




 本文详细介绍了Transformer架构,包括编码器和解码器的堆栈结构,自注意力机制,以及训练过程中的输入处理和位置编码。还探讨了词嵌入层和位置编码的作用,以及矩阵维度在模型中的流动。
本文详细介绍了Transformer架构,包括编码器和解码器的堆栈结构,自注意力机制,以及训练过程中的输入处理和位置编码。还探讨了词嵌入层和位置编码的作用,以及矩阵维度在模型中的流动。
什么是Transformer?
Transformer架构擅长处理文本数据,这些数据本身是有顺序的。他们将一个文本序列作为输入,并产生另一个文本序列作为输出。例如,讲一个输入的英语句子翻译成西班牙语。
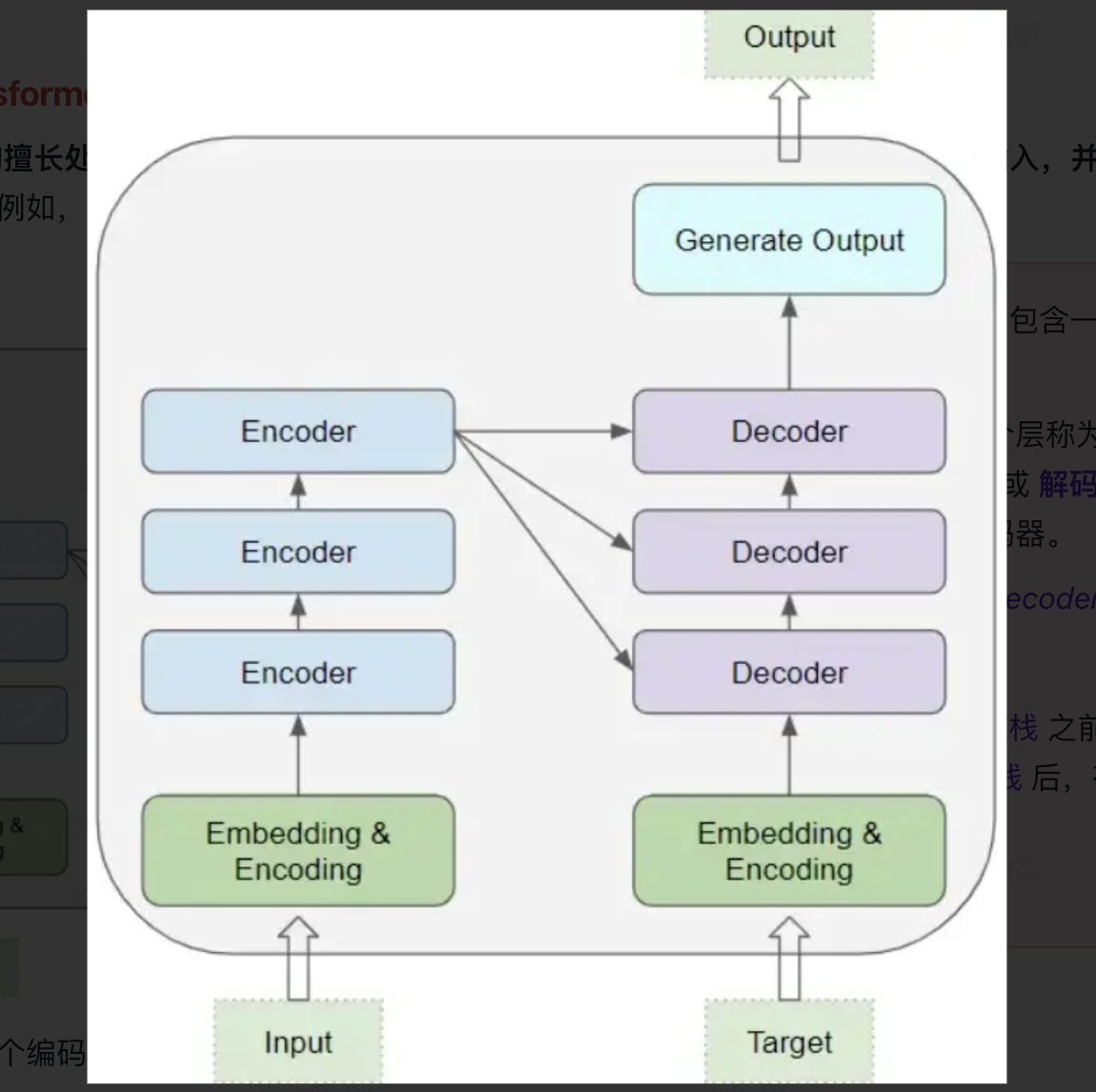
Transformer的核心部分,包含一个编码器层和解码器层的堆栈。
为了避免混淆,我们把单个层称为编码器或解码器,并使用编码器堆栈或解码器堆栈分别表示一组编码器与一组解码器。
