







文章目录
0. 摘要
文件是每一个主流操作系统的主要存储模型;这种观念如此根深蒂固以至于难以想出一种替代物。打个比方,你的电脑实际上就是泡在文件里了。
这一章将学习
p
y
t
h
o
n
python
python中的文件操作。
1. 读取文本文件

P y t h o n Python Python有一个内置函数 o p e n ( ) open() open(),它使用一个文件名作为其参数。在以上代码中,文件名是 ‘examples/chinese.txt’。关于这个文件名,有五件值得一讲的事情:
- 它不仅是一个文件的名字;实际上,它是文件路径和文件名的组合;一般来说,文件打开函数应该有两个参数 — 路径和文件名 — 但是函数 o p e n ( ) open() open()只使用一个参数。在 P y t h o n Python Python里,当你使用 f i l e n a m e filename filename作为参数的时候,你可以将部分或者全部的路径也包括进去。
- 在这个例子中,目录路径中使用的是斜杠( f o r w a r d s l a s h forward\ slash forward slash),但是我并没有说明我正在使用的操作系统。 W i n d o w s Windows Windows使用反斜杠来表示子目录,但是 M a c O S X Mac\ OS\ X Mac OS X和 L i n u x Linux Linux使用斜杠。但是,在 P y t h o n Python Python中,斜杠永远都是正确的,即使是在 W i n d o w s Windows Windows环境下。这很棒,没有人愿意打一堆反斜杠吧?
- 不使用斜杠或者反斜杠的路径被称作相对路径( r e l a t i v e p a t h relative\ path relative path)。你也许会问,相对于什么呢?耐心一些,伙计。
- f i l e n a m e filename filename参数是一个字符串。所有现代的操作系统(甚至 W i n d o w s Windows Windows)使用 U n i c o d e Unicode Unicode编码方式来存储文件名和目录名。 P y t h o n 3 Python 3 Python3全面支持非 a s c i i ascii ascii编码的路径。
- 文件不一定需要在本地磁盘上。也许你挂载了一个网络驱动器。它也可以是一个完全虚拟的文件系统( a n e n t i r e l y v i r t u a l f i l e s y s t e m an\ entirely\ virtual\ filesystem an entirely virtual filesystem)上的文件。只要你的操作系统认为它是一个文件,并且能够以文件的方式访问,那么, P y t h o n Python Python就能打开它。
但是对 o p e n ( ) open() open()函数的调用不局限于 f i l e n a m e filename filename。还有另外一个叫做 e n c o d i n g encoding encoding参数。天哪,似乎非常耳熟的样子!
1.1 字符编码抬起了它腌臜的头…
字节即字节;字符是一种抽象。字符串由使用
U
n
i
c
o
d
e
Unicode
Unicode编码的字符序列构成。但是磁盘上的文件不是
U
n
i
c
o
d
e
Unicode
Unicode编码的字符序列。文件是字节序列。所以你可能会想,如果从磁盘上读取一个“文本文件”,
P
y
t
h
o
n
Python
Python是怎样把那个字节序列转化为字符序列的呢?实际上,它是根据特定的字符解码算法来解释这些字节序列,然后返回一串使用
U
n
i
c
o
d
e
Unicode
Unicode编码的字符(或者也称为字符串)。
o
k
ok
ok,我再重复一遍。字节序列—编码(
e
n
c
o
d
i
n
g
encoding
encoding)—字符串,字符串—解码(
d
e
c
o
d
i
n
g
decoding
decoding)—字节序列。
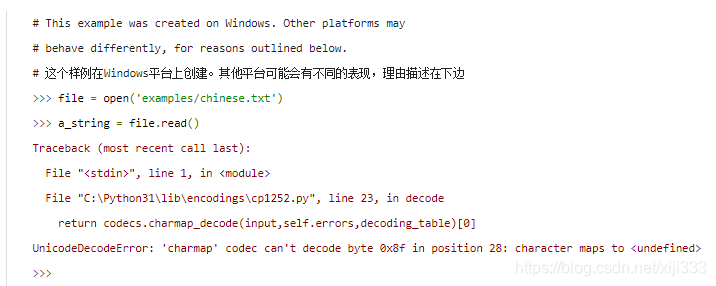
刚才发生了什么?由于你没有指定字符编码的方式,所以
P
y
t
h
o
n
Python
Python被迫使用默认的编码。那么默认的编码方式是什么呢?如果你仔细看了跟踪信息(
t
r
a
c
e
b
a
c
k
traceback
traceback),错误出现在
c
p
1252.
p
y
cp1252.py
cp1252.py,这意味着
P
y
t
h
o
n
Python
Python此时正在使用
C
P
−
1252
CP-1252
CP−1252作为默认的编码方式(在运行微软视窗操作系统的机器上,
C
P
−
1252
CP-1252
CP−1252是一种常用的编码方式)。
C
P
−
1252
CP-1252
CP−1252的字符集不支持这个文件上的字符编码,所以它读取失败了并返回这个可恶的
U
n
i
c
o
d
e
D
e
c
o
d
e
E
r
r
o
r
UnicodeDecodeError
UnicodeDecodeError错误。
但是,还有更糟糕的!因为默认的编码方式是平台相关的(
p
l
a
t
f
o
r
m
−
d
e
p
e
n
d
e
n
t
platform-dependent
platform−dependent),所以,当前的代码也许能够在你的电脑上运行(如果你的机器的默认编码方式是
u
t
f
−
8
utf-8
utf−8),但是当你把这份代码分发给其他人的时候可能就会失败(因为他们的默认编码方式可能跟你的不一样,比如说
C
P
−
1252
CP-1252
CP−1252)。
如果你需要获得默认编码的信息,则导入
l
o
c
a
l
e
locale
locale模块,然后调用
l
o
c
a
l
e
.
g
e
t
p
r
e
f
e
r
r
e
d
e
n
c
o
d
i
n
g
(
)
locale.getpreferredencoding()
locale.getpreferredencoding()。在我安装了
W
i
n
d
o
w
s
Windows
Windows的笔记本上,它的返回值是
c
p
1252
cp1252
cp1252,但是在我楼上安装了
L
i
n
u
x
Linux
Linux的台式机上边,它返回
U
T
F
8
UTF8
UTF8。你看,即使在我自己家里我都不能保证一致性(
c
o
n
s
i
s
t
e
n
c
y
consistency
consistency)!你的运行结果也许不一样(即使在
W
i
n
d
o
w
s
Windows
Windows平台上,没错,我的是
c
p
936
cp936
cp936),这依赖于操作系统的版本和区域/语言选项的设置。这就是为什么每次打开一个文件的时候指定编码方式是如此重要了。
1.2 流对象
到目前为止,我们都知道
P
y
t
h
o
n
Python
Python有一个内置的函数叫做
o
p
e
n
(
)
open()
open()。
o
p
e
n
(
)
open()
open()函数返回一个流对象(
s
t
r
e
a
m
o
b
j
e
c
t
stream\ object
stream object),它拥有一些用来获取信息和操作字符流的方法和属性。

