







文章目录
0.摘要
通过一个例子逐步了解高级迭代器、 z i p ( ) zip() zip()、 t r a n s l a t e ( ) translate() translate()、 e v a l ( ) eval() eval()的用法。
1.字母算数
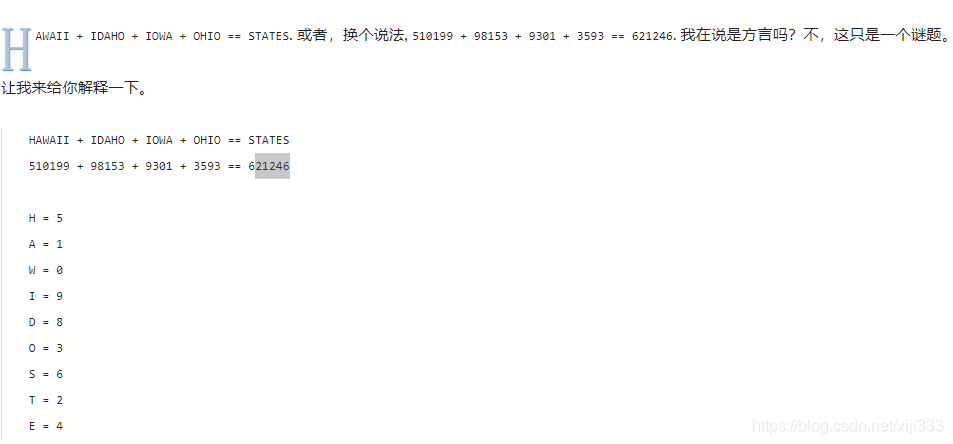
像这样的谜题被称为
c
r
y
p
t
a
r
i
t
h
m
s
cryptarithms
cryptarithms 或者 字母算术(
a
l
p
h
a
m
e
t
i
c
s
alphametics
alphametics)。字母可以拼出实际的单词,而如果你把每一个字母都用
0
–
9
中
0–9中
0–9中的某一个数字代替后, 也同样可以拼出 一个算术等式。关键的地方是找出每个字母都映射到了哪个数字。每个字母所有出现的地方都必须映射到同一个数字,数字不能重复, 并且单词不能以
0
0
0开始。
在这一章中,我们将深入一个最初由
R
a
y
m
o
n
d
H
e
t
t
i
n
g
e
r
Raymond\ Hettinger
Raymond Hettinger编写的难以置信的
P
y
t
h
o
n
Python
Python程序。这个程序只用
14
14
14行代码来解决字母算术谜题。
import re
import itertools
def solve(puzzle):
words = re.findall('[A-Z]+', puzzle.upper())
unique_characters = set(''.join(words))
assert len(unique_characters) <= 10, 'Too many letters'
first_letters = {word[0] for word in words}
n = len(first_letters)
sorted_characters = ''.join(first_letters) + \
''.join(unique_characters - first_letters)
characters = tuple(ord(c) for c in sorted_characters)
digits = tuple(ord(c) for c in '0123456789')
zero = digits[0]
for guess in itertools.permutations(digits, len(characters)):
if zero not in guess[:n]:
equation = puzzle.translate(dict(zip(characters, guess)))
if eval(equation):
return equation
if __name__ == '__main__':
import sys
for puzzle in sys.argv[1:]:
print(puzzle)
solution = solve(puzzle)
if solution:
print(solution)
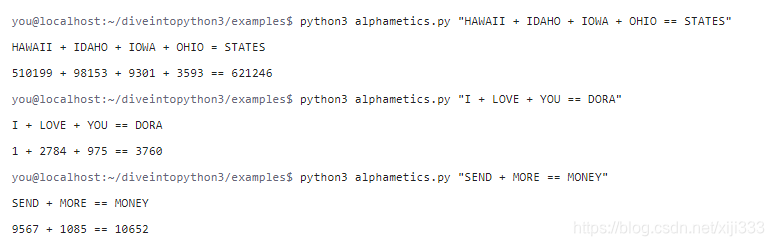
你可以从命令行运行这个程序。在
L
i
n
u
x
Linux
Linux上, 运行情况看起来是这样的。(取决于你机器的速度,计算可能要花一些时间,而且不会有进度条,耐心等待就好了)
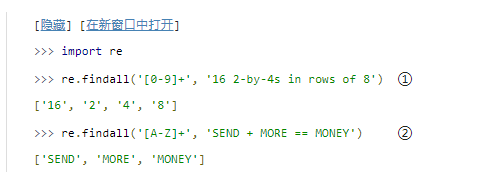
2.找到一个模式所有出现的地方
字母算术谜题解决者做的第一件事是找到谜题中所有的字母(
A
–
Z
A–Z
A–Z)。
r
e
re
re 模块是正则表达式的
P
y
t
h
o
n
Python
Python实现。它有一个漂亮的函数
f
i
n
d
a
l
l
(
)
findall()
findall(),接受一个正则表达式和一个字符串作为参数,然后找出字符串中出现该模式的所有地方。
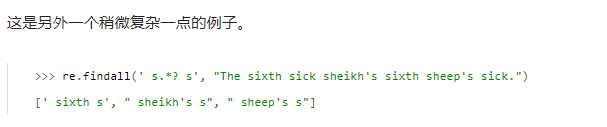
这个正则表达式寻找一个空格,一个
s
s
s, 然后是最短的任何字符构成的序列
(
.
∗
?
)
(.*?)
(.∗?), 然后是一个空格, 然后是另一个
s
s
s。 在输入字符串中,我看见了五个匹配:

