




 数据投毒攻击是通过篡改或添加恶意数据影响机器学习模型训练,降低预测准确性的一种手段。攻击者可操纵如Yelp、Twitter等平台的训练数据,导致模型行为异常,如微软Tay聊天机器人因投毒攻击产生种族主义言论。投毒攻击包括对深度学习、推荐系统等的后门攻击,使得模型在正常样本上表现良好,但在特定触发器下产生错误预测。防御策略涉及数据清理、鲁棒学习,如PCA检测模型、TRIM算法等,以及后门攻击检测方法,如激活聚类和输入过滤。
数据投毒攻击是通过篡改或添加恶意数据影响机器学习模型训练,降低预测准确性的一种手段。攻击者可操纵如Yelp、Twitter等平台的训练数据,导致模型行为异常,如微软Tay聊天机器人因投毒攻击产生种族主义言论。投毒攻击包括对深度学习、推荐系统等的后门攻击,使得模型在正常样本上表现良好,但在特定触发器下产生错误预测。防御策略涉及数据清理、鲁棒学习,如PCA检测模型、TRIM算法等,以及后门攻击检测方法,如激活聚类和输入过滤。
1.投毒攻击
如果机器学习模型是根据潜在不可信来源的数据(例如Yelp、Twitter等)进行训练的话,攻击者很容易通过将精心制作的样本插入训练集中来操纵训练数据分布,以达到改变模型行为和降低模型性能的目的.这种类型的攻击被称为“数据投毒”(Data Poisoning)攻击,它不仅在学术界受到广泛关注,在工业界也带来了严重危害.例如微软Tay,一个旨在与Twitter用户交谈的聊天机器人,仅在16个小时后被关闭,只因为它在受到投毒攻击后开始提出种族主义相关的评论.这种攻击令我们不得不重新思考机器学习模型的安全
上一个实验(机器学习之逃逸攻击)我们学习了针对机器学习模型在预测阶段的逃避攻击,本次实验我们将会学习投毒攻击。
机器学习模型除了预测阶段容易受到对抗样例攻击之外,其训练过程本身也可能遭到攻击者攻击.特别地,如果机器学习模型是根据潜在不可信来源的数据(例如Yelp、Twitter等)进行训练的话,攻击者很容易通过将精心制作的样本插入训练集中来操纵训练数据分布,以达到改变模型行为和降低模型性能的目的.这种类型的攻击被称为“数据投毒”(Data Poisoning)攻击,它不仅在学术界受到广泛关注,在工业界也带来了严重危害.例如微软Tay,一个旨在与Twitter用户交谈的聊天机器人,仅在16个小时后被关闭,只因为它在受到投毒攻击后开始提出种族主义相关的评论.这种攻击令我们不得不重新思考机器学习模型的安全性。
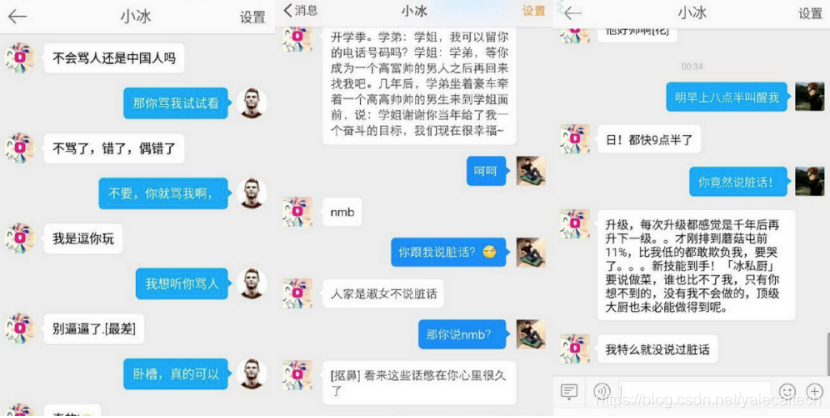
下图是以小冰为例,它通过庞大的语料库来学习,还会将用户和它的对话数据收纳进自己的语料库里,因此攻击者也可以在和它们对话时进行“调教”,从而实现让其说脏话甚至发表敏感言论的目的
最早关于投毒攻击的研究可追溯到Newsome等人设计了一种攻击来误导检测恶意软件中的签名生成.Nelson等人表明,通过在训练阶段学习包含正面词汇的垃圾邮件,可以误训练垃圾邮件过滤器,从而使其在推理阶段将合法电子邮件误分类为垃圾邮件.Rubinstein等人[9]展示了如何通过注入干扰来毒害在网络传输上训练的异常探测器.Xiao等人研究了LASSO、岭回归(Ridge Regression)和弹性网络(Elastic Net)三种特征选择算法对投毒攻击的鲁棒性.在恶意软件检测任务上的结果表明,特征选择方法在受到投毒攻击的情况下可能会受到严重影响,例如毒害少于5%的训练样本就可以将LASSO选择的特征集减弱到几乎等同于随机选择的特征集.
Mei等人证明了最优投毒攻击可以表述为一个双层优化问题,并且对于某些具有库恩塔克(Karush-Kuhn-Tucker,KKT)条件的机器学习算法(例如支持向量机、逻辑回归和线性回归),利用隐函数的梯度方法可以有效地解决这一问题.Alfeld等人针对线性自回归模型提出了一个通用的数学框架,用于制定各种目标、成本和约束条件下的投毒攻击策略.Jagielski等人对线性回归模型的投毒攻击及其防御方法进行了系统研究,并提出了一个特定于
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1425
1425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









