







大模型必知基础知识:13-大语言模型性能评估方法
总目录
- 大模型必知基础知识:1、Transformer架构-QKV自注意力机制
- 大模型必知基础知识:2、Transformer架构-大模型是怎么学习到知识的?
- 大模型必知基础知识:3、Transformer架构-词嵌入原理详解
- 大模型必知基础知识:4、Transformer架构-多头注意力机制原理详解
- 大模型必知基础知识:5、Transformer架构-前馈神经网络(FFN)原理详解
- 大模型必知基础知识:6、Transformer架构-提示词工程调优
- 大模型必知基础知识:7、Transformer架构-大模型微调作用和原理详解
- 大模型必知基础知识:8、Transformer架构-如何理解学习率 Learning Rate
- 大模型必知基础知识:9、MOE多专家大模型底层原理详解
- 大模型必知基础知识:10、大语言模型与多模态融合架构原理详解
- 大模型必知基础知识:11、大模型知识蒸馏原理和过程详解
- 大模型必知基础知识:12、大语言模型能力评估体系
- 大模型必知基础知识:13、大语言模型性能评估方法
目录
- 引言
- 评估指标体系
- 2.1 分类与回归任务的评估指标
- 2.2 语言模型的评估指标
- 2.3 文本生成任务的评估指标
- 评估方法论
- 评估方法的选择与应用
- 总结
引言
在建立了大语言模型的评估体系和数据集之后,接下来的核心问题是如何科学地评估模型的实际表现。这不仅包括选择哪些指标来衡量模型的能力,还涉及评估的具体方式和实施过程。换句话说,评估方法就是要系统地回答"大模型好不好、哪里好、怎么知道好"这三个关键问题。
在传统的自然语言处理时代,算法通常只针对某一个具体任务设计,比如情感分析、命名实体识别或机器翻译等。因此评估方法也相对单一,往往一个指标就能较好地反映模型的性能。但随着大语言模型的出现,任务类型呈现爆发式增长,不同任务之间的评估方式差异也越来越大。
例如,HELM评估体系整合了自然语言处理领域的多个评估数据集,覆盖了42类不同的任务场景,却需要使用59种不同的评估指标来全面衡量模型表现。这充分说明了大模型评估的复杂性已经达到了前所未有的程度。
评估指标体系
分类与回归任务的评估指标
分类任务评估
分类任务是指让模型把输入内容归入预定义的不同类别中。比如判断一句用户评论是"正面"还是"负面",或者把一篇新闻文章分类为"体育"、“经济”、“科技”、"汽车"等类型。这类任务在实际应用中非常常见,是大语言模型的基础能力之一。
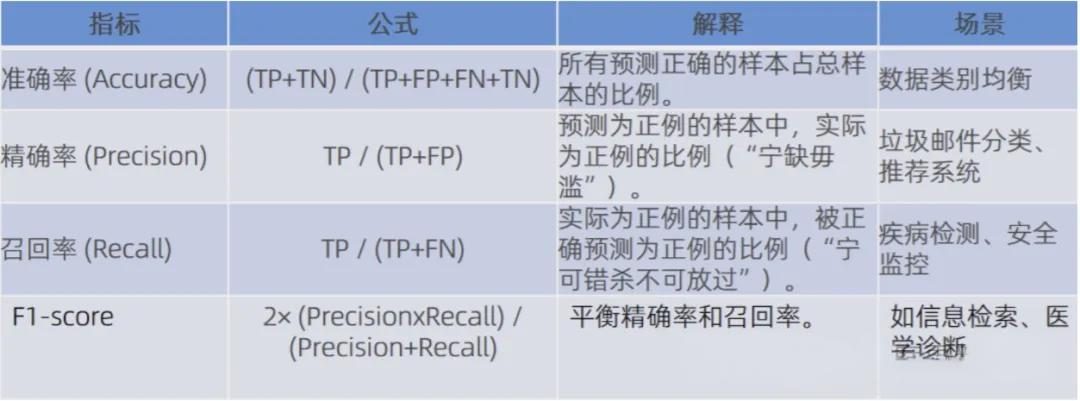
衡量分类任务的常用指标包括以下几种:
准确率 (Accuracy)
准确率是最直观的评估指标,表示预测正确的样本数占总样本数的比例。其计算公式为:
Accuracy = T P + T N T P + F P + F N + T N \text{Accuracy} = \frac{TP + TN}{TP + FP + FN + TN} Accuracy=TP+FP+FN+TNTP+TN
其中:
- TP (True Positive): 真正例,预测为正且实际为正
- TN (True Negative): 真负例,预测为负且实际为负
- FP (False Positive): 假正例,预测为正但实际为负
- FN (False Negative): 假负例,预测为负但实际为正
准确率适合用于数据类别均衡的场景,但在类别不平衡时可能会产生误导。
精确率 (Precision)
精确率关注的是在所有被预测为正例的样本中,真正为正例的比例。其计算公式为:
Precision = T P T P + F P \text{Precision} = \frac{TP}{TP + FP} Precision=TP+FPTP
精确率在垃圾邮件分类、推荐系统等场景中特别重要,因为我们希望推荐给用户的内容准确度高,宁可少推荐也不能推荐错误。