但是 r e . f i n d a l l ( ) re.findall() re.findall()函数值只返回了 3 3 3个匹配。准确的说,它返回了第一,第三和第五个。为什么呢?因为它不会返回重叠的匹配。
3.在序列中寻找不同的元素
集合使得在序列中查找不同的元素变得很简单。

s
e
t
(
)
set()
set()函数返回列表中不同的字符串组成的集合。把它想象成一个
f
o
r
for
for循环可以帮助理解。同样的技术也适用于字符串,因为一个字符串就是一个字符序列。
给出一个字符串列表,
′
′
.
j
o
i
n
(
a
_
l
i
s
t
)
''.join(a\_list)
′′.join(a_list)将所有的字符串拼接成一个。
所以我们可以很容易的得到谜题中出现的不同字符的集合。

4.作出断言

a
s
s
e
r
t
assert
assert 语句后面跟任何合法的
P
y
t
h
o
n
Python
Python 表达式。在这个例子里, 表达式
1
+
1
=
=
2
1 + 1 == 2
1+1==2 的求值结果为
T
r
u
e
True
True, 所以
a
s
s
e
r
t
assert
assert 语句没有做任何事情。
然而, 如果
P
y
t
h
o
n
Python
Python表达式求值结果为
F
a
l
s
e
False
False,
a
s
s
e
r
t
assert
assert 语句会抛出一个
A
s
s
e
r
t
i
o
n
E
r
r
o
r
AssertionError
AssertionError。
你可以额外提供一条消息,当异常被抛出时这条消息会被打印出来。
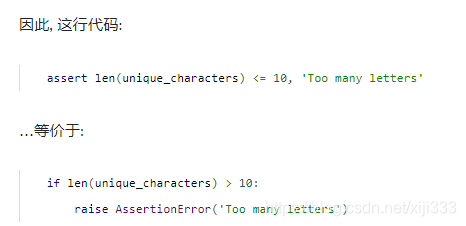
这很好理解,因为只有 [ 0 − 9 ] 10 [0-9]10 [0−9]10个数字。
5.生成器表达式
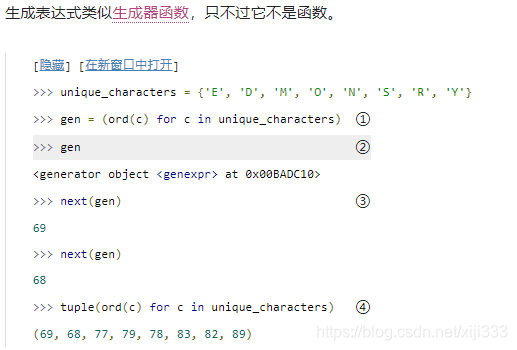
o
r
d
(
)
ord()
ord()函数是内置函数,传入一个字符会返回它的整数值。①是一个生成器表达式,它类似一个返回
y
i
e
l
d
yield
yield的匿名函数,看起来很像列表解析,不过列表解析是用方括号括起来的。
生成器表达式返回迭代器。调用
n
e
x
t
(
g
e
n
)
next(gen)
next(gen) 返回迭代器的下一个值。
