









一、什么是算子
算子是RDD中定义的函数,可以对RDD中的数据进行转换和操作(transformation和action)
transformation不触发提交作业;action出发SparkContext提交Job作业
二、常用算子不完全归纳
-
Transformation转换操作
- 基础转换操作
- map、mapPartitions、mapPartitionsWithIndex
- distinct:对RDD分区进行数据去重
- flatMap
- union:将两个RDD合并,返回两个RDD的并集,不去重
- intersection:返回两个RDD交集,去重
- subtract:返回在一个RDD中出现,且不在另一个RDD中出现的元素
- zip、zipPartition:
- zip将两个RDD组合成key-value形式的RDD(默认两个RDD的partition数量和元素数量相同)
- zipPartitions将多个RDD按照partition组合为新RDD(待组合的RDD具有相同的分区书,对每个分区内的元素数量没有要求)
- zipWithIndex
- zipWithUniqueId:唯一ID生成算法
- coalesce:使用HashPartitioner进行重分区(参数1:重分区的数目;参数2:是否进行 shuffle(false))
- repartition:coalesce参数2为true
- randomSplit:根据weights权重将一个RDD分隔为多个RDD(结果是一个RDD数组)
- sample:从数据集中抽取一部分数据
- glom:将RDD中每个分区所有类型为T的数据转变成元素类型为T的数组
- 键值转换操作
- partitionBy:根据partitioner函数生成新的shuffleRDD,将原来的RDD重新分区
- mapValues:对k-v中的v进行map
- flatMapValues:对k-v中的v进行flatMap
- combineByKey:RDD[K,V]->RDD[K,C]
- foldByKey:根据K将V做折叠、合并
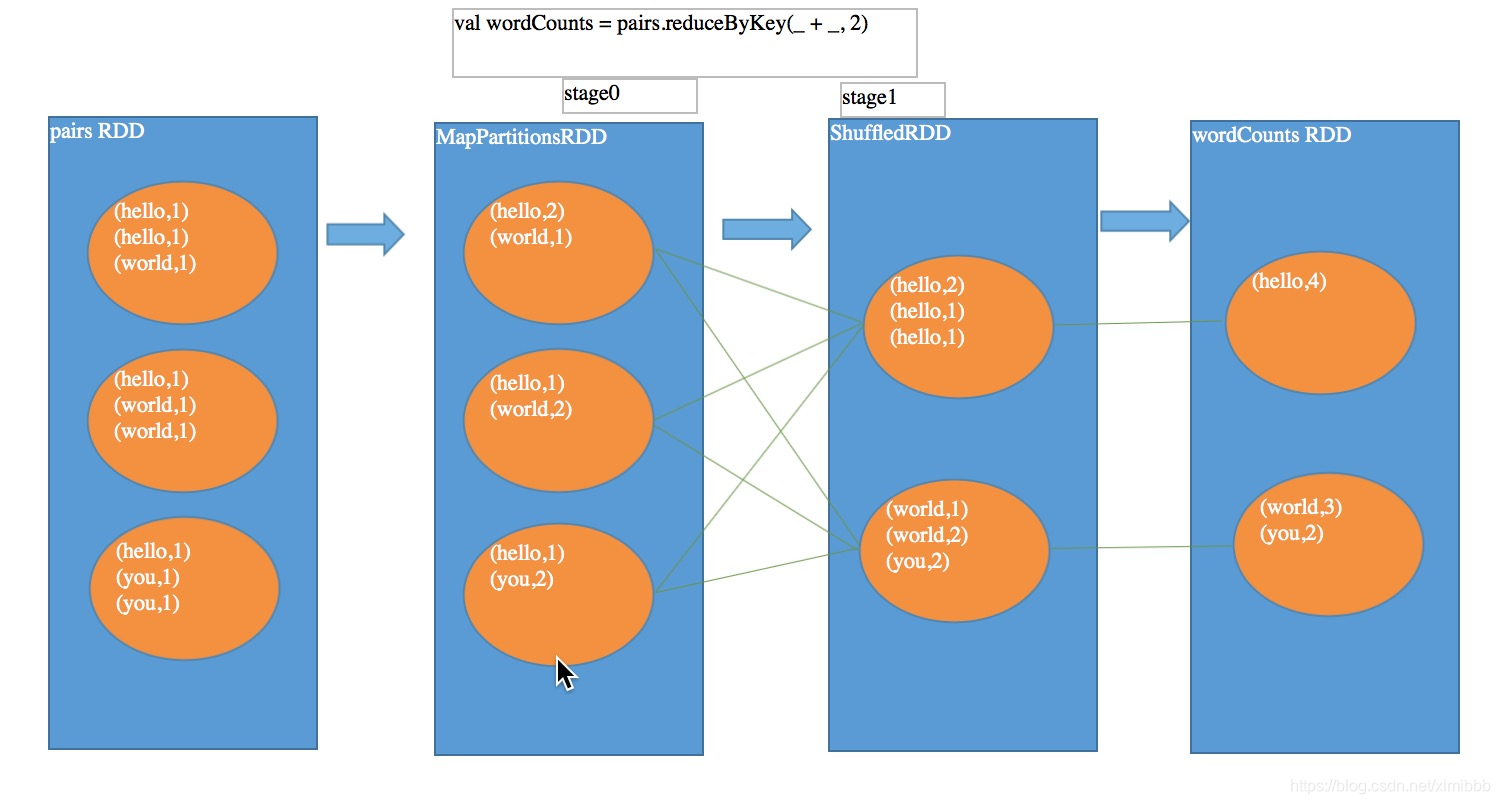
- reduceByKey:得到RDD[(K,V)]
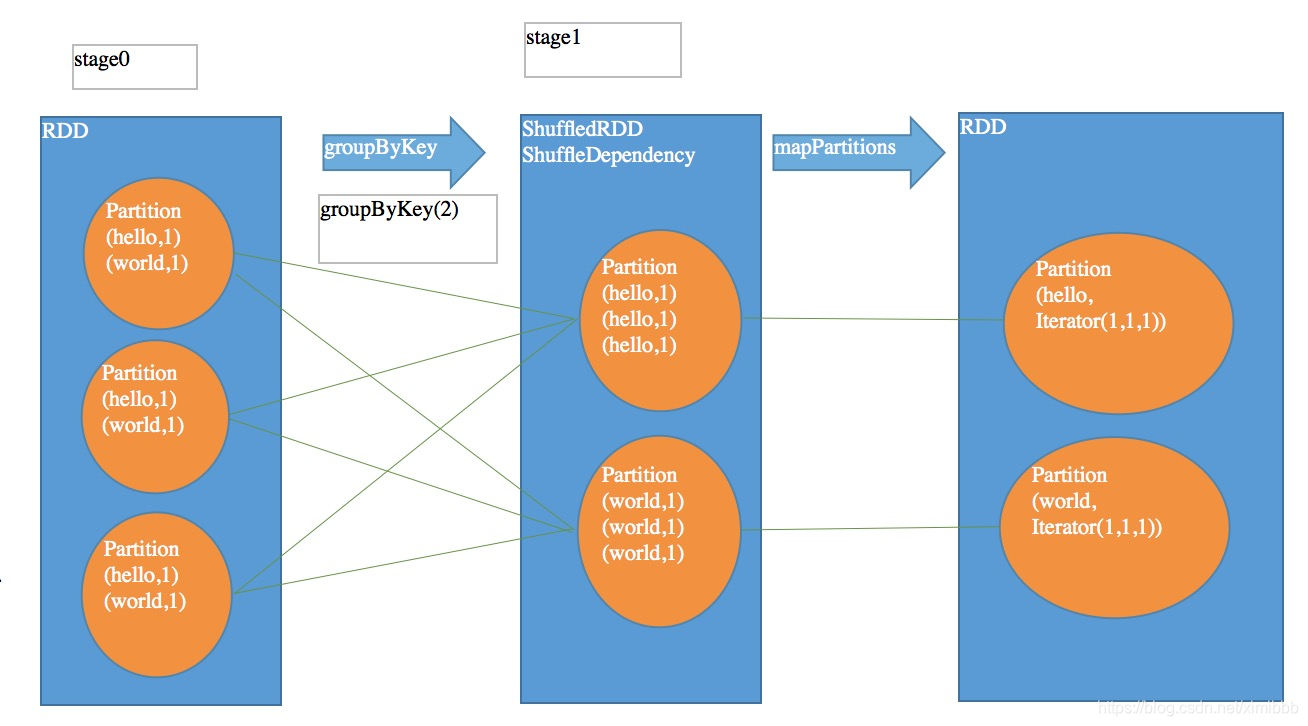
- groupByKey:将RDD[K,V]中每个K对应的V值合并到一个集合Iterable[V]中。得到RDD[(K,Iterable[V])]