n
a
m
e
name
name属性反映的是当你打开文件时传递给
o
p
e
n
(
)
open()
open()函数的文件名。它没有被标准化(
n
o
r
m
a
l
i
z
e
normalize
normalize)成绝对路径。
同样的,
e
n
c
o
d
i
n
g
encoding
encoding属性反映的是在你调用
o
p
e
n
(
)
open()
open()函数时指定的编码方式。如果你在打开文件的时候没有指定编码方式(不好的开发人员!),那么
e
n
c
o
d
i
n
g
encoding
encoding属性反映的是
l
o
c
a
l
e
.
g
e
t
p
r
e
f
e
r
r
e
d
e
n
c
o
d
i
n
g
(
)
locale.getpreferredencoding()
locale.getpreferredencoding()的返回值。
m
o
d
e
mode
mode属性会告诉你被打开文件的访问模式。你可以传递一个可选的
m
o
d
e
mode
mode参数给
o
p
e
n
(
)
open()
open()函数。如果在打开文件的时候没有指定访问模式,
P
y
t
h
o
n
Python
Python默认设置模式为
r
r
r,意思是“在文本模式下以只读的方式打开”。在这章的后面你会看到,文件的访问模式有各种用途;不同模式能够使你写入一个文件,追加到一个文件,或者以二进制模式打开一个文件(在这种情况下,你处理的是字节,不再是字符)。
1.3 从文本文件读取数据
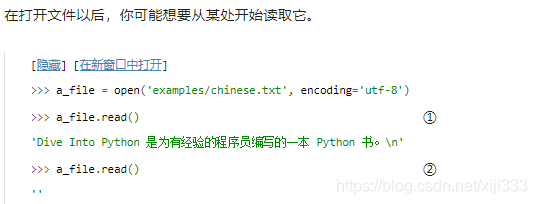
只要成功打开了一个文件(并且指定了正确的编码方式),你只需要调用流对象的
r
e
a
d
(
)
read()
read()方法即可以读取它。返回的结果是文件的一个字符串表示。
也许你会感到意外,再次读取文件不会产生一个异常。
P
y
t
h
o
n
Python
Python不认为到达了文件末尾(
e
n
d
−
o
f
−
f
i
l
e
end-of-file
end−of−file)还继续执行读取操作是一个错误;这种情况下,它只是简单地返回一个空字符串。

我希望你能注意到两个地方,
r
e
a
d
(
)
read()
read()方法的参数表示要读取的字符个数,
s
e
e
k
(
)
seek()
seek()方法是定位到文件中的特定字节。

你是否已经注意到了?
s
e
e
k
(
)
seek()
seek()和
t
e
l
l
(
)
tell()
tell()方法总是以字节的方式计数,但是,由于你是以文本文件的方式打开的,
r
e
a
d
(
)
read()
read()方法以字符的个数计数。中文字符的
U
T
F
−
8
UTF-8
UTF−8编码需要多个字节。而文件里的英文字符每一个只需要一个字节来存储,所以你可能会产生这样的误解:
s
e
e
k
(
)
seek()
seek()和
r
e
a
d
(
)
read()
read()方法对相同的目标计数。而实际上,只有对部分字符的情况是这样的。
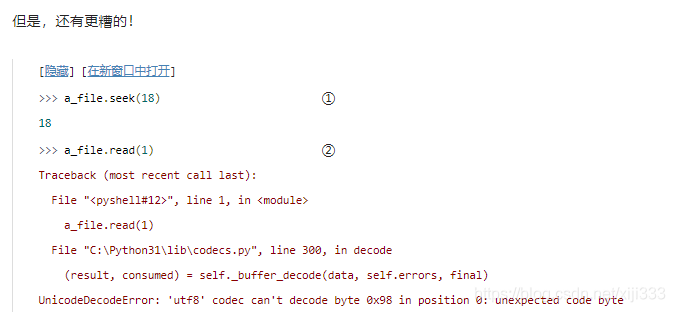
定位到第
18
18
18个字节,然后试图读取一个字符。
为什么这里会失败?因为在第
18
18
18个字节处不存在字符。距离此处最近的字符从第
17
17
17个字节开始(长度为三个字节)。试图从一个字符的中间位置读取会导致程序以
U
n
i
c
o
d
e
D
e
c
o
d
e
E
r
r
o
r
UnicodeDecodeError
UnicodeDecodeError错误失败。
1.4 关闭文件
打开文件会占用系统资源,根据文件的打开模式不同,其他的程序也许不能够访问它们。当已经完成了对文件的操作后就立即关闭它们,这很重要。

