRA
在最新版本的 Draw Things 中已经支持 LoRA 了,并且可以支持多个 LoRA 模型同时使用。
你可以直接下载内置的 LoRA 模型,也可以通过 URL 下载自己需要的 LoRA 模型。
如下图所示:



5)支持 ControlNet
在最新版本的 Draw Things 中已经支持 ControlNet 了,如下图所示:
 Draw Things 支持 ControlNet
Draw Things 支持 ControlNet
那 ControlNet 是干什么的呢?这里我们简单介绍一下。
在我们通过提示词来引导 AI 模型进行绘画时,在一些画面结构、主体姿态、人物手型等控制上还是不够精准,ControlNet 就可以比较好的解决这个问题。ControlNet 可控制 Stable Diffusion 学习特定任务的输入条件,比如输入的线稿图、深度图、骨骼图等,生成与输入文本对应的高质量图片。
下面是使用一张已有图生成的线稿图,再加上提示词生成新图的效果:
ControlNet 效果
2.2、苹果 macOS 电脑
要想在苹果 macOS 系统的电脑上把 Stable Diffusion 玩起来,有两种方案:
方案 1:使用 Draw Things App
在苹果电脑要玩起 Stable Diffusion,一种方式跟 iPhone/iPad 一样,直接使用 Draw Things App,它也是支持 macOS 的。但是也同样的对设备和系统版本有要求:
- 设备要求 M1/M2 芯片的 Mac Mini、Mac Studio、MacBook Air、MacBook Pro,且 macOS 系统版本在 12.4 及以上。
Draw Things App 在 macOS 上的用法和 iOS 上一样,参考上文即可,这里就不过多介绍了。
至于出图速度,我自己在 M1 的 MacBook 上 steps 20 的出图速度在 30s 左右,供大家参考。
方案 2:安装 Stable Diffusion WebUI
在苹果电脑本地玩 Stable Diffusion 的另外一种方式是安装 Stable Diffusion WebUI(https://github.com/AUTOMATIC1111/stable-diffusion-webui)[12]。
又来了新名词 Stable Diffusion WebUI,我们继续简单介绍:
