







一、安装基础环境
# 1、创建环境
conda create -n suna python==3.11.7
# 2、激活虚拟环境
conda activate suna
# 3、安装jupyter和ipykernel
pip install jupyter ipykernel
# 4、将虚拟环境添加到jupyter
# python -m ipykernel install --user --name=myenv --display-name="Python (myenv)"
python -m ipykernel install --user --name=suna二、安装suna环境
切换到源码路径下
cd /Users/dcs/study/Suna修改后项目源码/suna/backend
然后使用pip install,安装Suna项目依赖
pip install -r requirements.txt
安装完成后,我们进入项目前端文件夹(frontend)
然后使用npm install安装前端依赖,
cd /Users/dcs/study/Suna修改后项目源码/suna/frontend
npm install
三、配置Suna项目后端
为了让 Suna 项目具备完整的功能能力,后端需要集成并配置多个核心组件。这些组件为智能体的网络感知、数据抓取、任务执行和持久化存储等功能提供支持。整个配置流程共包括四个关键步骤,分别对应四个重要模块:
-
配置 1:Tavily API-KEY —— 开启网络搜索功能
Tavily 是一个支持智能搜索请求的 API 服务,能够帮助智能体通过自然语言查询获取实时的网页搜索结果。
在 Suna 中,Tavily 的接入主要用于为智能体提供“联网搜索”能力,特别适用于需要获取最新信息的 RAG(Retrieval-Augmented Generation)场景。 -
配置 2:Firecrawl API-KEY —— 开启网页爬虫功能
Firecrawl 是一个轻量级的网页爬虫服务,它可以提取网页的文本内容、元信息甚至嵌入结构化数据。
在 Suna 中,Firecrawl 的接入使得智能体可以针对特定网页进行内容爬取和语义理解,为深度问答、内容分析等任务提供支持。 -
配置 3:Daytona —— 开启沙盒环境支持
Daytona 是一个可供开发者远程部署并运行代码的云端开发环境。通过接入 Daytona,Suna 的智能体可以在隔离的沙盒中运行代码、调试任务或部署服务,从而实现更强的“Agent 执行能力”。
-
配置 4:Supabase —— 启用完整后端数据支持
Supabase 是一个开源后端服务平台,提供数据库、认证、存储等多项功能。在 Suna 中,Supabase 被用作数据持久化、用户管理、运行日志记录等关键功能的后端支持。
配置1、tavily API-KEY:开启网络搜索功能


配置2、firecrawl API-KEY:开启网络爬虫功能

配置3、Daytona:开启沙盒环境功能
接下来是配置沙盒环境工具 Daytona。由于 Daytona 的设置相对复杂,建议结合文字版课件操作,便于复制和参考。
首先,访问 Daytona 官方网站(Daytona - Secure Infrastructure for Running AI-Generated Code)并完成注册流程。
完成注册后,我们需要为 Suna 创建一个专属镜像,以确保 Daytona 能够正常运行项目代码。在左侧菜单栏点击 “Image(镜像)” 选项,接着点击右上角的 “Create Image(创建镜像)” 按钮。
在弹出的创建窗口中,填写预设的 Image Name 和 Entrypoint 信息,然后点击 创建。该过程配置较多,建议直接参考课件中的具体参数,复制粘贴以减少出错。

- Image name: kortix/suna:0.1.2
- Entrypoint: /usr/bin/supervisord -n -c /etc/supervisor/conf.d/supervisord.conf


配置4、supabase:开启完整后端支持
接下来是配置后端服务工具 Supabase。首先,访问 Supabase 官方网站(Supabase | The Postgres Development Platform.),并根据页面引导完成账户注册和项目创建流程。
创建项目时,你可以自定义项目名称,例如此处我们创建了一个名为 test 的项目。项目创建成功后,Supabase 将为该项目自动生成数据库实例及相关服务接口,用于支撑 Suna 项目的数据存储、用户管理和权限控制等功能。





