



spark
一、 启动篇
(一) 引子 在spark-shell终端执行
val arr = Array(1,2,3,4) val rdd = sc.makeRDD(arr)
rdd.collect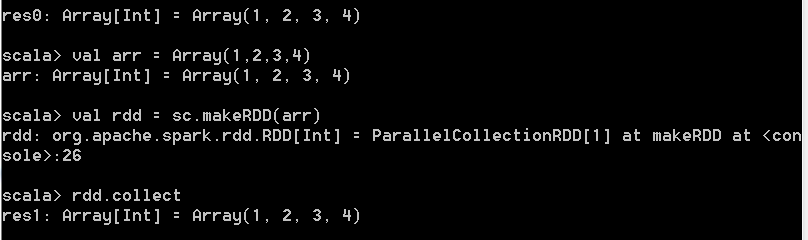
以上3行代码构成了一个完整的spark job执行。
(二) 启动篇
shell模式 shell模式下启动入口:org.apache.spark.repl. Main
shell模式下启动入口:org.apache.spark.repl. Main
submit模式
spark的启动过程就是实例化SparkContext的过程,涉及到driver、和executor端两边
1. SparkSubmit
AppClient
根据shell文件可以得知, spark入口是org.apache.spark.deploy.SparkSubmit,依次打印各类信息,其中最引人注目的是welcome信息