Stable Diffusion WebUI 是一个开源的基于 Gradio 库开发的用于使用 Stable Diffusion 的 Web 页面项目。
Gradio 则是专门用于轻松实现 AI 算法可视化部署的开源库。
简单来讲就是 Stable Diffusion WebUI 提供了一套 Web 页面让我们可以通过在网页上使用 Stable Diffusion 的各种能力。它长这样:
Stable Diffusion WebUI
由于 Stable Diffusion WebUI 使用的 Gradio 是基于 python3 的项目,所以,搭建这套环境最主要的问题是解决 python3 的环境问题。
下面我们来介绍如何搭建这套环境:
1)环境准备:安装 Homebrew
Homebrew 是一个用于在 macOS 上便捷安装和管理各种软件包的工具,我们后面很多包都会依赖它来安装,所以先把它装好。
官网的安装命令是:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
如果因为访问国外某些资源网络不通,导致安装失败,你可以使用国内的镜像来安装,命令如下:
/bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)"
安装完成后,可以用下面的命令查看一下版本,检测安装是否成功:
brew --version
2)环境准备:安装 python 3.10
macOS 默认带的 python 版本一般是 2.x,但是这里我们要用 3.10,所以要安装一下。使用下列命令用 Homebrew 来帮我们安装:
brew install cmake protobuf rust python@3.10 git wget
等待安装完成即可。
3)项目安装:下载 stable-diffusion-webui 项目
你可以使用下列命令从 github 上克隆这个项目:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
但是由于项目比较大(4G 左右),速度比较慢,你也可以使用如下链接直接从国内云盘下载其他开发者已经打包好的资源并解压好:https://pan.quark.cn/s/8c5e66287f37。