你可以将生成器表达式传给
t
u
p
l
e
(
)
tuple()
tuple(),
l
i
s
t
(
)
list()
list(), 或者
s
e
t
(
)
set()
set()来迭代所有的值并且返回元组,列表或者集合。在这种情况下,你不需要一对额外的括号 — 将生成器表达式
o
r
d
(
c
)
f
o
r
c
i
n
u
n
i
q
u
e
_
c
h
a
r
a
c
t
e
r
s
ord(c)\ for\ c\ in\ unique\_characters
ord(c) for c in unique_characters 传给
t
u
p
l
e
(
)
tuple()
tuple() 函数就可以了,
P
y
t
h
o
n
Python
Python 会推断出它是一个生成器表达式。
使用生成器表达式取代列表解析可以同时节省
c
p
u
cpu
cpu 和 内存(
r
a
m
ram
ram)。如果你构造一个列表的目的仅仅是传递给别的函数,用生成器表达式替代吧!

6.计算排列… 懒惰的方法!
想法是这样的,你有某物件(可以是数字,可以是字母,也可以是跳舞的熊)的一个列表,接着找出将它们拆开然后组合成小一点的列表的所有可能。所有的小列表的大小必须一致。最小是1,最大是元素的总数目。哦,也不能有重复。数学家说“让我们找出3个元素取2个的排列,” 意思是你有一个3个元素的序列,然后你找出所有可能的有序对。

i
t
e
r
t
o
o
l
s
itertools
itertools模块里有各种各样的有趣的东西,包括
p
e
r
m
u
t
a
t
i
o
n
s
(
)
permutations()
permutations()函数,它把查找排列的所有辛苦的工作的做了。
p
e
r
m
u
t
a
t
i
o
n
s
(
)
permutations()
permutations() 函数接受一个序列(这里是3个数字组成的列表) 和一个表示你要的排列的元素的数目的数字。函数返回迭代器,你可以在
f
o
r
for
for 循环或其他老地方使用它。这里我遍历迭代器来显示所有的值。
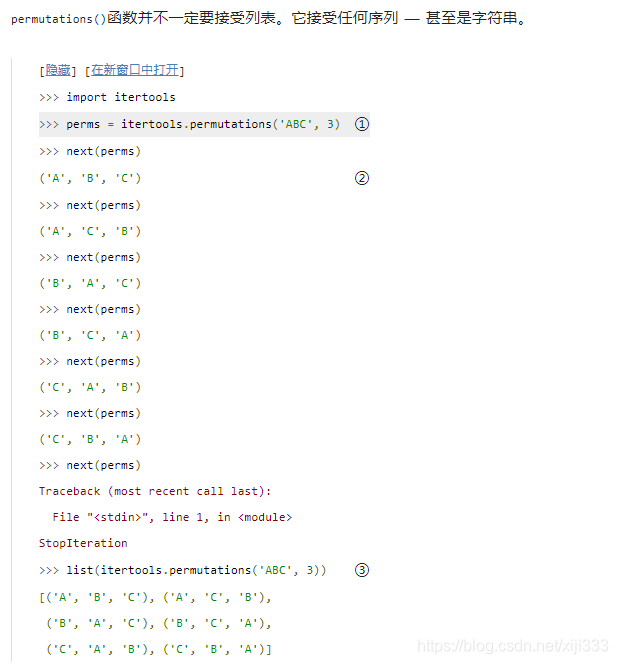
字符串就是一个字符序列。对于查找排列来说,字符串’ABC’和列表 [‘A’, ‘B’, ‘C’]是等价的。
7.itertools模块中的其它有趣的东西

