 PCA详解:主成分分析法在数据降维与噪声减少中的应用
PCA详解:主成分分析法在数据降维与噪声减少中的应用





 主成分分析(PCA)是一种数据降维方法,通过对数据进行正则化和特征向量计算,找出数据的主要变异轴。PCA不仅简化数据,还可用于数据可视化、预处理和噪声过滤。它通过最大化投影的方差选择主特征向量,这些向量形成数据的新正交基,使得低维表示保留原始数据的方差信息。
主成分分析(PCA)是一种数据降维方法,通过对数据进行正则化和特征向量计算,找出数据的主要变异轴。PCA不仅简化数据,还可用于数据可视化、预处理和噪声过滤。它通过最大化投影的方差选择主特征向量,这些向量形成数据的新正交基,使得低维表示保留原始数据的方差信息。
前面我们讲了因子分析(factor analysis),其中在某个 kkk 维度子空间对 x∈Rnx ∈ R^nx∈Rn 进行近似建模,kkk 远小于 nnn,即 k≪nk ≪ nk≪n。具体来说,我们设想每个点 x(i)x^{(i)}x(i) 用如下方法创建:首先在 kkk 维度仿射空间(affine space) Λz+μ;z∈Rk{Λz + μ; z ∈ R^k}Λz+μ;z∈Rk 中生成某个 z(i)z^{(i)}z(i) ,然后增加 ΨΨΨ-协方差噪音(covariance noise)。因子分析(factor analysis)是基于一个概率模型(probabilistic model),然后参数估计(parameter estimation)使用了迭代期望最大化算法(iterative EM algorithm)。
在本章讲义中,我们要学习一种新的方法,主成分分析(Principal Components Analysis,缩写为 PCA),这个方法也是用来对数据近似(approximately)所处的子空间(subspace)进行判别(identify)。然而,主成分分析算法(PCA)会更加直接,只需要进行一种特征向量(eigenvector)计算(在 Matlab 里面可以通过 eig 函数轻松实现),并且不需要再去使用期望最大化(EM)算法。
假如我们有一个数据集 { x(i);i=1,...,m}\{x^{(i)}; i = 1, . . ., m\}{ x(i);i=1,...,m},其中包括了 mmm 种不同汽车的属性,例如最大速度(maximum speed),转弯半径(turn radius)等等。设其中每个 iii 都有 x(i)∈Rn,(n≪m)x^{(i)} ∈ R^n,(n ≪ m)x(i)∈Rn,(n≪m)。但对于两个不同的属性,例如 xix_ixi 和 xjx_jxj,对应着以英里每小时(mph)为单位的最高速度和以公里每小时(kph)为单位的最高速度。因此这两个属性应该基本是线性相关(linearly dependent)的,只在对 mph 和 kph 进行四舍五入时候会有引入一些微小差异。所以,这个数据实际上应该是近似处于一个 n−1n-1n−1 维度的子空间中的。我们如何自动检测和删除掉这一冗余(redundancy)呢?
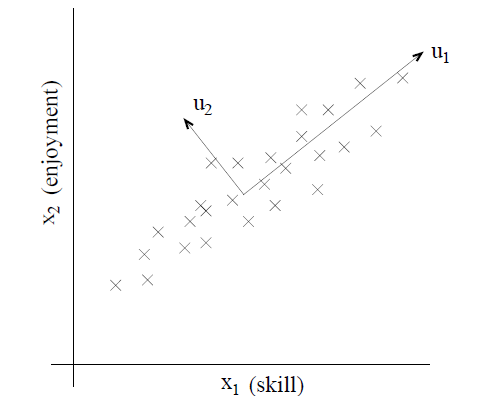
举一个不那么麻烦的例子,设想有一个数据集,其中包含的是对一个无线电遥控直升机(radio-controlled helicopters)飞行员协会进行调查得到的数据,其中的 x1(i)x_1^{ (i)}x1(i) 指代的是飞行员 iii 的飞行技能的度量,而 x2(i)x_2^{(i)}x2(i) 指代的是该飞行员对飞行的喜爱程度。无线电遥控直升机是很难操作的,只有那些非常投入,并且特别热爱飞行的学生,才能成为好的飞行员。所以,上面这两个属性 x1x_1x1 和 x2x_2x2 之间的相关性是非常强的。所以我们可以认为在数据中沿着对角线方向(也就是下图中的 u1u_1u1 方向)表征了一个人对飞行投入程度的内在“源动力(karma)”,只有少量的噪音脱离这个对角线方向。如下图所示,我们怎么来自动去计算出 u1u_1u1 的方向呢?
我们接下来很快就要讲到主成分分析算法(PCA algorithm)了。但在运行 PCA 之前,我们首先要进行一些预处理(pre-process),正则化(normalize)数据的均值(mean)和方差(variance),如下所示:
- Let μ=1m∑i=1mx(i)\mu=\frac1m\sum_{i=1}^mx^{(i)}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2411
2411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