在源码中的体现:
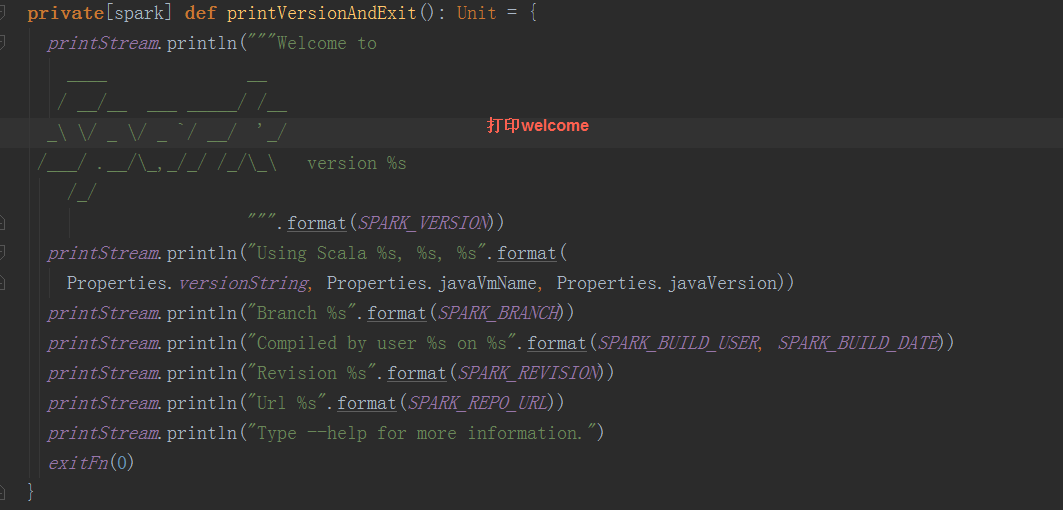 在SparkSubmit中,执行main函数 1.根据外部参数(在我们应用中对应启动sh文件中的参数)构造SparkSubmitArguments
在SparkSubmit中,执行main函数 1.根据外部参数(在我们应用中对应启动sh文件中的参数)构造SparkSubmitArguments
2.调用submit方法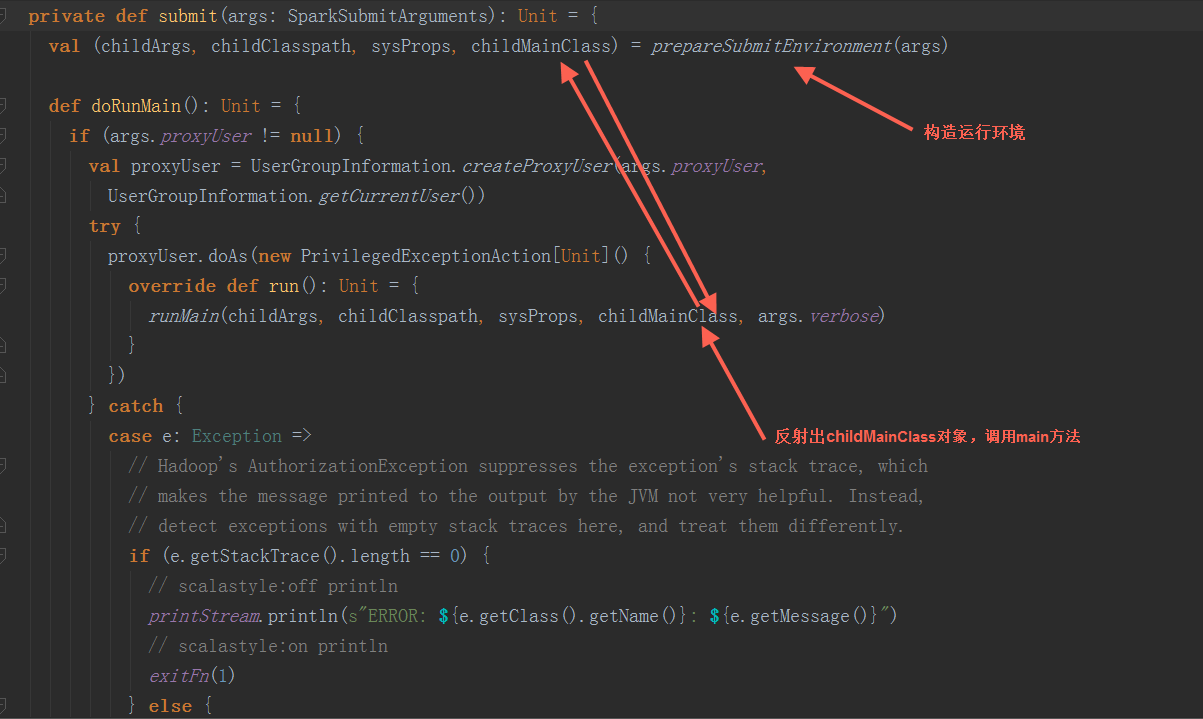 2.1 构造运行环境:
2.1 构造运行环境:
根据步骤1中构造的SparkSubmitArguments对象,确定运行环境,例如master 、deployMode、childMainClass,如果是yarn-cluster,使用org.apache.spark.deploy.yarn.YarnClusterApplication