- aggregateByKey:这个函数可用于完成对groupByKey,reduceByKey的相同的功能,用于对rdd中相同的key的值的聚合操作,主要用于返回一个指定的类型U的RDD的transform,
- cogroup
- join、fullOuterJoin、leftOuterJoin、rightOuterJoin
- subtractByKey
- 基础转换操作
-
Actions行为操作
- 基础行为操作
- first
- count
- reduce
- collect
- take:返回Array[T]。获取RDD中0-num-1下标的元素
- top:返回Array[T]。按照默认(降序)排序取前num个元素
- takeOrdered:返回Array[T]。以top相反的顺序返回元素
- aggregate:先聚合(支持不同类型的聚合)每个分区里的元素,返回所有结果。再按给定方法及给定的初始值进行聚合(同构聚合)
- fold:相比reduce加了一个初始值参数
- foreach、foreachPartition:遍历RDD,应用函数func(只会在Executor端有效,而不是Driver端);foreachPartition对每一个分区使用func
- sortBy:根据给定的排序函数,对RDD元素进行排序
- takeSample:takeSample返回的结果不再是RDD,而是相当于对采样后的数据进行collect()
- 键值行为操作
- lookup:用于(K,V)类型的RDD,指定K值,返回RDD中该K对应的所有V值
- countByKey:统计RDD[K,V]中每个K的数量
- 控制行为操作
- cache():是 persist()特例
- persist():可以指定storageLevel,当StorageLevel为MEMORY_ONLY时就是cache
- 存储行为操作
-
saveAsTextFile:用于将RDD以文本文件的格式存储到文件系统
-
saveAsSequence:用于将RDD以SequenceFile文件格式保存到HDFS
-
saveAsObjectFile:用于将RDD中的元素序列化成对象,存储到文件(对于HDFS,默认采用SequenceFile保存)
-
saveAsHadoopFile
-
saveAsHadoopDataset
-
saveAsNewAPIHadoopFile
-
saveAsNewAPIHadoopDateset
-
- 基础行为操作
三、容易混淆的算子对比
-
map vs mapPartitions vs mapPartitionWithIndex
map 一次处理一个 partition 中的一条数据
mapPartitions 一次处理一个 partition 的全部数据
