



Atlas 200部署YOLOv11避坑指南:从“卡壳王者”到“秒识别大神”,这波操作稳了!
家人们谁懂啊!当初抱着“ Atlas 200 + YOLOv11 ,AI部署快如闪电”的美好幻想入坑,结果差点被各种报错按在地上摩擦——驱动装了8遍还是不兼容,模型转换直接报“玄学错误”,推理时要么卡成PPT,要么直接“程序猝死”。
历经3天“血泪踩坑”,总算把这套组合拳打通了!今天就用最幽默的话,讲最严谨的操作,帮各位兄弟避开我踩过的所有坑,让你从部署小白,秒变“ Atlas 200 玩机大神”。话不多说,上干货!

一、部署前准备:这些“装备”千万别乱带
部署就像打仗,装备没备齐就冲,纯属送人头。很多兄弟刚上手就急着装模型,结果要么环境不兼容,要么工具缺胳膊少腿,最后只能原地emo。记住:前期准备到位,后期少走99%的弯路!
1. 核心“硬件武器”:Atlas 200 DK(别买错版本!)
首先确认你的Atlas 200是DK开发板版本,不是推理卡!当初我差点买成工业级推理卡,到手才发现没法接显示器调试,直接心态崩了。另外,准备好:12V/5A电源适配器(别用劣质的,容易烧板)、网线(最好是千兆的,传输模型更快)、HDMI线+显示器(调试必备,头铁不用的话,后期排查错误能让你怀疑人生)。
2. 软件“弹药库”:版本对应是关键(避坑第一要义)
这是最容易踩坑的地方!很多人随便找个驱动、固件就装,结果出现“驱动和固件不匹配”“MindStudio版本过低”等致命错误。这里给大家整理了经过实测的“黄金版本组合”,直接抄作业就行:
-
Atlas 200 DK 固件版本:22.0.0(别更最新版,容易出bug)
-
Ascend Driver 驱动版本:22.0.0(必须和固件版本一致,不然会“打架”)
-
MindStudio 版本:5.0.RC3(调试工具,可视化操作超香,不用记一堆命令)
-
YOLOv11 版本:最新版(从官方GitHub下载,别用第三方修改版,容易缺文件)
-
依赖库:Python 3.8(别用3.9及以上,很多库不兼容)、PyTorch 2.0.0、ONNX 1.14.0(模型转换核心工具)
避坑提示:安装前一定要先查Atlas 200官方文档,确认每个软件的版本兼容性!别抱着“新版本肯定更好”的想法乱更,稳定才是部署的第一要务。
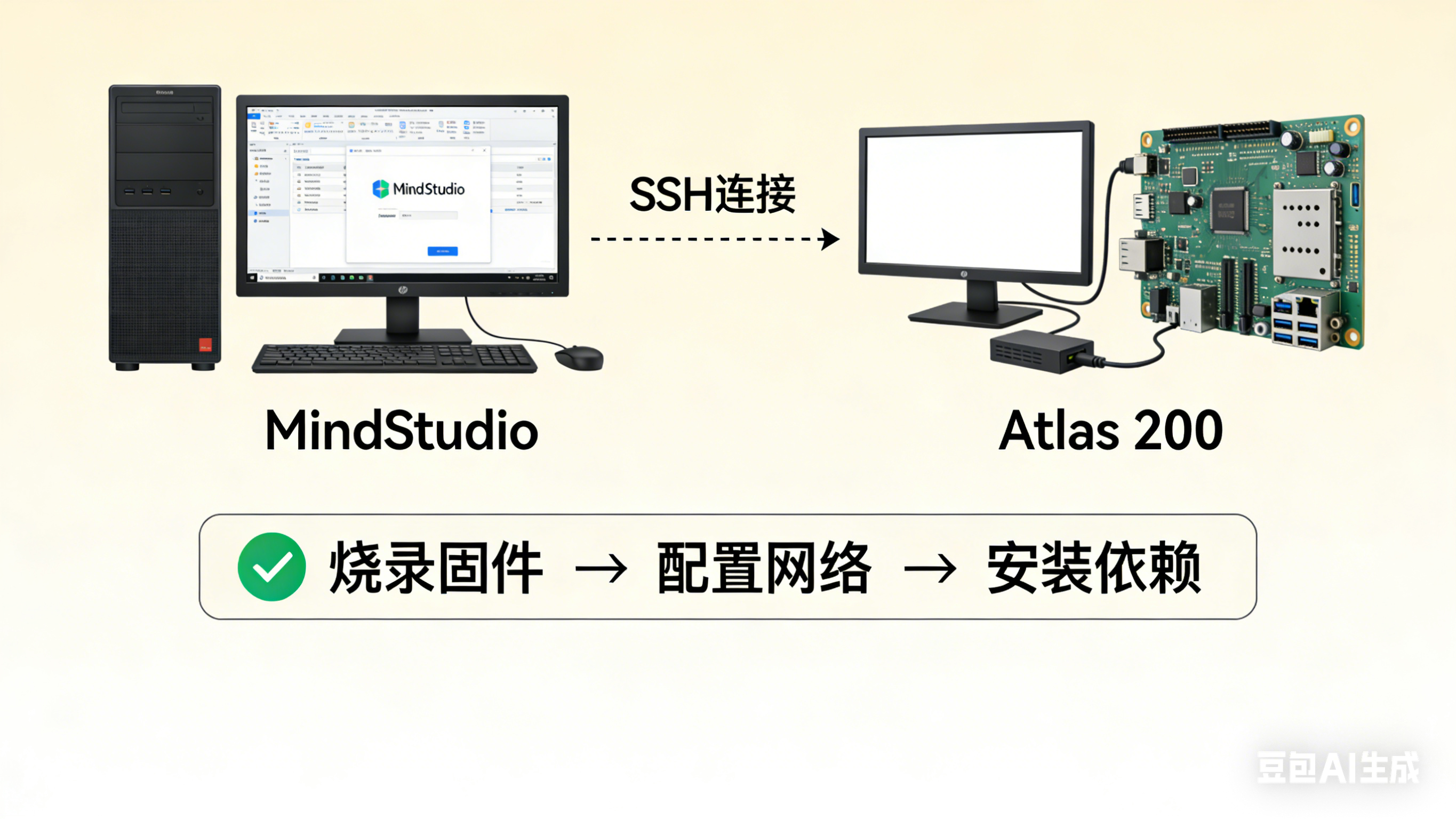
二、环境搭建:从“零到一”,拒绝“卡壳”
环境搭建就像搭积木,一步错步步错。这里分“开发机环境”和“Atlas 200 板端环境”两部分,一步步来,保证不卡壳。
1. 开发机环境搭建(Windows/Linux都可,Linux更稳)