(有的资料上显示是org.apache.spark.deploy.yarn.Client可能是老版本,YarnClusterApplication这个class与org.apache.spark.deploy.yarn.Client在同一个scala文件中)作为childMainClass;如果是mesos-cluster,使用org.apache.spark.deploy.rest.RestSubmissionClient作为childMainClass;如果是standalone模式,使用org.apache.spark.deploy.rest.RestSubmissionClient作为childMainClass
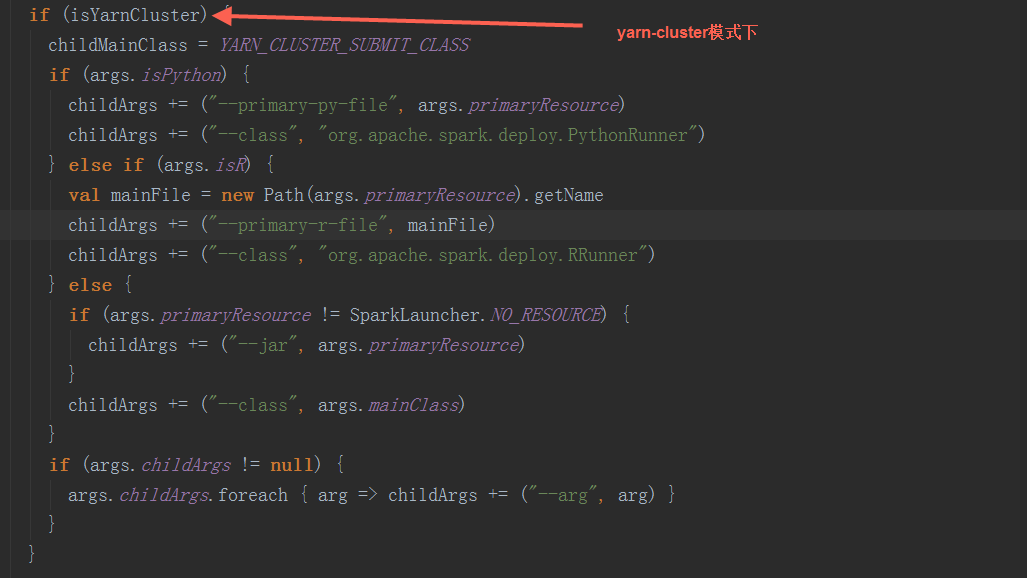 2.2 反射出上一步骤的生成的 childMainClass,调用其main方法