i
t
e
r
t
o
o
l
s
.
p
r
o
d
u
c
t
(
)
itertools.product()
itertools.product()函数返回包含两个序列的笛卡尔乘积的迭代器。
i
t
e
r
t
o
o
l
s
.
c
o
m
b
i
n
a
t
i
o
n
s
(
)
itertools.combinations()
itertools.combinations()函数返回包含给定序列的给定长度的所有组合的迭代器。这和
i
t
e
r
t
o
o
l
s
.
p
e
r
m
u
t
a
t
i
o
n
s
(
)
itertools.permutations()
itertools.permutations()函数很类似,除了不包含因为只有顺序不同而重复的情况。所以
i
t
e
r
t
o
o
l
s
.
p
e
r
m
u
t
a
t
i
o
n
s
(
′
A
B
C
′
,
2
)
itertools.permutations('ABC', 2)
itertools.permutations(′ABC′,2)同时返回(‘A’, ‘B’) and (‘B’, ‘A’) (同其它的排列一起),
i
t
e
r
t
o
o
l
s
.
c
o
m
b
i
n
a
t
i
o
n
s
(
′
A
B
C
′
,
2
)
itertools.combinations('ABC', 2)
itertools.combinations(′ABC′,2) 不会返回(‘B’, ‘A’) ,因为它和(‘A’, ‘B’)是重复的,只是顺序不同而已。

