




一、点云标注
1、力推-CVAT
这个github网址统计了标注工具。
https://github.com/HumanSignal/awesome-data-labeling
按照下面这个网址的推荐:我尝试了两种标注工具。实测心得如下:
https://zhuanlan.zhihu.com/p/694524430
- labelCloud标注时,对于点云放大缩小不敏感,特别慢,而且调整框的大小,需要手动修改右边的数字,不够精确。而且输出多次标注文件为空。
- 如果是通过pip安装的,特别是在conda环境下:那么软件的配置文件路径为:
- 通过pip show labelCloud来定位安装路径。/home/vincent/.conda/envs/labelcloud/lib/python3.9/site-packages/labelCloud
- 然后在安装路径下搜索文件。
- 参考下面链接评论区的指引:
- 利用 labelCloud 开源工具标注自己的点云数据集为KITTI标注格式教程(支持pcd、bin格式点云)_如何标注kitti数据集-优快云博客y
- 要在路径中所有文件中找到near_plane和far_plane,因此搜索:
- grep "plane" ./* -r
- 定位路径为:./resources/default_config.ini:,可以找到软件的配置选项。
- 如果是git源码安装路径为labelCloud下的resources路径下default_config.ini。
- cvat网页版的,非常方便。用github登录注册一下就可以了。在线管理方便。唯一限制就是上传文件必须是zip格式的,并且必须不超过4个G。
3D点云目标检测数据集标注工具 保姆级教程——CVAT (附json转kitti代码)_3d点云标注工具-优快云博客 这篇文章讲标注,讲的很好。也包含了,如何将json文件,转为kitti格式的txt标注文件。
cvat官网Leading Image & Video Data Annotation Platform | CVAT一看就是正经大工具。
也有官网手册Documentation | CVAT
这个网址对cvat做了简介:CVAT——计算机视觉标注工具-优快云博客
4.1.CVAT——目标检测的标注详细步骤_cvat标注工具教程-优快云博客
2、建议尝试-SUSTechPOINTS
这个软件最强大的地方在于:按住ctrl键,直接鼠标画框就可以自动标注,然后在左侧调整一下边界即可,如果标定效果不好,还可以点击小灯泡,让他继续自动匹配。拖动俯视图上的箭头还可以实现旋转。让标定工作大大简化。
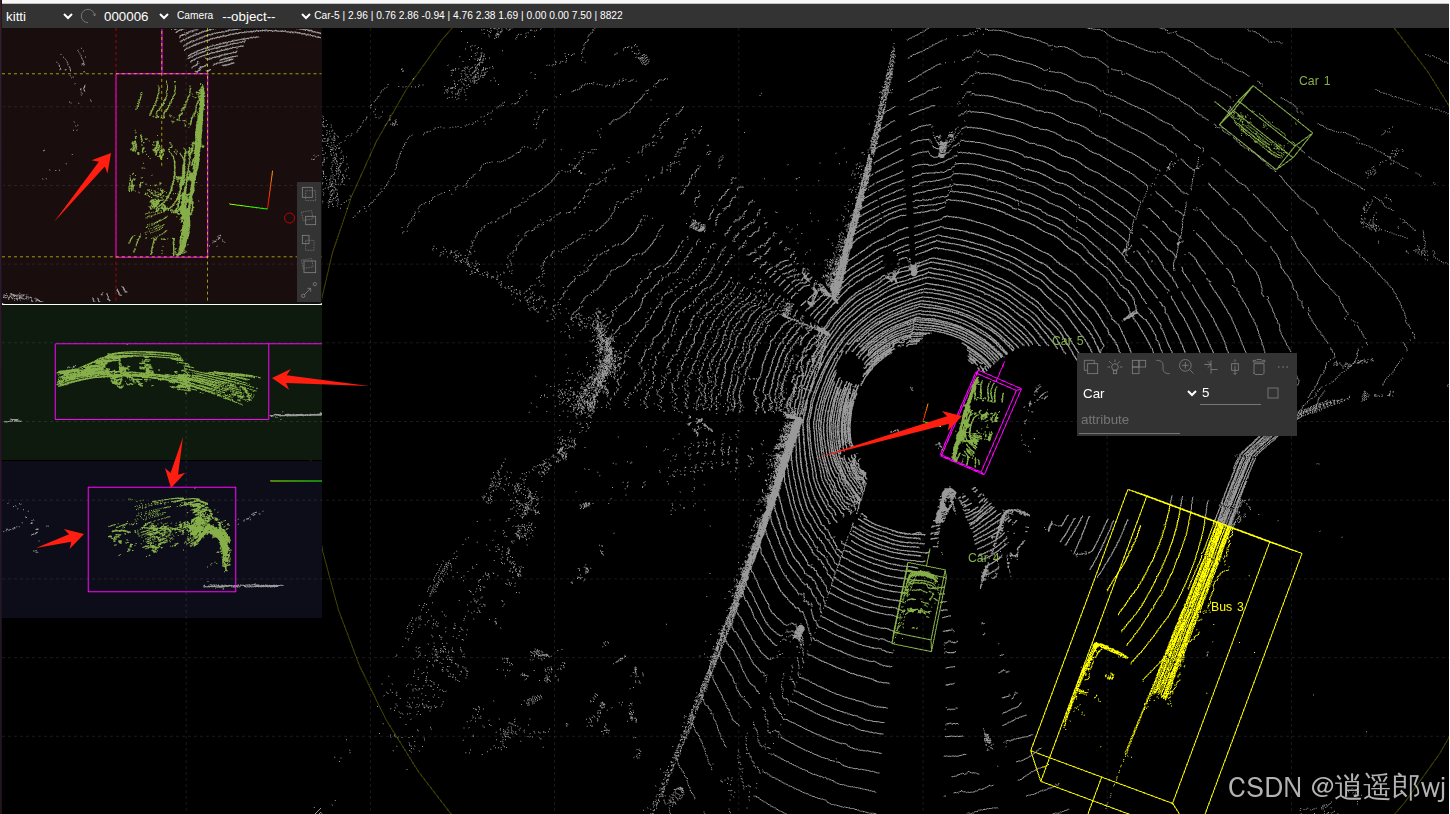
这篇文章也包含了将label转成OpenPCDet的代码。SUSTech代表的应该是南方科技大学。
中文说明https://github.com/naurril/SUSTechPOINTS/blob/dev-auto-annotate/README_guide.md可参照教程:下面这个链接更正经。【OpenPCDet】自定义数据集(kitti格式)训练PointPillars并评估&可视化,全过程debug_pointpillars训练自己的数据-优快云博客
我在安装时:如果是python=3.9的conda环境,无法启动。建议采用3.8的conda环境。
SUSTechPOINTS/README_cn.md at dev-auto-annotate · naurril/SUSTechPOINTS · GitHub
SUSTechPOINTS/README_guide.md at dev-auto-annotate · naurril/SUSTechPOINTS · GitHub
官网给的这两个教程可以详细读一读。
二、工程实施-带着问题前行
GPU租赁平台:
AutoDL算力云 | 弹性、好用、省钱。租GPU就上AutoDL
智星云 AI Galaxy | GPU云服务器 GPU服务器租用 远程GPU租用 深度学习服务器 | 免费GPU 便宜GPU
1、把当前跑通的conda环境复制出来。
conda activate pcdet
conda env export > environment.yml# 将这个yml文件拷贝到新的Anaconda环境中。然后基于这个文件,创建新的conda环境。
conda env create -f environment.yml
conda activate pcdet
conda list
conda env list或者手动复制~/anaconda3/envs/myenv(Linux/Mac)