如果用Windows,建议装个虚拟机(比如VMware)跑Ubuntu 20.04,亲测兼容性最好。步骤如下:
-
安装Python 3.8:别用系统自带的,从官网下载,安装时勾选“Add to PATH”,避免后续找路径找疯了。
-
安装PyTorch和torchvision:直接用官方命令,注意版本对应(PyTorch 2.0.0),命令:
pip3 install torch==2.0.0 torchvision==0.15.1 torchaudio==2.0.1 --index-url https://download.pytorch.org/whl/cu118(如果没有GPU,就用CPU版本,把“cu118”改成“cpu”)。 -
安装ONNX和ONNX Runtime:模型转换需要,命令:
pip install onnx==1.14.0 onnxruntime==1.15.0。 -
安装MindStudio:从华为昇腾官网下载5.0.RC3版本,安装时一路默认就行,中途会让选Python环境,选我们刚装的Python 3.8路径。安装完成后,打开MindStudio,会提示安装昇腾相关插件,直接点“安装”,等待完成即可。

2. Atlas 200 板端环境搭建(重点!别偷懒)
板端环境是核心,很多人栽在这里。步骤如下:
-
烧录固件:从华为昇腾官网下载Atlas 200 DK 22.0.0版本的固件,用SD卡烧录工具(比如Win32 Disk Imager)烧录到SD卡中,然后把SD卡插入Atlas 200开发板。
-
启动开发板:连接电源、网线、显示器,开机后输入默认账号密码(账号:HwHiAiUser,密码:Mind@123),登录成功后,先修改密码(避免被别人蹭板),命令:
passwd HwHiAiUser,然后按照提示输入新密码。 -
配置网络:确保开发板和开发机在同一局域网,然后查看开发板IP地址,命令:
ifconfig,记住eth0对应的IP(比如192.168.1.100),后续MindStudio连接开发板需要用。 -
安装板端依赖:在开发板终端输入命令,安装必要的依赖库:
sudo apt-get update && sudo apt-get install -y python3-pip python3-dev libprotobuf-dev protobuf-compiler,然后升级pip:pip3 install --upgrade pip。
小技巧:开发机和开发板之间可以用SSH连接,不用一直插显示器,命令:ssh HwHiAiUser@开发板IP,输入密码即可登录,超方便!
