






对于多智能体系统,任务分配本质上是一个多目标问题,涉及多个但可能相互冲突的性能要求。
本文任务分配的5个目标包括:1)最大完工时间、2)Agent满意度、3)资源利用率、4)任务完成时间、5)任务等待时间。
目录
贡献
1. 针对多任务多智能体分配问题,提出了一种新的分层MAS模型,分为两层。
2. 模型的第一层用于任务划分和简化优先级排序。引入deep Q-Learning。极大地节省了时间,提高了调度效率。
3. 模型的第二层用于同时进行任务分配和调度。提出了一种基于MSDE-SPEA 2的多目标优化方法,对多目标优化问题进行求解。
基于MSDE-SPEA 2的算法具有较强的多目标平衡能力。

以往研究不足
目前为止,已有各种调度方法来进行任务分配,以确保短的完工时间,高成功率和很少的冲突。但分配和调度问题很少被同时考虑到。
模型建立
| 第i个任务 | |
| 任务标识 | |
| 任务类型
| |
| 任务优先级
| |
| 任务的能力需求向量
| |
| 任务的资源需求向量
| |
| 完成任务的最大报酬 | |
| | 最大执行持续时间 |
分层
1. 第一层智能体
| 任务是否被划分的标志
|
2. 第二层智能体
|
| |
|
| |
|
|
目标定义
1. 分配给agent联盟Ci的任务ti的执行时间
2. agent满意度指数:agent对其回报的评价
3. 任务集T的完工时间
4. 任务ti的联盟Ci的资源利用率
5. 任务集合T的任务分配成功率:如果:1)相应的代理联盟满足任务的要求; 2)代理之间没有冲突; 3)ti的等待时间和ti的执行时间之和不超过最大持续时间TDti,则称分配成功。
6. 总任务等待时间定义
任务分配算法
第一层(任务划分与优先级简化)
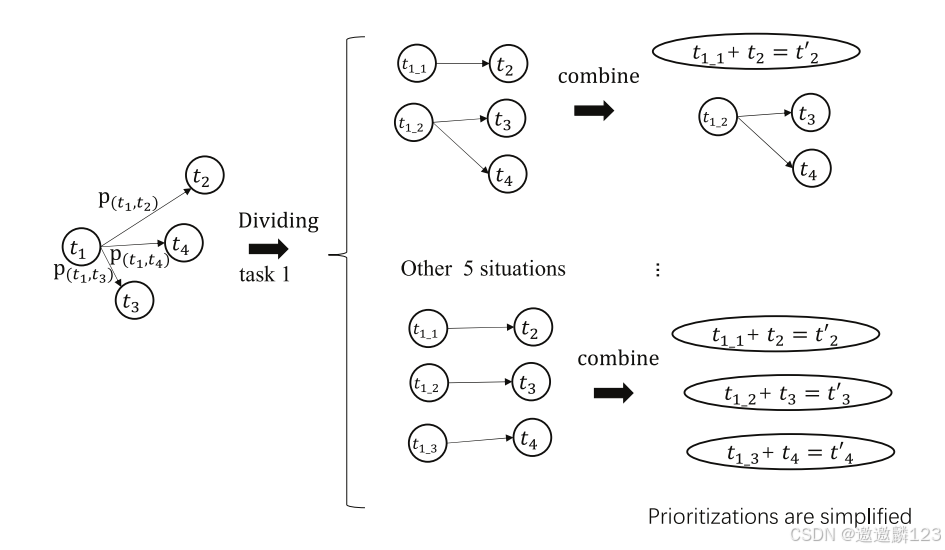
完成任务t1后,将以不同概率执行任务t2、t3和t4。
即划分任务t1,子任务t1_1以概率p(t1,t2)与任务t2合并,并将新任务标记为t2',即简化了(t1,t2)的优先级。当t1的所有子任务都被处理时,t1的优先级被简化,t3和t4同理。
在这种情况下,t1有7种不同的分法。因此,一个任务是否可以被划分取决于最后一个任务的情况和相应的概率。
划分
为了找出任务划分集合DS',尽可能简化优先级排序,引入DQL。
1)state:当前任务划分集合DS'。新的任务添加到DS'中来更新。结束状态指没有任务可以被划分。
2)action:新任务被添加到DS'中。
3)reward:新任务所导致的简化优先级的程度。
4)policy:贪婪策略。