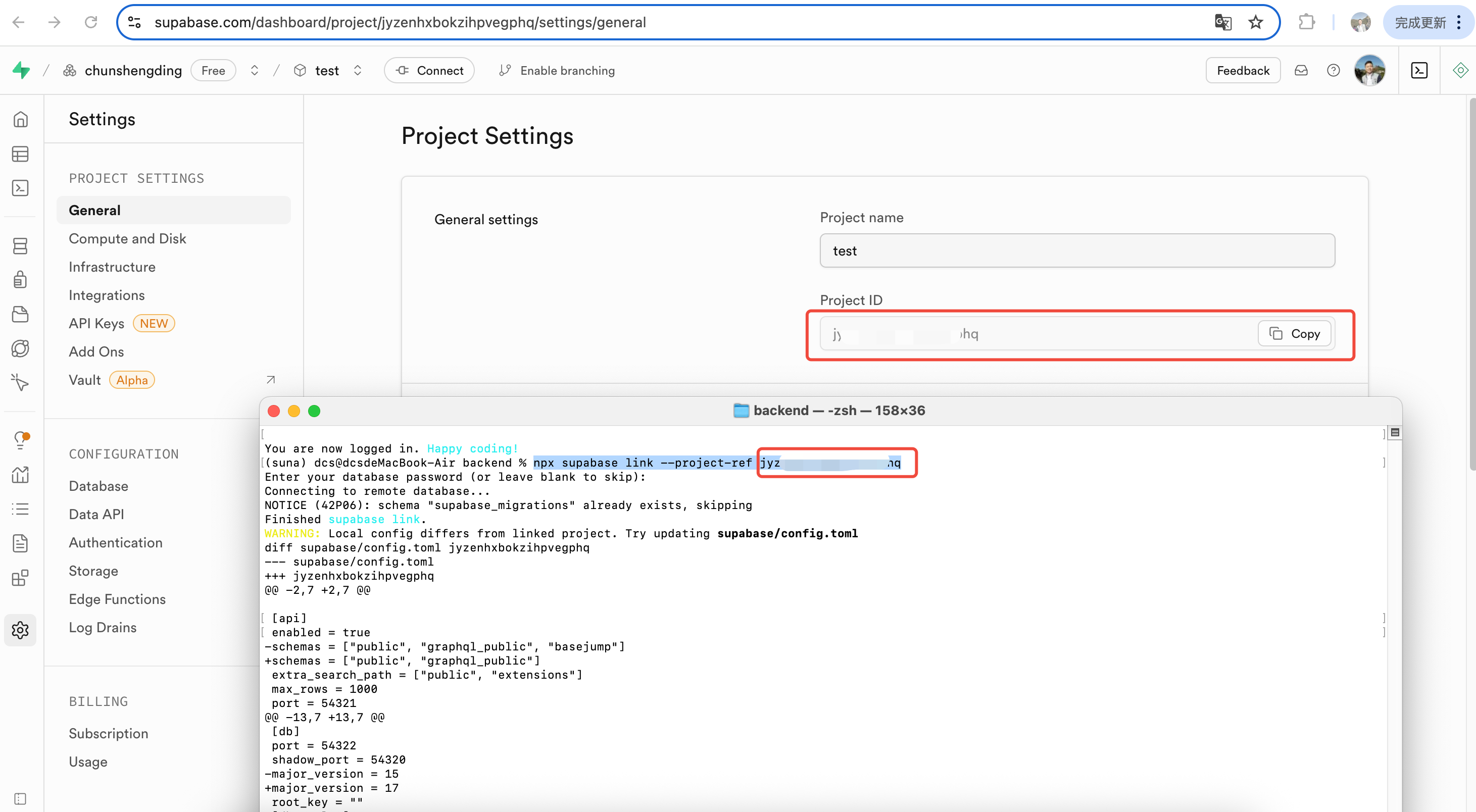
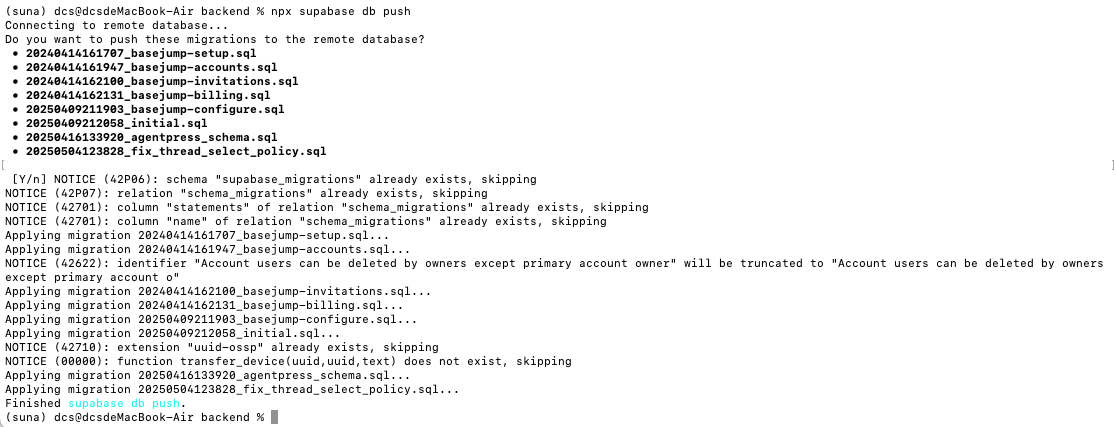