这里面是 stable-diffusion-webui 的项目,不包含 Stable Diffusion 和 LoRA 的模型。
4)项目安装:下载和配置 Stable Diffusion 和 LoRA 模型
比较推荐的基础模型有:
-
Stable Diffusion v1.5[13]:这个是官方原始模型,其中包括两个版本:绘画版(4.27GB),只用于绘画;训练版(7.7GB),可以以此模型为基础训练自己的模型。
-
- 下载地址(下载后缀名为 .safetensors 的文件):
https://huggingface.co/runwayml/stable-diffusion-v1-5/tree/main
- 下载地址(下载后缀名为 .safetensors 的文件):
-
ChilloutMix[14]:这个模型是在 2023.02 月出现在 C 站的一个真人写实风格的开源模型,可以画出以假乱真的摄影级真人。上文展示的
甜美风小姐姐、韩风小姐姐都是用它作为基础模型的。 -
- 下载地址:
https://civitai.com/api/download/models/11745
- 下载地址:
比较推荐的 LoRA 模型是亚洲三姐妹:
- koreanDollLikeness
- japaneseDollLikeness
- taiwanDollLikeness
但是,目前它们在 C 站上都已经下架了,这里也不方便贴出备份地址,你可以在本公众号回复消息 模型 来获取备份的模型地址:
除了上面的基础模型和 LoRA 外,还要下载一个影响出图的色调文件:
-
sd-vae-ft-mse-original[15]:
-
- 下载地址(下载后缀名为 .safetensors 的文件):
https://huggingface.co/stabilityai/sd-vae-ft-mse-original/tree/main
- 下载地址(下载后缀名为 .safetensors 的文件):
下载完这些模型后,就可以把部署起来了:
- 基础模型:把 safetensors 拷贝到
stable-diffusion-webui/models/Stable-diffusion路径。 - LoRA 模型:把 safetensors 拷贝到
stable-diffusion-webui/models/Lora路径。 - VAE 文件:把 safetensors 拷贝到