2.2 反射出上一步骤的生成的 childMainClass,调用其main方法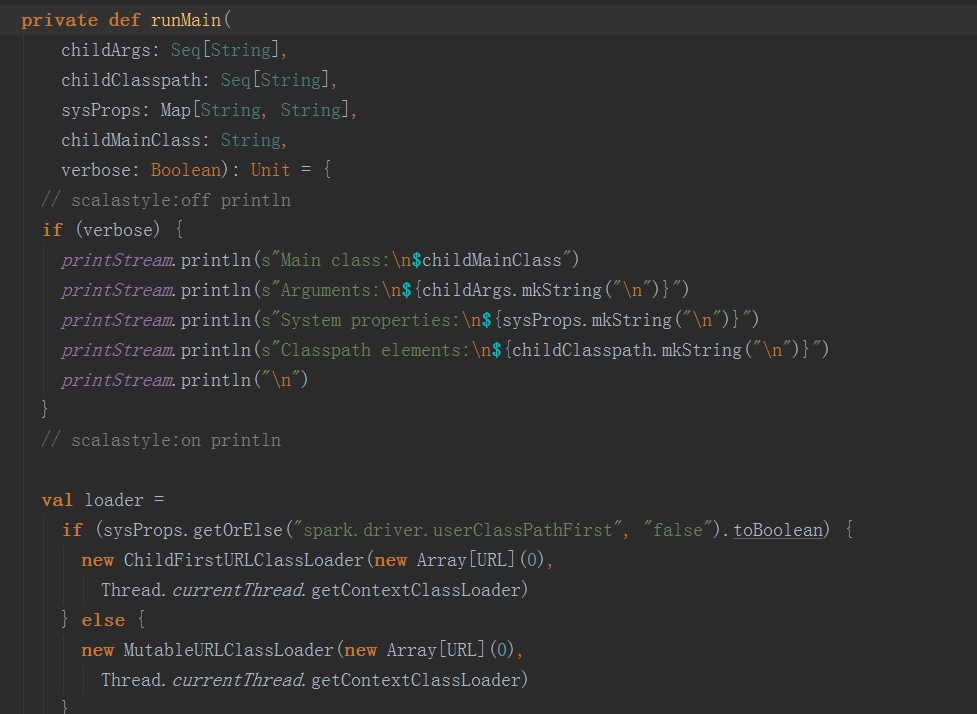
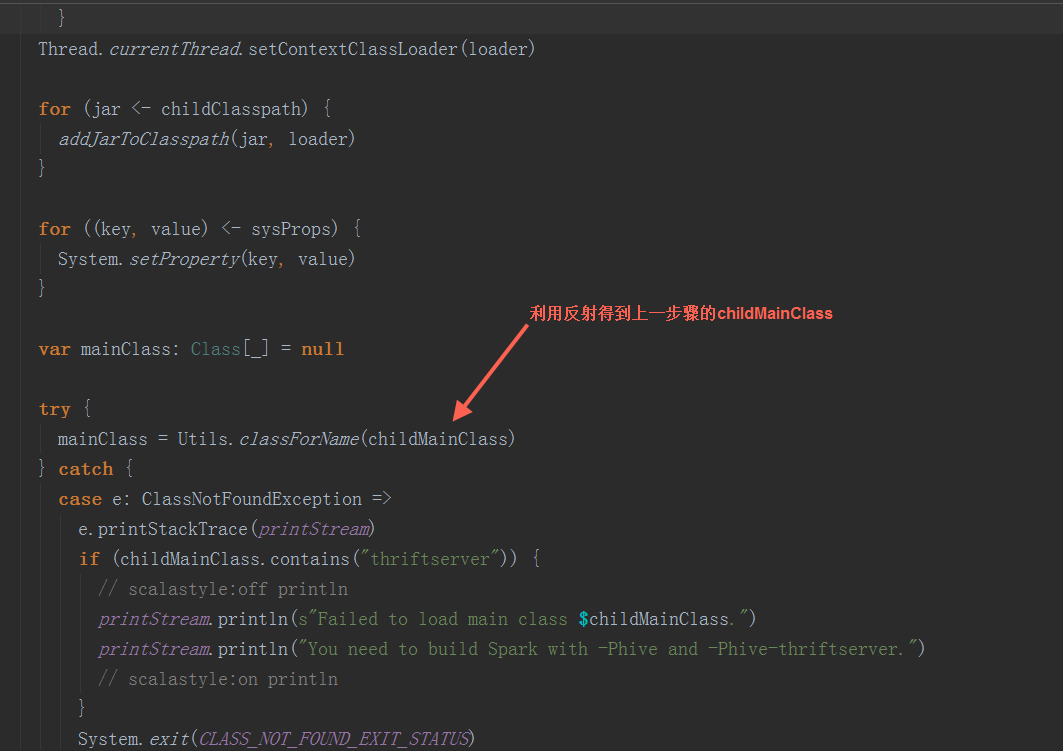
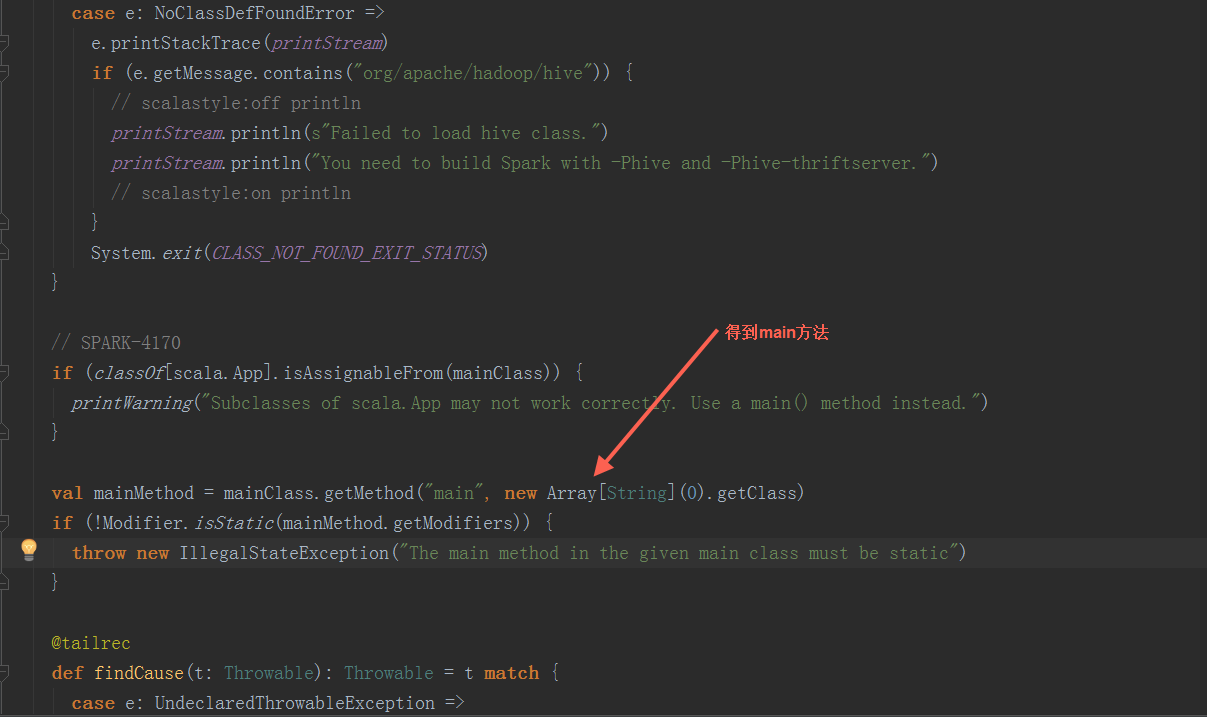
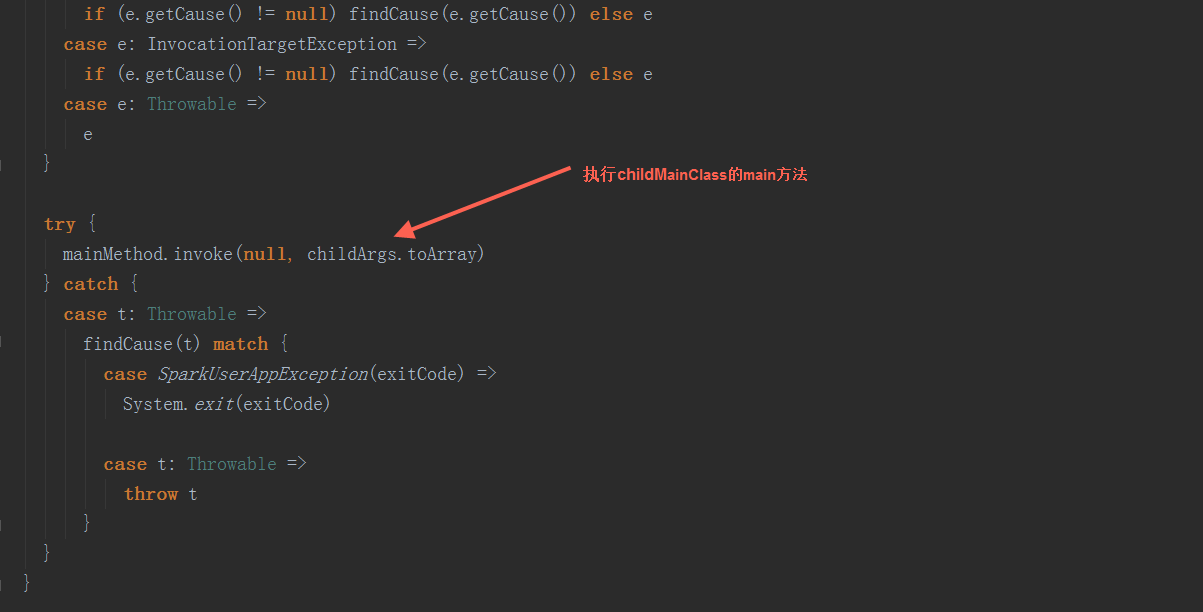 以yarn-cluster模式下,org.apache.spark.deploy.yarn.YarnClusterApplication启动(在spark-yarn这个module里,与org.apache.spark.deploy.yarn.Client在同一个scala文件中)
以yarn-cluster模式下,org.apache.spark.deploy.yarn.YarnClusterApplication启动(在spark-yarn这个module里,与org.apache.spark.deploy.yarn.Client在同一个scala文件中)