召回率 (Recall)
召回率衡量的是在所有真实为正例的样本中,有多少被成功预测出来。其计算公式为:
Recall = T P T P + F N \text{Recall} = \frac{TP}{TP + FN} Recall=TP+FNTP
召回率在医疗检测、安全监控等场景中至关重要,因为这些场景中漏掉一个正例可能造成严重后果,我们宁可错判也不能放过。
F1分数 (F1-score)
F1分数是精确率和召回率的调和平均数,综合考虑了两个指标的平衡。其计算公式为:
F1 = 2 × Precision × Recall Precision + Recall \text{F1} = \frac{2 \times \text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}} F1=Precision+Recall2×Precision×Recall
F1分数在信息检索、医疗诊断等需要平衡精确率和召回率的场景中被广泛使用。
这些指标在不同应用场景中各有侧重。例如,数据类别均衡的场景适合用准确率,垃圾邮件分类、推荐系统更看重精确率,而医疗检测、安全监控则更关注召回率。在需要综合考虑的情况下,F1分数是一个很好的选择。
回归任务评估
回归任务是预测一个连续的数值结果,而不是离散的类别。比如作文自动打分系统需要给出1到10分的连续评分,或者对用户评论进行情感强度评分。
常见的回归任务评估指标包括:
平均绝对误差 (MAE, Mean Absolute Error)
MAE计算预测值与真实值之间绝对差值的平均值:
MAE = 1 n ∑ i = 1 n ∣ y i − y ^ i ∣ \text{MAE} = \frac{1}{n}\sum_{i=1}^{n}|y_i - \hat{y}_i| MAE=n1i=1∑n∣yi−y^i∣
MAE的优点是计算简单,易于理解,单位与原始数据一致。
均方误差 (MSE, Mean Squared Error)
MSE计算预测值与真实值之间差值平方的平均值:
MSE = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 \text{MSE} = \frac{1}{n}\sum_{i=1}^{n}(y_i - \hat{y}_i)^2 MSE=n1i=1∑n(yi−y^i)2
由于采用平方计算,MSE会更关注偏差较大的样本,对异常值更敏感。
均方根误差 (RMSE, Root Mean Squared Error)
RMSE是MSE的平方根:
RMSE = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 \text{RMSE} = \sqrt{\frac{1}{n}\sum_{i=1}^{n}(y_i - \hat{y}_i)^2} RMSE=n1i=1∑n(yi−y^i)2
RMSE的单位与原始数据一致,同时保留了MSE对大误差敏感的特点。
平均绝对百分比误差 (MAPE, Mean Absolute Percentage Error)
MAPE计算相对误差的平均值:
MAPE = 100 % n ∑ i = 1 n ∣ y i − y ^ i y i ∣ \text{MAPE} = \frac{100\%}{n}\sum_{i=1}^{n}\left|\frac{y_i - \hat{y}_i}{y_i}\right| MAPE=n100%i=1∑n yiyi−y^i
MAPE特别适合带比例意义的场景,可以直观地反映预测的相对准确度。
这些回归指标在机器学习中是非常经典的评估方法,为模型性能评估提供了坚实的数学基础。
语言模型的评估指标
语言模型的核心任务是预测序列中的下一个词或token。评估语言模型是否真正"理解语言",最常用的两种指标是交叉熵和困惑度。
交叉熵 (Cross-Entropy)