stable-diffusion-webui/models/VAE路径。
如下图所示:
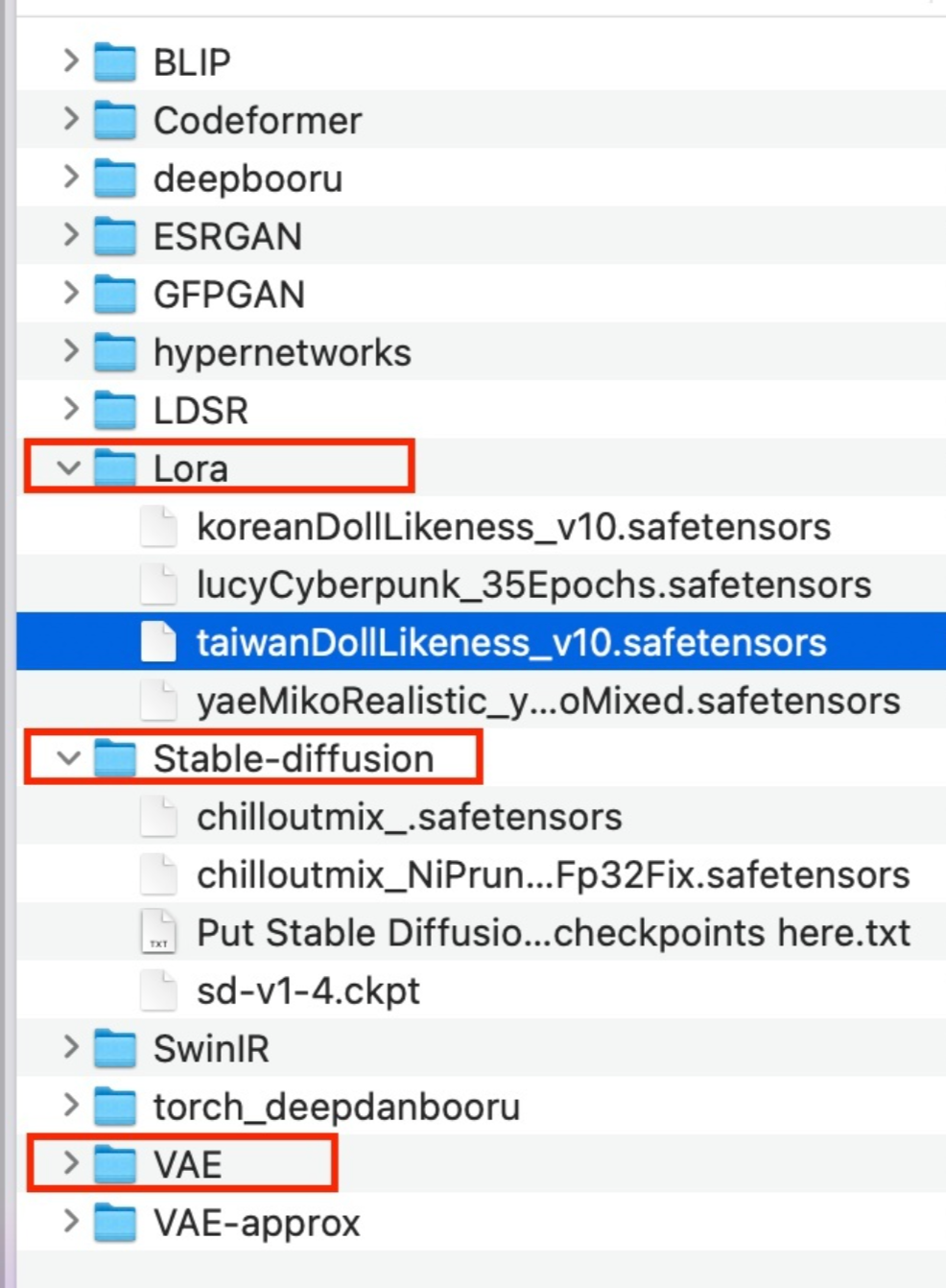 Stable Diffusion WebUI 的模型部署路径
Stable Diffusion WebUI 的模型部署路径
5)项目运行:运行 stable-diffusion-webui 项目及解决依赖库的安装
做完上面这些步骤,准备工作就告一段落了,接下来就是运行项目和解决依赖库安装的问题。
进入 stable-diffusion-webui 文件夹使用下面命令来启动项目:
./webui.sh
这个过程会安装项目需要的依赖库,通常会遇到一些问题,这里有几个建议:
- 这步最好是在网络环境比较通畅的情况下进行,要不然会遇到依赖库无法下载而导致安装失败。
- 遇到一些 python3 相关的依赖库的报错,可以使用 homebrew 单独安装,或者使用 pip3 来按照。
- 其他问题可以在下面的参考文章里去找一下解决方案。
参考:
- Mac 本地部署 Stable Diffusion[16]
- SD WebUI Installation on Apple Silicon[17]
当最后你看到类似下面的界面是,基本上就大功告成了:
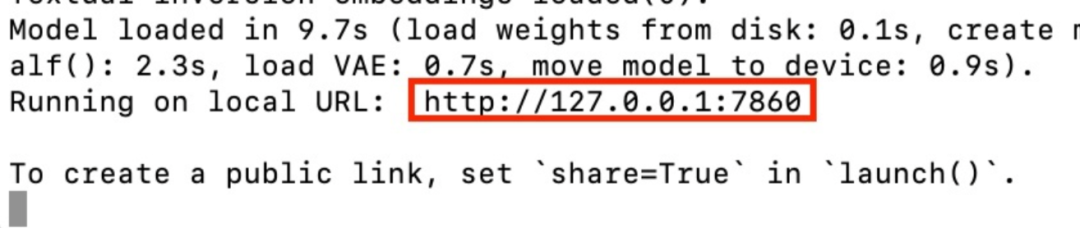 Stable Diffusion WebUI 运行
Stable Diffusion WebUI 运行
在浏览器中输入 http://127.0.0.1:7860 回车即可开始玩耍了。
2.3、Windows PC 电脑
要在 Windows PC 电脑上把 Stable Diffusion 搭建起来,首先需要显卡能够满足需要,Stable Diffusion WebUI 的最低显存要求是 4GB。
如果显卡给力,接下来的工作就跟在 macOS 电脑上搭建的道理类似,就是把 Stable Diffusion WebUI(https://github.com/AUTOMATIC1111/stable-diffusion-webui)[18]项目及依赖的 python 环境及各种依赖库给下载下来,将项目运行起来。但是也有更方便的办法,我们下面就来介绍一下。
1)下载 Stable Diffusion 及其依赖环境的整合包。