以yarn-cluster模式下,org.apache.spark.deploy.yarn.YarnClusterApplication启动(在spark-yarn这个module里,与org.apache.spark.deploy.yarn.Client在同一个scala文件中) 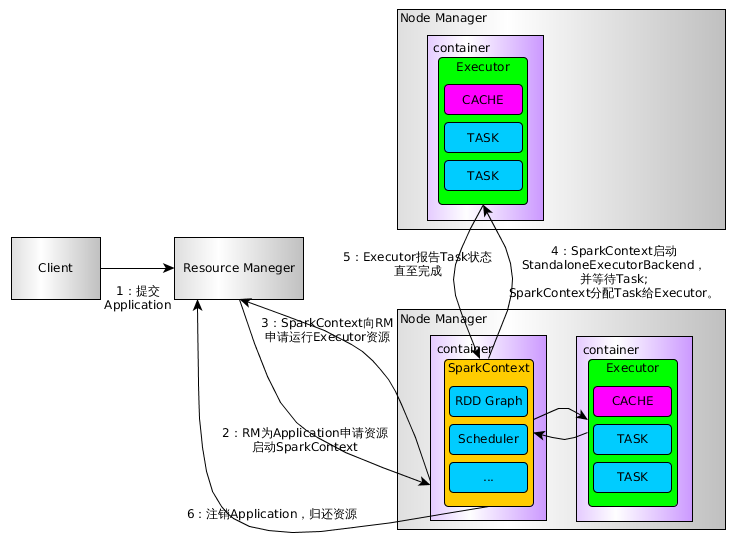
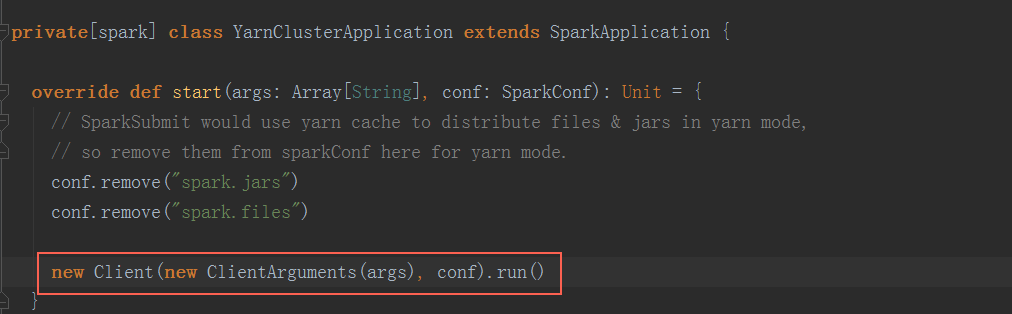 最终调用Client.run()方法:
最终调用Client.run()方法: 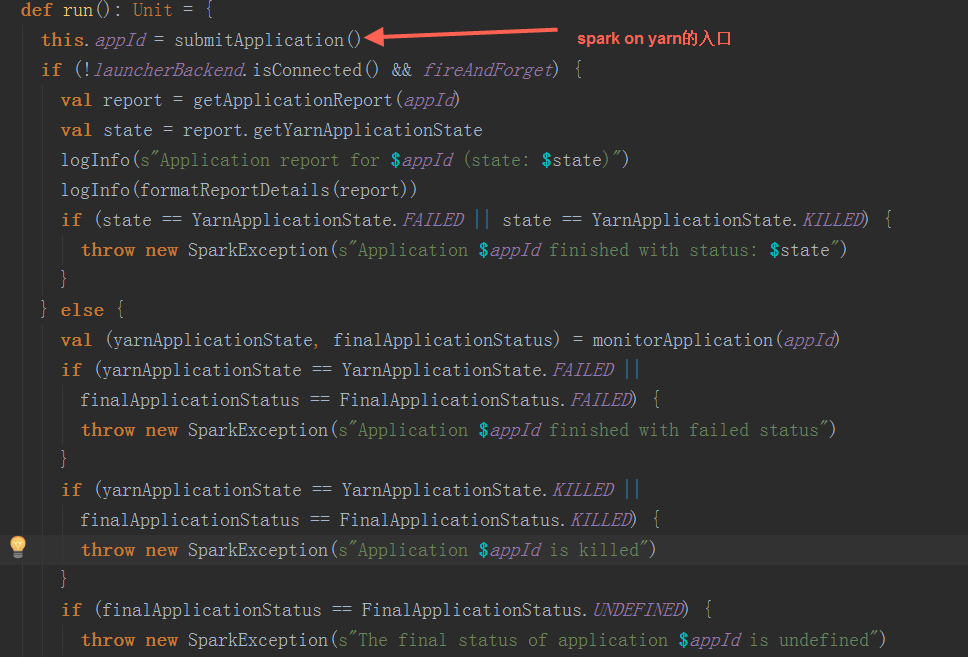 在submitApplication方法中,在经过一些初始化操作后,提交请求到ResouceManager,检查集群的内存情况,检验集群的内存等资源是否满足当前的作业需求,最后正式提交application
