






1. 引言
我们知道,大模型在回答各种问题时具备强大的能力,但它也存在一些明显的局限,比如知识更新滞后、无法获取企业内部的专有信息,以及偶尔生成表面合理却实际错误的内容,这种现象通常被称为“幻觉”。
为了解决这些问题,RAG(Retrieval-Augmented Generation)应运而生。它结合了检索与生成的能力,通过从外部知识库中获取相关信息,再配合生成模型的语言能力,能够生成更加准确且有针对性的回答。
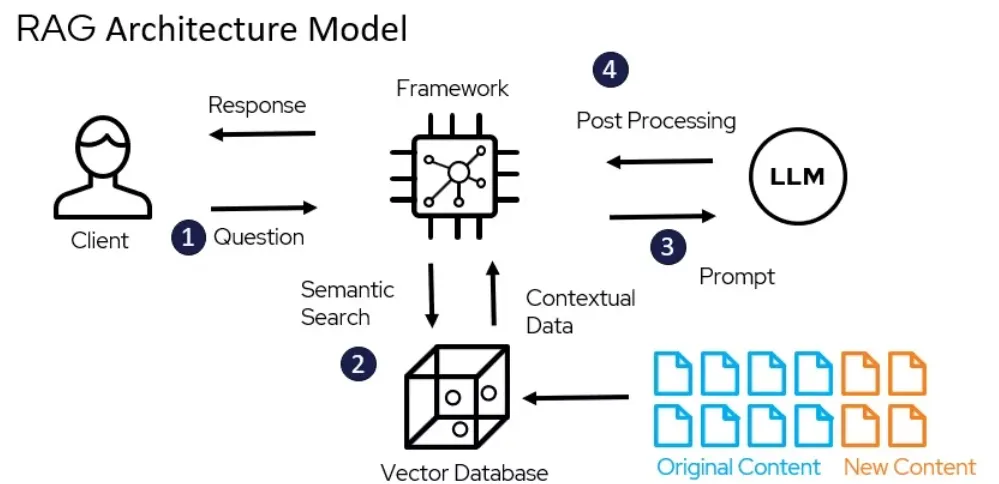
Image Source: https://medium.com/@bijit211987/advanced-rag-for-llms-slms-5bcc6fbba411
简单来说,RAG 就像一个能实时“查资料”的生成模型助手。不管是从企业的内部文档中快速找到答案,还是在大规模数据库中提取最新信息,它都能大显身手。而且,通过减少幻觉的可能性,它也让生成结果更值得信赖。
这篇文章里,我们会用一个简单的例子,带大家一步步实现一个 RAG 系统。通过这个过程,你会了解到如何用 LangChain 从零搭建一个系统,包括加载和处理文档、构建检索与生成模型,以及最终实现一个能回答具体问题的问答工具。
2. 环境准备
在开始构建 RAG 系统之前,确保安装了所有必需的库,同时检查是否有遗漏的模块。以下是所需依赖的完整列表及其安装方法。
2.1 安装必要依赖
根据你的代码,以下是需要安装的依赖库及其功能说明:
pip install langchain-milvus langchain-openai langchain-community python-dotenv
langchain-milvus:支持与 Milvus 向量数据库的交互。langchain-openai:提供与 OpenAI 模型(如嵌入生成和对话模型)的连接支持。langchain-community:扩展 LangChain 的社区工具,如文档加载器。python-dotenv: 加载和管理环境变量。
2.2 确保安装的库与代码匹配
为了避免导入错误,建议在安装完成后通过以下方式验证是否安装正确:
pip show langchain-milvus
pip show langchain-openai
pip show langchain-community
每个命令都会返回安装包的详细信息,例如版本号和安装路径。如果某个库没有安装,重新执行安装命令。
2.3 配置环境变量
为了让程序正常运行,需要配置 OpenAI 的 API 密钥和 Base URL,以及 Milvus 的连接信息。我们本例中,使用自己提前预装好的一个Milvus向量数据库。
创建 .env 文件,并写入以下内容:
OPENAI_API_KEY=your_openai_api_key
OPENAI_BASE_URL=https://x.x.x.x
如果需要连接 Milvus,还需要在代码中设置主机和端口,如下所示:
MILVUS_HOST="x.x.x.x"
MILVUS_PORT="19530"
2.4 加载环境变量
利用 dotenv 库加载 .env 文件,确保所有敏感信息安全地加载到程序中:
from dotenv import load_dotenv, find_dotenv
import os
# 加载 .env 文件
env_path = find_dotenv()
ifnot env_path:
raise EnvironmentError("No .env file found. Please create a .env file with the required API keys.")