交叉熵衡量的是模型预测的概率分布与真实数据分布之间的差距。对于语言模型,交叉熵的计算公式为:
H ( p , q ) = − ∑ x p ( x ) log q ( x ) H(p, q) = -\sum_{x}p(x)\log q(x) H(p,q)=−x∑p(x)logq(x)
其中p(x)是真实分布,q(x)是模型预测的分布。交叉熵越小,说明模型的预测越接近真实情况。
困惑度 (Perplexity)
困惑度是交叉熵的指数形式,可以理解为模型在预测时的"不确定程度":
Perplexity = 2 H ( p , q ) \text{Perplexity} = 2^{H(p,q)} Perplexity=2H(p,q)
或者在实际计算中:
Perplexity = exp ( − 1 N ∑ i = 1 N log P ( w i ∣ w 1 , . . . , w i − 1 ) ) \text{Perplexity} = \exp\left(-\frac{1}{N}\sum_{i=1}^{N}\log P(w_i|w_1,...,w_{i-1})\right) Perplexity=exp(−N1i=1∑NlogP(wi∣w1,...,wi−1))
举个通俗的比喻来理解困惑度:一个困惑度低的模型,就像一个"心里有数"的人,对下一个词的预测很有把握;而困惑度高的模型,则常常"猜不准",显得很困惑,需要在更多的候选词中犹豫不决。
一般来说,交叉熵和困惑度越小,说明模型的语言理解能力越强,对语言结构的把握越准确。这两个指标在预训练语言模型的训练过程中被广泛用作优化目标和评估标准。
文本生成任务的评估指标
当模型需要生成一段完整的文本时,比如机器翻译或自动摘要生成,评估就变得更加复杂。这是因为语言的表达方式具有高度的多样性,同一个意思可以有无数种不同的表达方式,很难用简单的对错来判断。
机器翻译评估:BLEU指标
BLEU (Bilingual Evaluation Understudy) 是专门用来衡量机器翻译质量的自动评估指标。它通过计算生成译文与参考译文之间n-gram的重叠程度来评估翻译质量。
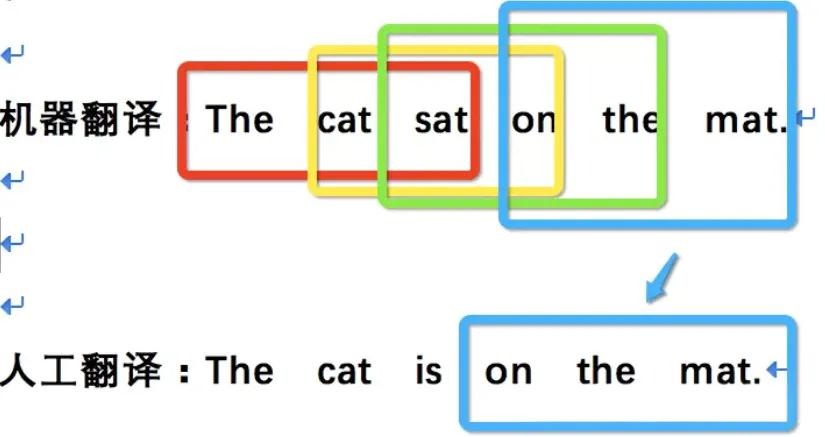
BLEU的核心思想是计算生成译文中有多少词组 (n-gram) 出现在标准译文中。具体计算包括以下几个步骤:
- 计算不同长度n-gram的精确率
- 对各个n-gram精确率取几何平均
- 引入长度惩罚因子,防止生成过短的译文
BLEU的计算公式为:
BLEU = B P × exp ( ∑ n = 1 N w n log p n ) \text{BLEU} = BP \times \exp\left(\sum_{n=1}^{N}w_n\log p_n\right) BLEU=BP×exp(n=1∑Nwnlogpn)
其中:
- p n p_n pn 是n-gram的精确率
- w n w_n wn 是权重系数(通常均匀分配)
- BP是长度惩罚因子: B P = { 1 if c > r e 1 − r / c if c ≤ r BP = \begin{cases}1 & \text{if } c > r \\ e^{1-r/c} & \text{if } c \leq r\end{cases} BP={1e1−r/cif c>rif c≤r
- c是候选译文长度,r是参考译文长度
BLEU分数范围是0到1,越接近1表示翻译质量越好。简单来说,BLEU更关注"精确率",即机器翻译输出的内容中,有多少是与参考译文匹配的。
例如,对于句子"The cat sat on the mat"的翻译,BLEU会检查机器翻译中的1-gram(单词)、2-gram(词对)、3-gram(三词组)等是否出现在参考译文中,通过这种方式量化翻译的准确性。
摘要生成评估:ROUGE指标