2、如何训练自己的训练集
3D目标检测(4):OpenPCDet训练篇--自定义数据集(二十五)实践出真知——OpenPCDet 制作pointpillars自定义数据集 - 梦里寻梦的文章 - 知乎
上面这个链接也提及了SUSTechPOINTS工具。
根据自己需求,调整点云范围,需要注意的是x和y轴范围与voxel_size的比值需要是16的倍数,如(69.12+69.12)/0.16 /16= 54
里面提及400张标注还是不太够。
评论区的内容值得学习:数据泛化、标注前转车身坐标系。
3D目标检测(4):OpenPCDet训练篇--自定义数据集![]() https://zhuanlan.zhihu.com/p/407302009这个知乎作者程法说也是跑通的人。注意他的评论区。
https://zhuanlan.zhihu.com/p/407302009这个知乎作者程法说也是跑通的人。注意他的评论区。
同时讲解了对于NX设备的环境部署问题。
自动驾驶系统进阶与项目实战(十)基于PointPillars的点云三维目标检测和TensorRT实战(1)_tensorrt pointpillars-优快云博客
3、只有激光雷达坐标系如何变换。
kitti这个标注,它是以相机2坐标系为基准的。
4、如何训练。
5、如何连续检测。
6、检测结果如何通过ros2的topic形式发送出去。
7、显示问题。如何把检测框体,通过汽车模型的方式替换掉。
8、如何筛选可行驶区域。
9、如何渲染整个环境。
10、地面问题处理。
三、思想实验
上面都是查找的别人如何做的。实操也很难自己收集数据,挨个标定。来测试。
那么这个操作就需要小批量的操作。
1、数据集:
第一步获取自己的数据:我们就用kitti中的点云数据。
我们选择其training中的前一千帧作为训练集,测试集中的前一千帧作为测试集。
2、标注
标注文件相应的拷贝过来,这样就构建了自己的训练集。
3、标注转换
我们用training中的训练集,比如选择中间的10帧数据。放在CVAT或者SUSTechPOINTS下去标注形成JSON文件,然后将JSON文件转为OPenPCDet可以训练的txt文件。
检查对比自己标注之后生成的txt与原始txt的数值差异。
4、训练
采用以上只有点云和标注文件的数据集。没有任何图像的情况下,训练模型。
当前数量只有1000个。然后尝试将训练集提升到2000个,3000个,4000个,测试集一次增长500,看看效果。记录训练时长和评价指标。
四、实操
官网文档:OpenPCDet/docs/CUSTOM_DATASET_TUTORIAL.md at master · open-mmlab/OpenPCDet · GitHub
1、构建数据集
先查看OPenPCDet对于自定义数据集的目录要求。按照路径生成自己的数据集文档。详情参照二、训练自己的模型中提及的链接:
【OpenPCDet】自定义数据集(kitti格式)训练PointPillars并评估&可视化,全过程debug_pointpillars训练自己的数据-优快云博客
custom
├── testing
│ ├── velodyne # 点云数据
├── training
│ ├── label_2 # 标签文件
│ ├── velodyne其中点云数据的格式是bin文件。如果采集到的数据是rosbag包,则先进行bag2pcd,然后pcd2bin。得到bin格式的点云数据。代码如下:
bag2pcd.py:
import rospy
import rosbag
from sensor_msgs.msg import PointCloud2
from sensor_msgs import point_cloud2
import struct
def pointcloud2_to_pcd(point_cloud2_msg, filename):
# 更新头部信息以包含intensity
header = f"""# .PCD v0.7 - Point Cloud Data file format
VERSION 0.7
FIELDS x y z intensity
SIZE 4 4 4 4
TYPE F F F F
COUNT 1 1 1 1
WIDTH {point_cloud2_msg.width}
HEIGHT {point_cloud2_msg.height}
VIEWPOINT 0 0 0 1 0 0 0
POINTS {point_cloud2_msg.width * point_cloud2_msg.height}
DATA ascii
"""
