




 本文深入介绍了Spark中的RDD算子,包括转化算子如map、filter和flatMap,以及按键归约算子reduceByKey。通过实例展示了如何使用这些算子进行数据处理,如翻倍元素、过滤偶数、统计单词数量和计算学生总分等。此外,还涵盖了在SparkShell和IDEA中执行Spark任务的方法。
本文深入介绍了Spark中的RDD算子,包括转化算子如map、filter和flatMap,以及按键归约算子reduceByKey。通过实例展示了如何使用这些算子进行数据处理,如翻倍元素、过滤偶数、统计单词数量和计算学生总分等。此外,还涵盖了在SparkShell和IDEA中执行Spark任务的方法。
文章目录
一、RDD算子
RDD被创建后是只读的,不允许修改。Spark提供了丰富的用于操作RDD的方法,这些方法被称为算子。一个创建完成的RDD只支持两种算子:转化(Transformation)算子和行动(Action)算子
二、准备工作
(一)准备文件
1、准备本地系统文件
在/home目录里创建wprds.txt

2、把文件上传到HDFS
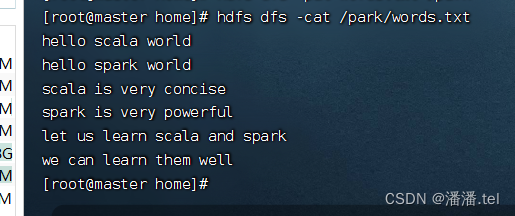
将words.txt上传到HDFS系统的/park目录里

说明:/park是在上一讲我们创建的目录
查看文件内容
(二)启动Spark Shell
1、启动HDFS服务
执行命令:start-dfs.sh
如果采用的是Spark on YARN集群或者Spark HA集群,那么还得启动YARN服务

2、启动Spark服务
进入Spark的sbin目录执行命令:./start-all.sh

3、启动Spark Shell
执行名命令: spark-shell --master spark://master:7077
三、转化算子
(一)映射算子 - map()
1、映射算子功能
map()是一种转化算子,它接收一个函数作为参数,并把这个函数应用于RDD的每个元素,最后将函数的返回结果作为结果RDD中对应元素的值。
2、映射算子案例
预备工作:创建一个RDD - rdd1
执行命令:val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5, 6))

任务1、将rdd1每个元素翻倍得到rdd2
对rdd1应用map()算子,将rdd1中的每个元素平方并返回一个名为rdd2的新RDD

上述代码中,向算子map()传入了一个函数x = > x * 2。其中,x为函数的参数名称,也可以使用其他字符,例如a => a * 2。Spark会将RDD中的每个元素传入该函数的参数中。
其实,利用神奇占位符_可以写得更简洁
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2815
2815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