字符串的
r
s
t
r
i
p
(
)
rstrip()
rstrip()方法可以移除字符串末尾的指定字符,默认是空格和换行。
s
o
r
t
e
d
(
)
sorted()
sorted()函数接受一个列表并返回排序后的列表。它也接受一个函数作为
k
e
y
key
key 参数, 并且使用
k
e
y
key
key来排序。在这个例子里,排序函数是
l
e
n
(
)
len()
len(),所以它按
l
e
n
(
e
a
c
h
i
t
e
m
)
len(each\ item)
len(each item)来排序。短的名字排在前面,然后是稍长,接着是更长的。
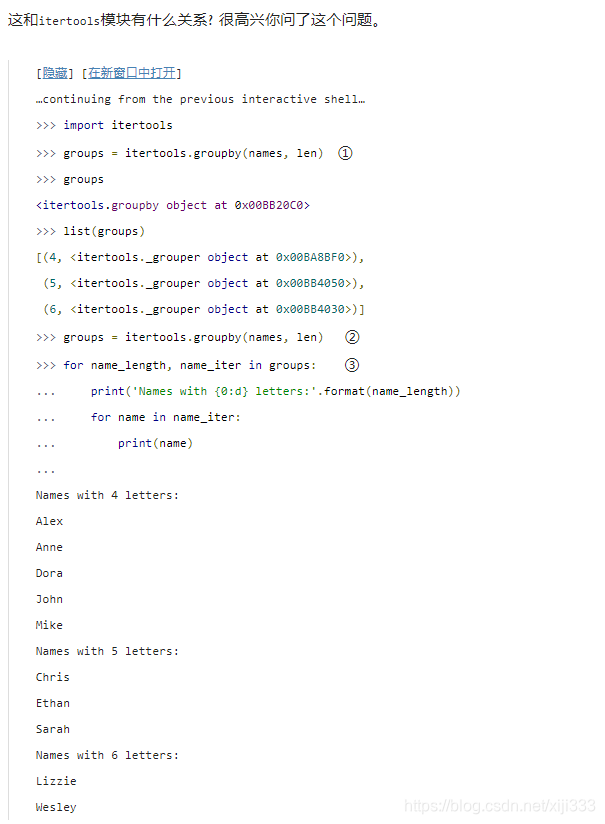
i
t
e
r
t
o
o
l
s
.
g
r
o
u
p
b
y
(
)
itertools.groupby()
itertools.groupby()函数接受一个序列和一个
k
e
y
key
key 函数, 并且返回一个生成二元组的迭代器。每一个二元组包含
k
e
y
_
f
u
n
c
t
i
o
n
(
e
a
c
h
i
t
e
m
)
key\_function(each\ item)
key_function(each item)的结果和另一个包含着所有共享这个
k
e
y
key
key结果的元素的迭代器。
调用
l
i
s
t
(
)
list()
list() 函数会“耗尽”这个迭代器, 也就是说 你生成了迭代器中所有元素才创造了这个列表。迭代器没有“重置”按钮。你一旦耗尽了它,就没法重新开始。如果你想要再循环一次(例如, 在接下去的
f
o
r
for
for循环里面), 你得调用
i
t
e
r
t
o
o
l
s
.
g
r
o
u
p
b
y
(
)
itertools.groupby()
itertools.groupby()来创建一个新的迭代器。
注意,
i
t
e
r
t
o
o
l
s
.
g
r
o
u
p
b
y
(
)
itertools.groupby()
itertools.groupby()只有当输入序列已经按分组函数排过序才能正常工作。
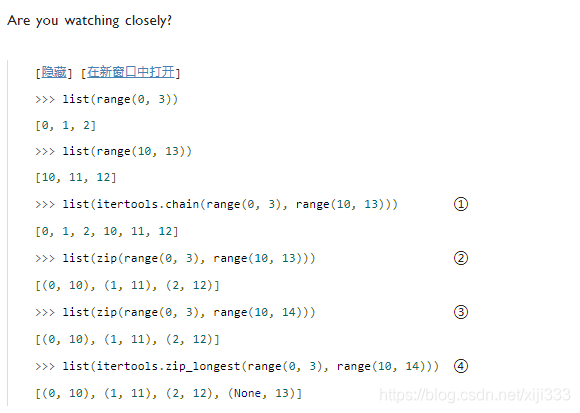
i
t
e
r
t
o
o
l
s
.
c
h
a
i
n
(
)
itertools.chain()
itertools.chain()函数接受两个迭代器,返回一个迭代器,它包含第一个迭代器的所有内容,以及跟在后面的来自第二个迭代器的所有内容(实际上,它接受任何数目的迭代器,并把它们按传入顺序串在一起)。
z
i
p
(
)
zip()
zip()函数接受任何数目的序列然后返回一个迭代器,其第一个元素是每个序列的第一个元素组成的元组,然后是每个序列的第二个元素(组成的元组),以此类推。它在到达最短的序列结尾的时候停止。
相反,
i
t
e
r
t
o
o
l
s
.
z
i
p
_
l
o
n
g
e
s
t
(
)
itertools.zip\_longest()
itertools.zip_longest()函数在到达最长的序列的结尾的时候才停止, 对短序列结尾之后的元素填入
N
o
n
e
None
None值。

给出一个字母列表和一个数字列表(两者的元素的形式都是1个字符的字符串),
z
i
p
zip
zip函数按顺序创建出字母、数字对。
为什么这很酷? 因为这个数据结构正好可以用来传递给
d
i
c
t
(
)
dict()
dict()函数来创建以字母为键,对应数字为值的字典。当然使用字典解析也可以。

8.一种新的操作字符串的方法
P
y
t
h
o
n
Python
Python 字符串有很多方法。我们在字符串章节中学习了其中一些:
l
o
w
e
r
(
)
lower()
lower(),
c
o
u
n
t
(
)
count()
count(), 和
f
o
r
m
a
t
(
)
format()
format()。现在我要给你介绍一个强大但鲜为人知的操作字符串的技术:
t
r
a
n
s
l
a
t
e
(
)
translate()
translate() 方法。