B 站 UP 主 秋葉aaaki[19]、独立研究员-星空[20] 都有制作 Stable Diffusion 及其依赖环境的整合包,只要整体下载下来就可以直接使用。
下面是几个整合包的下载地址,大家可以选一个自己去取:
这份完整版的SD整合包已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

2)下载 WebUI 的启动器。
接下来可以去 秋葉aaaki 的视频教程描述中 去找到 WebUI 启动器的下载地址:
这份完整版的SD整合包已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
把它下载下来,并将下载完成的启动器解压缩复制到刚才的整合包文件夹中,双击启动器 A启动器.exe 就可以启动了。
这个启动器的功能主要是通过可视化的界面帮助我们来下载和管理 Stable Diffusion WebUI 的各种插件和模型。
3)通过 WebUI 启动器更新模型和扩展。
打开启动器后,我们要做两个工作:
- 1、点开
版本管理栏,点击一键升级按钮,升级模型。 - 2、点开
扩展管理栏,点击一键更新按钮,更新扩展。
4)给 WebUI 安装 Kohya-ss Additional Networks 扩展以支持 LoRA。
- 1、回到 WebUI 启动器,点开
一键启动栏,点击一键启动按钮,打开 WebUI 的页面。 - 2、依次点击:页面上部的
扩展栏 →可用栏 →加载自按钮。 - 3、在列表中找到
Kohya-ss Additional Networks插件,点击它右侧的Install按钮。 - 4、等待该插件安装完成后,点击出现的
重启并应用用户界面。
重启后,如果顶层 Tab 上多了 Additional Networks 就说嘛插件已经安装成功了。
接下来就可以部署自己喜欢的基础模型和 LoRA 了。
5)下载和部署自己喜欢的基础模型和 LoRA。
跟上面一样,我们比较推荐的主模型:
-
ChilloutMix[21]:这个模型是在 2023.02 月出现在 C 站的一个真人写实风格的开源模型,可以画出以假乱真的摄影级真人。上文展示的
甜美风小姐姐、韩风小姐姐都是用它作为基础模型的。 -
- 下载地址:
https://civitai.com/api/download/models/11745
- 下载地址:
比较推荐的 LoRA 模型是亚洲三姐妹:
- koreanDollLikeness
- japaneseDollLikeness
- taiwanDollLikeness
但是,目前它们在 C 站上都已经下架了,这里也不方便贴出备份地址,你可以在本公众号回复消息 模型 来获取备份的模型地址:
这里需要注意:
- 1、对于 ChilloutMix 这样的主模型,我们下载下来后,需要把它们拷贝到 WebUI 整合包文件夹下的
models\Stable-diffusion目录下。 - 2、对于 koreanDollLikeness、japaneseDollLikeness、taiwanDollLikeness 这样的 LoRA 模型,我们下载下来后,需要把它们拷贝到 WebUI 整合包文件夹下的
extensions\sd-webui-additional-networks\models\lora目录下。
6)通过 WebUI 启动器启动 WebUI。
现在我们关闭 WebUI,回到 WebUI 启动器,点击一键启动按钮,重启 WebUI。
当 WebUI 页面启动完成后,我们自己部署的主模型和 LoRA 应该也可以用了,接下来就可以进入 AI 绘画的世界开始玩耍了。
参考:
- 打造你的赛博 Coser-StableDiffusion 模型及 LoRA 插件保姆级教程[22]
- Stable Diffusion 最终版,无需额外下载安装[23]
- 启动器正式发布!一键启动/修复/更新/模型下载管理全支持![24]
2.4、云服务器
除了在自己的 iOS、macOS、Windows 设备上搭建 Stable Diffusion 的环境之外,我们还可以在云服务器上部署 Stable Diffusion。
这里依然要感谢有无私的开发贡献者,把整个流程变得非常简单。这里使用的就是巴哈姆特上的一篇文章介绍的开源部署脚本在 Colab 上部署 Stable Diffusion WebUI。
1)访问 Colab 傻瓜式部署 Stable Diffusion WebUI 的脚步。
要访问下面的服务,需要具备一定的上网条件,如果条件就绪,你可以打开这个网址:https://colab.research.google.com/drive/1lekLF7iib6M1R-NCylS0VMTF4wve-XuV?usp=sharing。
2)直接运行部署脚本的『前置步骤』。
点击下列按钮开始执行『前置步骤』:
 执行前置步骤
执行前置步骤
成功运行完成后,会看到每一个细分步骤前有一个小绿勾。
3)选择和下载需要的 SD 模型和 LoRA 模型。
在 2.1 下载 SD 模型 这一步,参考下图选择 ChilloutMix_Ni_fix 模型:
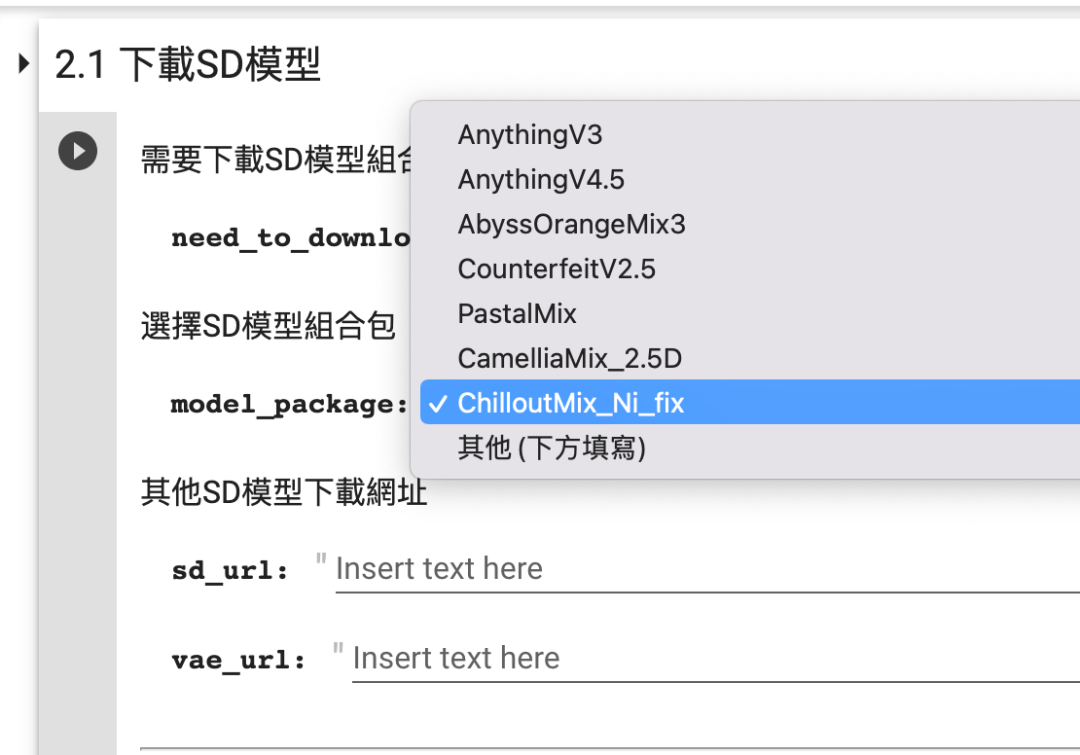 设置要下载的 SD 模型
设置要下载的 SD 模型
在 2.2 下载 Embedding + Hypernetwork + LoRA 这一步,参考下图选择所有的内置 LoRA 模型:
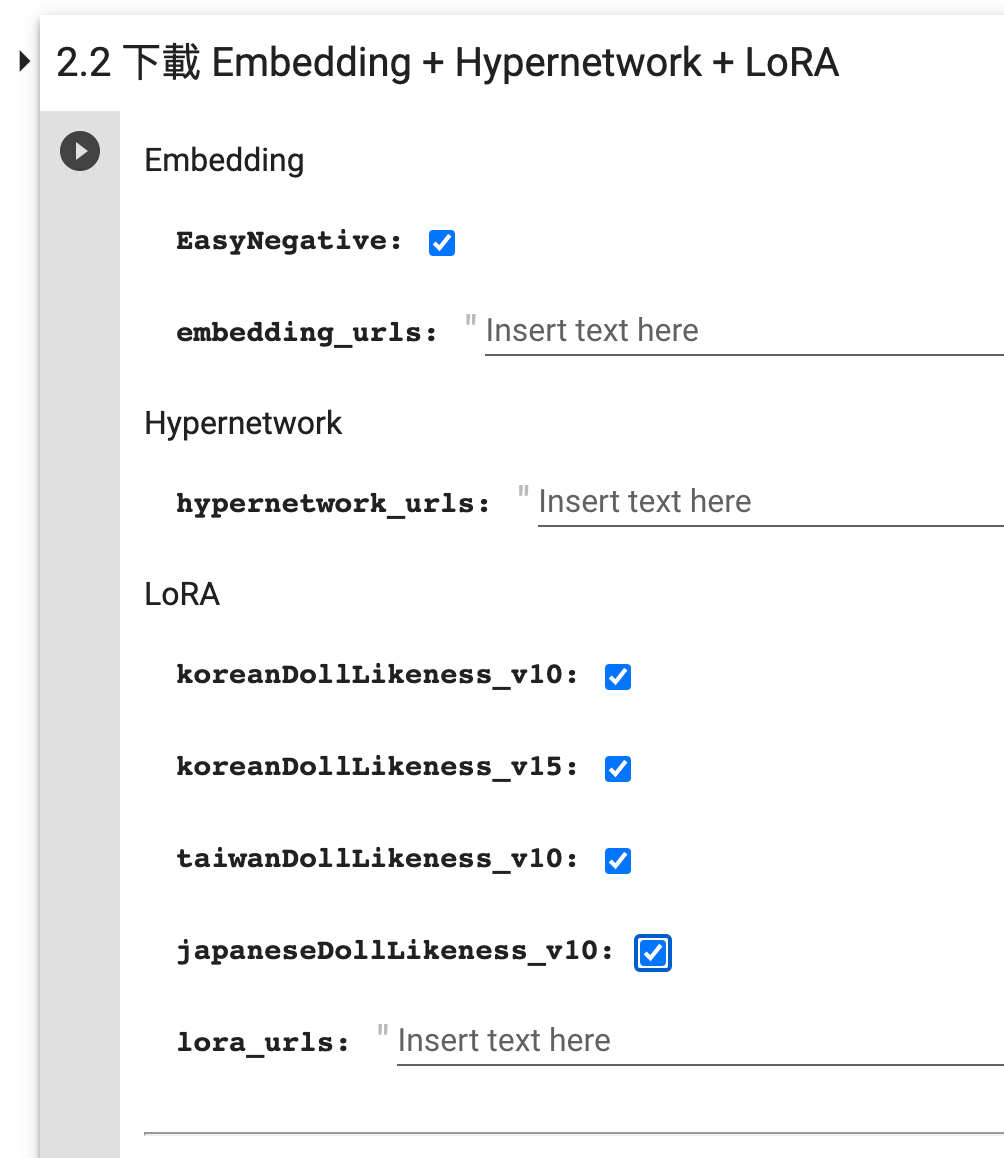 设置要下载的 LoRA 模型
设置要下载的 LoRA 模型
收起 2 - 下载模型,点击下列按钮开始执行『下载模型』:
 执行下载模型
执行下载模型
同样的,成功运行完成后,会看到每一个细分步骤前有一个小绿勾。
4)选择和下载需要的 Extension。
在 3.1 下载&更新 Extensions 这一步勾选需要的扩展:
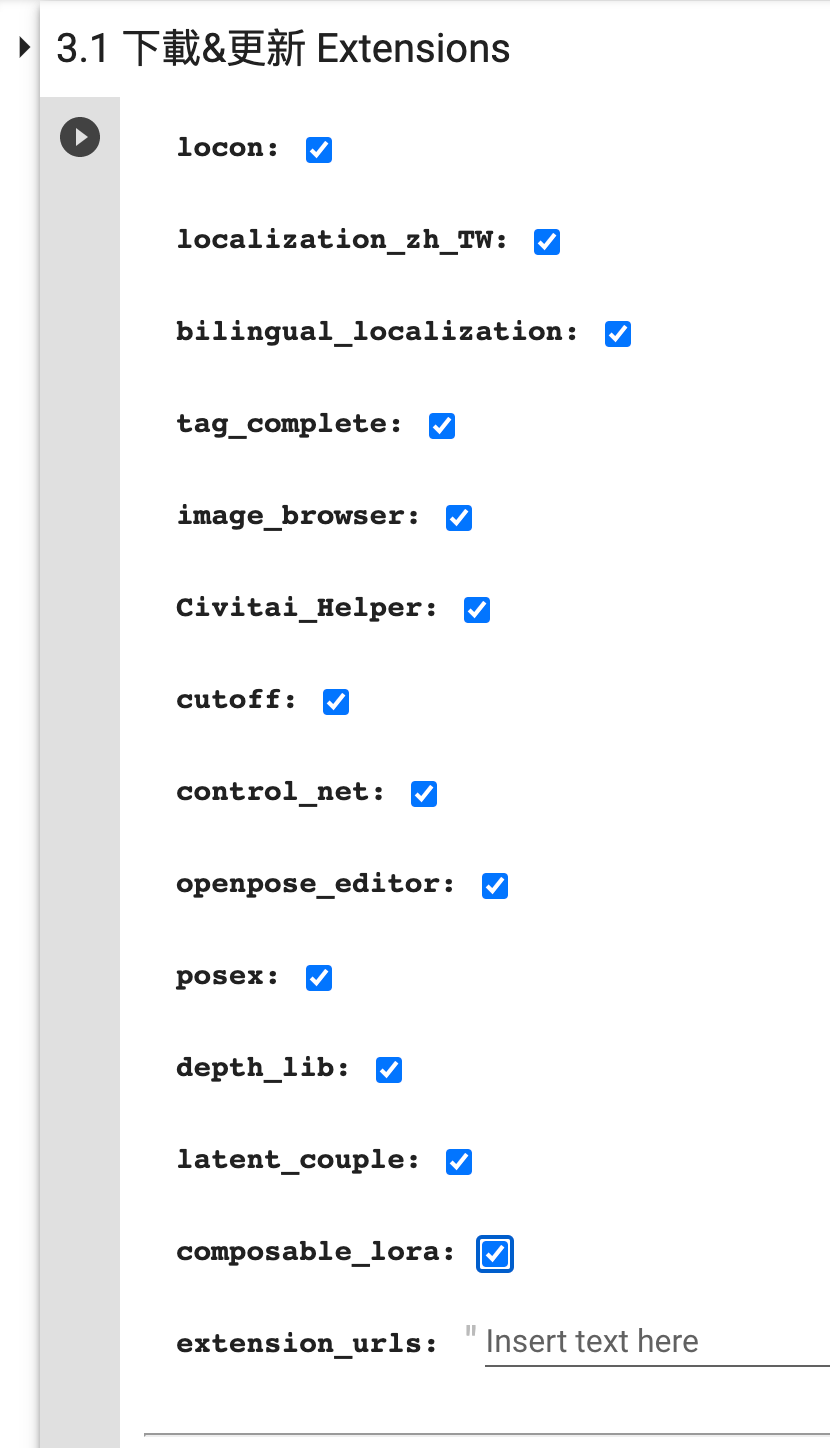 选择需要下载扩展
选择需要下载扩展
在 3.2 下载 ControlNet 模型 这一步勾选需要的 ControlNet 模型:
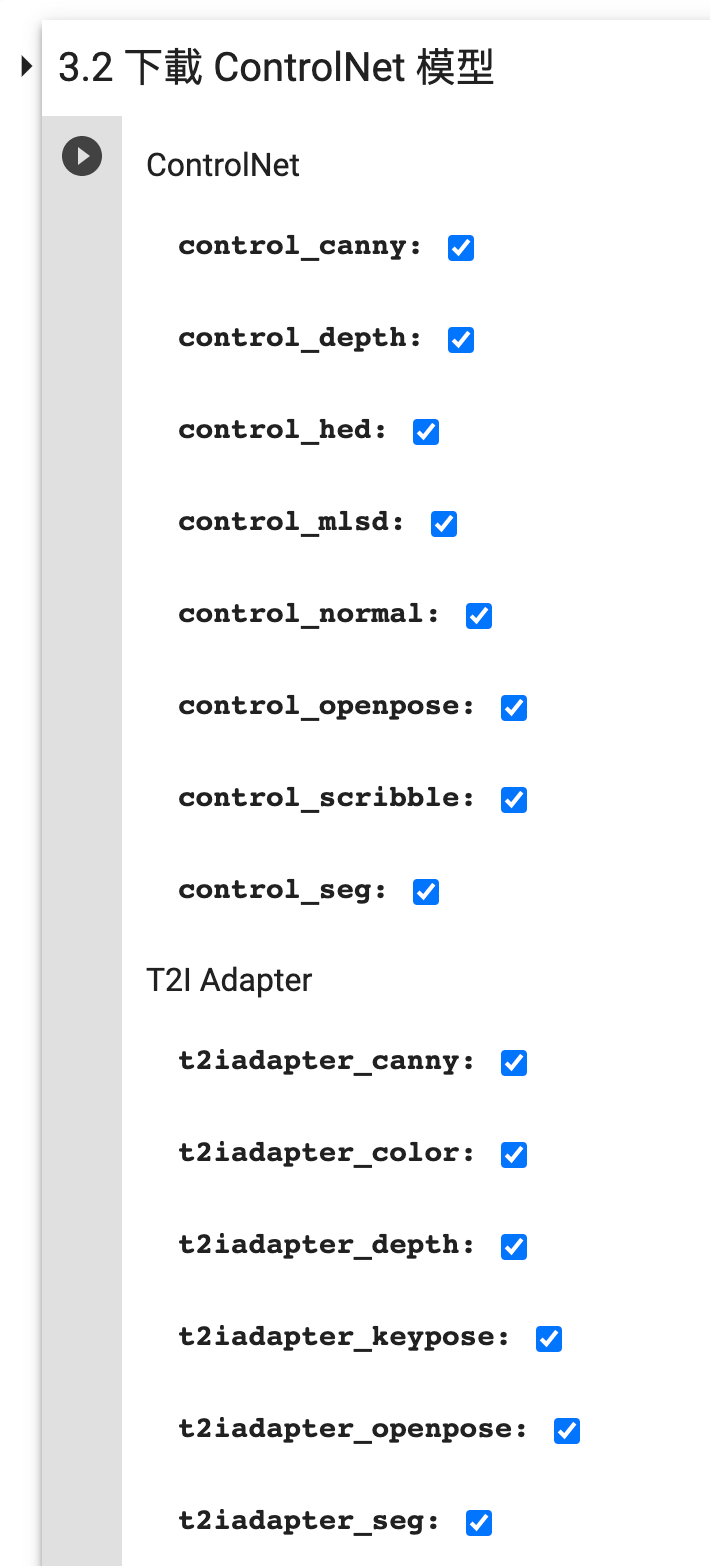 选择需要下载 ControlNet 模型
选择需要下载 ControlNet 模型
收起 3 - Extension,点击下列按钮开始执行『Extension』:
 执行 Extension
执行 Extension
5)直接执行『其他设置』。
点击下列按钮开始执行『其他设置』:
 执行其他设置
执行其他设置
6)直接执行『启动 WebUI』。
点击下列按钮开始执行『启动 WebUI』:
 执行启动 WebUI
执行启动 WebUI
如果顺利运行,到后面你会看到如下输出:
 进入 WebUI 页面
进入 WebUI 页面
点击 public URL 进入 WebUI 页面即可开始使用了。
3、论剑:不同方案的优势和限制
上面介绍的不同方案有着各自不同的优势和限制,你可以根据自己的情况来选择合适的方案。
1)苹果 iOS 手机和平板
使用 Draw Things App:
-
优势:
-
- 是在手机和平板上本地玩 Stable Diffusion 为数不多的选择
