






原文链接:
贡献
1)考虑到跨域连通性和实际约束条件,提出了一种层次化异构多智能体系统。
2)提出了一种层次化的任务分解方法,该方法不仅能在现实约束条件下处理搜索使命,而且能增强人对系统的理解。
3)在MARL的基础上提出了一种串行耦合依赖策略的训练方法MARL,该方法能够成功地同时训练多个策略。
模型建立
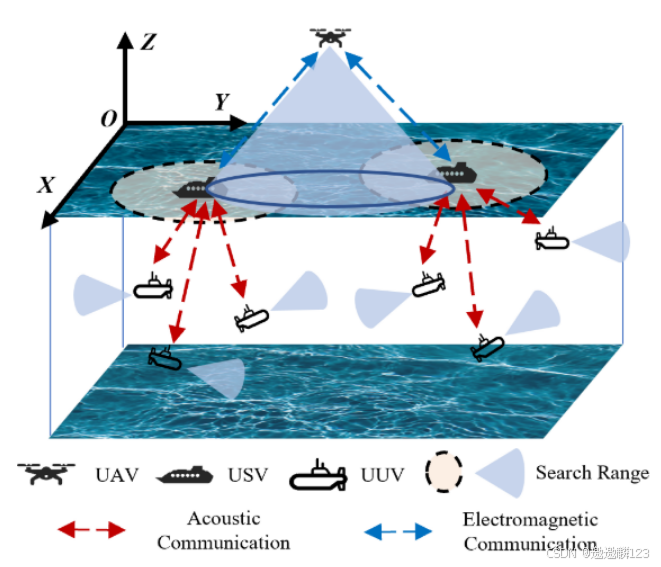
主要的困难在于UUV的运动和控制,因为USV和UAV都有自己独特的运动规则。对于UUV,它们的运动由USV发送的命令引导,遵循相同的基本编队来探索水下环境并使用装备的FLS确定水下目标的位置。

约束包括对UUV的位置、角度、速度和加速度的限制。此外,为了确保与USV和外部环境的可靠通信连接,我们对同一基本编队内USV和UUV之间的距离施加了限制。
任务划分
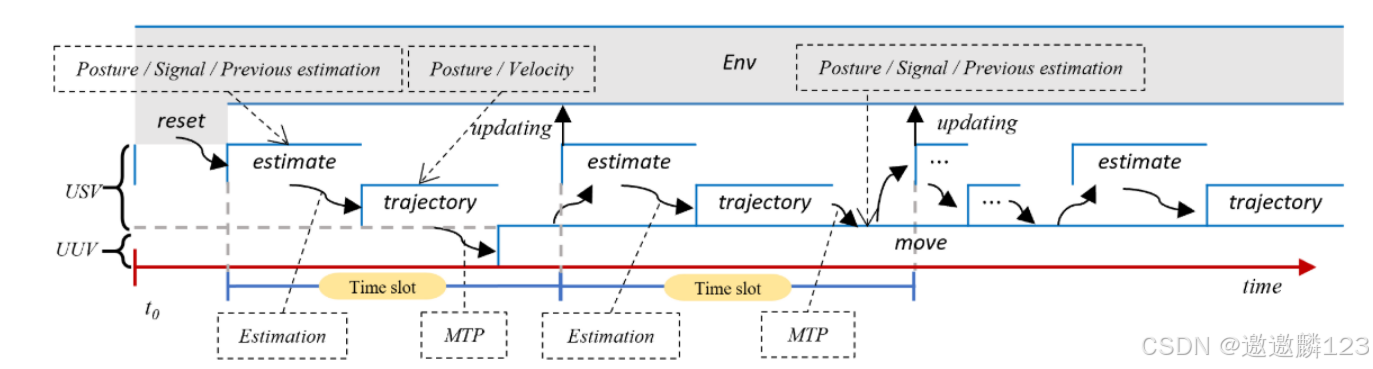
根据跨域环境属性,将水下搜索任务划分为移动、目标估计和轨迹规划三个子任务。
USV负责目标估计和轨迹规划子任务,而UUV负责移动子任务。
1)模拟环境在其边界内随机重置相关参数。
2)USV根据相关信息,如UUV的姿态和信号,估计目标区域。USV规划UUV的MTP并将其传递给UUV。
3)UUV移动到各自的位置,整个过程重复进行,直到任务完成信息收集。
移动子任务
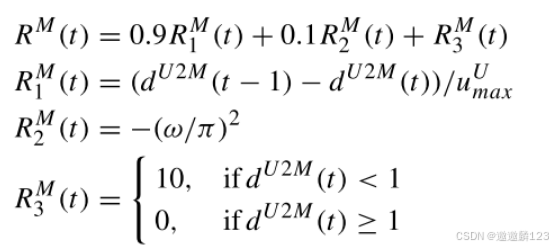
RM1(t)是与时间段t和时间段t-1的MTP与当前位置的距离差相关的报酬。
dU2M(t)= ηU(t)-ηMTP(t)表示UUV与MTP之间的距离;
uU max是用于RM1(t)标准化的UUV在洋流中的最大速度。
RM 2(t)是对应于UUV的当前运动方向与连接当前位置和MTP的线的方向之间的角度ω的回报。RM 3(t)是MTP与当前位置之间的距离小于1时的终端报酬。
采用PPO。
目标估计子任务
通过对同一基本编队内的所有UUV的相关状态信息进行聚合,并结合上一时刻的估计结果,采用目标估计策略πE对目标区域进行估计,有助于规划UUV的轨迹,加速搜索过程。
为了在减轻数据存储需求和降低计算成本之间取得平衡,提出了一种仅使用单向前馈神经网络(FNN)进行估计任务的方法。
为了更有效地利用历史数据,结合了递归神经网络(RNN)的原理,该网络能够使用内部状态(内存)来处理任意输入序列。利用来自前一时隙的估计区域来初始化内部状态,该估计区域用作下一时隙的估计的输入的一部分。
此外,置信度参数有助于对连续估计之间的关系进行建模。这种方法允许FNN保留一种形式的存储器,提供类似于RNN的一些功能,但具有更流线型的网络架构。
FNN
https://zhuanlan.zhihu.com/p/653205860
RNN
【循环神经网络】5分钟搞懂RNN,3D动画深入浅出_哔哩哔哩_bilibili