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) 是用于评估自动摘要质量的指标集合。与BLEU类似,但ROUGE更关注"召回率",即标准摘要中的信息有多少被机器生成的摘要覆盖。
ROUGE包含多个变体,最常用的有:
ROUGE-N
ROUGE-N统计n-gram的召回率:
ROUGE-N = ∑ S ∈ RefSum ∑ gram n ∈ S Count match ( gram n ) ∑ S ∈ RefSum ∑ gram n ∈ S Count ( gram n ) \text{ROUGE-N} = \frac{\sum_{S \in \text{RefSum}}\sum_{\text{gram}_n \in S}\text{Count}_{\text{match}}(\text{gram}_n)}{\sum_{S \in \text{RefSum}}\sum_{\text{gram}_n \in S}\text{Count}(\text{gram}_n)} ROUGE-N=∑S∈RefSum∑gramn∈SCount(gramn)∑S∈RefSum∑gramn∈SCountmatch(gramn)
其中最常用的是ROUGE-1(单字匹配)和ROUGE-2(词对匹配)。
ROUGE-L
ROUGE-L基于最长公共子序列 (LCS, Longest Common Subsequence),能够捕捉句子层面的相似度,而不要求词语必须连续出现:
ROUGE-L = ( 1 + β 2 ) R l c s P l c s R l c s + β 2 P l c s \text{ROUGE-L} = \frac{(1+\beta^2)R_{lcs}P_{lcs}}{R_{lcs} + \beta^2P_{lcs}} ROUGE-L=Rlcs+β2Plcs(1+β2)RlcsPlcs
其中 R l c s R_{lcs} Rlcs是基于LCS的召回率, P l c s P_{lcs} Plcs是基于LCS的精确率。
举个具体例子来说明ROUGE的工作原理:
假设参考摘要是:“there is a dog in the garden”
机器生成摘要是:“a dog is in the garden”
ROUGE指标会计算两者之间匹配的词和词组比例。可以看到,虽然词序略有不同,但主要内容都被覆盖了,因此会得到较高的ROUGE分数。
这些自动评估指标虽然不能完全替代人工评估,但在大规模实验和模型迭代过程中提供了快速、客观、可重复的评估方式,对模型开发具有重要价值。
评估方法
在确定了评估指标之后,我们还需要选择合适的评估方法来实施评估过程。不同的评估方法各有优劣,适用于不同的场景和需求。
人工评估方法
人工评估是让真实的人类评估者对模型输出进行打分和判断。虽然听起来简单直接,但这实际上是目前最接近真实使用体验、最能反映模型实际效果的评估方式。
人工评估的优势
人工评估具有以下明显优势:
贴近人类直觉:人类评估者能够从多个维度判断文本质量,包括语言是否流畅自然、逻辑是否严密合理、内容是否准确深刻、表达是否得体恰当等。这些微妙的判断往往是自动化指标难以捕捉的。
高度灵活:人工评估几乎适用于任何类型的任务,无论是创意写作、开放对话还是专业领域的内容生成,人类评估者都能给出有价值的反馈。
提供定性反馈:除了量化评分,人类评估者还能提供详细的文字反馈,指出模型的具体问题和改进方向,这对模型优化具有重要指导意义。
人工评估的局限性
然而,人工评估也存在一些明显的局限:
主观性强:不同评估者可能因为个人背景、知识水平、审美偏好等因素,对同一输出给出不同的评价。这种主观性可能影响评估结果的一致性。
成本高昂:人工评估需要支付评估者报酬,尤其是专家评估,费用可能非常高昂。
耗时较长:人工评估的速度远慢于自动化评估,在需要快速迭代的研发阶段可能成为瓶颈。
规模受限:由于时间和成本限制,人工评估往往只能在有限的样本上进行,可能无法全面反映模型在不同场景下的表现。