在submitApplication方法中,在经过一些初始化操作后,提交请求到ResouceManager,检查集群的内存情况,检验集群的内存等资源是否满足当前的作业需求,最后正式提交application 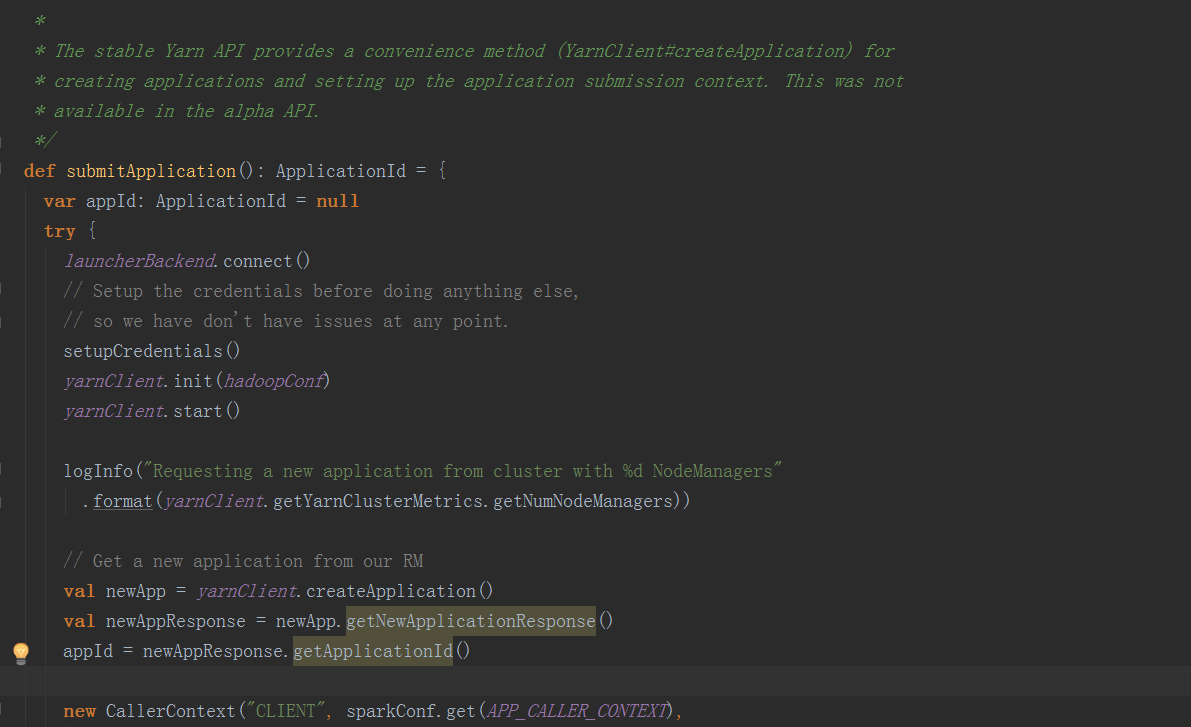
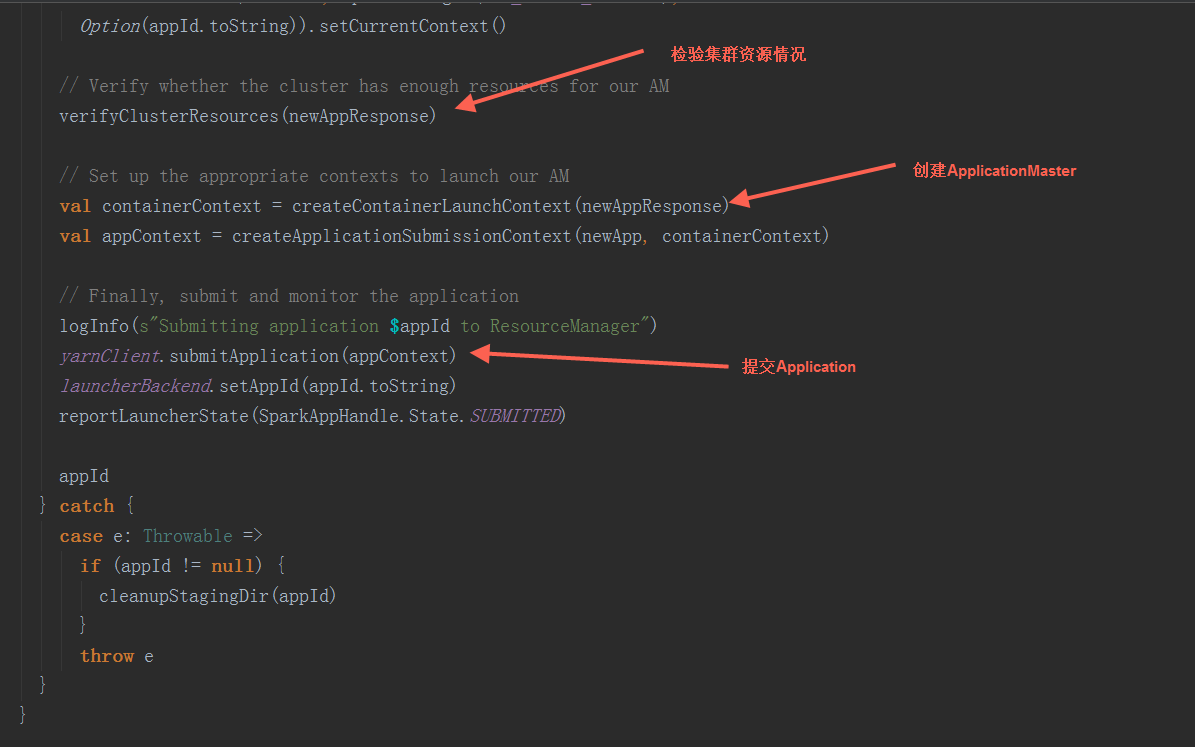 在createContainerLaunchContext方法中,用反射创建ApplicationMaster,负责运行Spark Application的Driver程序,并分配执行需要的Executors。
在createContainerLaunchContext方法中,用反射创建ApplicationMaster,负责运行Spark Application的Driver程序,并分配执行需要的Executors。 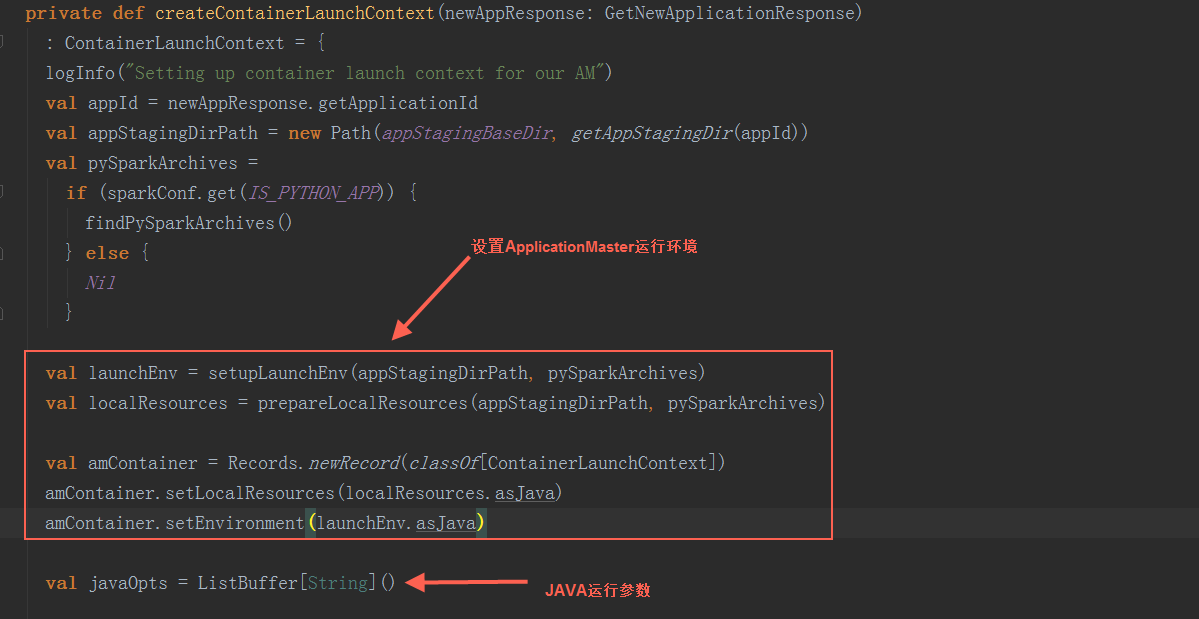