字符串翻译从一个转换表开始, 转换表就是一个将一个字符映射到另一个字符的字典。实际上,“字符” 是不正确的 — 转换表实际上是将一个 字节(
b
y
t
e
byte
byte)映射到另一个。
P
y
t
h
o
n
3
Python 3
Python3 中的字节是整型数。
o
r
d
(
)
ord()
ord() 函数返回字符的
a
s
c
i
i
ascii
ascii码。在这个例子中,字符是
A
–
Z
A–Z
A–Z, 所以返回的是从65 到 90的字节。
一个字符串的
t
r
a
n
s
l
a
t
e
(
)
translate()
translate()方法接收一个转换表,并用它来转换该字符串。换句话说,它将出现在转换表的键中的字节替换为该键对应的值。在这个例子里, 将MARK 转换为 MORK。

通过生成器表达式、 z i p ( ) zip() zip()函数、 t r a n s l a t e ( ) translate() translate()函数我们可以方便的把字符串公式转换成对应的数字公式。然而它还是一个字符串,所以还需要进一步处理。
9.将任何字符串作为Python表达式求值
这是谜题的最后一部分(或者说, 谜题解决者的最后一部分)。经过华丽的字符串操作,我们得到了类似’9567 + 1085 == 10652’这样的一个字符串。但那是一个字符串,字符串有什么好的?输入
e
v
a
l
(
)
eval()
eval(),
P
y
t
h
o
n
Python
Python 通用求值工具。

e
v
a
l
(
)
eval()
eval() 并不限于布尔表达式。它能处理任何
P
y
t
h
o
n
Python
Python 表达式并且返回任何数据类型。

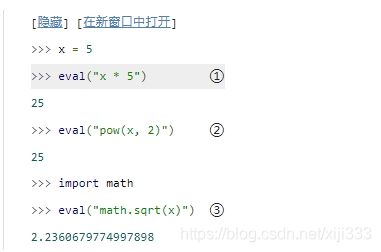
e
v
a
l
(
)
eval()
eval()接受的表达式可以引用在
e
v
a
l
(
)
eval()
eval()之外定义的全局变量。如果(
e
v
a
l
(
)
eval()
eval())在函数内被调用, 它也可以引用局部变量。甚至可以引用函数和模块……
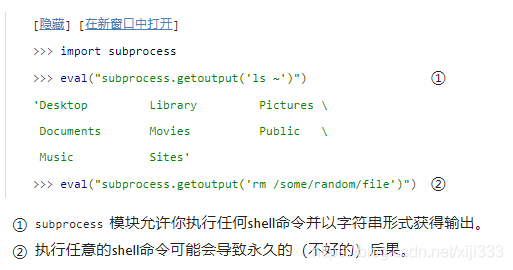
更坏的是,由于存在全局函数
_
_
i
m
p
o
r
t
_
_
(
)
\_\_import\_\_()
__import__(),它接收字符串形式的模块名,导入模块,并返回模块的引用。和
e
v
a
l
(
)
eval()
eval()的能力结合起来,你可以构造一个单独的表达式来删除你所有的文件:

所以你应该只在信任的输入上使用
e
v
a
l
(
)
eval()
eval()。当然,关键的部分是确定什么是“可信任的”。但有一点我敢肯定: 你不应该将这个字母算术表达式放到网上最为一个
w
e
b
web
web服务。不要错误的认为,“Gosh, 这个函数在求值以前做了那么多的字符串操作。我想不出谁能利用这个漏洞。” 会有人找出穿过这些字符串操作把危险的可执行代码放进来的方法的。
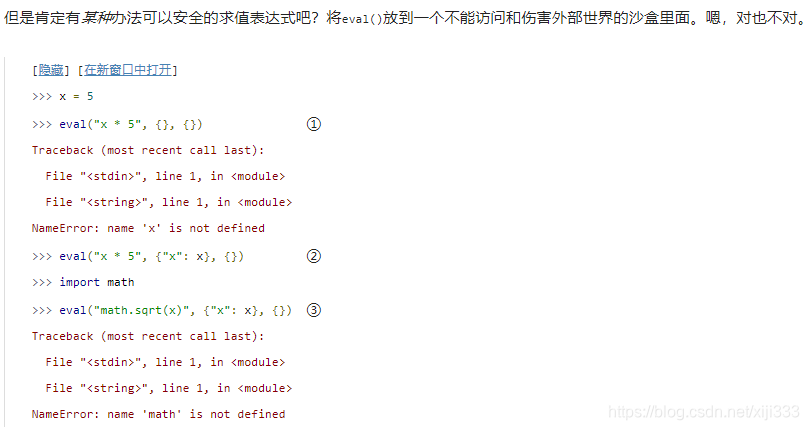
传给
e
v
a
l
(
)
eval()
eval()函数的第二和第三个函数担当了求值表达式的全局和局部名字空间的角色。在这个例子里,它们都是空的,意味着当字符串"x * 5"被求值的时候, 在全局和本地的名字空间都没有变量
x
x
x, 所以
e
v
a
l
(
)
eval()
eval()抛出了一个异常。
你可以通过一个个列出的方式选择性的在全局名字空间里面包含一些值。并且只有这有这些变量在求值的时候可用。
即使你刚刚导入了
m
a
t
h
math
math模块, 你没有在传给eval()函数的名字空间里包含它,所以求值失败了。

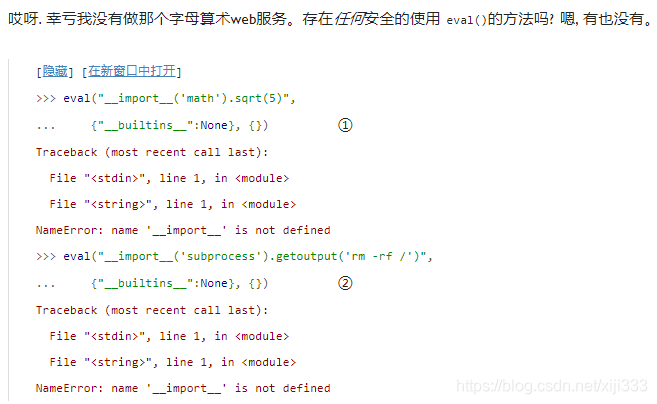
为了安全的求值不受信任的表达式, 你需要定义一个将"__builtins__" 映射为
N
o
n
e
None
None(
P
y
t
h
o
n
Python
Python 的空值)的全局名字空间字典. 在内部, “内建” 函数包含在一个叫做"__builtins__"的伪模块内。这个伪模块(即 内建函数的集合) 在没有被你显式的覆盖的情况下对被求值的表达式是总是可用的。
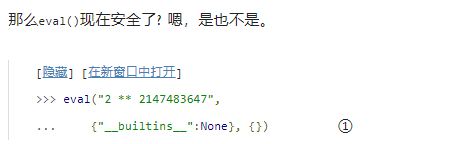
即使不能访问到__builtins__, 你还是可以开启一个拒绝服务攻击。例如, 试图求2 的 2147483647次方会导致你的服务器的 \cpu\ 利用率到达100% 一段时间。(如果你在交互式shell中试验这个, 请多按几次 Ctrl-C来跳出来。) 技术上讲,这个表达式 最终将会返回一个值, 但是在这段时间里你的服务器将啥也干不了。
最后,
P
y
t
h
o
n
Python
Python 表达式的求值是可能达到某种意义的“安全”的, 但结果是在现实生活中没什么用。如果你只是玩玩没有问题,如果你只给它传递安全的输入也没有问题。但是其它的情况完全是自找麻烦。
10.把所有东西放在一起



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