人工评估的关键要素
为了使人工评估更加科学有效,需要关注以下几个关键要素:
评估者的选择
不同类型的评估者适合不同的评估场景:
专家评估由领域专家完成,能够对专业内容的准确性、深度和专业性做出权威判断。例如医疗文本生成需要医学专家评估,法律文档生成需要法律专家评估。但专家评估成本高,获取专家资源也较为困难。
众包评估通过在线众包平台(如Amazon Mechanical Turk)让大量普通人快速参与评估。这种方式成本相对较低,速度快,样本量大,适合评估一般性的语言质量和可读性。但需要设计清晰的评估指南和质量控制机制。
用户评估由系统的真实使用者直接打分,最能反映实际应用效果和用户满意度。这在产品迭代中特别有价值,但需要注意用户样本的代表性。
评分方式设计
常用的评分方式是李克特量表 (Likert Scale),通常采用5分制或7分制:
- 1分:非常差
- 2分:较差
- 3分:一般
- 4分:较好
- 5分:非常好
评分可以针对多个维度分别进行,例如:
- 流畅性:语言是否通顺自然
- 准确性:内容是否正确无误
- 相关性:是否切题,是否回答了问题
- 完整性:信息是否完整充分
- 创造性:内容是否有新意和深度
上下文信息的提供
在某些评估场景中,需要为评估者提供必要的上下文信息,如任务指令、参考答案、背景资料等。这有助于评估者更准确地判断输出质量。例如,在评估摘要质量时,需要提供原文;在评估对话系统时,需要提供对话历史。
绝对评估与相对评估
绝对评估是让评估者单独对某个系统的输出进行评分,如"这段回答的质量如何?"。这种方式能够获得每个系统的独立评分。
相对评估是让评估者比较不同系统的输出,如"系统A和系统B哪个回答更好?"。相对评估通常比绝对评估更容易操作,评估者一致性也更高,因为比较判断比绝对判断更符合人类的认知习惯。
理由说明的要求
在一些深度评估中,会要求评估者不仅给出评分,还要说明评分理由。例如,为什么给4分而不是5分?模型输出存在哪些具体问题?这种定性反馈虽然增加了评估负担,但能够帮助研发人员深入理解模型的优势和不足,指导后续优化方向。
评估结果的整合与一致性检验
由于单个评估者的主观性,通常需要多个评估者对同一样本进行评估,然后整合结果。
评分整合方法
平均分法 (MOS, Mean Opinion Score):取所有评估者评分的算术平均值。这是最常用的方法,简单直观。
中位数法:取所有评分的中位数。这种方法对异常值不敏感,当存在个别评估者打分异常时,中位数能提供更稳健的结果。
多数表决法:统计每个评分出现的次数,选择出现最多的评分作为最终结果。这种方法常用于二元判断(好/坏)或排序任务。
加权平均法:根据评估者的专业程度或历史表现给予不同权重。例如,专家的评分权重可以高于普通评估者。
一致性检验
评估者之间的一致性是评估质量的重要指标。如果评估者之间分歧很大,说明任务定义不够清晰,或者评估标准存在歧义,需要改进评估流程。
一致性百分比:计算评估者之间评分完全一致的样本比例。这是最简单的一致性度量方法。
Cohen’s Kappa系数:用于衡量两个评估者之间的一致性,考虑了随机一致的可能性。Kappa值在-1到1之间,通常认为:
- Kappa < 0.4:一致性较差
- 0.4 ≤ Kappa < 0.6:一致性一般
- 0.6 ≤ Kappa < 0.8:一致性良好
- Kappa ≥ 0.8:一致性优秀
Fleiss’ Kappa系数:Cohen’s Kappa的扩展版本,用于三个或更多评估者的一致性检验。
相关系数:计算不同评估者评分之间的皮尔逊相关系数或斯皮尔曼等级相关系数,衡量评分趋势的一致性。
通过这些一致性指标,我们可以判断评估流程是否可靠,是否需要改进评估指南或增加评估者培训。
大语言模型评估方法
人工评估虽然准确可靠,但速度慢、成本高的问题在大规模评估中尤为突出。随着大语言模型能力的提升,研究者开始思考一个有趣的问题:“既然大模型已经具备了强大的理解和判断能力,能不能让模型自己来评估?”
