






在gensim中LDA模型的参数如下:
corpus: 这是你要分析的文档集。通常,它是一个词袋(bag-of-words)表示,其中每个文档都是一个词频的列表或数组。
num_topics: 你希望模型从数据中学习的主题数量。
id2word: 一个映射,将单词ID转换为实际的单词。这通常是通过Gensim的Dictionary对象生成的。
distributed: 一个布尔值,指示是否使用分布式计算。
chunksize: 当处理大型语料库时,此参数指定每次迭代中处理的文档数。
passes: 通过整个语料库进行完整的LDA迭代的次数。
update_every: 在多少次迭代后更新模型参数。
alpha: 文档-主题分布的先验参数。'symmetric'表示使用对称的Dirichlet分布。
eta: 主题-词分布的先验参数。如果没有给出,则默认为与主题数量相同的1/num_topics的数组。
decay: 随机性减小的参数。随着迭代次数的增加,该参数使得模型变得更加确定。
offset: 在计算概率时添加到分母上的常数,以避免除以零的错误。
eval_every: 在多少次迭代后评估模型的困惑度或对数似然。
iterations: 最大迭代次数。
gamma_threshold: 用于确定何时停止迭代的阈值。当最大的主题概率变化小于此阈值时,迭代将停止。
minimum_probability: 过滤掉低于此概率的主题。
random_state: 随机数生成器的种子。
ns_conf: 用于控制非对称先验的参数。
minimum_phi_value: 过滤掉低于此值的词-主题分布。
per_word_topics: 如果为True,则模型将返回每个词的主题分布,而不是每个文档的主题分布。
callbacks: 一个回调函数列表,用于在模型训练过程中的特定点执行自定义操作。
dtype: 用于存储模型内部数据的数据类型。默认为numpy.float32。
1.词袋模型
LDA 采用词袋模型。所谓词袋模型,是将一篇文档,我们仅考虑一个词汇是否出现,而不考虑其出现的顺序。在词袋模型中,“我喜欢你”和“你喜欢我”是等价的。下面是将分词cut转化为LDA模型词袋的一个实例
#将cuts转化为词组
texts = [[word for word in cut] for cut in cuts]
dictionary = Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts] 2.二项分布
二项分布是N重伯努利分布,即为X ~ B(n, p). 概率密度公式为:
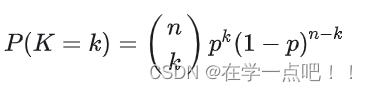
3. 多项分布
多项分布,是二项分布扩展到多维的情况. 多项分布是指单次试验中的随机变量的取值不再是0-1的,而是有多种离散值可能(1,2,3...,k).概率密度函数为:
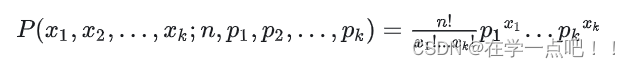
3.Gamma函数
Gamma函数的定义:
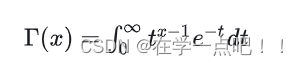
分部积分后,可以发现Gamma函数如有这样的性质:
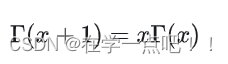
Gamma函数可以看成是阶乘在实数集上的延拓,具有如下性质:
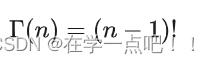
4.Beta分布
Beta分布的定义:对于参数\alpha > 0, \beta > 0, 取值范围为[0, 1]的随机变量x的概率密度函数为: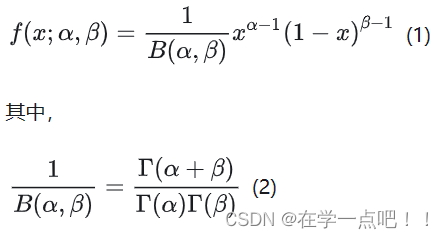
结合3可知,x的概率密度函数Beta分布为alpha和beta阶乘分之alpha与beta和的阶乘,乘x的变性二项分布。
5.共轭先验分布
在贝叶斯概率理论中,如果后验概率P(θ|x)和先验概率p(θ)满足同样的分布律,那么,先验分布和后验分布被叫做共轭分布,同时,先验分布叫做似然函数的共轭先验分布。
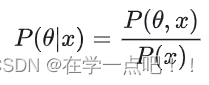
Beta分布是二项式分布的共轭先验分布,而狄利克雷(Dirichlet)分布是多项式分布的共轭分布。
共轭的意思是,以Beta分布和二项式分布为例,数据符合二项分布的时候,参数的先验分布和后验分布都能保持Beta分布的形式,这种形式不变的好处是,我们能够在先验分布中赋予参数很明确的物理意义,这个物理意义可以延续到后续分布中进行解释,同时从先验变换到后验过程中从数据中补充的知识也容易有物理解释。
6.Dirichlet分布
Dirichlet的概率密度函数为:
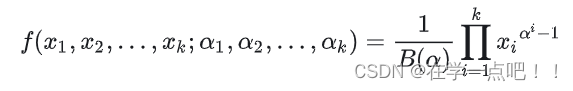
其中,
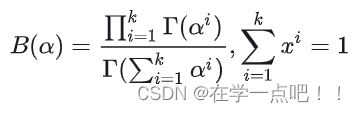
根据Beta分布、二项分布、Dirichlet分布、多项式分布的公式,我们可以验证上一小节中的结论 -- Beta分布是二项式分布的共轭先验分布,而狄利克雷(Dirichlet)分布是多项式分布的共轭分布。
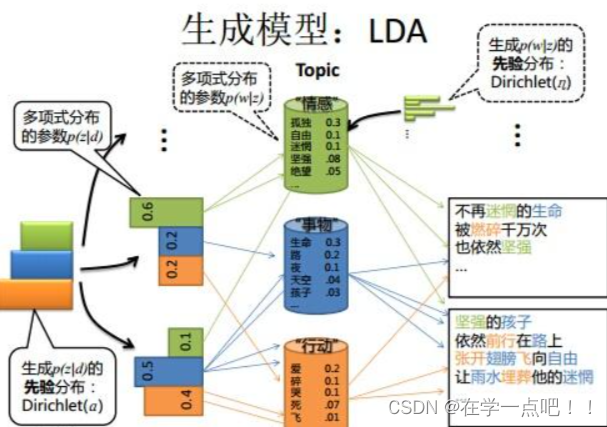
7.LDA 模型




















 921
921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