然而,这还不够。流对象
a
_
f
i
l
e
a\_file
a_file仍然存在;调用
c
l
o
s
e
(
)
close()
close()方法并没有把对象本身销毁。所以这并不是非常有效。
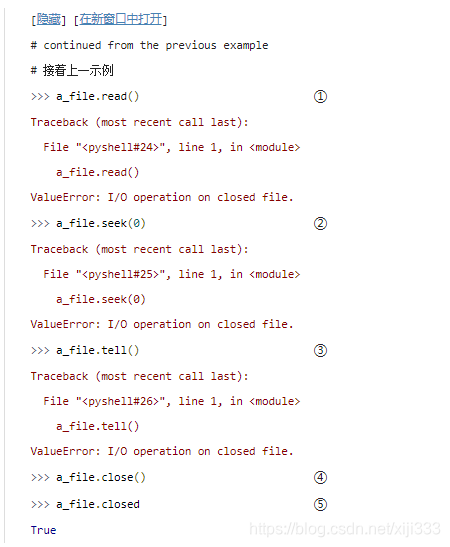
不能读取已经关闭了的文件;那样会引发一个
I
O
E
r
r
o
r
IOError
IOError异常。
也不能对一个已经关闭了的文件执行定位操作。
由于文件已经关闭了,所以也就不存在所谓当前的位置了,所以
t
e
l
l
(
)
tell()
tell()也会失败。
也许你会有些意外,文件已经关闭,调用原来流对象的
c
l
o
s
e
(
)
close()
close()方法并没有引发异常。其实那只是一个空操作(
n
o
−
o
p
no-op
no−op)而已。
已经关闭了的流对象确实还有一个有用的属性:
c
l
o
s
e
d
closed
closed,用来确认文件是否已经被关闭了。
1.5 自动关闭文件
流对象有一个显式的
c
l
o
s
e
(
)
close()
close()方法,但是如果代码有缺陷,在调用
c
l
o
s
e
(
)
close()
close()方法以前就崩溃了呢?理论上,那个文件会在相当长的一段时间内一直打开着,这是没有必要地。当你在自己的机器上调试的时候,这不算什么大问题。但是当这种代码被移植到服务器上运行,也许就得三思了。
对于这种情况,
P
y
t
h
o
n
2
Python 2
Python2有一种解决办法:
t
r
y
.
.
f
i
n
a
l
l
y
try..finally
try..finally块。这种方法在
P
y
t
h
o
n
3
Python 3
Python3里仍然有效,也许你可以在其他人的代码,或者从比较老的被移植到
P
y
t
h
o
n
3
Python 3
Python3的代码中看到它。但是
P
y
t
h
o
n
2.5
Python 2.5
Python2.5引入了一种更加简洁的解决方案,并且
P
y
t
h
o
n
3
Python 3
Python3将它作为首选方案:
w
i
t
h
with
with语句。