load_dotenv(env_path)
# 获取 OpenAI API 配置
api_key = os.getenv("OPENAI_API_KEY")
base_url = os.getenv("OPENAI_BASE_URL")
ifnot api_key ornot base_url:
raise EnvironmentError("Missing API key or base URL in environment variables.")
2.5 配置日志系统
为了跟踪程序运行状态,我们需要设置一个功能强大的日志系统:
import logging
# 日志配置
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.StreamHandler(), # 输出到控制台
logging.FileHandler('log/langchain_rag_system.log') # 输出到文件
]
)
logger = logging.getLogger(__name__)
logger.info("Logging system initialized.")
2.6 验证依赖与环境
测试你的环境是否正确安装和配置,可以尝试运行以下代码:
from langchain_openai import OpenAIEmbeddings
# 测试 OpenAI 嵌入是否能正确生成
embeddings = OpenAIEmbeddings(
model="text-embedding-ada-002",
openai_api_key=api_key,
openai_api_base=base_url
)
try:
test_vector = embeddings.embed_query("This is a test query.")
logger.info("Embedding generation successful.")
except Exception as e:
logger.error(f"Embedding generation failed: {str(e)}")
raise
如果日志显示 Embedding generation successful,说明依赖和环境已经正确配置。接下来,我们将开始文档加载与预处理的部分。
3. 文档加载与预处理
在 RAG 系统中,文档加载与预处理是非常关键的一步。通过将原始文档转换为模型可用的结构化数据,我们可以为后续的检索和生成打下坚实基础。
3.1 文档加载
你的代码中使用了 PyMuPDFLoader 来加载 PDF 文档,这是一种高效的方式来处理 PDF 文件。以下是加载文档的具体代码:
from langchain_community.document_loaders import PyMuPDFLoader
# 加载 PDF 文档
logger.info("Starting document processing pipeline")
loader = PyMuPDFLoader("data/llama2.pdf") # 替换为你的文档路径
pages = loader.load_and_split()
logger.info(f"Loaded {len(pages)} pages from PDF")
关键点:
- PyMuPDFLoader 可以将 PDF 文档按页加载,方便后续分块处理。
- 每页的内容被提取为一个对象,包含
page_content和其他元信息。
3.2 文本分块
由于大语言模型对输入长度有限制(例如 GPT 模型通常限制在 4096 字符以内),需要将文档分块。这里使用了 RecursiveCharacterTextSplitter,一种递归分割器,能够根据字符长度和上下文分割文本。
代码如下:
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 初始化文本分割器
logger.info("Initializing text splitter")
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=300, # 每个块的最大字符数
chunk_overlap=100, # 每个块的重叠部分,确保上下文完整性
length_function=len, # 使用字符长度作为分割标准
add_start_index=True, # 为每个块添加起始索引
)
# 分割文档
texts = text_splitter.create_documents(
[page.page_content for page in pages[:4]] # 处理前4页内容
)
logger.info(f"Created {len(texts)} text chunks")
logger.debug(f"Average chunk size: {sum(len(t.page_content) for t in texts)/len(texts):.0f} characters")
关键点:
chunk_size和chunk_overlap:决定了分块的大小和相邻块的重叠部分。重叠可以确保检索到的上下文具有连贯性。add_start_index:为每个分块附加起始位置索引,便于后续检索结果的定位。
3.3 数据验证
在完成分块后,可以检查生成的分块数据是否合理。例如,以下代码可以验证分块的数量和每个块的大小:
# 打印前5个分块内容和大小
for i, chunk in enumerate(texts[:5]):
logger.info(f"Chunk {i + 1}: {chunk.page_content[:50]}... (Length: {len(chunk.page_content)})")
3.4 小结
到这里,我们已经成功完成了文档的加载与分块处理,生成了模型可用的小段文本。这些分块内容将在后续步骤中被转换为向量,用于检索和生成答案。
接下来,我们将进入向量存储的初始化和数据存储部分。