# 将点云数据(包括intensity)转换为ASCII格式并保存到PCD文件
with open(filename, 'w') as f:
f.write(header)
for p in point_cloud2.read_points(point_cloud2_msg, field_names=("x", "y", "z", "intensity"), skip_nans=True):
f.write(f"{' '.join(str(value) for value in p)}\n")
def main():
bag_file = '/home/dxy/SUSTechPOINTS/备份/rosbag/train.bag'
topic = '/velodyne_points'
output_directory = '/home/dxy/SUSTechPOINTS/备份/lidar/'
frame_count = 0
with rosbag.Bag(bag_file, 'r') as bag:
for topic, msg, t in bag.read_messages(topics=[topic]):
if 1:
filename = f"{output_directory}{t.to_nsec()}.pcd"
pointcloud2_to_pcd(msg, filename)
frame_count += 1
print(f"Processed frame {frame_count}: Saved {filename}")
else:
print(f"Message is not of type PointCloud2: {type(msg)}")
print(f"Total frames processed: {frame_count}")
if __name__ == "__main__":
main()pcd2bin.py:
import os
import numpy as np
def read_pcd(filepath):
lidar = []
header_passed = False
with open(filepath, 'r') as f:
for line in f:
line = line.strip()
if line.startswith('DATA'):
header_passed = True
continue
if header_passed:
linestr = line.split()
if len(linestr) == 3:
linestr_convert = list(map(float, linestr)) + [1.0]
linestr_convert[2] += 0
print("!!!!!!!!!!!!!!!!!!!!!!ERROR")
lidar.append(linestr_convert)
elif len(linestr) == 4:
linestr_convert = list(map(float, linestr))
linestr_convert[2] += 0
lidar.append(linestr_convert)
return np.array(lidar)
def pcd2bin(pcdfolder, binfolder, start_idx, end_idx):
ori_path = pcdfolder
des_path = binfolder
if not os.path.exists(des_path):
os.makedirs(des_path)
for idx in range(start_idx, end_idx + 1):
filename = f"{idx:06d}" # 格式化文件名,确保是六位数字,例如000001
velodyne_file = os.path.join(ori_path, filename + '.pcd')
if os.path.exists(velodyne_file): # 确保文件存在
pl = read_pcd(velodyne_file)
pl = pl.reshape(-1, 4).astype(np.float32)
velodyne_file_new = os.path.join(des_path, filename + '.bin')
pl.tofile(velodyne_file_new)
else:
print(f"File not found: {velodyne_file}")
if __name__ == "__main__":
pcdfolder = "/home/dxy/SUSTechPOINTS/data/备份/lidar_copy"