这段代码调用了
o
p
e
n
(
)
open()
open()函数,但是它却一直没有调用
a
_
f
i
l
e
.
c
l
o
s
e
(
)
a\_file.close()
a_file.close()。
w
i
t
h
with
with语句引出一个代码块,就像
i
f
if
if语句或者
f
o
r
for
for循环一样。在这个代码块里,你可以使用变量
a
_
f
i
l
e
a\_file
a_file作为
o
p
e
n
(
)
open()
open()函数返回的流对象的引用。所以流对象的常规方法都是可用的 —
s
e
e
k
(
)
seek()
seek(),
r
e
a
d
(
)
read()
read(),无论你想要调用什么。当
w
i
t
h
with
with块结束时,
P
y
t
h
o
n
Python
Python自动调用
a
_
f
i
l
e
.
c
l
o
s
e
(
)
a\_file.close()
a_file.close()。
这就是它与众不同的地方:无论你以何种方式跳出
w
i
t
h
with
with块,
P
y
t
h
o
n
Python
Python会自动关闭那个文件…即使是因为未处理的异常而
e
x
i
t
exit
exit。是的,即使代码中引发了一个异常,整个程序突然中止了,
P
y
t
h
o
n
Python
Python也能够保证那个文件能被关闭掉。
从技术上说,
w
i
t
h
with
with语句创建了一个运行时环境(
r
u
n
t
i
m
e
c
o
n
t
e
x
t
runtime\ context
runtime context)。在这几个样例中,流对象的行为就像一个上下文管理器(
c
o
n
t
e
x
t
m
a
n
a
g
e
r
context\ manager
context manager)。
P
y
t
h
o
n
Python
Python创建了
a
_
f
i
l
e
a\_file
a_file,并且告诉它正进入一个运行时环境。当
w
i
t
h
with
with块结束的时候,
P
y
t
h
o
n
Python
Python告诉流对象它正在退出这个运行时环境,然后流对象就会调用它的
c
l
o
s
e
(
)
close()
close()方法。
w
i
t
h
with
with语句不只是针对文件而言的;它是一个用来创建运行时环境的通用框架(
g
e
n
e
r
i
c
f
r
a
m
e
w
o
r
k
generic\ framework
generic framework),告诉对象它们正在进入和离开一个运行时环境。如果该对象是流对象,那么它就会做一些类似文件对象一样有用的动作(就像自动关闭文件)。但是那个行为是被流对象自身定义的,而不是在
w
i
t
h
with
with语句中。还有许多跟文件无关的使用上下文管理器(
c
o
n
t
e
x
t
m
a
n
a
g
e
r
context\ manager
context manager)的方法。在这章的后面可以看到,你甚至可以自己创建它们。
1.6 一次读取一行数据
正如你所想的,一行数据就是这样 — 输入一些单词,按
E
N
T
E
R
ENTER
ENTER键,然后就在新的一行了。一行文本就是一串被某种东西分隔的字符,到底是被什么分隔的呢?好吧,这有些复杂,因为文本文件可以使用几个不同的字符来标记行末(
e
n
d
o
f
a
l
i
n
e
end\ of\ a\ line
end of a line)。每种操作系统都有自己的规矩。有一些使用回车符(
c
a
r
r
i
a
g
e
r
e
t
u
r
n
carriage\ return
carriage return),另外一些使用换行符(
l
i
n
e
f
e
e
d
line\ feed
line feed),还有一些在行末同时使用这两个字符来标记。
其实你可以舒口气了,因为
P
y
t
h
o
n
Python
Python默认会自动处理行的结束符。如果你告诉它,“我想从这个文本文件一次读取一行,”
P
y
t
h
o
n
Python
Python自己会弄明白这个文本文件到底使用哪种方式标记新行,然后正确工作。
如果想要细粒度地控制(
f
i
n
e
−
g
r
a
i
n
e
d
c
o
n
t
r
o
l
fine-grained control
fine−grainedcontrol)使用哪种行标记符,你可以传递一个可选的参数
n
e
w
l
i
n
e
newline
newline给
o
p
e
n
(
)
open()
open()函数。
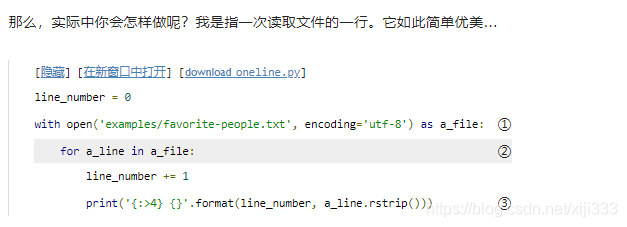
使用
w
i
t
h
with
with语句,安全地打开这个文件,然后让
P
y
t
h
o
n
Python
Python为你关闭它。
为了一次读取文件的一行,使用
f
o
r
for
for循环。是的,除了像
r
e
a
d
(
)
read()
read()这样显式的方法,流对象也是一个迭代器(
i
t
e
r
a
t
o
r
iterator
iterator),它能在你每次请求一个值时分离出单独的一行。
使用字符串的
f
o
r
m
a
t
(
)
format()
format()方法,你可以打印出行号和行自身。格式说明符
{
:
>
4
}
\{:>4\}
{:>4}的意思是“使用最多四个空格使之右对齐,然后打印此参数。”变量
a
_
l
i
n
e
a\_line
a_line是包括回车符等在内的完整的一行。字符串方法
r
s
t
r
i
p
(
)
rstrip()
rstrip()可以去掉尾随的空白符,包括回车符。
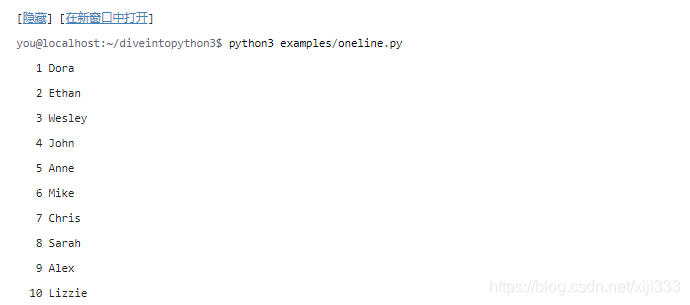
2.写入文本文件
写入文件的方式和从它们那儿读取很相似。首先打开一个文件,获取流对象,然后你调用一些方法作用在流对象上来写入数据到文件,最后关闭文件。
为了写入而打开一个文件,可以使用
o
p
e
n
(
)
open()
open()函数,并且指定写入模式。有两种文件模式用于写入:

如果文件不存在,两种模式下都会自动创建新文件。所以,只需要打开一个文件,然后开始写入即可。
在完成写入后你应该马上关闭文件,释放文件句柄(
f
i
l
e
h
a
n
d
l
e
file\ handle
file handle),并且保证数据被完整地写入到了磁盘。跟读取文件一样,可以调用流对象的
c
l
o
s
e
(
)
close()
close()方法,或者你也可以使用
w
i
t
h
with
with语句让
P
y
t
h
o
n
Python
Python为你关闭文件。我敢打赌,你肯定能猜到我推荐哪种方案。
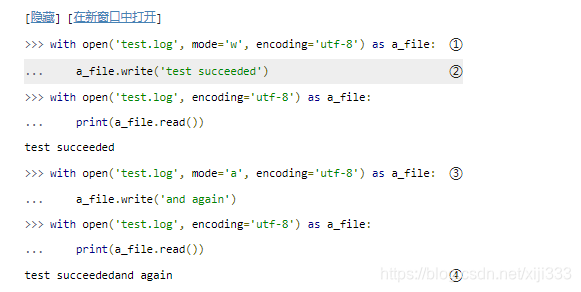
大胆地创建新文件
t
e
s
t
.
l
o
g
test.log
test.log(或者重写已经存在的文件),参数
m
o
d
e
=
mode=
mode=’w’的意思是文件以写入的模式打开。是的,这听起来似乎比较危险。我希望你确定不再关心那个文件以前的内容(如果有的话),因为之前的数据已经没了。
你可以通过
o
p
e
n
(
)
open()
open()函数返回的流对象的
w
r
i
t
e
(
)
write()
write()方法来给新打开的文件添加数据。当
w
i
t
h
with
with块结束的时候,
P
y
t
h
o
n
Python
Python自动关闭文件。
多么有趣,我们再试一次。这一次,使用
m
o
d
e
=
mode=
mode=’a’参数来添加数据到文件末尾,而不是重写它。追加模式绝不会破坏现有文件的内容。
原来写入的行,还有追加上去的第二行现在都在文件test.log里了。同时请注意,回车符没有被包括进去。你可以通过’\n’写入一个回车符。由于一开始没有这样做,所以写入到文件的数据现在都在同一行。
2.1再次讨论字符编码
你是否注意到当你在打开文件用于写入数据的时候传递给 o p e n ( ) open() open()函数的 e n c o d i n g encoding encoding参数。它“非常重要”,不要忽略了!就如你在这章开头看到的,文件中并不存在字符串,它们由字节组成。只有当你告诉 P y t h o n Python Python使用何种编码方式把字节流转换为字符串,从文件读取“字符串”才成为可能。相反地,写入文本到文件面临同样的问题。实际上你不能直接把字符写入到文件;字符只是一种抽象。为了写入字符到文件, P y t h o n Python Python需要知道如何将字符串转换为字节序列。唯一能保证正确地执行转换的方法就是当你为写入而打开一个文件的时候,指定 e n c o d i n g encoding encoding参数。
3.二进制文件
不是所有的文件都包含文本内容。有一些还包含了我可爱的狗的照片。

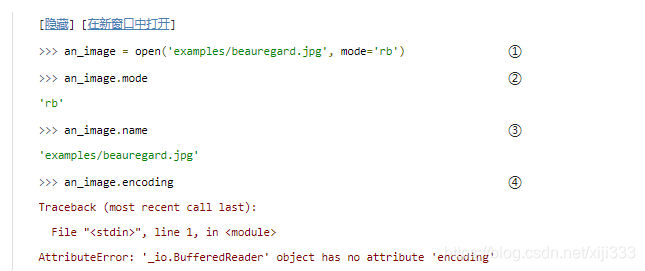
用二进制模式打开文件很简单,但是很精细。与文本模式唯一不同的是
m
o
d
e
mode
mode参数多包含一个字符’b’(
b
i
n
a
r
y
binary
binary)。
以二进制模式打开文件得到的流对象与之前的有很多相同的属性,包括
m
o
d
e
mode
mode属性,它记录了你调用
o
p
e
n
(
)
open()
open()函数时指定的
m
o
d
e
mode
mode参数的值。
二进制文件的流对象也有
n
a
m
e
name
name属性,就如文本文件的流对象一样。
然而,确实有不同之处:二进制的流对象没有
e
n
c
o
d
i
n
g
encoding
encoding属性。你能明白其中的道理的,对吧?现在你读写的是字节,而不是字符串,所以
P
y
t
h
o
n
Python
Python不需要做转换工作。从二进制文件里读出的跟你所写入的是完全一样的,所以没有执行转换的必要。
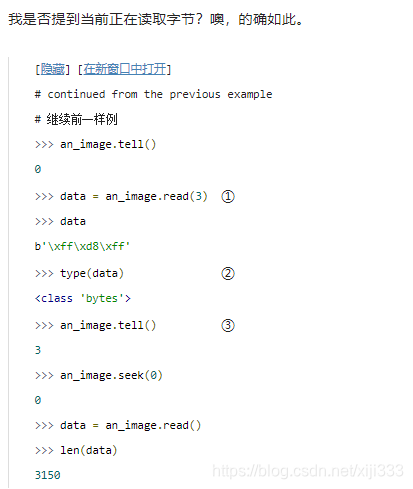
跟读取文本文件一样,你也可以从二进制文件一次读一点儿。但是它们之间有一个重大的不同之处:你正在读取字节,而不是字符串。
同时由于你以二进制模式打开文件,
r
e
a
d
(
)
read()
read()方法每次读取指定的字节数,而非字符数。
这就意味着,你传递给
r
e
a
d
(
)
read()
read()方法的数目和你从
t
e
l
l
(
)
tell()
tell()方法得到的位置序号不会出现意料之外的不匹配。
4.非文件来源的流对象
想象一下你正在编写一个库(
l
i
b
r
a
r
y
library
library),其中有一库函数用来从文件读取数据。它使用文件名作为参数,以只读的方式打开文件,读取数据,关闭文件,返回。但是你不应该只做到这个程度。你的
a
p
i
api
api应该能够接纳任意的类型的流对象。
最简单的情况,只要对象包含
r
e
a
d
(
)
read()
read()方法,这个方法使用一个可选参数
s
i
z
e
size
size并且返回值为一个串,它就是是流对象。不使用
s
i
z
e
size
size参数调用
r
e
a
d
(
)
read()
read()的时候,这个方法应该从输入源读取所有可读的信息然后以单独的一个值返回所有数据。当使用
s
i
z
e
size
size参数调用
r
e
a
d
(
)
read()
read()时,它从输入源读取并返回指定量的数据。当再一次被调用时,它从上一次离开的地方开始读取并返回下一个数据块。
这听起来跟你从打开一个真实文件得到的流对象一样。不同之处在于你不再受限于真实的文件。能够“读取”的输入源可以是任何东西:网页,内存中的字符串,甚至是另外一个程序的输出。只要你的函数使用的是流对象,调用对象的
r
e
a
d
(
)
read()
read()方法,你可以处理任何行为与文件类似的输入源,而不需要为每种类型的输入指定特别的代码。

