



 模型离线推理涉及Host和Device的内存管理,包括数据传输、模型加载、输入输出准备、执行推理以及输出解析等关键步骤。在设备上,om模型被加载,输入数据在Host内存处理后转移到Device进行推理,最后结果从Device内存解析出来。整个过程由AscendCL接口协助完成。
模型离线推理涉及Host和Device的内存管理,包括数据传输、模型加载、输入输出准备、执行推理以及输出解析等关键步骤。在设备上,om模型被加载,输入数据在Host内存处理后转移到Device进行推理,最后结果从Device内存解析出来。整个过程由AscendCL接口协助完成。
应用开发深入讲解之模型离线推理
模型离线推理是指使用已经转好的om模型对输入图片进行推理,主要步骤如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4hMx2mLb-1685345896843)(../../../../AppData/Roaming/Typora/typora-user-images/image-20230529151126820.png)]](https://i-blog.csdnimg.cn/blog_migrate/9cdb3aac998e0c7cb56e16fca13d21a1.png)
1.Host&Device内存管理与数据传输
Host&Device上的内存申请与释放,内存间的相互拷贝。
代码中加载输入数据时,需要申请Host内存进行存储,当输入数据处理完毕后,需要将处理完成的数据从Host内存拷贝
到Device的模型输入内存中,以便于Device进行模型推理的专用计算。

2.模型加载
将离线的om文件加载到Device上。
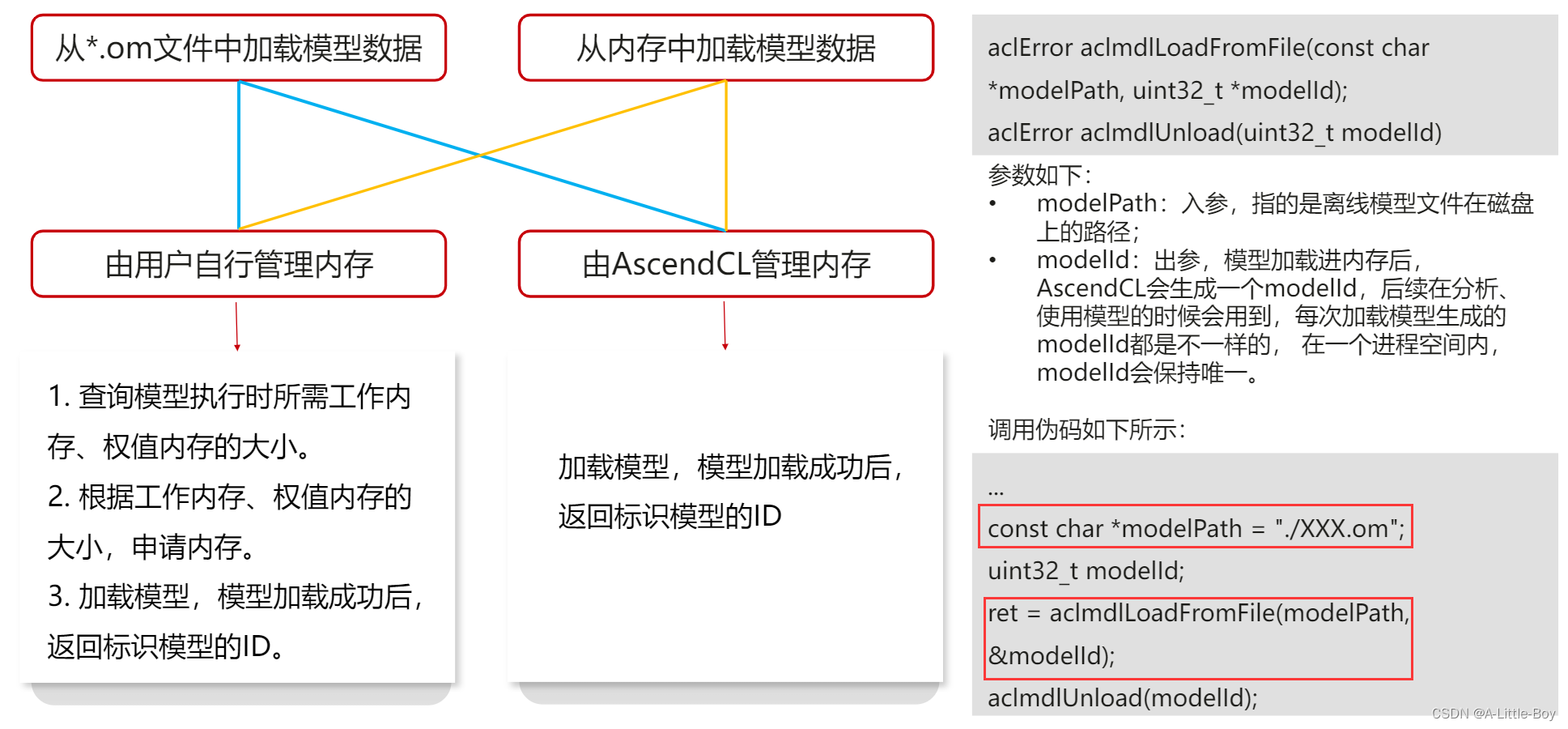
模型加载支持多种加载方式,由用户根据需求选择从om模型文件或内存加载模型数据、选择由用户自行管理内存或由AscendCL管理内存。而不管用哪种接口,最终卸载时接口都是统一的。
3.模型输入输出准备
根据离线om的输入输出,在Deⅵce上申请好模型的输入输出内存。

4.执行推理
当模型的输入内存获取到有效数据后,便可以调用AscendCL接口执行模型推理,推理完成后结果生成到输出内存中;在样例的模型推理模块中进行。

5.输出解析:使用AscendCL接口,将模型输出数据从特定格式中解析出来;在输出数据处理模块中进行。

















 852
852

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