四、配置Suna底层大模型
最后一个阶段是设置 Suna 的基础模型配置。强烈建议分别为 Suna 的前端和后端配置不同的大模型,这样可以显著提升系统的响应速度和整体性能。
-
后端大模型配置: 推荐使用 Claude 3.7 模型,该模型目前在 Agent 能力方面表现最为出色,也是 Suna 默认采用的后端模型。您可以通过官方渠道(例如某宝购买或自行注册)获取 Claude 的 API Key,然后将该密钥填写到后端配置文件 .env 中对应的字段,完成配置。
-
前端大模型配置: 建议配置 DeepSeek 模型,专门优化前端交互体验,保证响应的流畅与精准。
这样区分配置,能够让 Suna 在不同任务场景下发挥最佳效能。

此外,您也可以填写 OpenRouter 的 API Key,以便调用包括 DeepSeek 模型在内的多种主流大模型,提升灵活性和模型选择范围。
接下来,使用文本编辑器打开前端的配置文件 .env.local,进行相应的 API Key 填写和配置调整。

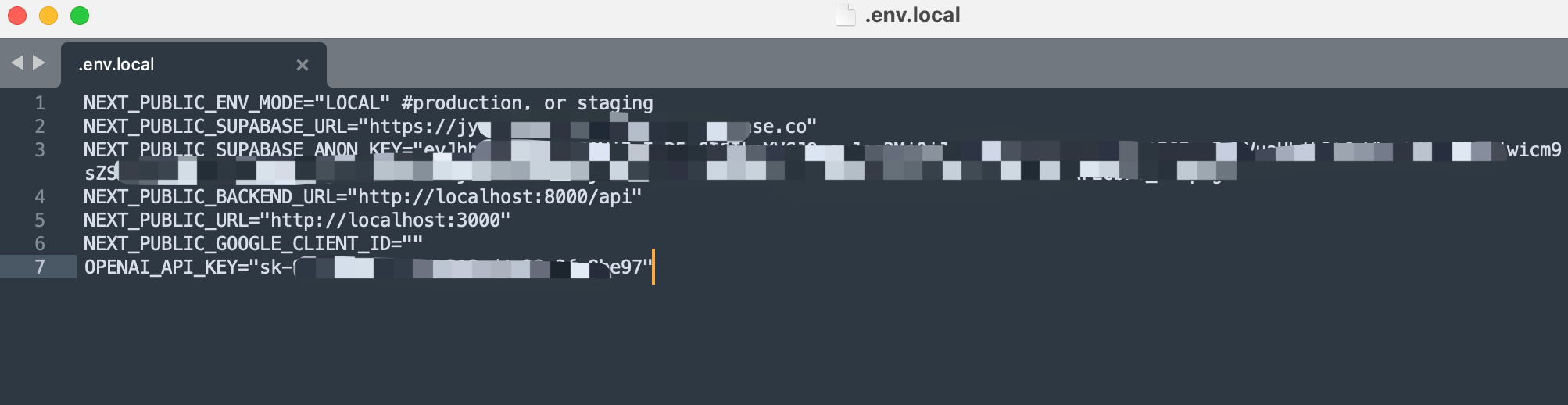
然后,记得保存并关闭配置文件。
至此,所有准备工作已经完成,接下来即可按照以下步骤启动 Suna 项目:
- 第一步:借助docker启动Redis
- 第二步:启动Suna后端
- 第三步:启动Suna前端



