







0.摘要
用来记录与正则表达式相关的知识吧。并不会详细介绍 p y t h o n python python的 r e re re模块。
1.推荐网址
首先推荐一个用来测试正则表达式的网站:https://regex101.com/。个人感觉非常好用。
再推荐一个学习正则表达式的网站:https://github.com/ziishaned/learn-regex/blob/master/translations/README-cn.md。
2.元字符
正则表达式主要依赖于元字符。元字符不代表他们本身的字面意思,他们都有特殊的含义。

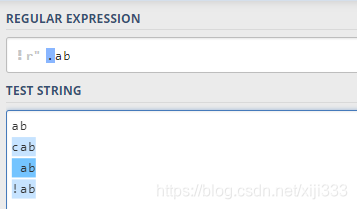
2.1 点元字符
.
.
.匹配任意单个字符,但不会匹配换行符:
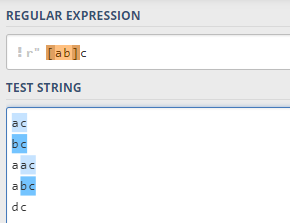
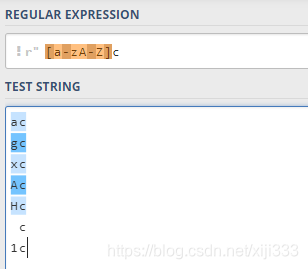
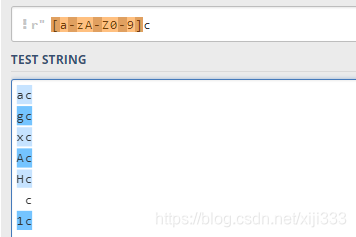
2.2字符集
方括号用来指定一个字符集,在方括号中使用连字符来指定字符集的范围。只要匹配这个字符集中的任意一个元素就行:
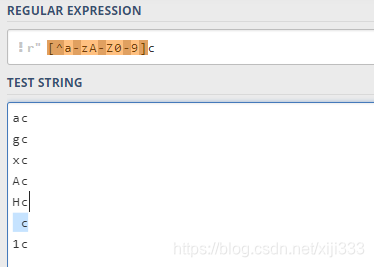
2.2.1 否定字符集
在方括号开头位置加上^表示否定字符集。只要和这个字符集之外的任意一个字符匹配即可:
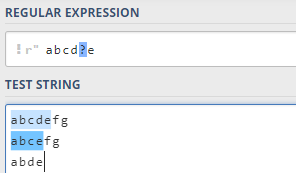
2.3 ?限定符
第一个限定符是
?
?
?,它表示前面的字符需要出现
0
0
0次或
1
1
1次,直接看例子:
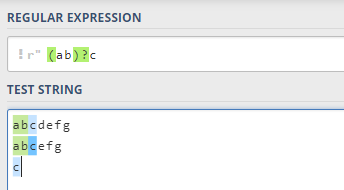
通常来说,
?
?
?只影响它前面的那个字符,除非前面的内容被我们用
(
)
()
()包起来了:
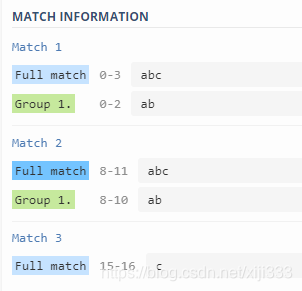
这里还可以引申出一个 g r o u p group group的概念,简单来说,用 ( ) () ()括起来的部分就被认为是一个分组。在 p y t h o n python python中,你不仅可以看到整体的匹配情况,也可以拿到每个分组的匹配情况。
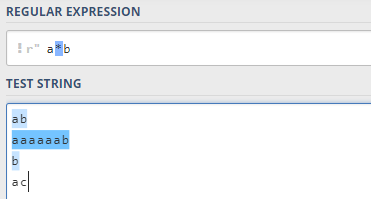
2.4 *限定符
第二个限定符是
∗
*
∗,它表示前面的字符需要出现
0
0
0次或多次(任意次):
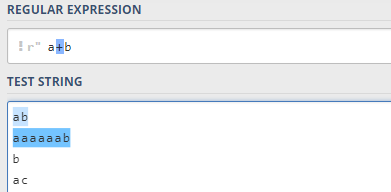
2.5 +限定符
第三个限定符是
+
+
+,它表示前面的字符需要出现
1
1
1次或多次:
2.6. {n,m}语法
使用这种语法可以让你做更加精准的匹配。
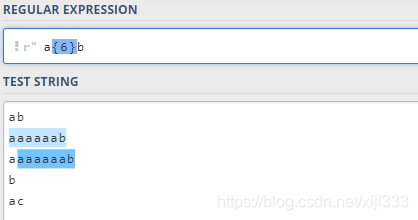
2.6.1 {n}语法
{
n
}
\{n\}
{n}表示它前面的字符需要出现
n
n
n次:
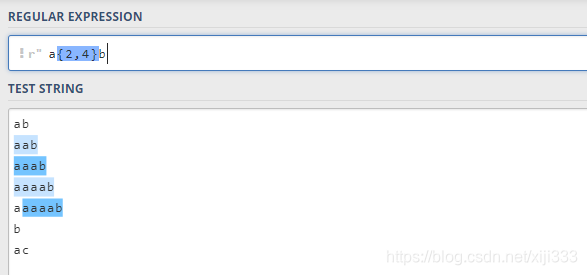
2.6.2 {n,m}语法
{
n
,
m
}
\{n,m\}
{n,m}表示它前面的字符至少要出现
n
n
n次,至多出现
m
m
m次:
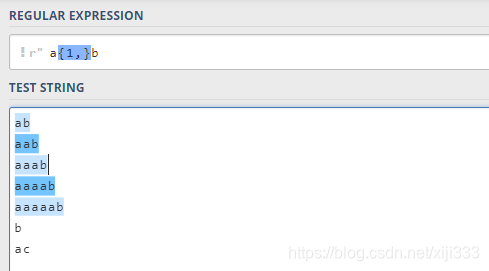
2.6.3 {n,}语法
{
n
,
}
\{n,\}
{n,}表示它前面的字符至少要出现
n
n
n次:
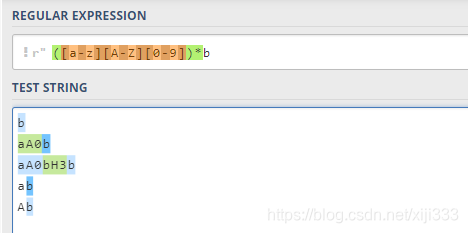
2.7(…) 特征标群 & 非捕获组
一般来说,限定符或者
{
n
,
m
}
\{n,m\}
{n,m}语法只影响前面的单个字符,如果是多个字符该怎么办呢?正如我们在
2.3
2.3
2.3内提到的,用
(
)
()
()括起来,在括号后面使用限定符即可。
用
(
)
()
()括起来的内容就是特征标群,也可以称为一个
G
r
o
u
p
Group
Group,其内的内容会被看作一个整体。在匹配之后还可以拿到特定
G
r
o
u
p
Group
Group的内容进一步进行处理。
更进一步,可以通过 ( ? P < n a m e > . . . ) (?P<name>...) (?P<name>...)来对某个组进行命名。其中 n a m e name name是这个分组的名称, . . . ... ...部分是正常的匹配表达式。之后可以通过 m a t c h . g r o u p ( n a m e ) match.group(name) match.group(name)来访问该组的匹配信息。
import re
s = "apple test for test wtf."
pattern = "(?P<for>for) (test)" # 注意P是大写的
match = re.search(pattern, s)
print(match.span())
print(match.groups())
print(match.group("for"))
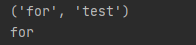
当然有时候你可能并不在意每个 G r o u p Group Group的内容,那么可以使用非捕获组来把它们忽略掉。它们依然会参与匹配结果,但不会分配组号。
import re
s = "apple test for test wtf."
pattern = "(test)"
print(re.search(pattern, s).groups())
pattern = "(?:test)"
print(re.search(pattern, s).groups())