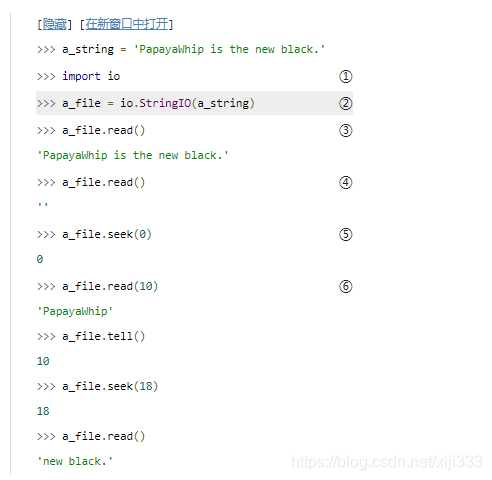
i
o
io
io模块定义了
S
t
r
i
n
g
I
O
StringIO
StringIO类,你可以使用它来把内存中的字符串当作文件来处理。
为了从字符串创建一个流对象,可以把想要作为“文件”使用的字符串传递给
i
o
.
S
t
r
i
n
g
I
O
(
)
io.StringIO()
io.StringIO()来创建一个
S
t
r
i
n
g
I
O
StringIO
StringIO的实例。
调用
r
e
a
d
(
)
read()
read()方法“读取”整个“文件”,以
S
t
r
i
n
g
I
O
StringIO
StringIO对象为例即返回原字符串。
就像一个真实的文件一样,再次调用
r
e
a
d
(
)
read()
read()方法返回一个空串。
通过使用
S
t
r
i
n
g
I
O
StringIO
StringIO对象的
s
e
e
k
(
)
seek()
seek()方法,你可以显式地定位到字符串的开头,就像在一个真实的文件中定位一样。
通过传递
s
i
z
e
size
size参数给
r
e
a
d
(
)
read()
read()方法,你也可以以数据块的形式读取字符串。
i
o
.
S
t
r
i
n
g
I
O
io.StringIO
io.StringIO让你能够将一个字符串作为文本文件来看待。另外还有一个
i
o
.
B
y
t
e
I
O
io.ByteIO
io.ByteIO类,它允许你将字节数组当做二进制文件来处理。
4.1处理压缩文件
P
y
t
h
o
n
Python
Python标准库包含支持读写压缩文件的模块。有许多种不同的压缩方案;其中,
g
z
i
p
gzip
gzip和
b
z
i
p
2
bzip2
bzip2是非
W
i
n
d
o
w
s
Windows
Windows操作系统下最流行的两种压缩方式。
g
z
i
p
gzip
gzip模块允许你创建用来读写
g
z
i
p
gzip
gzip压缩文件的流对象。该流对象支持
r
e
a
d
(
)
read()
read()方法(如果你以读取模式打开)或者
w
r
i
t
e
(
)
write()
write()方法(如果你以写入模式打开)。这就意味着,你可以使用从普通文件那儿学到的技术来直接读写
g
z
i
p
gzip
gzip压缩文件,而不需要创建临时文件来保存解压缩了的数据。
作为额外的功能,它也支持
w
i
t
h
with
with语句,所以当你完成了对
g
z
i
p
gzip
gzip压缩文件的操作,
P
y
t
h
o
n
Python
Python可以为你自动关闭它。
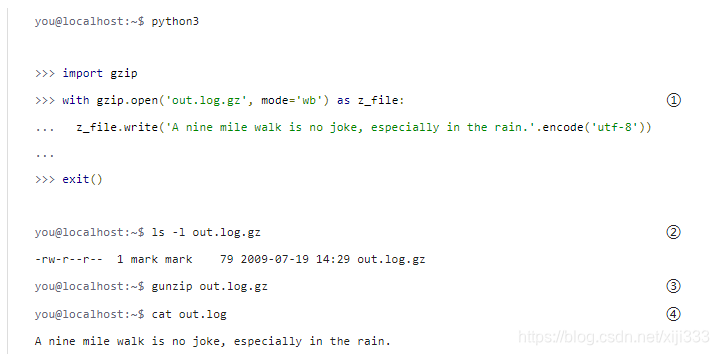
你应该以二进制模式打开
g
z
i
p
gzip
gzip压缩文件(注意
m
o
d
e
mode
mode参数里的’b’字符)。
我在
L
i
n
u
x
Linux
Linux系统上完成的这个例子。如果你对命令行不熟悉,这条命令用来显示刚才你在
P
y
t
h
o
n
s
h
e
l
l
Python\ shell
Python shell创建的
g
z
i
p
gzip
gzip压缩文件的“长清单(
l
o
n
g
l
i
s
t
i
n
g
s
long\ listings
long listings)”,你可以看到,它有
79
79
79个字节长。而实际上这个值比一开始的字符串还要长!由于
g
z
i
p
gzip
gzip文件包括了一个固定长度的文件头来存放一些关于文件的元数据(
m
e
t
a
d
a
t
a
metadata
metadata),所以它对于极小的文件来说效率不高。
g
u
n
z
i
p
gunzip
gunzip命令(发音:“gee-unzip”)解压缩文件然后保存其内容到一个与原来压缩文件同名的新文件中,并去掉其
.
g
z
.gz
.gz扩展名。
c
a
t
cat
cat命令显示文件的内容。当前文件包含了原来你从
P
y
t
h
o
n
s
h
e
l
l
Python\ shell
Python shell直接写入到压缩文件
o
u
t
.
l
o
g
.
g
z
out.log.gz
out.log.gz的那个字符串。
5.标准输入、输出和错误
命令行高手已经对标准输入,标准输出和标准错误的概念相当熟悉了。这部分内容是对另一部分还不熟悉的人员准备的。
标准输出和标准错误(通常缩写为
s
t
d
o
u
t
stdout
stdout和
s
t
d
e
r
r
stderr
stderr)是被集成到每一个类
U
N
I
X
UNIX
UNIX操作系统中的两个管道(
p
i
p
e
pipe
pipe),包括
M
a
c
O
S
X
Mac\ OS\ X
Mac OS X和
L
i
n
u
x
Linux
Linux。当你调用
p
r
i
n
t
(
)
print()
print()的时候,需要打印的内容即被发送到
s
t
d
o
u
t
stdout
stdout管道。当你的程序出错并且需要打印跟踪信息(
t
r
a
c
e
b
a
c
k
traceback
traceback)时,它们被发送到
s
t
d
e
r
r
stderr
stderr管道。默认地,这两个管道都被连接到你正在工作的终端窗口上(
t
e
r
m
i
n
a
l
w
i
n
d
o
w
terminal\ window
terminal window);当你的程序打印某些东西,你可以在终端上看到这些输出,当程序出错,你也可以从终端上看到这些错误信息。在图形化的
P
y
t
h
o
n
s
h
e
l
l
Python\ shell
Python shell里,
s
t
d
o
u
t
stdout
stdout和
s
t
d
e
r
r
stderr
stderr管道默认连接到交互式窗口(
I
n
t
e
r
a
c
t
i
v
e
W
i
n
d
o
w
Interactive\ Window
Interactive Window)。