于是,大语言模型评估 (LLM Evaluation) 应运而生。
LLM评估的基本原理
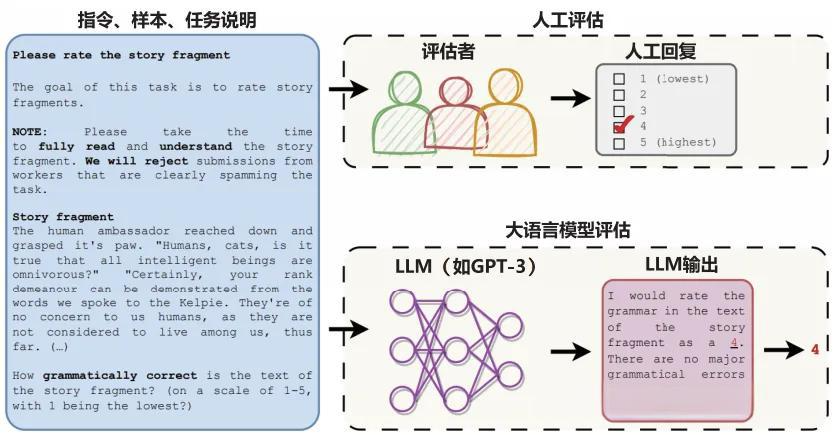
大语言模型评估的核心思想是让一个强大的模型(如GPT-4、Claude等)充当"评审员"的角色。评估流程通常包括以下步骤:
- 设计评估提示词:编写详细的评估指令,说明评估维度、评分标准和输出格式
- 输入待评估内容:将待评估的模型输出、相关上下文等信息提供给评估模型
- 获取评估结果:评估模型根据指令给出评分和评估理由
- 结果分析:收集和分析评估结果,形成最终评估报告
例如,我们可以设计如下的评估提示词:
"请你作为一个专业的文本质量评估专家,从以下五个维度对给定的故事片段进行评分(1-5分):
- 语法正确性:是否存在语法错误
- 语言流畅性:表达是否自然流畅
- 逻辑连贯性:情节是否合理连贯
- 创意性:内容是否有新意
- 吸引力:是否能吸引读者继续阅读
请为每个维度给出具体分数,并简要说明评分理由。最后给出总体评价。"
LLM评估的优势
LLM评估相比人工评估具有明显的优势:
效率高:可以快速处理大量样本,不受人力资源限制,特别适合需要评估大规模数据集的场景。
成本低:虽然调用大模型API需要费用,但相比人工评估,成本通常低得多,尤其是在大规模评估时。
一致性好:同一个模型在相同提示词下的评估标准是一致的,不会出现人工评估中不同评估者标准不一的问题。
可扩展性强:可以轻松调整评估维度和标准,快速适应不同的评估需求。
支持复杂评估:可以设计复杂的评估逻辑,如多轮对比、多维度综合评估等。
LLM评估的有效性
多项研究表明,LLM评估的结果与人工评估具有高度的一致性。特别是在以下场景中,LLM评估表现优异:
- 开放域对话评估:判断对话是否自然、相关、有趣
- 创意写作评估:评估故事、文章的质量和创意性
- 摘要质量评估:判断摘要是否准确、完整、简洁
- 翻译质量评估:评估译文的准确性和流畅性
研究发现,在这些没有标准答案的主观评估任务中,GPT-4等先进模型的评估结果与人类专家的相关性可以达到0.8以上,显示出强大的评估能力。
LLM评估的局限与注意事项
尽管LLM评估具有诸多优势,但也存在一些需要注意的问题:
位置偏见:研究发现,评估模型在比较多个输出时,可能倾向于给排在前面或后面的选项更高的分数。需要通过随机打乱顺序等方法来缓解。
长度偏见:模型可能倾向于给更长的输出更高的分数,即使长度不等于质量。
自我偏见:如果用同一个模型评估自己的输出,可能会给出偏高的评分。因此建议使用不同的模型进行交叉评估。
评估能力局限:即使是最强大的模型,在某些需要专业知识的领域(如医学、法律)的评估准确性可能不如人类专家。
提示词敏感性:评估结果可能受到提示词表述方式的影响,需要仔细设计和测试提示词。
为了提高LLM评估的可靠性,实践中通常采用以下策略:
- 使用多个不同的大模型进行评估,取平均结果
- 设计详细清晰的评估提示词,包含具体的评分标准和示例
- 在关键样本上进行人工验证,检查LLM评估的准确性
- 结合自动化指标和LLM评估,形成多层次的评估体系
对比评估方法
在许多实际场景中,我们关心的不是某个模型的绝对性能如何,而是想要知道:"A模型和B模型相比,哪个更强?新版本比旧版本有提升吗?"这时候就需要用到对比评估方法。
对比评估的核心是判断两个或多个模型之间是否存在显著的性能差异,以及这种差异是否具有统计学意义。
麦克尼马尔检验 (McNemar Test)
麦克尼马尔检验是对比评估中最常用的统计学方法,特别适用于比较两个分类模型在同一测试集上的表现。
