







 本文深入探讨深度学习中图像预处理技术,包括随机旋转、颜色通道标准化、min_max_norm标准化及解码至[0,255]区间的方法。同时,解析了针对权重和输入数据的归一化技术,如Xavier初始化、spectral_norm、batch_normalization和AdaIN等,以及每层添加高斯噪声的技巧。
本文深入探讨深度学习中图像预处理技术,包括随机旋转、颜色通道标准化、min_max_norm标准化及解码至[0,255]区间的方法。同时,解析了针对权重和输入数据的归一化技术,如Xavier初始化、spectral_norm、batch_normalization和AdaIN等,以及每层添加高斯噪声的技巧。
一、biasic image process
1、输入的图片数据进行随机旋转。
2、图片减去imagenet均值(一种数据标准化方法)
img[:, :, 0] -= 103.939 # Blue
img[:, :, 1] -= 116.779 # Green
img[:, :, 2] -= 123.6 # Red
3、读入的图数据在均值处理以后再进行min_max_norm标准化到[-1,1]之间。
def min_max_norm(x):
x_ = np.reshape(x, [256 * 256 * 3])# flattern
mean_ = np.mean(x_)
min_ = min(x_)
max_ = max(x_)
x = x.astype(np.float32)
x = (x[:, :, :]-mean_)/float(max_ - min_)
return x
ps:实际上这不是真正的min_max_norm,真正的min_max_norm操作是归一化到[0,1]之间。具体:
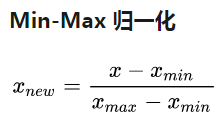
这里的是把分子里最小值换成了均值。
Ps:Z-score标准化。数据的预处理上怎样把数据变成一个均值为0,方差为1的分布,使用最普遍的就是z-score标准化来处理数据。具体如下:
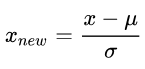
U -> 均值,分母 -> 方差。
4、在最终输出图片的时候需要decode将像素转为[0,255]之间。
img = (img*127.5) + 2
从style-gan中得到的技巧是可以在最后一层用一个1x1的卷积核。
二、normalization between weight and x
Normalization分为两种,一种是针对梯度的,即weight,一种针对输入的x(输入的数据)。
1) 针对梯度:
① 使用Xavier初始化可以保证每一层的梯度方差变化不大
② L2_normalization 和 L2_regulization
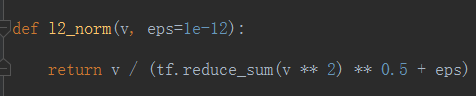
没用过,但是猜测和L2正则功效差不多。

凸函数,不是处处可微分,因此得到是稀疏解,对梯度有特征提取功能。
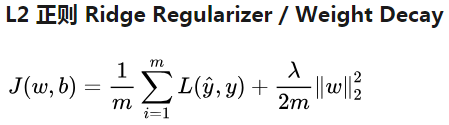
凸函数,处处可微,使得梯度相对平滑。
Ps:L2_标准化和L2正则化的概念还是不同的。个人经验认为在实际应用上L2_标准化比较偏向应用于对input的调整,L2正则化比较偏向应用于对应weight梯度的调整,加一个惩罚项防止某一个梯度过大,防止过拟合。
Ps:L2_标准化和L2_正则的作用应该是差不多的。此外还有drop_out的使用。
③ spectral_norm(主要功能是维护GAN训练的稳定性,最初研究是用在判别器上,后发现在生成器上的效果也很好)
2) 针对input:
① batch_normalization
② AdaIN:”Adaptive Instance Normalization” in
https://arxiv.org/abs/1703.06868 for details.(主要是针对style和input之间做的一个normalization,维持style对input的影响力。)style-base方法几乎都必须使用。
三、每一层都加高斯噪声:
def gaussian_noise_layer(input_layer, std):
noise = tf.random_normal(shape=tf.shape(input_layer), mean=0.0, stddev=std, dtype=tf.float32)
return input_layer+noise
ps:spectral_norm、batch_normalization和AdaIN代码github上有。有需要私信发你也可以。
ps:研究完style-gan可以更新一遍了。

















 1679
1679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