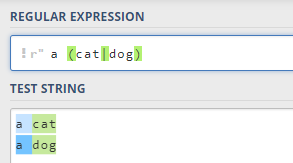
2.8 | 或运算符
或运算符就表示或,用作判断条件:
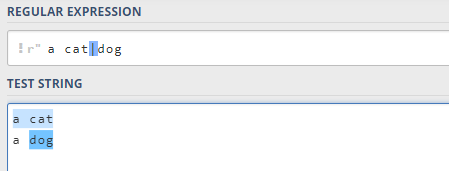
你可能想当然的以为,上面这个应该匹配
a
c
a
t
a\ cat
a cat和
a
d
o
g
a\ dog
a dog,实际上并不是。所以在使用
∣
|
∣运算符时使用
(
)
()
()吧,这可以让逻辑更加清晰:
2.9 转码特殊字符
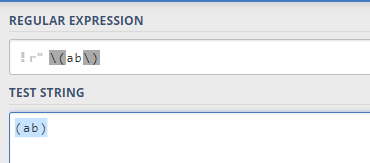
反斜线 \ 在表达式中用于转码紧跟其后的字符。用于指定 { } [ ] / \ + * . $ ^ | ? 这些特殊字符。如果想要匹配这些特殊字符则要在其前面加上反斜线 \。
2.10 原始字符串
你或许在网站上注意到了这个玩意:
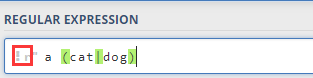
这个 r r r表示后面的这个字符串是一个原始字符串。先不考虑正则表达式,我们看一下这个 r r r有什么用:
s1='\\123'
s2=r'\123'
print(s1,s2,s1==s2,sep='\n')