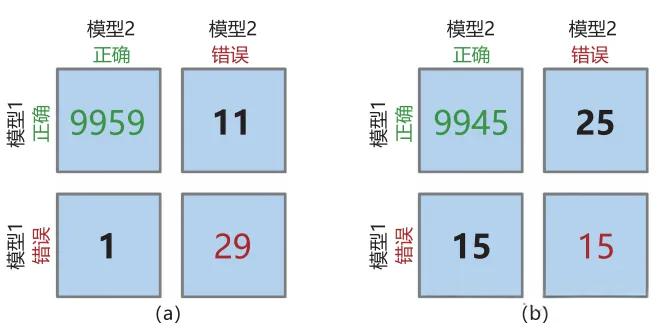
基本原理
假设我们有模型A和模型B,在同一批测试样本上进行预测。对于每个样本,可能出现四种情况:
- 两个模型都预测正确
- 模型A正确,模型B错误
- 模型A错误,模型B正确
- 两个模型都预测错误
我们可以用一个2×2的列联表来表示:
| 模型B正确 | 模型B错误 | |
|---|---|---|
| 模型A正确 | a | b |
| 模型A错误 | c | d |
麦克尼马尔检验关注的是b和c这两个不一致的单元格。如果两个模型性能相近,那么b和c应该大致相等;如果一个模型明显优于另一个,那么b和c就会有显著差异。
检验统计量
麦克尼马尔检验的卡方统计量计算公式为:
χ 2 = ( b − c ) 2 b + c \chi^2 = \frac{(b-c)^2}{b+c} χ2=b+c(b−c)2
当样本量较大时(b+c>25),可以使用连续性校正:
χ 2 = ( ∣ b − c ∣ − 1 ) 2 b + c \chi^2 = \frac{(|b-c|-1)^2}{b+c} χ2=b+c(∣b−c∣−1)2
这个统计量服从自由度为1的卡方分布。通过查卡方分布表或计算p值,我们可以判断两个模型的差异是否具有统计显著性。
显著性判断
在假设检验中,我们通常设定显著性水平α=0.05。判断标准为:
- 如果p值 < 0.05,则拒绝零假设,认为两个模型存在显著差异
- 如果p值 ≥ 0.05,则不能拒绝零假设,认为没有足够证据表明两个模型有显著差异
实际应用示例
假设我们在1000个测试样本上比较两个模型,得到如下结果:
| 模型2正确 | 模型2错误 | |
|---|---|---|
| 模型1正确 | 945 | 25 |
| 模型1错误 | 15 | 15 |
这里b=25,c=15,计算卡方统计量:
χ 2 = ( 25 − 15 ) 2 25 + 15 = 100 40 = 2.5 \chi^2 = \frac{(25-15)^2}{25+15} = \frac{100}{40} = 2.5 χ2=25+15(25−15)2=40100=2.5
查卡方分布表,自由度为1,卡方值为2.5时,p值约为0.114,大于0.05。因此我们不能认为这两个模型有显著差异。
但如果结果是:
| 模型2正确 | 模型2错误 | |
|---|---|---|
| 模型1正确 | 9945 | 25 |
| 模型1错误 | 15 | 15 |
这种情况下,虽然不一致的数量相同,但由于总体准确率都很高(模型1为9960/10000,模型2为9960/10000),我们需要更多样本或更细致的分析来判断差异。
配对t检验
在回归任务或连续评分任务中,麦克尼马尔检验不再适用,这时可以使用配对t检验 (Paired t-test)。
配对t检验比较两个模型在同一测试集上的平均性能差异。检验统计量为:
t = d ˉ s d / n t = \frac{\bar{d}}{s_d/\sqrt{n}} t=sd/ndˉ
其中:
- d ˉ \bar{d} dˉ 是两个模型评分差值的平均值
- s d s_d sd 是差值的标准差
- n 是样本数量
Wilcoxon符号秩检验
当数据不满足正态分布假设时,可以使用Wilcoxon符号秩检验,这是一种非参数检验方法,对数据分布的假设更少,更加稳健。
Bootstrap检验
Bootstrap是一种基于重采样的统计方法,通过从原始数据中有放回地抽样多次,构建统计量的分布,从而估计置信区间。这种方法对数据分布没有严格要求,在样本量较小时也能给出可靠的结果。