4. 向量存储初始化与数据存储
文档分块后,需要将这些分块转化为模型可用的向量表示,并存储在向量数据库中。向量存储是 RAG 系统的核心组件,它支持高效的相似度检索,帮助从文档中找到与用户问题相关的内容。
4.1 向量存储概述
向量存储将文本块通过嵌入模型转化为高维向量,并存储在数据库中。后续的检索通过计算用户问题与存储向量的相似度,返回最相关的文本块。在本例中,我们使用 Milvus 作为向量存储解决方案,配合 OpenAI 的嵌入模型 text-embedding-ada-002。
4.2 配置 Milvus 向量存储
以下代码初始化 Milvus 向量存储:
from langchain_milvus import Milvus
from langchain_openai import OpenAIEmbeddings
# Milvus 配置信息
MILVUS_HOST = "x.x.x.x"
MILVUS_PORT = "19530"
COLLECTION_NAME = "langchain_rag_demo"
EMBEDDING_DIM = 1536# 与 OpenAI 模型的嵌入维度匹配
# 嵌入模型初始化
embeddings = OpenAIEmbeddings(
model="text-embedding-ada-002",
openai_api_key=api_key,
openai_api_base=base_url
)
# 初始化 Milvus 向量存储
logger.info(f"Connecting to Milvus at {MILVUS_HOST}:{MILVUS_PORT}")
vector_store = Milvus(
embedding_function=embeddings,
collection_name=COLLECTION_NAME,
connection_args={"uri": f"tcp://{MILVUS_HOST}:{MILVUS_PORT}"},
drop_old=True, # 如果集合已存在,删除旧集合
auto_id=True # 自动生成唯一 ID
)
logger.info(f"Initialized Milvus vector store: {COLLECTION_NAME}")
关键点:
EMBEDDING_DIM:必须与嵌入模型的输出维度一致,例如text-embedding-ada-002的维度是 1536。drop_old=True:在每次运行脚本时删除旧集合,确保干净的存储环境。
4.3 文档向量化与存储
将分块的文本转化为向量并存储到 Milvus 中:
# 向量化并存储文档
logger.info("Starting document embedding and storage")
try:
vector_store.add_documents(texts)
logger.info("Successfully added documents to Milvus")
except Exception as e:
logger.error(f"Failed to add documents to Milvus: {str(e)}")
raise
注意事项:
- 嵌入生成的时间可能较长,具体取决于分块数量和嵌入模型的性能。
- 可以使用进度条库(如
tqdm)展示存储进度,提高用户体验。
4.4 验证存储内容
在数据存储完成后,可以通过以下代码检查存储内容是否正确:
# 检查存储内容
try:
stats = vector_store.get_stats()
logger.info(f"Milvus collection stats: {stats}")
except Exception as e:
logger.error(f"Error retrieving Milvus stats: {str(e)}")
raise
4.5 检索器配置
向量存储完成后,需要将其配置为检索器,支持后续的查询操作。以下代码实现检索器的配置:
# 配置检索器
logger.info("Configuring retriever with top-k=2")
retriever = vector_store.as_retriever(search_kwargs={"k": 2})
参数解释:
k:检索返回的结果数量,k=2表示每次查询返回两个最相关的文档块。
4.6 小结
这一部分完成了向量存储的初始化和数据存储。文档内容已经成功转化为向量并存储在 Milvus 中,同时配置了一个检索器,用于高效地找到相关内容。
接下来,我们将构建完整的 RAG 流程,包括使用检索器和生成模型实现问答功能。
5. 构建 RAG 流程
在完成向量存储和检索器配置后,我们可以将检索器和生成模型组合起来,构建完整的 RAG 流程。RAG 的核心流程包括以下几个部分:
- 接收用户问题。
- 检索相关文档。
- 使用生成模型根据检索到的文档生成答案。
以下是具体实现步骤:
5.1 定义 Prompt 模板
Prompt 模板定义了生成模型如何处理上下文和问题。在本例中,使用以下模板将检索到的文档和用户问题传递给生成模型:
from langchain.prompts import ChatPromptTemplate
# 定义 Prompt 模板
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
说明:
{context}:由检索器返回的相关文档内容填充。{question}:用户输入的问题。- 模板明确指示模型只能基于上下文回答问题,减少幻觉的可能性。
5.2 初始化生成模型
使用 OpenAI 的对话模型作为生成部分的核心:
from langchain_openai import ChatOpenAI
# 初始化 LLM(生成模型)
logger.info("Initializing LLM with model: gpt-4o-mini")
llm = ChatOpenAI(
