




安装版和解压版 区别
- 安装版:
安装方便,下一步------下一步就OK了,但重装系统更换环境又要重新来一遍,会特别麻烦 - 解压版(推荐):
这种方式(项目打包特别方便)能更深了解mysql的配置,以后遇到问题,也就可以自行解决了,我个人推荐解压版MySQL,最主要的是学会这一种方法,你会发现其他软件甚至是linux系统软件安装也一通百通了。
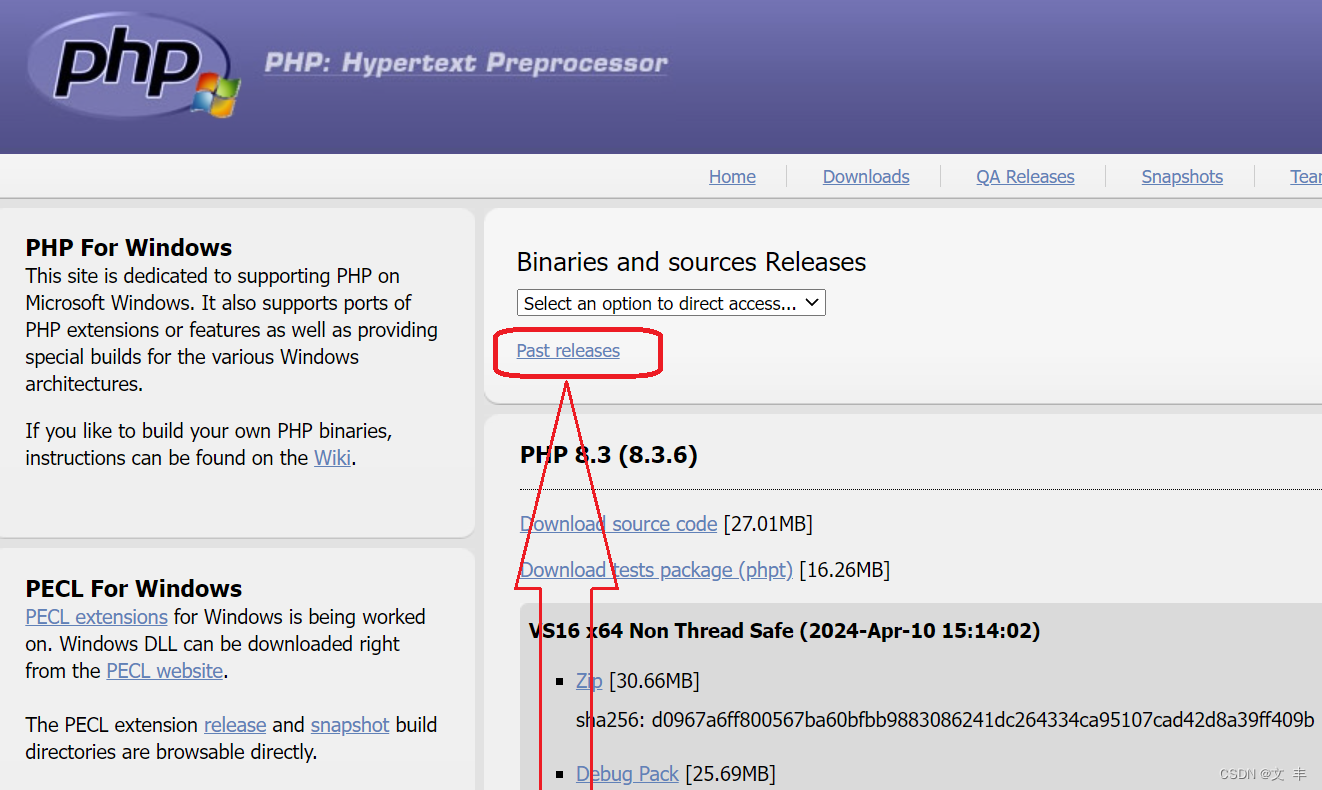
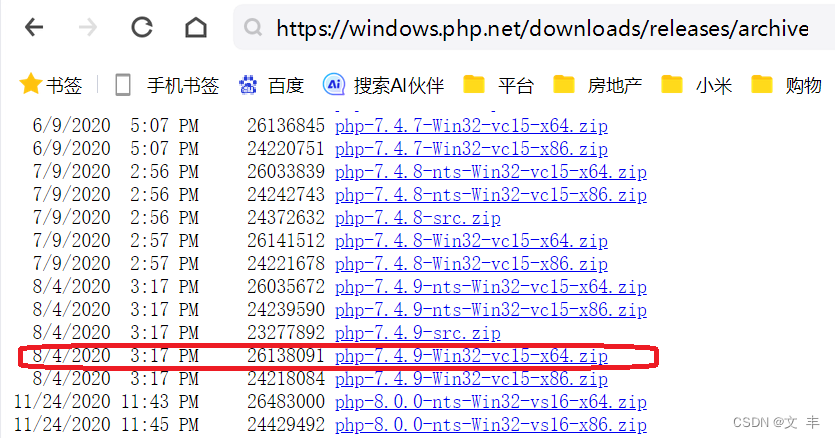
一、下载PHP
下载地址如下:
https://windows.php.net/download/
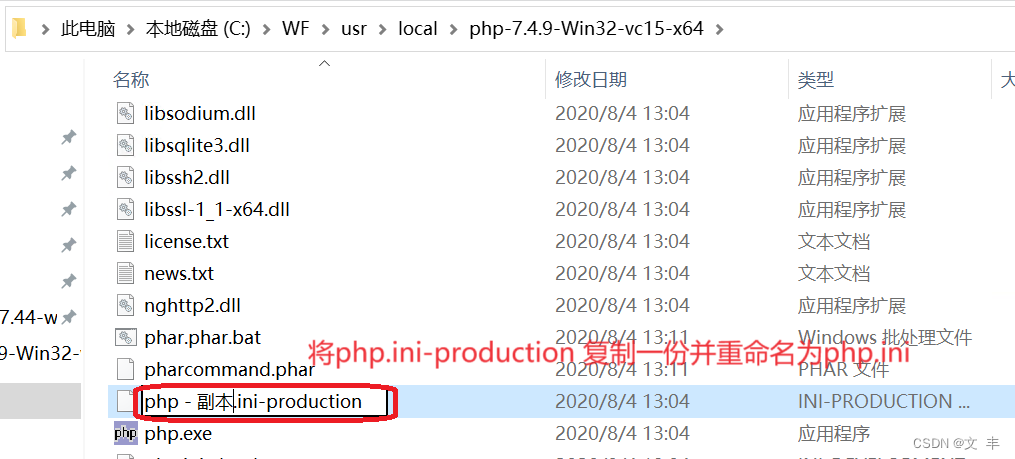
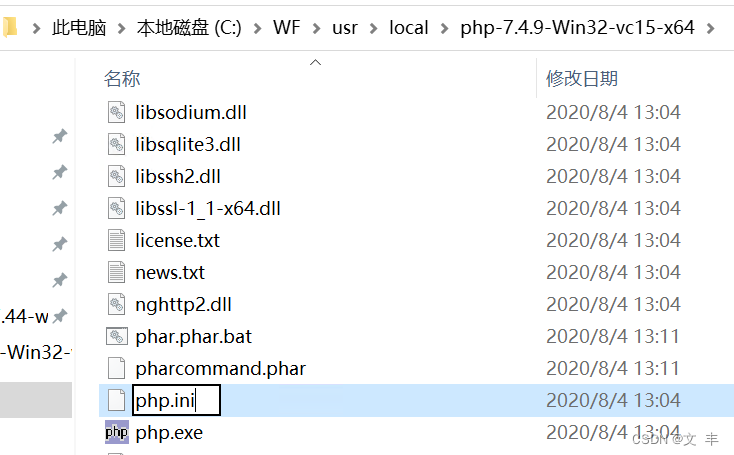
extension_dir = “./”
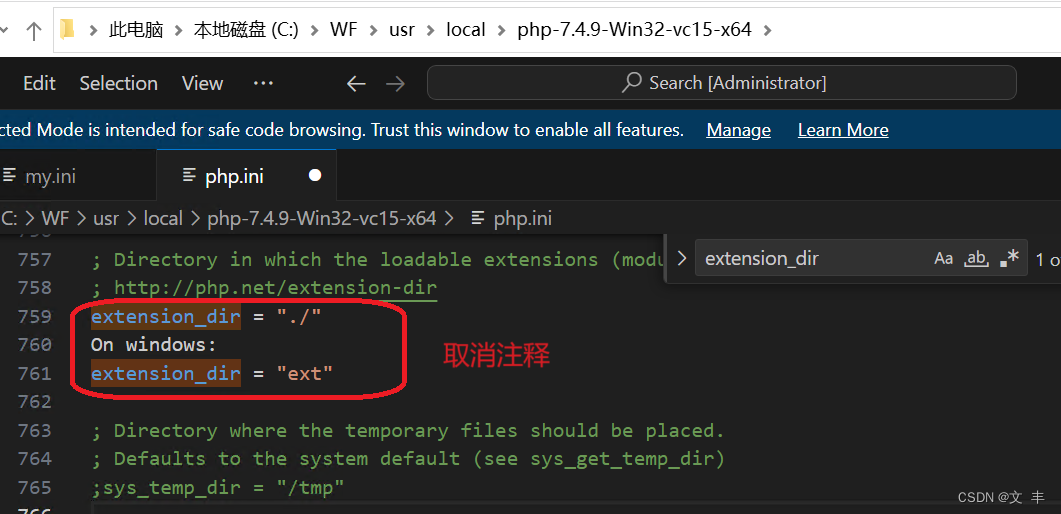
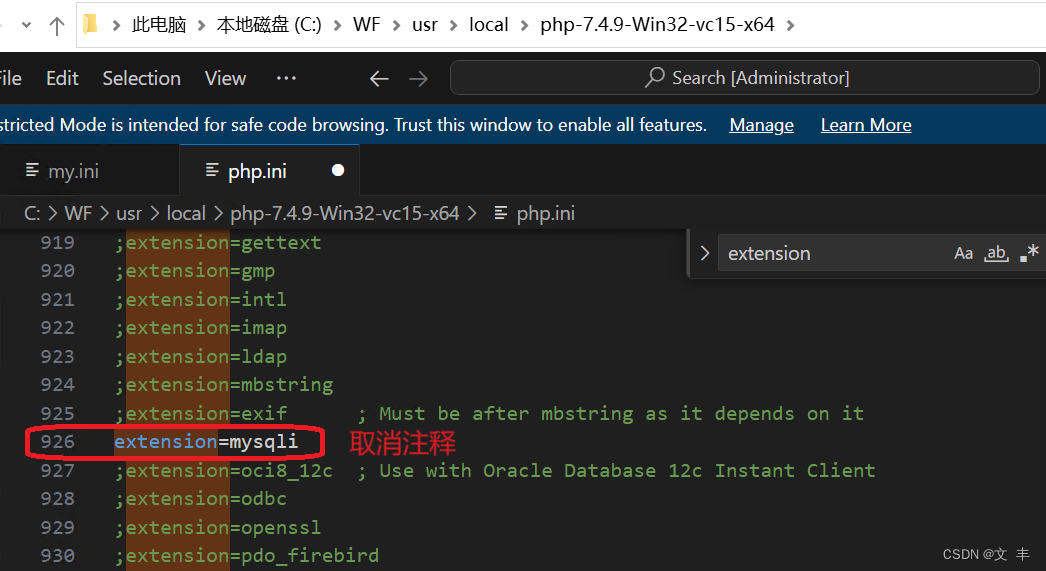
 本文讨论了安装版与解压版MySQL的区别,强调解压版的优势在于便于项目打包、深入了解配置和独立解决问题。作者推荐学习解压安装,指出这有助于掌握其他软件安装技巧。同时给出了PHP下载和设置扩展目录的示例。
本文讨论了安装版与解压版MySQL的区别,强调解压版的优势在于便于项目打包、深入了解配置和独立解决问题。作者推荐学习解压安装,指出这有助于掌握其他软件安装技巧。同时给出了PHP下载和设置扩展目录的示例。
安装版和解压版 区别
下载地址如下:
https://windows.php.net/download/
extension_dir = “./”

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





















 1674
1674