binfolder = "/home/dxy/SUSTechPOINTS/data/备份/lidar_bin"
# 可以在这里设置开始和结束的帧
start_frame = 1
end_frame = 35
pcd2bin(pcdfolder, binfolder, start_idx=start_frame, end_idx=end_frame)经过上面的步骤,就可以得到velodyne文件夹下所需的bin格式点云数据。
复制训练集:
cp ../data_object_velodyne/training/velodyne/000*.bin ./custom/training/velodyne/
cp ../data_object_label_2/training/label_2/000* ./training/label_2/复制测试集:
cp ../data_object_velodyne/testing/velodyne/000*.bin ./custom/testing/2、小标注数据集
但是此处要补充一些内容,我观察SUSTechPoints的输入为pcd格式,所以为了标注kitti中的数据集,需要将bin点云文件,转为pcd文件。
bin2pcd.py
import numpy as np
import open3d as o3d
import os
import argparse
def bin_to_pcd(bin_file_path, pcd_file_path):
"""
将 KITTI Velodyne 点云的 .bin 文件转换为 .pcd 文件
:param bin_file_path: 输入的 .bin 文件路径
:param pcd_file_path: 输出的 .pcd 文件路径
"""
# 读取 .bin 文件
points = np.fromfile(bin_file_path, dtype=np.float32).reshape(-1, 4)
# 提取 x, y, z 坐标(第4列是强度,通常不需要)
points = points[:, :3]
# 创建 Open3D 点云对象
pcd = o3d.geometry.PointCloud()
pcd.points = o3d.utility.Vector3dVector(points)
# 保存为 .pcd 文件
o3d.io.write_point_cloud(pcd_file_path, pcd)
print(f"点云文件已成功保存到 {pcd_file_path}")
def main():
# 解析命令行参数
parser = argparse.ArgumentParser(description="将 KITTI Velodyne 点云的 .bin 文件转换为 .pcd 文件")
parser.add_argument("bin_file", type=str, help="输入的 .bin 文件路径")
parser.add_argument("pcd_file", type=str, help="输出的 .pcd 文件路径")
args = parser.parse_args()
# 转换文件
bin_to_pcd(args.bin_file, args.pcd_file)
if __name__ == "__main__":
main()将label文件从JSON转化成OpenPCDet的格式 txt
import json
filename = "777.json"
with open(filename, 'r') as f:
data = json.load(f)
label_list = []
for obj_dict in data:
label_name = obj_dict["obj_type"]
pos_xyz = obj_dict["psr"]["position"]
rot_xyz = obj_dict["psr"]["rotation"]
scale_xyz = obj_dict["psr"]["scale"]
temp = str(label_name) + " "
for xyz_dict in [pos_xyz, scale_xyz]:
for key in ["x", "y", "z"]:
temp += str(xyz_dict[key])
temp += " "
temp += str(rot_xyz["z"]) + "\n"
label_list.append(temp)
txt_name = filename.split(".")[0] + ".txt"