对比评估的注意事项
在进行对比评估时,需要注意以下几点:
测试集的选择:确保测试集具有代表性,覆盖不同的难度和场景。测试集太小可能导致结果不可靠,太偏可能无法反映真实性能。
多重比较问题:当同时比较多个模型时,需要进行多重比较校正(如Bonferroni校正),避免假阳性率过高。
实际意义与统计显著性:统计显著不等于实际重要。即使两个模型有显著差异,如果差异很小(如准确率相差0.1%),实际应用价值可能有限。
样本独立性:确保测试样本之间相互独立,避免数据泄露或重复。
评估方法的选择与应用
在实际项目中,如何选择合适的评估方法呢?这需要根据具体场景、资源条件和评估目的来综合考虑。
根据任务类型选择
分类任务:优先使用准确率、精确率、召回率、F1分数等自动化指标,必要时结合人工评估验证边界情况。
回归任务:使用MAE、MSE、RMSE等指标,关注预测误差的分布特征。
生成任务:
- 机器翻译:BLEU作为基础指标,结合人工评估流畅性和准确性
- 摘要生成:ROUGE系列指标,配合人工评估完整性和可读性
- 对话系统:主要依赖人工评估或LLM评估,关注相关性、连贯性、有用性
- 创意写作:人工评估或LLM评估,关注创意性、吸引力、文学价值
根据资源条件选择
预算充足、时间宽裕:采用人工评估,特别是专家评估,能够得到最准确、最有深度的评估结果。
预算有限、需要快速迭代:使用自动化指标或LLM评估,在关键节点进行小规模人工验证。
大规模评估需求:自动化指标结合LLM评估,用人工评估作为标杆来验证自动化方法的可靠性。
根据评估目的选择
模型研发阶段:侧重自动化指标和LLM评估,追求快速反馈和迭代优化。
模型选型决策:结合对比评估和人工评估,确保选择最优方案。
产品上线前验证:必须进行充分的人工评估,特别是真实用户测试,确保产品质量。
持续监控优化:建立自动化评估体系,定期进行人工抽检。
多层次评估策略
在实际应用中,最佳实践是建立多层次的评估体系:
第一层:自动化快速筛选
使用BLEU、ROUGE等自动化指标快速评估大量样本,筛选出明显的问题和优秀案例。
第二层:LLM辅助评估
对自动化指标无法覆盖的维度(如创意性、深度)使用LLM进行评估,提供更全面的视角。
第三层:人工深度评估
对关键样本、边界情况、以及自动化评估结果不确定的案例进行人工深度评估。
第四层:用户反馈
收集真实用户的使用反馈,这是检验模型实际效果的终极标准。
总结
大语言模型的性能评估是一个复杂而系统的工程,需要综合运用多种指标和方法。
本文系统介绍了评估的三个核心层面:
在评估指标方面,我们需要根据任务特点选择合适的度量方式。分类任务有准确率、精确率、召回率、F1分数等经典指标;回归任务使用MAE、MSE、RMSE等误差度量;语言模型关注交叉熵和困惑度;文本生成任务则使用BLEU、ROUGE等专门指标。每种指标都有其适用场景和局限性,需要结合实际需求选择。
在评估方法方面,人工评估、大语言模型评估和对比评估各有特点。人工评估最准确但成本高,适合高质量要求的场景;LLM评估效率高成本低,适合大规模快速评估;对比评估则专门用于判断模型间的性能差异。实践中往往需要组合使用多种方法,建立多层次的评估体系。
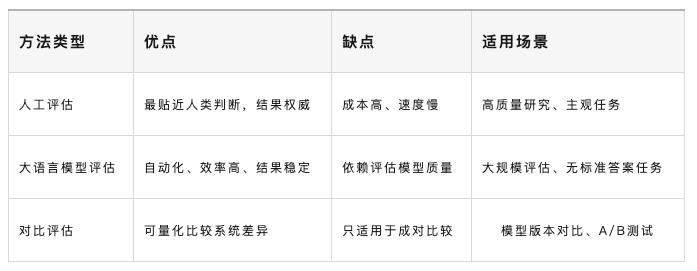
选择评估策略时,需要综合考虑任务类型、资源条件、评估目的等因素。没有一种评估方法适用于所有场景,关键是理解各种方法的优势和局限,根据具体情况灵活选择和组合。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