三、模型转换:YOLOv11转OM模型,避开“玄学错误”
YOLOv11官方提供的是PyTorch模型(.pt格式),而Atlas 200只支持OM模型,所以必须进行模型转换,这是部署的核心步骤,也是最容易出“玄学错误”的地方。记住:转换前先验证模型,转换时参数别填错!

1. 下载YOLOv11模型并验证
-
从YOLOv11官方GitHub下载预训练模型(比如yolov11n.pt,体积小,适合部署),命令:
git clone https://github.com/ultralytics/ultralytics.git && cd ultralytics && wget https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov11n.pt。 -
验证模型是否能正常运行:在开发机上运行以下Python代码,测试模型推理效果:
`from ultralytics import YOLO
加载模型
model = YOLO(‘yolov11n.pt’)
推理测试
results = model(‘test.jpg’) # test.jpg是你自己的测试图片
打印结果
results[0].show()`
- 如果能正常显示检测结果,说明模型没问题;如果报错,大概率是PyTorch版本不兼容,回到第一步重新安装对应版本的PyTorch。
2. 将.pt模型转成ONNX模型
ONNX是模型转换的“中间桥梁”,步骤很简单,用YOLOv11自带的导出功能就行,命令:
from ultralytics import YOLO
model = YOLO('yolov11n.pt')
# 导出ONNX模型,指定输入尺寸(640x640,Atlas 200支持这个尺寸)
model.export(format='onnx', imgsz=640)
运行完成后,会在当前目录生成yolov11n.onnx文件。验证ONNX模型是否正常:用ONNX Runtime推理,命令:
import onnxruntime as ort
import numpy as np
# 加载ONNX模型
session = ort.InferenceSession('yolov11n.onnx')
# 构造输入(640x640x3,随机生成测试数据)
input_data = np.random.randn(1, 3, 640, 640).astype(np.float32)
# 推理
outputs = session.run(None, {'images': input_data})
print(f"ONNX模型推理成功,输出形状:{outputs[0].shape}")
如果打印出输出形状,说明ONNX模型没问题;如果报错,检查导出时的imgsz参数是否正确(必须是32的倍数,640是最稳妥的选择)。
3. 将ONNX模型转成OM模型(关键一步!)
这一步需要用到华为昇腾的ATC工具(Ascend Tensor Compiler),MindStudio安装完成后会自带这个工具。步骤如下:
-
打开MindStudio,新建一个“昇腾工程”,选择“模型转换”模板。
-
在模型转换界面,设置以下参数(重点!别填错):
模型输入路径:选择刚才生成的yolov11n.onnx文件。 -
模型输出路径:自定义一个路径(比如./om_model)。
-
目标芯片类型:选择“Atlas 200”。
-
输入格式:NCHW(YOLOv11默认是这个格式,别改成NHWC)。
-
输入尺寸:640,640(和ONNX导出时一致)。
-
数据类型:输入为FP32,输出为FP32(如果想优化性能,可以改成FP16,但需要验证兼容性)。
-
点击“转换”,等待几分钟,如果显示“转换成功”,就会在输出路径生成yolov11n.om文件;如果报错,大概率是输入参数设置错误,或者ATC工具版本不兼容,回到第一步确认软件版本。
避坑提示:转换时如果出现“输入维度不匹配”错误,检查ONNX模型的输入维度是否为(1,3,640,640),可以用Netron工具(在线版:https://netron.app/)打开ONNX模型查看输入输出维度。
四、部署运行:Atlas 200 实战,秒识别不是梦
模型转换完成后,就可以在Atlas 200上部署运行了!这一步很简单,主要是把OM模型传到板端,然后编写推理代码。
1. 传输OM模型到Atlas 200开发板
在开发机终端输入命令,用SCP工具传输OM模型到开发板(需要知道开发板IP地址):
scp ./om_model/yolov11n.om HwHiAiUser@192.168.1.100:/home/HwHiAiUser/
输入开发板密码(Mind@123,如果你改了就输新密码),等待传输完成即可。
2. 编写板端推理代码(Python版,简单易上手)
在开发板终端新建一个Python文件(比如yolov11_infer.py),输入以下代码(注释很详细,跟着改就行):
import cv2
import numpy as np
from ascend.common import * # 昇腾Python API,需要提前安装
# 初始化昇腾设备
device_id = 0 # Atlas 200只有一个设备,ID为0
context = AscendContext(device_id)
context.activate()
# 加载OM模型
model_path = "/home/HwHiAiUser/yolov11n.om"
model = AscendModel(model_path, context)