合并
对DS'中的任务进行划分,得到新的任务集T。
引入辅助参数p。如果任务ti是待分割的,且p > p(ti,tη),则ti的子任务ti_λ将成功地与tη合并。如果任务ti被分割,且p < p(ti,tj),则子任务将不能与任务tη合并。
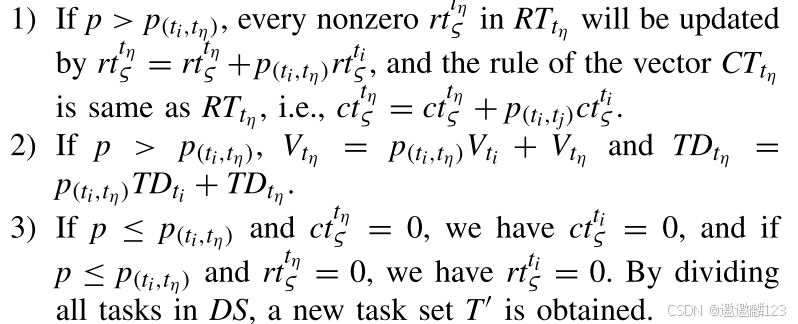
第二层(任务分配与调度)
在新的任务集T和第二层Agent集A的基础上,提出了基于MSDE-SPEA 2的多目标任务分配与调度优化算法。
1. 定义五个目标
2. 定义约束条件
a. 任务类型限制
b. 时间限制:ti的等待时间和ti的执行时间之和不能超过最大持续时间
c. agent约束:一个agent不能同时加入一个以上的联盟
d.资源限制:如果一个任务被分配给一个联盟,则该联盟应满足至少有一个Agent满足资源条件
MSDE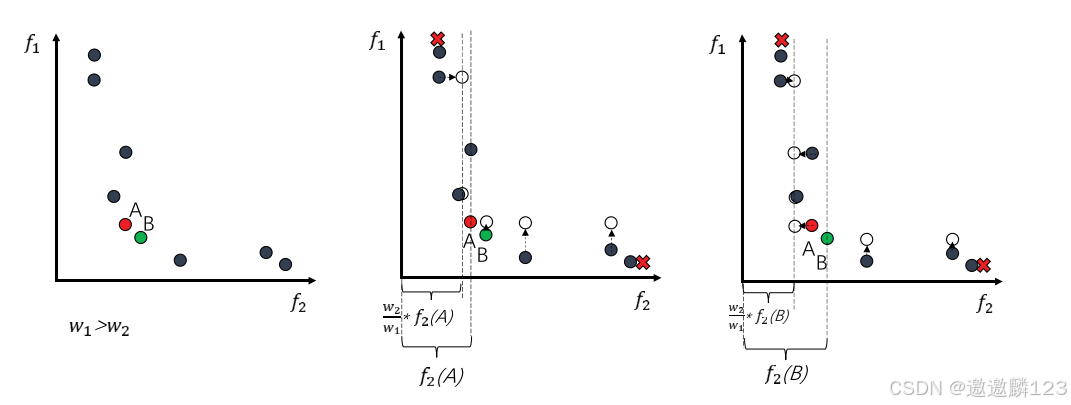
假设f1的权重w1大于f2的权重w2。
f1轴上每个节点的移动将遵循基本的递归方法:f1轴上每个节点的值等于目标节点的f1值,f2轴上的每个节点的值将是w2/w1的值乘以目标节点的f2值。具体移动规则如下:
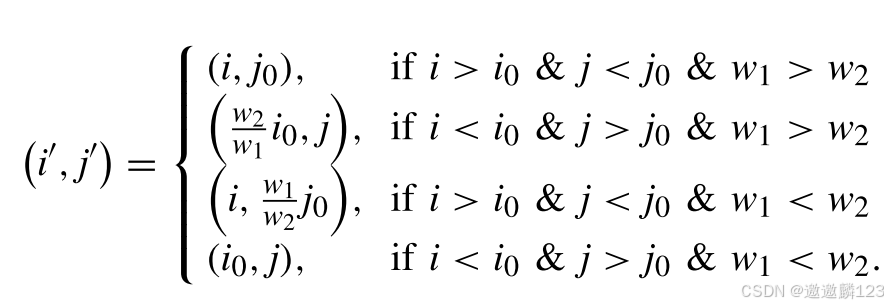
可以看出,两个A和B在这两个功能上没有明显差异。因此,通过MSDE方法进行评估个体密度,并且在第二和第三坐标轴中分别展示了它们的基于移位的密度估计的过程,并得出,A具有比B更好的聚类评估值。