通过采用这种配置,仅需要保存上一个时隙的估计结果,并且可以将其看作当前状态的一部分。
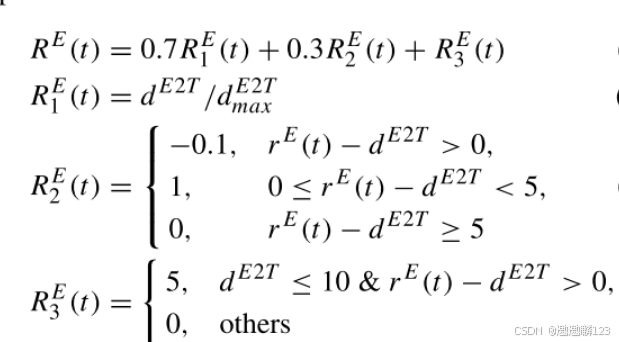
RE 1(t)是与真实目标位置和估计目标位置之间的距离相关联的回报。
RE 2(t)在ηT(t)不在估计区域内的情况下惩罚动作,在ηT(t)在估计区域内的情况下奖励动作,并且在估计区域过大的情况下避免给予奖励,因为可能不会积极地搜索任务。
RE 3(t)是当距离dE 2 T小于10并且真实目标位置在估计区域内时的终端奖励。
轨迹规划子任务
在USV估计目标区域之后,下一步是引导UUV确定目标位置。USV采用策略πP来规划UUV的轨迹。
HHMA系统旨在通过轨迹规划策略快速搜索目标。因此,奖励与目标与每个UUV之间的距离以及每对UUV之间的距离有关。奖励的定义如下:
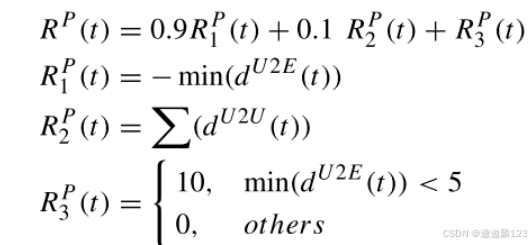
RP1(t)与估计目标位置与每个UUV之间的最小距离(dU2E(t))相关联,旨在鼓励最近的UUV评估估计位置是否正确。
RP 2(t)是每对UUV之间的距离dU2U(t)之和。这鼓励UUV彻底探索环境,帮助目标估计策略πE准确估计目标位置。
RP 3表示终端奖励,当最小dU2E(t)小于5时触发。
多策略强化学习
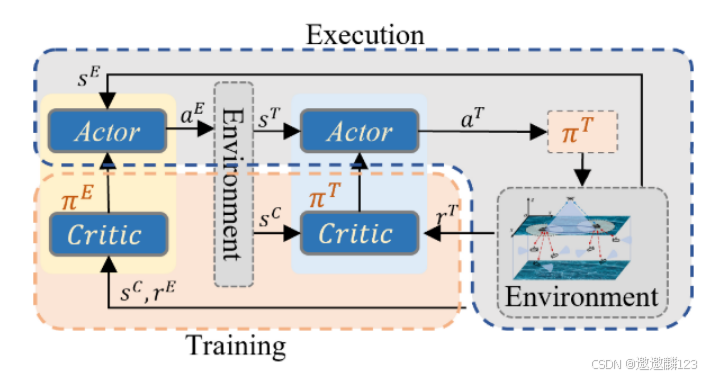
由于目标位置估计策略的输出在轨迹规划策略执行之前会改变环境,因此,不能单独训练两个串联耦合的策略,运动子任务可以依赖于目标随机发生器来训练,在目标估计任务的背景下,当π P在RL训练期间经历变化时,状态转移函数PE的概率性质受到环境变化的影响。
此外,γE的存在又增加了一层复杂性,因为不同的政策π P不仅会影响它们自己未来的回报,还会影响整体的环境动态。
考虑到这两种政策之间的相互依赖性,引入了一种MPRL方法。MPRL和MARL政策的培训模式都遵循集中培训和分散执行(CTDE)的方法,类似于MARL。
与MARL相比,MPRL有以下不同之处:
1)异步策略执行引入了更高的依赖度。
2)MPRL是当每个策略被执行时,在现实的时间内给出不同的奖励,而MARL是在所有agent同时执行MARL的策略后给出团队奖励。
3)在MPRL中,两种策略的输入及其对应的批评网络是在不同的时间获得的。相反,在MARL中,所有agent的输入,以及对应的批评网络的输入是同时获得的。

前一个策略可以影响另一个策略的状态转换函数,努力最大限度地减少前一个策略对当前更新的影响。为此,采用了一种基于策略的算法,特别是IPPO,它建立在PPO算法的基础上,用于同时更新πE和π P。采用了一个行动者-批评者架构。
在相同的时隙内,πE和π P的批评网络之间的输入OE和rE不同,这强调了这两个策略的操作中固有的顺序性质。
总结
将水下搜索使命分解为三个子任务,这些子任务设计成能够适应环境条件和设备能力:移动、目标估计和轨迹规划。
为了解决相互依赖策略的训练问题,提出了一种基于MARL和CTDE的MPRL框架,并利用改进的IPPO算法实现了该框架。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