然后,完成注册后即可登录到对话页面,开始与 Suna 进行交互。Suna 不仅支持普通的聊天对话,还能够执行各种复杂任务。当前你看到的,就是一个完整的复杂任务执行流程示例:
-
Suna 会先对任务进行整体规划,
-
然后按照计划一步步执行各项操作,
-
在执行过程中,Suna 能够调用命令行命令、操作浏览器、编写和运行 Python 代码,
-
甚至能在沙盒环境中创建、编辑相关文件,完成复杂的自动化工作。
这种高度灵活且强大的能力,使得 Suna 不仅是聊天助手,更是一个多功能的智能执行平台。

五、功能介绍
简单来说,Suna 是一款全能型 AI 助手,能够通过自然语言对话帮助你完成各种实际任务。它不仅仅是一个聊天机器人,更是一个能真正解决问题、自动化工作流程的数字伙伴。
最令人兴奋的是,Suna 完全开源,任何人都可以自由使用、学习和二次开发,推动智能助手技术的普及与进步。

Suna 的四大核心组件
-
后端 API
基于 Python 和 FastAPI 构建,负责处理 RESTful 接口请求、线程管理,
并通过 LiteLLM 集成 OpenAI、Anthropic 及其他大型语言模型(LLM),为智能体提供强大的语言理解和生成能力。
-
前端
使用 Next.js 和 React 技术打造,提供响应式的用户界面,
包括流畅的聊天窗口、管理仪表盘等,确保用户体验友好顺畅。
-
Agent Docker
为每个智能代理提供独立隔离的执行环境,支持浏览器自动化操作、代码解释执行、文件系统访问、各种工具集成及安全控制,确保任务执行高效且安全。
-
Supabase 数据库
负责数据的持久化管理,包括用户认证、权限控制、对话历史记录、文件存储、代理状态监控、数据分析及实时订阅推送,构建可靠的数据基础设施。
Suna 能做什么?
Suna 就像你的私人 AI 助手,具备丰富且强大的功能:
-
浏览器自动化:自动访问网页,采集和提取所需数据
-
文件管理:创建、编辑和管理各类文档
-
网络爬虫:智能抓取网络信息,辅助内容检索
-
扩展搜索:帮助快速定位和获取关键信息
-
命令行执行:处理系统层面的任务和命令
-
网站部署:简化网站上线和维护流程
-
API 集成:无缝连接各类第三方服务和平台
这些功能协同工作,使得 Suna 能通过简单的自然语言对话,轻松解决复杂的问题和任务,实现真正的智能自动化。
实际应用案例
- 市场竞争分析
- 寻找投资机会
- 人才招聘辅助
- 公司旅行规划
- Excel数据整理
- 活动演讲嘉宾寻找
- 科学论文总结与比较
- 潜在客户研究
- SEO分析
- 个人旅行规划

















 1954
1954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