染色体编码
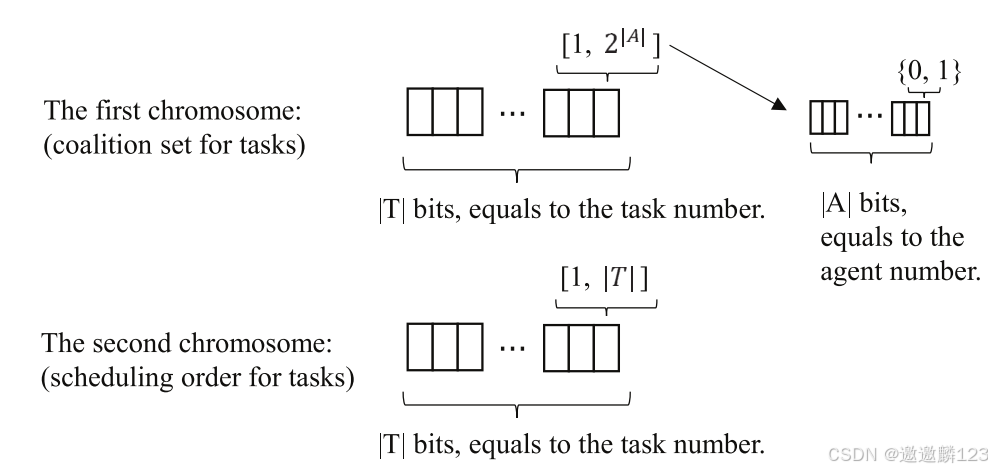
当涉及到具体的任务分配时,染色体编码在交叉和变异算子中起着非常重要的作用。
每个个体包含两条染色体。统一两条染色体的长度为|T|位。
第一条染色体:每个任务的联盟组合。每个位的范围是[1,2^|A|]。这种二进制表示包括所有类型的agent联盟。
第二条染色体:整个任务集的调度顺序。每个位的某些值可能相同,因为某些任务可能同时执行。
染色体的交叉
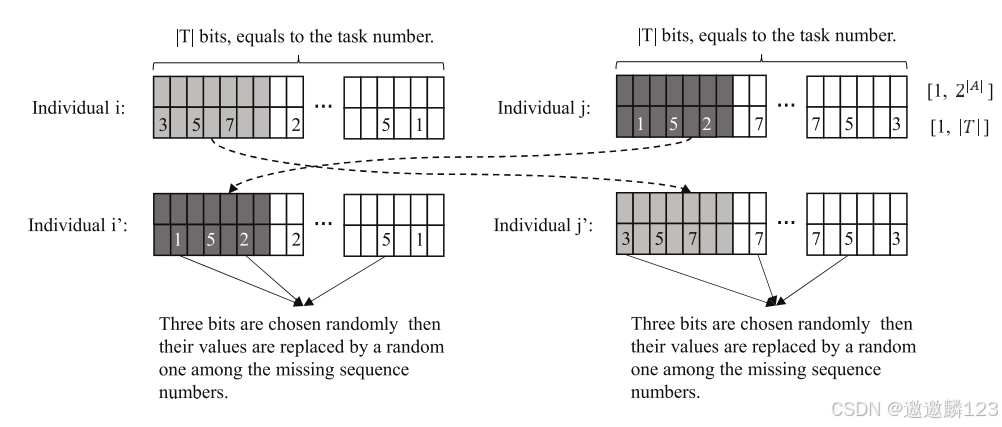
根据随机选择的截断位置,染色体的前7位被交换。该交叉算子不仅包含联盟信息,还包含相应的调度序列。但是,交换的染色体的调度信息可能由于缺少序列号而变得混乱。
因此,需要补充缺失的序列号。在第二染色体中,随机选择一个位具有相同值的位,替换丢失的序列号。
算法如下:

