




从零开始实现GPT风格的Transformer:完整代码实战指南
作为大模型算法工程师,我深知Transformer架构在现代自然语言处理中的重要地位。今天我将带领大家从零开始,逐步实现一个类似GPT的Transformer模型,每一步都会详细讲解原理和代码实现。
项目概述
本文将完整实现一个GPT风格的Transformer模型,包含所有核心组件:多头注意力机制、位置编码、前馈网络、残差连接和层归一化。我们会使用PyTorch框架,从最基础的数据准备开始,到最终的概率输出,每个环节都会详细解释。
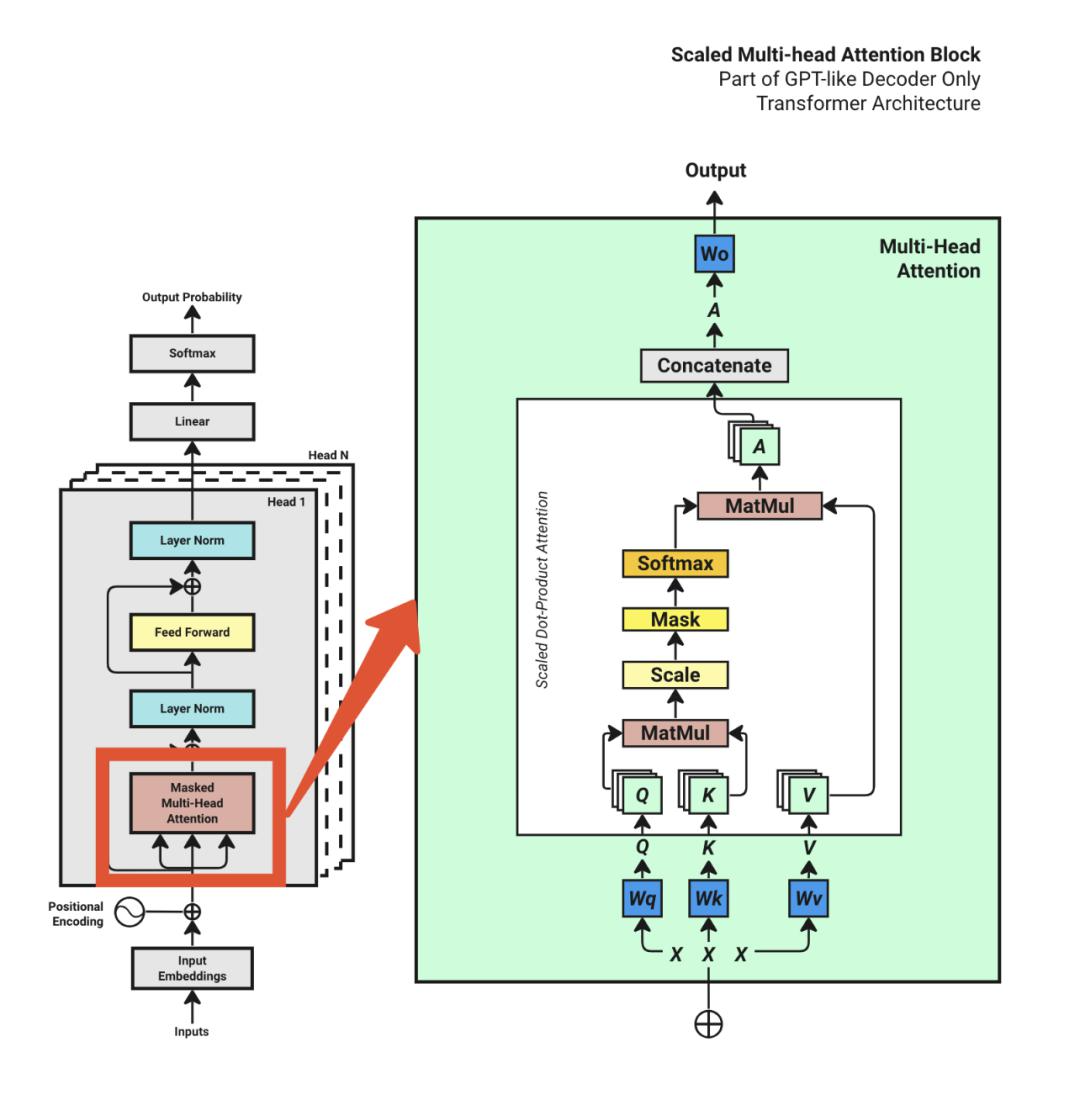
环境准备
首先安装必要的依赖包:
pip install numpy requests torch tiktoken matplotlib pandas
然后导入所需的库:
import os
import requests
import pandas as pd
import matplotlib.pyplot as plt
import math
import tiktoken
import torch
import torch.nn as nn
超参数设置
超参数是模型训练前就需要确定的配置参数,它们直接影响模型的性能和训练效果。我来详细解释每个参数的作用:
# 核心超参数配置
batch_size = 4 # 每个训练步骤的批次大小,影响训练稳定性和显存使用
context_length = 16 # 每个序列的长度,决定模型能处理的最大文本长度
d_model = 64 # Token嵌入向量的维度,影响模型的表达能力
num_layers = 8 # Transformer块的数量,层数越多模型越复杂
num_heads = 4 # 多头注意力中的头数,允许模型从多个角度关注信息
learning_rate = 1e-3 # 学习率,控制参数更新的步长
dropout = 0.1 # Dropout概率,防止过拟合
max_iters = 5000 # 最大训练迭代次数
eval_interval = 50 # 每50步评估一次模型性能
eval_iters = 20 # 评估时平均多少次迭代的损失
device = 'cuda' if torch.cuda.is_available() else 'cpu' # 优先使用GPU加速
# 设置随机种子确保结果可复现
TORCH_SEED = 2008
torch.manual_seed(TORCH_SEED)
数据集准备
我们使用一个销售教科书的文本文件作为训练数据。这个数据集虽然不大,但足以演示Transformer的工作原理:
# 下载销售教科书数据集
if not os.path.exists('sales_textbook.txt'):
url = 'https://huggingface.co/datasets/goendalf666/sales-textbook_for_convincing_and_selling/raw/main/sales_textbook.txt'
with open('sales_textbook.txt', 'w') as f:
f.write(requests.get(url).text)
# 读取文本数据
with open('sales_textbook.txt', 'r', encoding='utf-8') as f:
text = f.read()
第一步:文本分词(Tokenization)
分词是将原始文本转换为模型可以理解的数字序列的关键步骤。我们使用OpenAI的tiktoken库,这是一个高效的分词器:
# 使用TikToken进行分词
encoding = tiktoken.get_encoding("cl100k_base")
tokenized_text = encoding.encode(text)
vocab_size = len(set(tokenized_text)) # 词汇表大小
max_token_value = max(tokenized_text) # 最大token值
print(f"分词后文本长度: {
len(tokenized_text)}")
print(f"词汇表大小: {
vocab_size}")
print(f"最大token值: {
max_token_value}")
输出结果显示:
分词后文本长度: 77919
词汇表大小: 3771
最大token值: 100069
这意味着我们的文本被分割成了77,919个token,词汇表包含3,771个不同的token。
第二步:词嵌入(Word Embedding)
接下来将数据分为训练集和验证集,并准备训练批次:
# 划分训练集和验证集(8:2比例)
split_idx = int(len(tokenized_text) * 0.8)
train_data  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 282
282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









