




 本文深入探讨了TensorFlow的高级特性,包括TensorBoard的使用、slim模块的介绍、tf.nn与tf.layers的区别、动态图机制Eager Execution、自定义Estimator的创建,以及卷积和反卷积操作的详细解析。
本文深入探讨了TensorFlow的高级特性,包括TensorBoard的使用、slim模块的介绍、tf.nn与tf.layers的区别、动态图机制Eager Execution、自定义Estimator的创建,以及卷积和反卷积操作的详细解析。
tensorflow-Note
1,tensorboard(tf.summery)
https://blog.youkuaiyun.com/sinat_33761963/article/details/62433234
https://blog.youkuaiyun.com/shenxiaolu1984/article/details/52815641
2,slim模块
https://blog.youkuaiyun.com/guvcolie/article/details/77686555
https://zhuanlan.zhihu.com/p/35203106 (这个知乎的讲的比较易读,slim也是对tf.nn进行的一些较为高层封装,目的为能够快速构建模型,我认为其最让我喜欢的功能就是stack、arg_scope和repeat,能让模型更加精致。)
3,tf.nn,tf.layers, tf.contrib的区别
https://blog.youkuaiyun.com/u014365862/article/details/77833481
tf.contrib是最不稳定的,建议少用,这三个官方一直更为推荐的是tf.layers,虽然也是对tf.nn的封装,但是比较友好,所以其实现在有三个选择面向tfboy 和tfgirl,slim,tf.layers,tf.keras,tf.keras和动态图模式、生产环境的Estimator部分兼容,感觉用tf.keras会越来越多,虽然现在pytorch真的不错。
4,tensorflow动态图机制Eager Execution
https://ai.googleblog.com/2017/10/eager-execution-imperative-define-by.html
https://www.zhihu.com/question/67471378 (知乎的这个不错)
动态图模式中使用tf.data.Dataset这个API进行输入:https://www.tensorflow.org/api_docs/python/tf/data/Dataset
模型的构建官网推荐使用tf.keras的API:https://www.tensorflow.org/api_docs/python/tf/keras
5,创建自定义 Estimator
https://www.tensorflow.org/guide/custom_estimators
6,卷积核反卷积总结
卷积和反卷积总结:
1, 参数计算:
- 卷积padding=VALID:
Output_h = (original_h + padding*2 – kernelSize_h)/strides + 1 - 卷积padding=SAME:
Output_h = float(original_h)/float(strides) - 反卷积padding=SAME:
Output_h = input_h*strides - 反卷积padding=VALID:
Output_h = input_h* kernel_h – (kernel_h - strides)*(input_h-1)
或者:
Output_h = (input_h-1)*strides + kernel_h
Ps:VALID下的公式仍存疑问
反卷积(转置卷积)tensorflow下的API详解:
deconv = tf.nn.conv2d_transpose(x, kernel, output_shape=output_shape, strides=[1, d_h, d_w, 1], padding=’SAME’)
‘’’
:param x: 输入的将被反卷积的对象
:param kernel: 卷积核[k_h, k_w, out_channel(你输出featuremap的通道数), in_channel(x的通道数)]为什么是反的,后面推导证明。
:param output_shape: 指定输出的维度,一般直接按:[batch_size, x.get_shape().as_list()[1]*strides, x.get_shape().as_list()[2]*strides, out_channel]
:param strides:[1, d_h, d_w, 1]步长。(这个参数非常重要)
‘’’
反卷积在tensorflow中的实现以及推导:
现有kernel:3x3 称为kernel
Input:4x4 称为矩阵A
Stides:1
Output:2x2
参数在正向卷积时候有如下:
Kernel为3x3矩阵,其将对A4x4的矩阵进行卷积,可将kernel转化为如下4x16的矩阵:
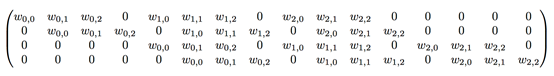
再将A转化为16x1的矩阵,则输出为:
Y = kernel * A
得到的Y为4x1的向量,再转化为2x2的矩阵即为我们的输出
而反卷积就是从output4x1 input16x1即将4x1向量变为16x1,此时需要一个
A = kernel_ * Y
Kernel_必须是16x4维的而kernel_ = transpose(kernel)
故而转置卷积由此而来。
Tensorflow实现时候直接将正向卷积的kernel矩阵进行转置然后进行反卷积。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