temperature=0, # 确保回答的确定性
model="gpt-4o-mini", # 替换为所需的模型
openai_api_key=api_key,
openai_api_base=base_url
)
参数说明:
temperature=0:设置生成模型的输出更加确定,避免随机性带来的不确定答案。model:指定所使用的 OpenAI 模型,如gpt-4o-mini。
5.3 构建 RAG 链
将检索器、Prompt 模板和生成模型组合成完整的 RAG 链:
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
# 构建 RAG 流程
logger.info("Building RAG chain")
rag_chain = (
{"question": RunnablePassthrough(), "context": retriever}
| prompt
| llm
| StrOutputParser()
)
logger.info("RAG system initialization complete")
流程解析:
RunnablePassthrough():直接将用户输入问题传递到后续步骤。retriever:根据用户问题检索相关文档。prompt:将检索到的上下文和问题格式化为生成模型可用的输入。llm:使用生成模型生成答案。StrOutputParser():将生成模型的输出解析为文本。
5.4 处理单个查询
定义一个函数,用于处理单个用户查询并返回答案:
def process_query(question: str):
"""处理单个查询并返回答案"""
logger.info(f"Processing query: {question}")
try:
logger.info("Retrieving relevant documents")
response = rag_chain.invoke(question)
logger.info("Successfully generated response")
return response
except Exception as e:
logger.error(f"Error processing query: {str(e)}")
raise
5.5 交互式问答
为了让系统更加友好,可以实现一个交互式问答循环:
# 启动交互式问答
logger.info("Starting interactive chat loop")
whileTrue:
question = input("\nEnter your question (or press Enter to exit): ")
if question.strip() == "":
logger.info("User requested exit")
break
logger.info("Processing user question")
try:
response = process_query(question)
print(f"\nResponse: {response}\n")
logger.info("Successfully provided response to user")
except Exception as e:
logger.error(f"Error in chat loop: {str(e)}")
print(f"An error occurred: {str(e)}")
print("-" * 50)
5.6 单次测试(可选)
如果不需要交互式问答,可以直接测试单个问题:
# 测试单个问题
question = "Llama 2 有多少参数?"
response = rag_chain.invoke(question)
print(f"\nQuestion: {question}")
print(f"Response: {response}")
5.7 小结
这一部分详细构建了 RAG 系统的主要流程:
- 使用 Prompt 模板组织上下文和问题。
- 配置生成模型,结合检索器和向量存储实现问答。
- 构建一个完整的 RAG 流程链,支持交互式问答。
到这里,我们的 RAG 系统已经能够处理用户问题并生成回答。下面是我们给出的一个运行输出。
2025-01-06 21:26:24,376 - INFO - Environment variables loaded successfully
2025-01-06 21:26:24,377 - INFO - Starting document processing pipeline
2025-01-06 21:26:24,377 - INFO - Loading PDF from data/llama2.pdf
2025-01-06 21:26:24,599 - INFO - Loaded 5 pages from PDF
2025-01-06 21:26:24,599 - INFO - Initializing text splitter
2025-01-06 21:26:24,600 - INFO - Created 53 text chunks
2025-01-06 21:26:24,600 - INFO - Attempting to connect to Milvus
2025-01-06 21:26:26,612 - INFO - Initializing Milvus vector store: langchain_rag_demo
2025-01-06 21:26:26,613 - INFO - Connecting to Milvus
2025-01-06 21:26:26,749 - INFO - Starting document embedding and storage
2025-01-06 21:26:26,750 - INFO - Adding documents to Milvus...