mapPartitionWithIndex 可以得到每个 partition 的 index,从 0 开始 -
sample vs takeSample
sample 算子就是从数据集中抽取一部分数据
takeSample 是 action 操作,sample 是 transformation 操作。takeSample返回的结果不再是RDD,而是相当于对采样后的数据进行collect()
takeSample 不能指定抽取比例,只能是抽取几个 -
groupByKey vs reduceByKey
shuffle算子作为stage划分的边界。(K,V)->(K,Seq[V])
不同之处:比groupByKey多了一个RDD,MapPartitionRDD。代表了进行本地数据规约后的RDD。所以网络传输的数据量以及磁盘I/O等都会减少,性能更高
相同之处:后面进行 shuffle read 和聚合的过程基本和 groupByKey 类似。都是 shuffleRDD,去做 shuffle read。然后聚合, 聚合后的数据就是最终的 RDD。
-
aggregateByKey vs combineByKey vs cogroup vs sortByKey
aggregateByKey提供了一个函数,控制如何对每个partition中的数据进行聚合(Seq Function控制进行shuffle map端的本地聚合;Combiner Function进行shuffle reduce端的全局聚合)
combineByKey对RDD中的数据集按key进行聚合操作
cogroup把多个 RDD 中的数据根据 key 聚合起来
shuffleRDD, 做 shuffle read, 将相同的 key 拉到一个 partition 中来
mapPartition, 对每个 partition 内的 key 进行全局的排序 -
intersection vs join
intersection
1. 首先 map 操作变成一个 tuple
2. 然后 cogroup 聚合两个 RDD 的 key
3. filter, 过滤掉两个集合中任意一个集合为空的 key
4. map,还原出单 keyjoin
1. cogroup, 聚合两个 RDD 的 key,将相同key的数据放到一个分区
2. flatMap, 聚合后,每条数据可能返回多条数据,将每个 key 对应两个集合做了一个笛卡儿积

















 2648
2648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