s1='\\n123'
s2=r'\n123'
print(s1,s2,s1==s2,sep='\n')
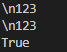
你是否看出了一些端倪?我们知道在编程语言中,反斜杠\加上一些其他字符(如n等)会构成转义字符。由于反斜杠的这个特性,如果我们想要表示出\这个字符,那么实际上需要使用“\\”,就比如上面例子中的
s
1
s_1
s1。这样看起来很不舒服,而且容易让人迷惑,所以我们可以使用原始字符串,比如上面例子中的
s
2
s_2
s2,这时\就不具有转义性质了(但是你依然不能以它作为字符串的结尾)。
现在让我们考虑正则表达式:
import re
s1='\n123'
s2=r'\n123'
print(s1)
print(s2)
pattern='\n'
print(re.sub(pattern,'a',s1))
print(re.sub(pattern,'a',s2))

e m m m emmm emmm,没错,它成功的将换行符替换为了 a a a。顺便一提,当 p a t t e r n pattern pattern为\\n、\\\n时,结果也与上面一致。但是:
import re
s1='\n123'
s2=r'\n123'
print(s1)
print(s2)
pattern='\\\\n'
print(re.sub(pattern,'a',s1))
print(re.sub(pattern,'a',s2))
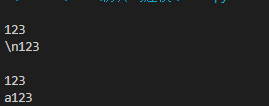
没错,为了匹配\这个字符,我们需要使用4个反斜杠(字符串转义+正则转义)。这实在是太不方便了,而且可读性相当差劲。但是如果使用原始字符串,只需要两个就可以:
import re
s1='\n123'
s2=r'\n123'
print(s1)
print(s2)
pattern=r'\\n'
print(re.sub(pattern,'a',s1))
print(re.sub(pattern,'a',s2))

2.11 锚点
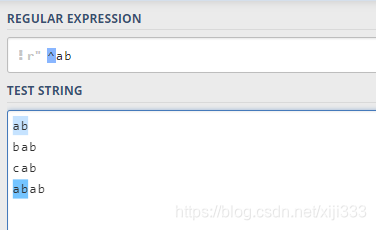
2.11.1 ^ 号
^ 用来检查匹配的字符串是否在所匹配字符串的开头。
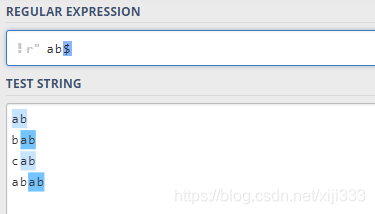
2.11.2 $ 号
$ 号用来匹配字符是否是最后一个。
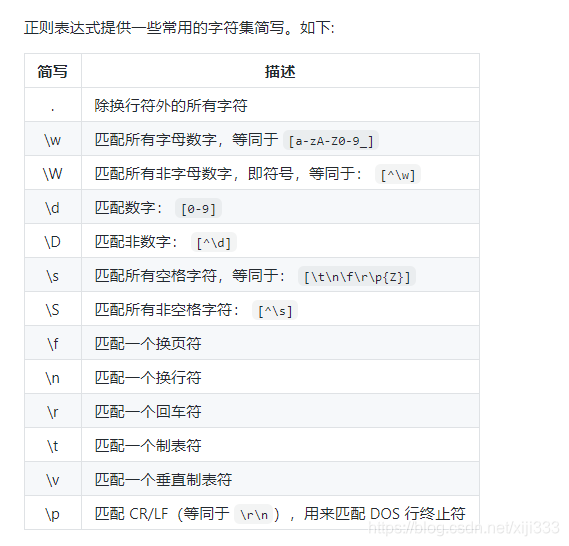
3.简写字符集
4.零宽度断言(前后预查)
先行断言和后发断言都属于非捕获簇(不捕获文本 ,也不针对组合计进行计数)。先行断言用于判断所匹配的格式是否在另一个确定的格式之前,匹配结果不包含该确定格式(仅作为约束)。