2025-01-06 21:26:51,700 - INFO - HTTP Request: POST embeddings "HTTP/1.1 200 OK"
2025-01-06 21:26:52,791 - INFO - Successfully added documents to Milvus
2025-01-06 21:26:52,792 - INFO - Configuring retriever with top-k=2
2025-01-06 21:26:52,804 - INFO - Initializing RAG chain components
2025-01-06 21:26:52,804 - INFO - Initializing LLM with model: gpt-4o-mini
2025-01-06 21:26:54,789 - INFO - Building RAG chain
2025-01-06 21:26:54,790 - INFO - RAG system initialization complete
2025-01-06 21:26:54,790 - INFO - Starting interactive chat loop
Enter your question (or press Enter to exit): llama 2 有多少参数
2025-01-06 21:27:33,374 - INFO - Processing user question
2025-01-06 21:27:33,375 - INFO - Processing query: llama 2 有多少参数
2025-01-06 21:27:33,375 - INFO - Retrieving relevant documents
2025-01-06 21:27:36,816 - INFO - HTTP Request: POST embeddings "HTTP/1.1 200 OK"
2025-01-06 21:27:40,900 - INFO - HTTP Request: POST chat/completions "HTTP/1.1 200 OK"
2025-01-06 21:27:40,928 - INFO - Successfully generated response
Response: Llama 2 有 7B、13B 和 70B 三种参数规模。
2025-01-06 21:27:40,930 - INFO - Successfully provided response to user
--------------------------------------------------
Enter your question (or press Enter to exit): 最大的模型是?
2025-01-06 21:27:55,336 - INFO - Processing user question
2025-01-06 21:27:55,336 - INFO - Processing query: 最大的模型是?
2025-01-06 21:27:55,336 - INFO - Retrieving relevant documents
2025-01-06 21:28:00,916 - INFO - HTTP Request: POST embeddings "HTTP/1.1 200 OK"
2025-01-06 21:28:04,798 - INFO - HTTP Request: POST chat/completions "HTTP/1.1 200 OK"
2025-01-06 21:28:04,801 - INFO - Successfully generated response
Response: 最大的模型是70亿参数的模型。
2025-01-06 21:28:04,813 - INFO - Successfully provided response to user
--------------------------------------------------
Enter your question (or press Enter to exit): 模型开源吗?
2025-01-06 21:28:13,614 - INFO - Processing user question
2025-01-06 21:28:13,616 - INFO - Processing query: 模型开源吗?
2025-01-06 21:28:13,617 - INFO - Retrieving relevant documents
2025-01-06 21:28:17,049 - INFO - HTTP Request: POST embeddings "HTTP/1.1 200 OK"
2025-01-06 21:28:20,860 - INFO - HTTP Request: POST chat/completions "HTTP/1.1 200 OK"
2025-01-06 21:28:20,861 - INFO - Successfully generated response
Response: 是的,Llama 2-Chat模型对公众开放,供研究和商业使用。
2025-01-06 21:28:20,864 - INFO - Successfully provided response to user
--------------------------------------------------
Enter your question (or press Enter to exit):
2025-01-06 21:28:30,464 - INFO - User requested exit
2025-01-06 21:28:30,464 - INFO - Chat session ended
我们看到模型正确回答了我们所提问的问题。
7. 总结
本文通过一个完整的实例,带领大家了解如何使用 LangChain 构建一个检索增强生成(RAG)系统。从环境配置到文档加载,从向量存储初始化到构建完整的问答链条,我们一步步搭建了一个灵活且高效的系统。
整个过程中,我们覆盖了以下关键内容:
- 环境准备:如何安装依赖、配置环境变量,并搭建可靠的日志系统。
- 文档加载与预处理:通过分块策略,让大文档内容能够高效适配生成模型。
- 向量存储与检索:借助 Milvus 和 OpenAI 嵌入模型,快速实现文本的向量化存储和相似度检索。
- 问答流程构建:结合检索器和生成模型,通过 Prompt 模板构建完整的 RAG 流程。
RAG 系统的核心在于将生成模型与外部知识库无缝结合,从而弥补生成模型知识更新不及时和存在幻觉的问题。通过合理的优化和扩展,这一架构不仅适用于小型实验,也能够胜任大规模生产场景,例如企业内部知识管理系统、智能客服平台、或高效的问答工具。
希望本文的内容能帮助你快速上手 RAG 系统的开发,并为你的实际应用提供思路和灵感。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。 

四、100+套大模型面试题库

五、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 52
52

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