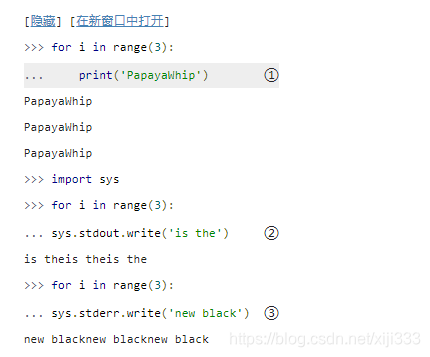
s
t
d
o
u
t
stdout
stdout被定义在
s
y
s
sys
sys模块里,它是一个流对象(
s
t
r
e
a
m
o
b
j
e
c
t
stream\ object
stream object)。使用任意字符串调用其
w
r
i
t
e
(
)
write()
write()函数会按原样输出。事实上,这就是
p
r
i
n
t
(
)
print()
print()函数实际在做的事情;它在串的结尾添加一个回车符,然后调用
s
y
s
.
s
t
d
o
u
t
.
w
r
i
t
e
sys.stdout.write
sys.stdout.write。
最简单的情况下,
s
y
s
.
s
t
d
o
u
t
sys.stdout
sys.stdout和
s
y
s
.
s
t
d
e
r
r
sys.stderr
sys.stderr把他们的输出发送到同一个位置:
P
y
t
h
o
n
i
d
e
Python\ ide
Python ide(如果你在那里执行操作),或者终端(如果你从命令行执行
P
y
t
h
o
n
Python
Python指令)。跟标准输出一样,标准错误也不会自动为你添加回车符。如果你需要回车符,你需要手工写入回车符到标准错误。

5.1标准输出重定向
s
y
s
.
s
t
d
o
u
t
sys.stdout
sys.stdout和
s
y
s
.
s
t
d
e
r
r
sys.stderr
sys.stderr都是流对象,尽管他们只支持写入。但是他们是变量而不是常量。这就意味着你可以给它们赋上新值 — 任意其他流对象 — 来重定向他们的输出。
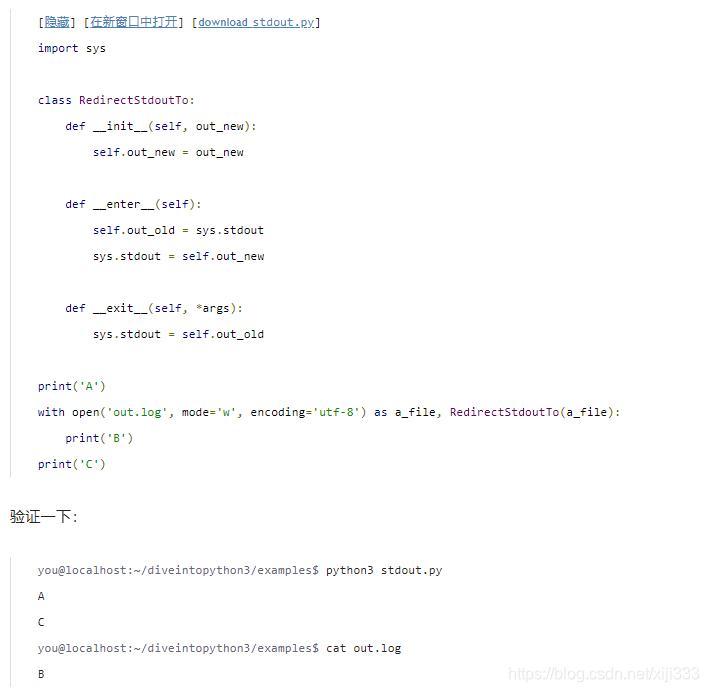