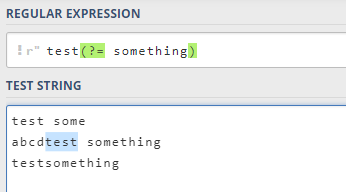
4.1 ?=… 正先行断言
?
=
.
.
.
?=...
?=... 正先行断言,表示第一部分表达式之后必须跟着
?
=
.
.
.
?=...
?=...定义的表达式。
返回结果只包含满足匹配条件的第一部分表达式。 定义一个正先行断言要使用
(
)
()
()。在括号内部使用一个问号和等号: (
?
=
.
.
.
?=...
?=...)。
正先行断言的内容写在括号中的等号后面。
4.2 ?!.. 负先行断言
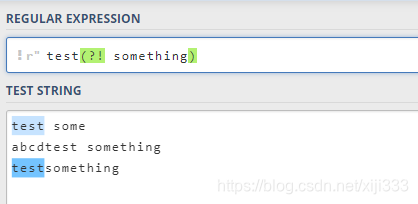
负先行断言
?
!
?!
?! 用于筛选所有匹配结果,筛选条件为其后不跟随着断言中定义的格式。 正先行断言定义和负先行断言一样,区别就是
=
=
= 替换成
!
!
! 也就是 (
?
!
.
.
.
?!...
?!...)。
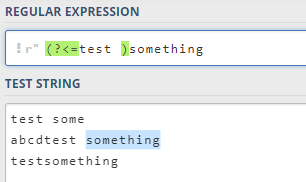
4.3 ?<= … 正后发断言
正后发断言记作(
?
<
=
.
.
.
?<=...
?<=...) 用于筛选所有匹配结果,筛选条件为其前跟随着断言中定义的格式。
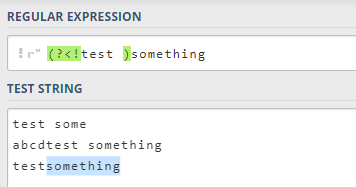
4.4 ?<!.. 负后发断言
负后发断言记作(
?
<
!
.
.
.
?<!...
?<!...) 用于筛选所有匹配结果,筛选条件为其前不跟随着断言中定义的格式。
5.标志
5.1 忽略大小写 (Case Insensitive)
修饰语
i
i
i 用于忽略大小写。

5.2 全局搜索 (Global search)
修饰符
g
g
g 常用于执行一个全局搜索匹配,即(不仅仅返回第一个匹配的,而是返回全部)。
5.3 多行修饰符 (Multiline)
多行修饰符
m
m
m 常用于执行一个多行匹配。


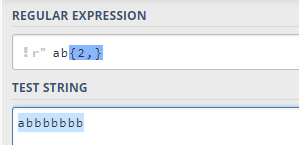
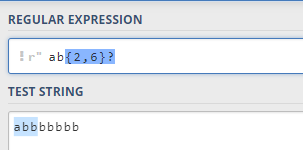
6.贪婪匹配与惰性匹配 (Greedy vs lazy matching)
.
∗
.*
.∗等限定符结合起来可以匹配任意多个字符,那么就涉及到了贪婪匹配与惰性匹配。默认采用贪婪匹配模式,在该模式下意味着会匹配尽可能长的子串。

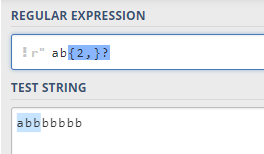
我们可以在
∗
*
∗后面加一个
?
?
?从而把贪婪匹配模式转化为惰性匹配模式。

注意,这里并不局限于
.
∗
.*
.∗,
+
∗
+*
+∗或者
{
n
,
m
}
\{n,m\}
{n,m}语法均可:

















 1002
1002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