# 读取测试图片并预处理
img_path = "test.jpg" # 传到板端的测试图片路径
img = cv2.imread(img_path)
# 调整图片尺寸为640x640
img_resized = cv2.resize(img, (640, 640))
# 转换格式:BGR->RGB,HWC->CHW
img_rgb = cv2.cvtColor(img_resized, cv2.COLOR_BGR2RGB)
img_chw = np.transpose(img_rgb, (2, 0, 1))
# 增加batch维度(1,3,640,640)
img_input = np.expand_dims(img_chw, axis=0).astype(np.float32)
# 归一化(和YOLOv11训练时一致,均值0.0,方差1.0/255.0)
img_input = img_input / 255.0
# 模型推理
outputs = model.infer([img_input])
# 后处理(解析检测结果,这里简化处理,详细后处理可以参考YOLOv11官方代码)
output = outputs[0] # 输出形状:(1, 84, 8400),84代表(x,y,w,h,conf+80个类别)
h, w = img.shape[:2] # 原始图片尺寸
# 解析检测框、置信度和类别
for i in range(output.shape[2]):
conf = output[0, 4, i]
if conf > 0.5: # 置信度阈值,只显示置信度>0.5的结果
# 转换检测框坐标(相对于640x640的坐标->原始图片坐标)
x = output[0, 0, i] * w / 640
y = output[0, 1, i] * h / 640
w_box = output[0, 2, i] * w / 640
h_box = output[0, 3, i] * h / 640
# 绘制检测框
cv2.rectangle(img, (int(x - w_box/2), int(y - h_box/2)), (int(x + w_box/2), int(y + h_box/2)), (0, 255, 0), 2)
# 绘制类别和置信度
cls = np.argmax(output[0, 5:, i])
cv2.putText(img, f"Class: {cls}, Conf: {conf:.2f}", (int(x - w_box/2), int(y - h_box/2) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 1)
# 保存并显示结果
cv2.imwrite("result.jpg", img)
print("推理完成,结果已保存为result.jpg")
# 释放资源
context.deactivate()
3. 运行推理代码并查看结果
-
将测试图片(test.jpg)传到开发板,命令:
scp test.jpg HwHiAiUser@192.168.1.100:/home/HwHiAiUser/。 -
在开发板终端运行推理代码:
python3 yolov11_infer.py。 -
如果显示“推理完成,结果已保存为result.jpg”,说明运行成功!然后用SCP命令把结果图片传回开发机查看:
scp HwHiAiUser@192.168.1.100:/home/HwHiAiUser/result.jpg ./。
打开result.jpg,你会看到图片上清晰地标注出了检测目标,置信度也很高!此时,你已经成功在Atlas 200上部署了YOLOv11,是不是超有成就感?
五、常见问题排查:遇到这些坑,这样解决!
部署过程中难免会遇到问题,这里整理了我踩过的5个常见坑和解决方法,帮你快速“渡劫”:
-
坑1:驱动安装失败,提示“依赖库缺失”。解决方法:执行
sudo apt-get install -y libxml2 libssl-dev libcurl4-openssl-dev,安装缺失的依赖库,然后重新安装驱动。 -
坑2:模型转换时提示“ATC工具未找到”。解决方法:在MindStudio中设置ATC工具路径,路径一般是
/home/用户名/Ascend/ascend-toolkit/latest/atc/bin。 -
坑3:推理时提示“内存不足”。解决方法:选择体积更小的YOLOv11模型(比如yolov11n.pt),或者减小输入尺寸(比如416x416)。
-
坑4:检测结果不准确,出现大量误检。解决方法:检查模型转换时的输入尺寸和归一化参数是否和训练时一致,或者提高置信度阈值(比如从0.5改成0.6)。
-
坑5:开发板无法连接网络。解决方法:检查网线是否插好,确认开发机和开发板在同一局域网,用
ping 开发板IP命令测试网络连通性。
六、总结:部署不难,避坑是关键!

其实Atlas 200部署YOLOv11并不难,核心就是“版本对应、步骤严谨、避开坑点”。只要按照本文的步骤来,从环境搭建到模型转换,再到部署运行,每一步都别偷懒,就能顺利完成部署。
如果大家在部署过程中遇到其他问题,或者有更好的优化方法,欢迎在评论区留言交流!祝各位兄弟都能顺利玩转Atlas 200和YOLOv11,实现各种好玩的AI应用~
最后,求点赞、求收藏、求关注!后续还会分享更多昇腾部署和AI实战教程,咱们下期再见~


















 2349
2349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









