




1.Transformer 整体结构
首先介绍 Transformer 的整体结构,下图是 Tansformer 用于中英文翻译的整体结构:
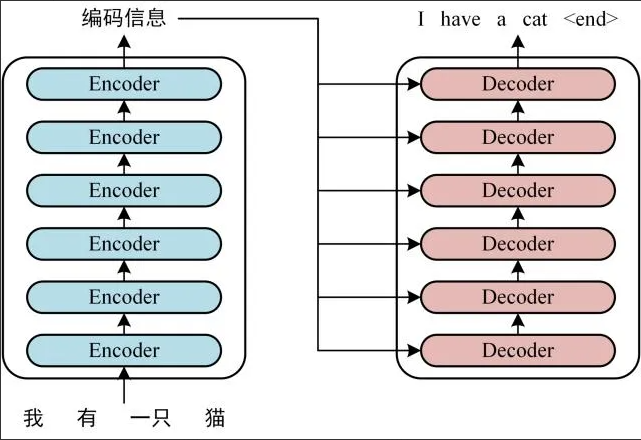
Transformer 的整体结构,左图Encoder和右图Decoder
可以看到Transformer由Encoder和 Decoder 两个部分组成,Encoder和Decoder都包含6个block。
Transformer 的工作流程大体如下:
第一步:构建输入句子中每个单词的表示向量X,该向量通过单词的Embedding(即从原始数据提取的特征)与单词位置的Embedding叠加生成。
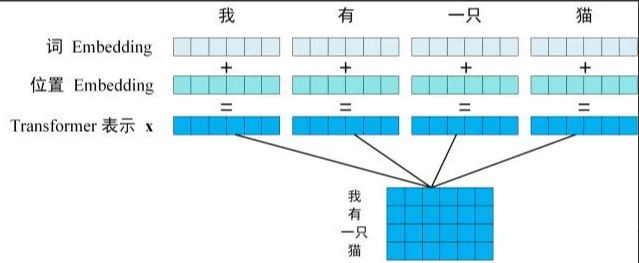
Transformer的输入表示
第二步:将形成的单词表示向量矩阵(如图示,每行对应一个单词的表示x)输入至Encoder,经过6个Encoder模块处理后,输出包含句子全部单词编码信息的矩阵C。

最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
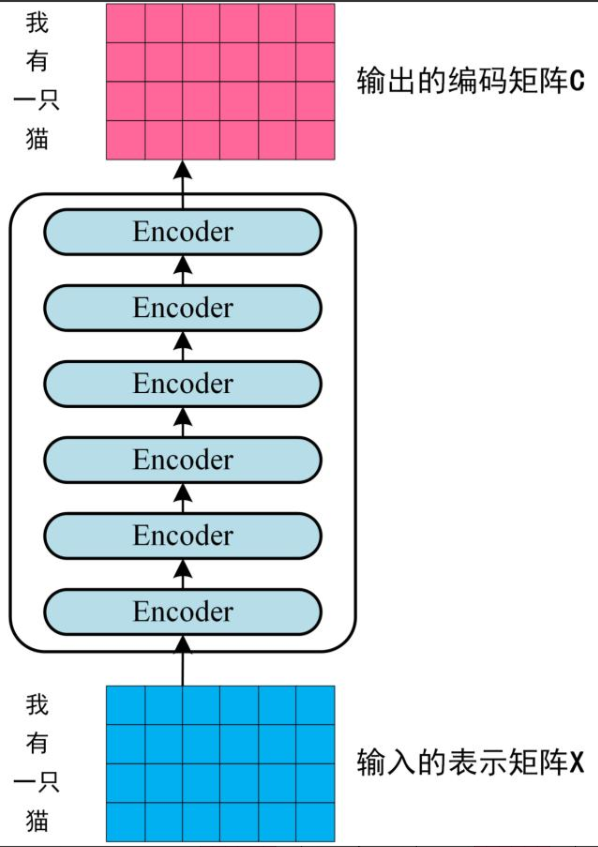
Transformer Encoder 编码句子信息
第三步:将Encoder生成的编码矩阵C传递至Decoder,Decoder按序基于已翻译的单词1~i预测后续单词i+1,如图示流程。
在预测i+1时需通过Mask操作遮蔽i+1之后的单词信息。
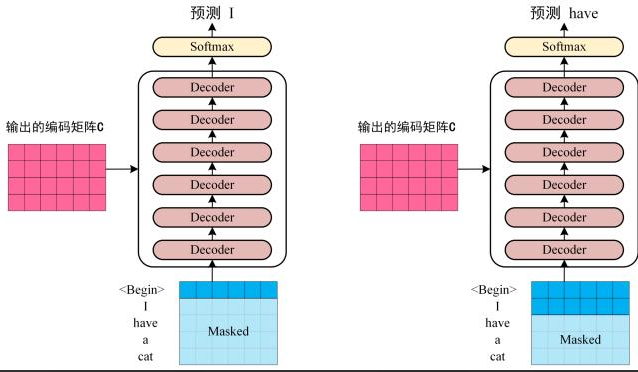
Transofrmer Decoder 预测
图示中,Decoder首先接收编码矩阵C并输入起始符"“,首轮预测结果为"I”;随后结合"“与"I"预测"have”,逐步推进。
此为Transformer模型的基本工作流程,后续将详解各组件细节。
1.1 Transformer 的输入
Transformer 中单词的输入表示x由 单词 Embedding 和 位置 Embedding(Positional Encoding)相加得到。
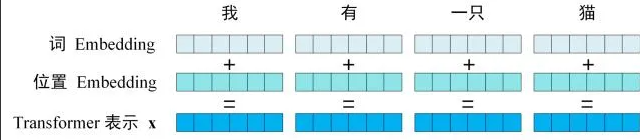
Transformer 的输入表示
1.1.1 单词 Embedding
单词的 Embedding 有很多种方式可以获取,例如可以采用 Word2Vec、Glove 等算法预训练得到,也可以在Transformer 中训练得到。
1.1.2 位置 Embedding
在Transformer模型中,除词Embedding外,还需引入位置Embedding(PE)以表征单词在句子中的位置信息。
由于Transformer摒弃了RNN结构,采用全局注意力机制,无法直接获取单词的顺序信息,而这正是自然语言处理(NLP)任务中的关键要素。
因此,位置Embedding被用于编码序列中单词的相对或绝对位置关系。
位置Embedding(PE)的维度与词Embedding保持一致。
其实现方式可分为两种:通过训练学习或基于公式计算。原始Transformer论文选择了后一种方法。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 975
975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