with open(txt_name, "w") as f:
for label in label_list:
f.write(label)
标注工具SUSTechPOINTS使用教程 - 减肥囧途的文章 - 知乎
https://zhuanlan.zhihu.com/p/6875184641、链接讲解了如何修改标签:在SUSTechPOINTS/public/js/obj_cfg.js中配置。修改obj_type_map和popularCategories
2、在tools/trans_kitti_labels.py文件中作者提供了,kitti转为SUSTechPOINTS格式的方法。
3、在data目录下,新建文件夹,跟example同一级目录。然后在网页的scene中可以看到你建立的文件夹的名字。修改完标签,添加完目录就可以标注了。
严格按照kitti中的类别名字来修改标注配置文件。
3、如何查看kitti数据集的标注情况。
现在需要查看kitti数据集标注情况,特别是关心它是只标注了摄像头视野范围,还是标注了全部数据?带着问题去探索。
kitti标注数据中包含了截断率和难度系数(截断率和难度系数主要用于评估数据集的标注质量或模型的检测性能,而不是算法训练的直接需求。),这对我们来说是没有用的,我们自定义数据集这块可以不包含这些内容。
所以我们只关注位置、大小、朝向即可。
我先把少量kitti数据标注文件,转成JSON格式。甚至手动复制的方式,来完成标注,看看可否查看标注情况。
3.1 实践流程:
(1)先将SUSTechPoints标签文件,修改为kitti的类别。在example同级目录下,新建kitti目录。
(2)在kitti目录下,新建lidar和label文件夹,然后选择四到五个点云和标注文件,将点云文件拷贝到lidar中。
(3)将标注文件拷贝到label下。通过代码或者手动将里面的位置、大小、朝向信息拷贝到json文件中,JSON的格式,仿照example中的格式。
(4)重启网页查看,新建的JSON是否可以对应上。
(5)然后自己重新标注一下其他kitti文件。检查标注信息。
(6)通过脚本,在kitti数据集中的标注信息,将截断率和难度系数等信息删除掉。只剩下位置、大小、朝向信息。
后续优化部分:将源码中,需要通过读取kitti格式,修改为通过读取JSON来训练。
(7)修改源码,直接读取JSON格式。
(8)将以上自定义数据集投入到OPenPCDet中,启动训练。
(9)评估训练效果。
执行:
3.2 绕不开的坐标变换
读这个源码:注意排序问题。
import os
import json
import math
import numpy as np
import sys
def trans_detection_label(src_label_path, tgt_label_path, start_idx=None, end_idx=None):
files = os.listdir(src_label_path)
files.sort() # 确保文件按名称排序
# 初始化最大ID为0
max_id = 0
# 如果指定了 start_idx 和 end_idx,过滤出范围内的文件
if start_idx is not None and end_idx is not None:
files = [f for f in files if f.split('.')[0].isdigit() and start_idx <= int(f.split('.')[0]) <= end_idx]
for fname in files:
frame, _ = os.path.splitext(fname)
print(frame)
kitti_lines = []
with open(os.path.join(src_label_path, fname), encoding='utf-8') as f:
labels = json.load(f, strict=False)
for label in labels:
obj_type = label["obj_type"]
# if label.get('obj_attr') == 'static':
# continue # 跳过当前对象
# 根据条件修改 obj_type
if obj_type == 'Scooter':
obj_type = 'Bic 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2596
2596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