- 本地出图,随时可玩
- 使用比较方便
- 支持自己选择基础模型
- 支持 LoRA
- 支持 ControlNet
-
限制:
-
- 要求 iPhone XS 以上
- 使用时手机发热比较明显
- 出图速度不快,一般出图时间在 1 分钟左右
2)苹果 macOS 电脑
使用 Draw Things App:
-
优势:
-
- 本地出图,随时可玩
- 使用比较方便
- 支持自己选择基础模型
- 支持 LoRA
- 支持 ControlNet
- 出图速度还可以,一般出图时间在 30s 左右
-
限制:
-
- 要求 M1 芯片以上
使用 Stable Diffusion WebUI:
-
优势:
-
- 本地出图,随时可玩
- 支持自己选择基础模型
- 支持 LoRA
- 支持 ControlNet
- 支持集成到 WebUI 的各种其他插件
-
限制:
-
- 要求 M1 芯片以上
- 比较吃内存,建议内存 32G 以上
- 使用略微复杂
- 出图速度不快,一般出图时间在 2 分钟左右
3)Windows PC 电脑
使用 Stable Diffusion WebUI:
-
优势:
-
- 本地出图,随时可玩
- 支持自己选择基础模型
- 支持 LoRA
- 支持 ControlNet
- 支持集成到 WebUI 的各种其他插件
- 出图速度不错,一般出图时间在 15s 左右
-
限制:
-
- 要求显卡显存 4GB 以上,内存 16GB 以上
- 使用略微复杂
4)云服务器
使用 Stable Diffusion WebUI:
-
优势:
-
- 不需要操心硬件资源
- 支持自己选择基础模型
- 支持 LoRA
- 支持 ControlNet
- 支持集成到 WebUI 的各种其他插件
- 出图速度不错,一般出图时间在 15s 左右
-
限制:
-
- 使用略微复杂
- 需要联网使用
- 使用云服务资源可能需要付费
4、试剑:基于 Stable Diffusion 如何商业变现
如果你对使用 Stable Diffusion 进行商业变现有兴趣,可以扫描下面二维码加我微信,我将和你交流我们基于 Stable Diffusion 实现商业变现的一些探索。
这份完整版的AI新手入门资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