正如改动后的代码所展示的,实际上你使用了两个
w
i
t
h
with
with语句,其中一个嵌套在另外一个的作用域(
s
c
o
p
e
scope
scope)里。“外层的”
w
i
t
h
with
with语句你应该已经熟悉了:它打开一个使用
u
t
f
−
8
utf-8
utf−8编码的叫做
o
u
t
.
l
o
g
out.log
out.log的文本文件用来写入,然后把返回的流对象赋给一个叫做
a
_
f
i
l
e
a\_file
a_file的变量。但是,内层的
w
i
t
h
with
with语句呢?

a
s
as
as子句到哪里去了?其实
w
i
t
h
with
with语句并不一定需要
a
s
as
as子句。就像你调用一个函数然后忽略其返回值一样,你也可以不把
w
i
t
h
with
with语句的上下文环境赋给一个变量。在这种情况下,我们只关心
R
e
d
i
r
e
c
t
S
t
d
o
u
t
T
o
RedirectStdoutTo
RedirectStdoutTo上下文环境的边际效应(
s
i
d
e
e
f
f
e
c
t
side\ effect
side effect)。
那么,这些边际效应都是些什么呢?我们来看一看
R
e
d
i
r
e
c
t
S
t
d
o
u
t
T
o
RedirectStdoutTo
RedirectStdoutTo类的内部结构。这是一个用户自定义的上下文管理器(
c
o
n
t
e
x
t
m
a
n
a
g
e
r
context\ manager
context manager)。任何类只要定义了两个特殊方法:
_
_
e
n
t
e
r
_
_
(
)
\_\_enter\_\_()
__enter__()和
_
_
e
x
i
t
_
_
(
)
\_\_exit\_\_()
__exit__()就可以变成上下文管理器。

在实例被创建后
_
_
i
n
i
t
_
_
(
)
\_\_init\_\_()
__init__()方法马上被调用。它使用一个参数,即在上下文环境的生命周期内你想用做标准输出的流对象。这个方法只是把该流对象保存在一个实例变量里(
i
n
s
t
a
n
c
e
v
a
r
i
a
b
l
e
instance\ variable
instance variable)以使其他方法在后边能够使用到它。
_
_
e
n
t
e
r
_
_
(
)
\_\_enter\_\_()
__enter__()方法是一个特殊的类方法;在进入一个上下文环境时
P
y
t
h
o
n
Python
Python会调用它(即,在
w
i
t
h
with
with语句的开始处)。该方法把当前
s
y
s
.
s
t
d
o
u
t
sys.stdout
sys.stdout的值保存在
s
e
l
f
.
o
u
t
_
o
l
d
self.out\_old
self.out_old内,然后通过把
s
e
l
f
.
o
u
t
_
n
e
w
self.out\_new
self.out_new赋给
s
y
s
.
s
t
d
o
u
t
sys.stdout
sys.stdout来重定向标准输出。
_
_
e
x
i
t
_
_
(
)
\_\_exit\_\_()
__exit__()是另外一个特殊类方法;当离开一个上下文环境时(即,在
w
i
t
h
with
with语句的末尾)
P
y
t
h
o
n
Python
Python会调用它。这个方法通过把保存的
s
e
l
f
.
o
u
t
_
o
l
d
self.out\_old
self.out_old的值赋给
s
y
s
.
s
t
d
o
u
t
sys.stdout
sys.stdout来恢复标准输出到原来的状态。
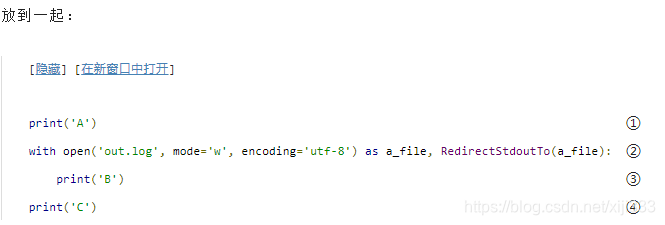
A
A
A会输出到
i
d
e
ide
ide的交互式窗口(或者终端,如果你从命令行运行这段脚本)。
这条
w
i
t
h
with
with语句使用逗号分隔的上下文环境列表。这个列表就像一系列相互嵌套的
w
i
t
h
with
with块。先列出的是“外层”的块;后列出的是“内层”的块。第一个上下文环境打开一个文件;第二个重定向
s
y
s
.
s
t
d
o
u
t
sys.stdout
sys.stdout到由第一个上下环境创建的流对象。
由于第二个
p
r
i
n
t
(
)
print()
print()函数在
w
i
t
h
with
with语句创建的上下文环境里执行,所以它不会输出到屏幕;它会写入到文件
o
u
t
.
l
o
g
out.log
out.log。
w
i
t
h
with
with语句块结束了。
P
y
t
h
o
n
Python
Python告诉每一个上下文管理器完成他们应该在离开上下文环境时应该做的事。这些上下文环境形成一个后进先出的栈。当离开一个上下文环境的时候,第二个上下文环境将
s
y
s
.
s
t
d
o
u
t
sys.stdout
sys.stdout的值恢复到它的原来状态,然后第一个上下文环境关闭那个叫做
o
u
t
.
l
o
g
out.log
out.log的文件。由于标准输出已经被恢复到原来的状态,再次调用
p
r
i
n
t
(
)
print()
print()函数会马上输出到屏幕上。
重定向标准错误的原理跟这个完全一样,将
s
y
s
.
s
t
d
o
u
t
sys.stdout
sys.stdout替换为
s
y
s
.
s
t
d
e
r
r
sys.stderr
sys.stderr即可。
整个流程看下来,我们也知道了为撒第二个
w
i
t
h
with
with语句没有
a
s
as
as字句,因为没有必要,这个对象的所有方法都是自动调用的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