在编码器堆栈和解码器堆栈之前,都有对应的嵌入层。而在解码器堆栈后,有一个输出层来生成最终的输出。
编码器堆栈中的每个编码器的结构相同。解码器堆栈也是如此。其各自结构如下:
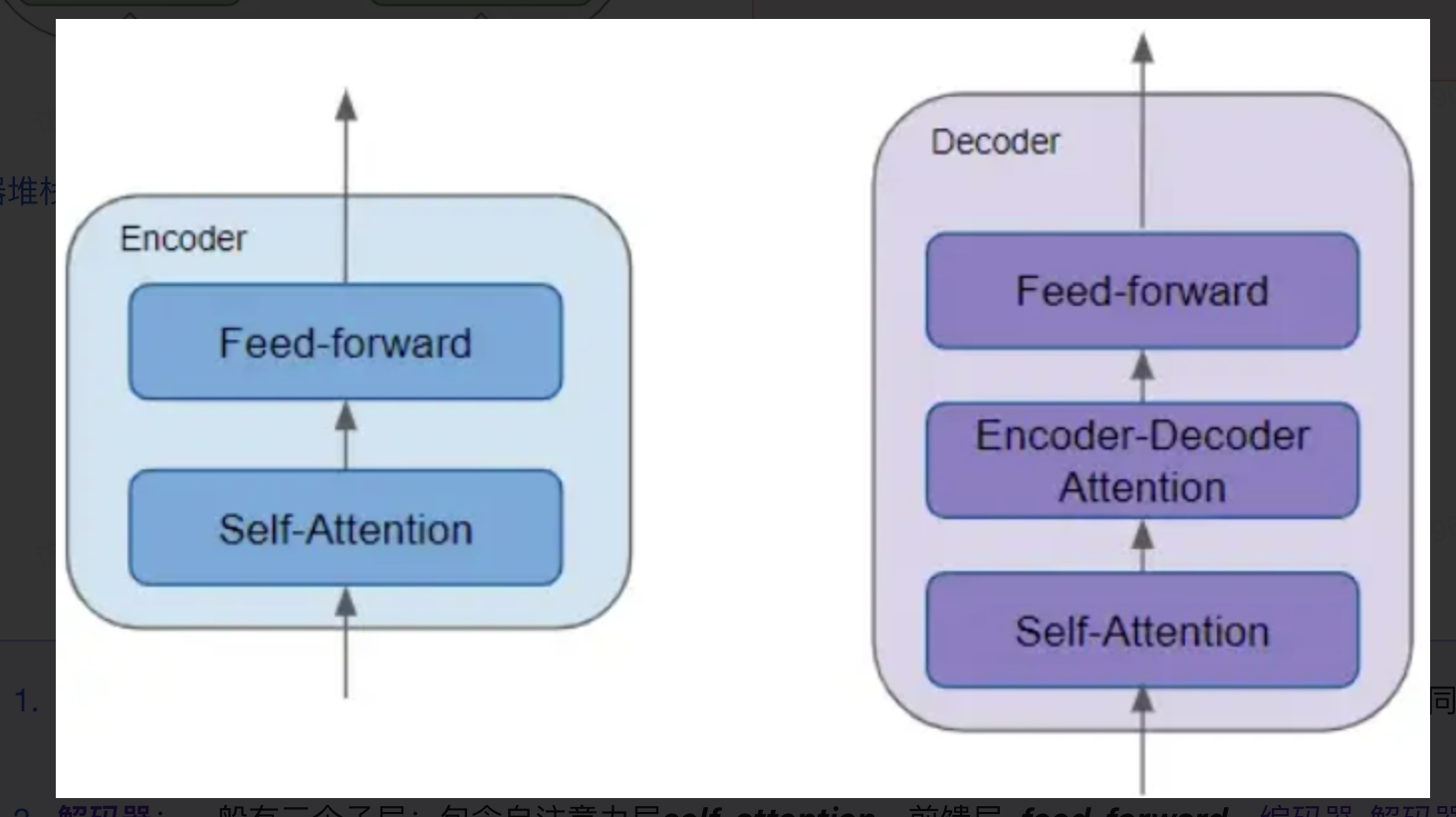
- 编码器:一般有两个子层:包含自注意力层self-attention,用于计算序列中不同词之间的关系;同时包含一个前馈层feed-forward。
- 解码器:一般有三个子层:包含自注意力层self-attention,前馈层feed-forward,编码器-解码器注意力层Decoder-Encoder self attention。
- 每个编码器和解码器都有独
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1797
1797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