染色体的变异
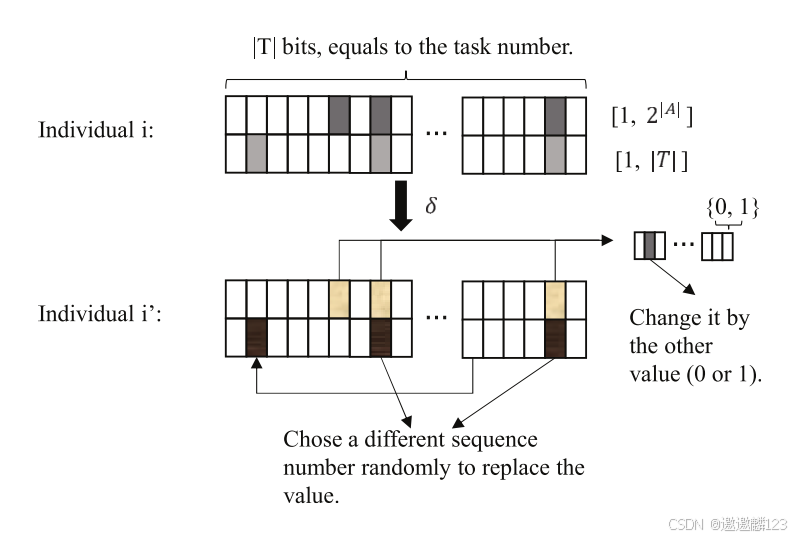
包括联盟变异、调度变异和联盟-调度对变异。
突变概率δ,如上图,一个位用于联盟变异,一个位用于调度变异,两个位用于联盟-调度对变异。
对于联盟变异,首先,将所选位的值转换为二进制队列。然后,将“1”加到任意位。最后,将生成的二进制队列转换为十进制。
对于调度突变,随机选择一个位,并且其值将替换应当被突变的位的值。
对于联盟-调度对变异,联盟部分服从联盟变异,调度部分被替换为不同的调度序列号。
算法如下:

算法总结

算法3可以得到一个最优解集OSS,但实际上对于一个特定的任务分配问题最终只能执行一个解。因此,需找出最终解决方案的选择方法。
将具有最大评估值的解决方案放入一个集合FL中。

计算OSS中每个解决方案si的评估值,将具有最大评估值的解决方案放入一个集合FL中,并不断筛选更新,缩小FL,最终在FL中随机选择一个解作为最终解。
评价
为了全面评估基于MSDE-SPEA 2的方法的性能,引入了IGD度量对该方法进行了测试。
IGD:反映解集的收敛性和多样性的组合信息的度量。IGD从Pareto前沿中的点到所获得的集中它们的最近解的平均距离。
引入HV度量来计算所获得的解集与参考点之间的目标空间的体积。
进一步的研究课题:
1)不同协作环境和不同Agent类型下的分布式MAS深度学习;
2)利用一些新的优化方法求解动态环境中的不确定任务分配问题;
3)在具有面向工程的复杂性的MAS上的任务分配问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