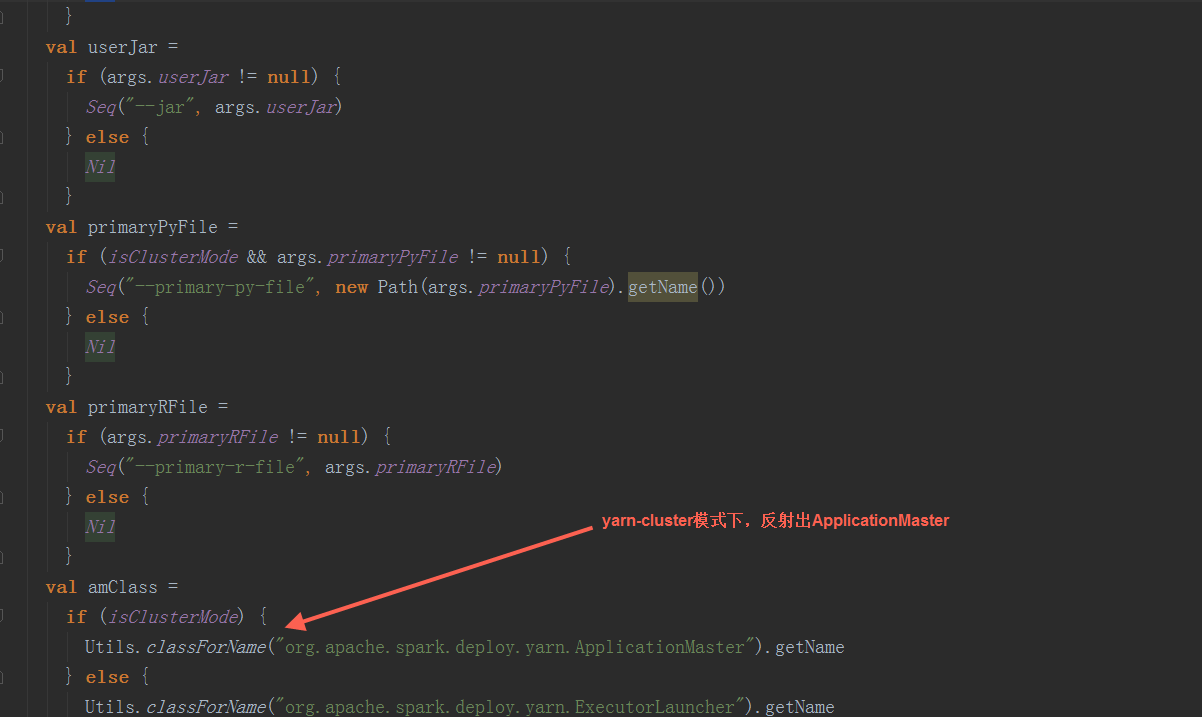
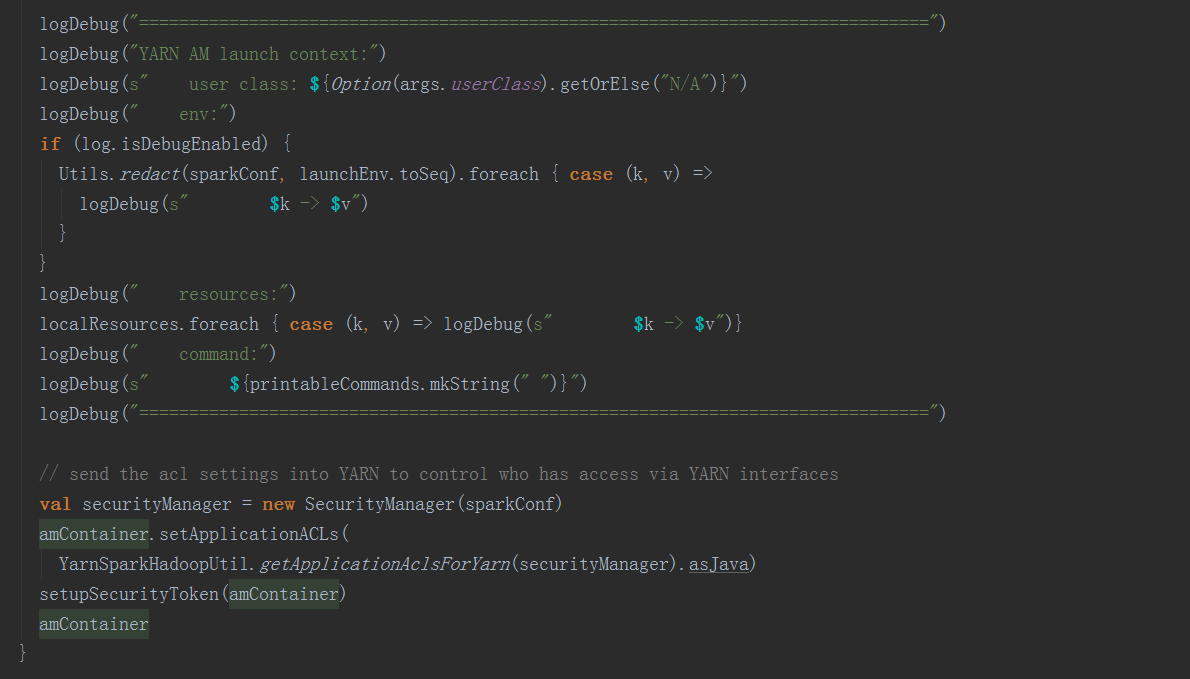 在ApplicationMaster中,其run方法中调用runImpl,如果是集群模式,调用runDriver启动driver端和executor端
在ApplicationMaster中,其run方法中调用runImpl,如果是集群模式,调用runDriver启动driver端和executor端 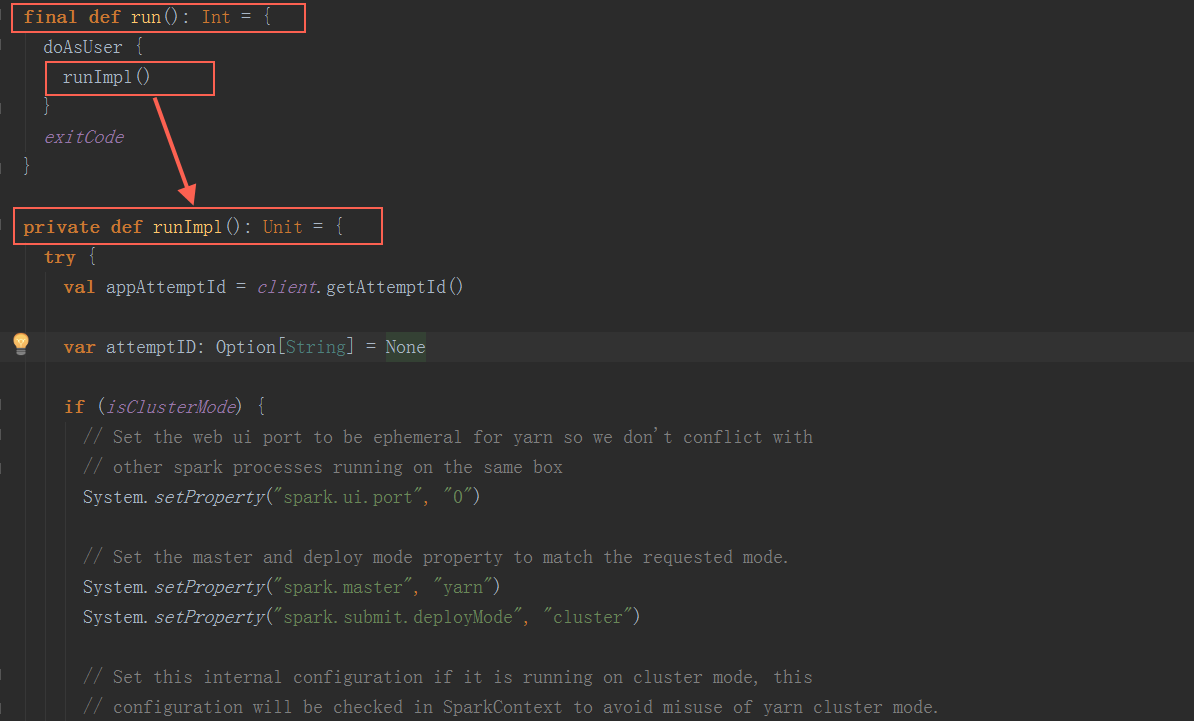
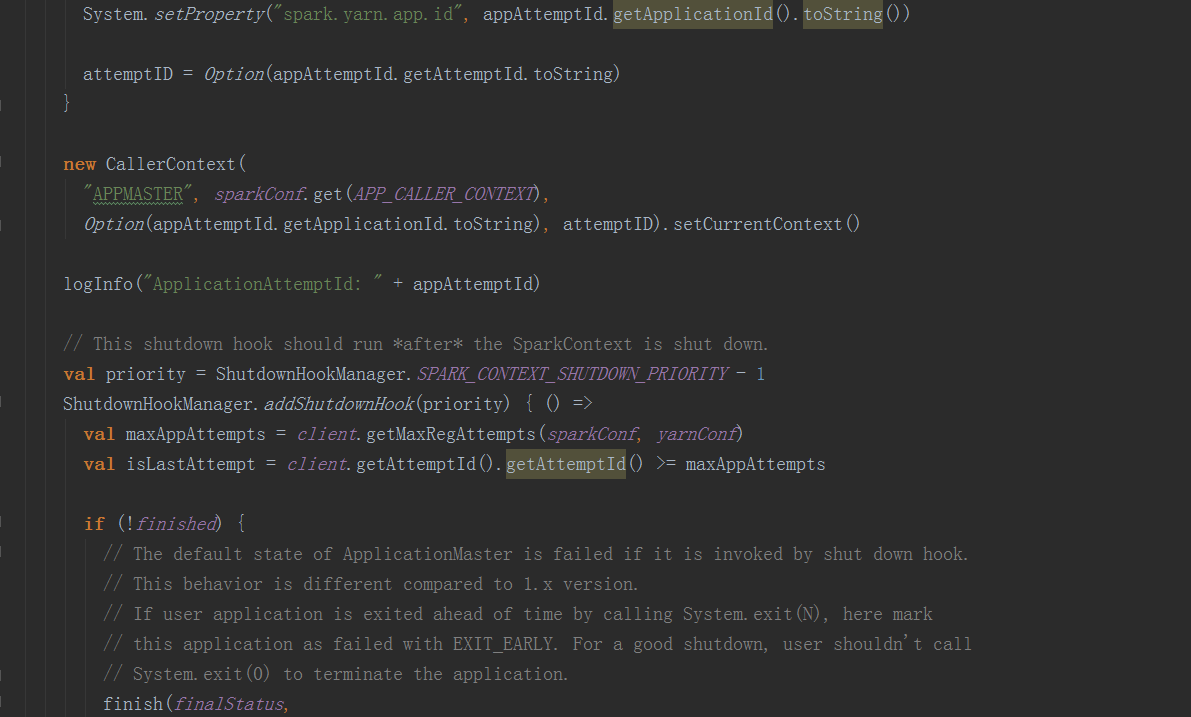
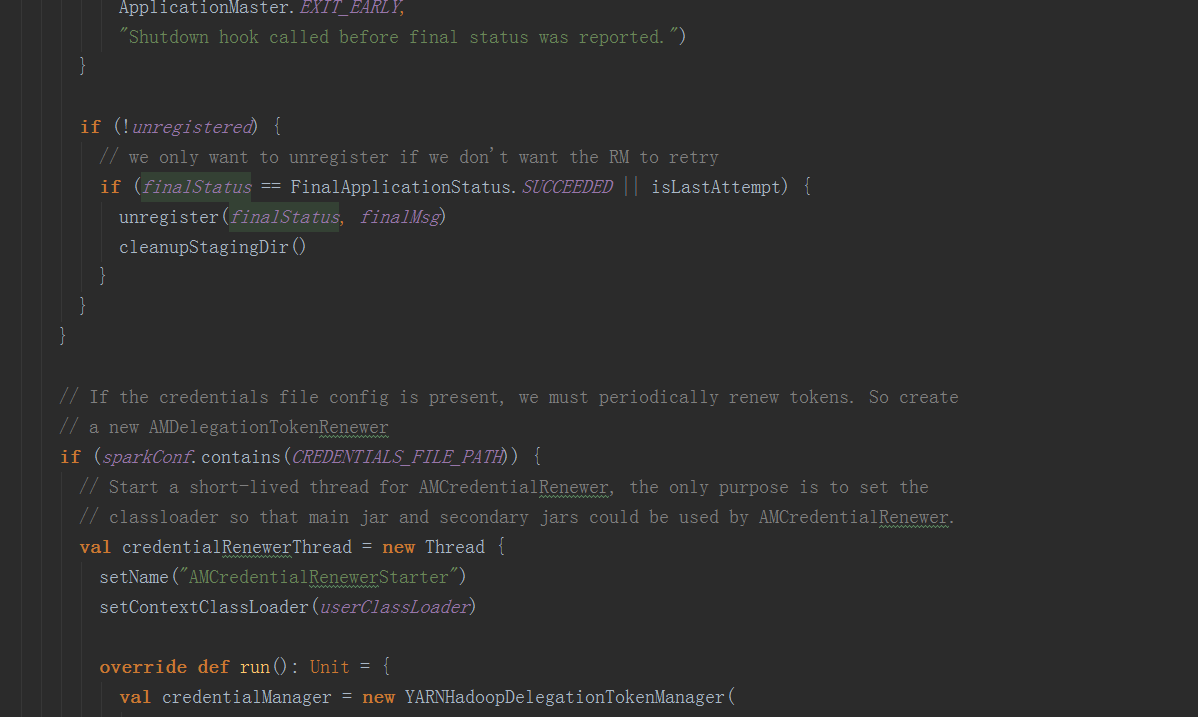
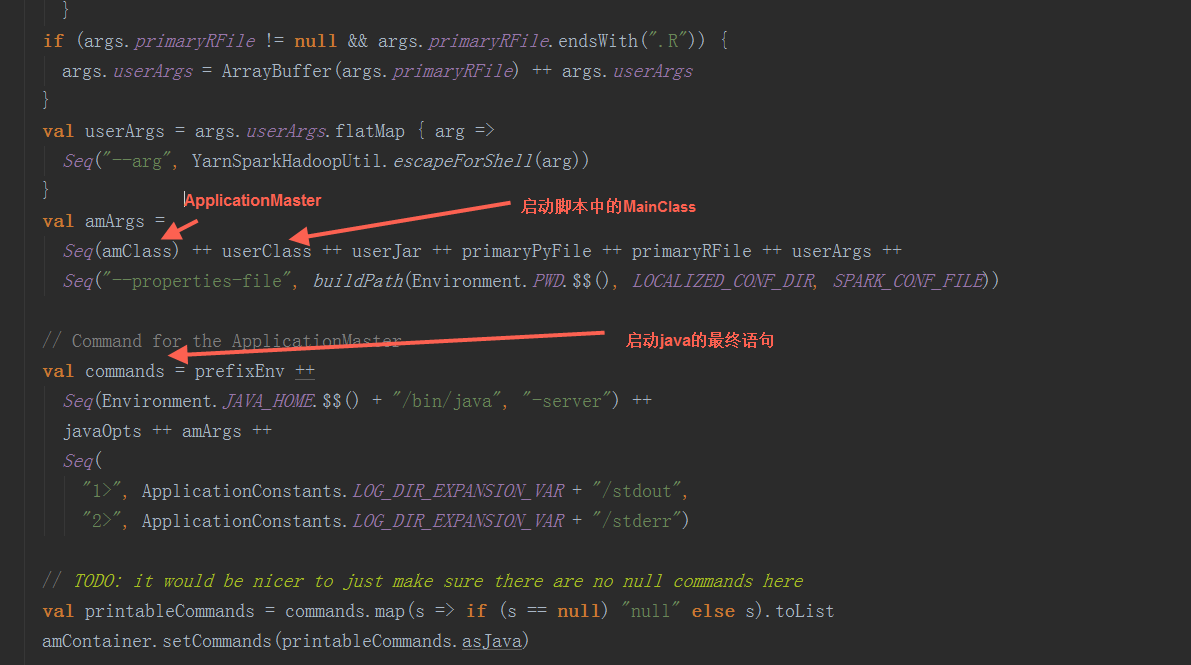
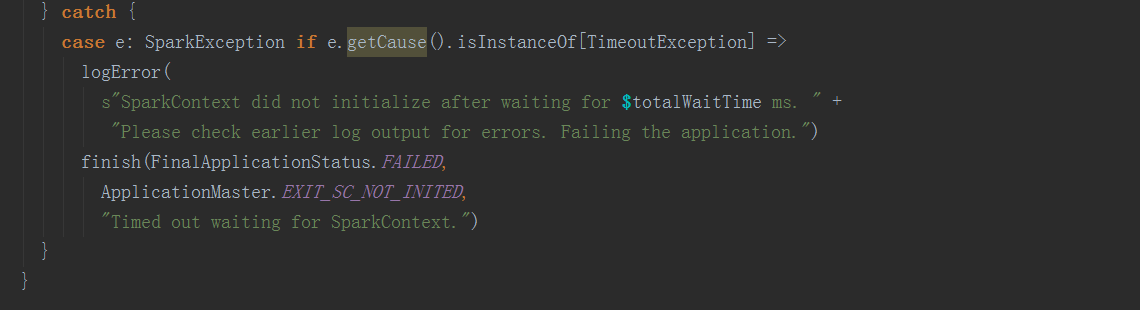
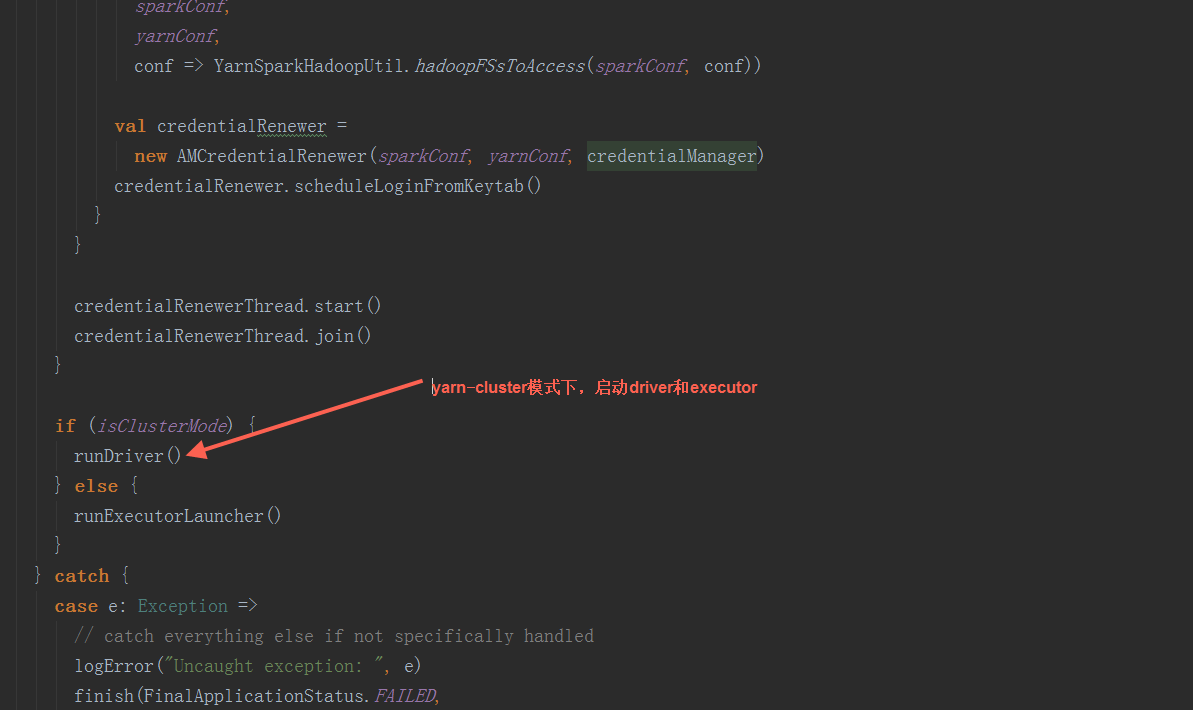 在runDriver方法中,调用startUserApplication方法,创建一个线程,用反射构造出启动脚本中的MainClass,并在线程中执行其main方法。调用registerAM方法,注册driver到yarn集群,并为executor分配资源并启动。
在runDriver方法中,调用startUserApplication方法,创建一个线程,用反射构造出启动脚本中的MainClass,并在线程中执行其main方法。调用registerAM方法,注册driver到yarn集群,并为executor分配资源并启动。 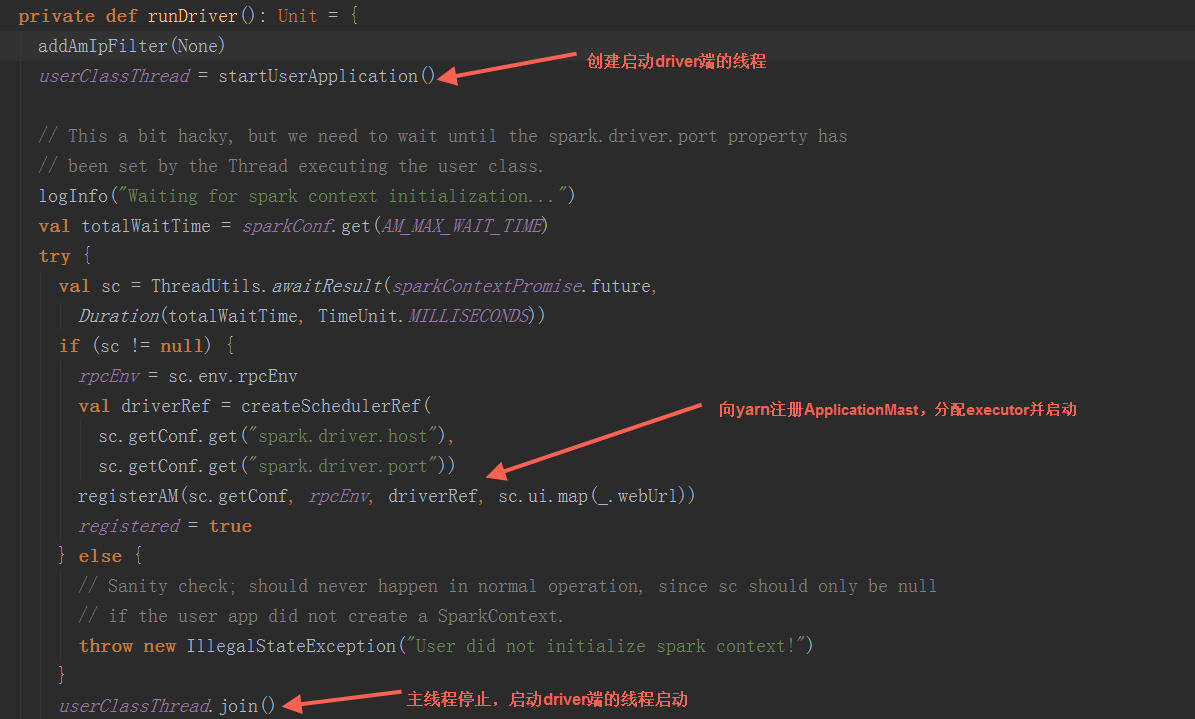
 在startUserApplication方法中,
在startUserApplication方法中, 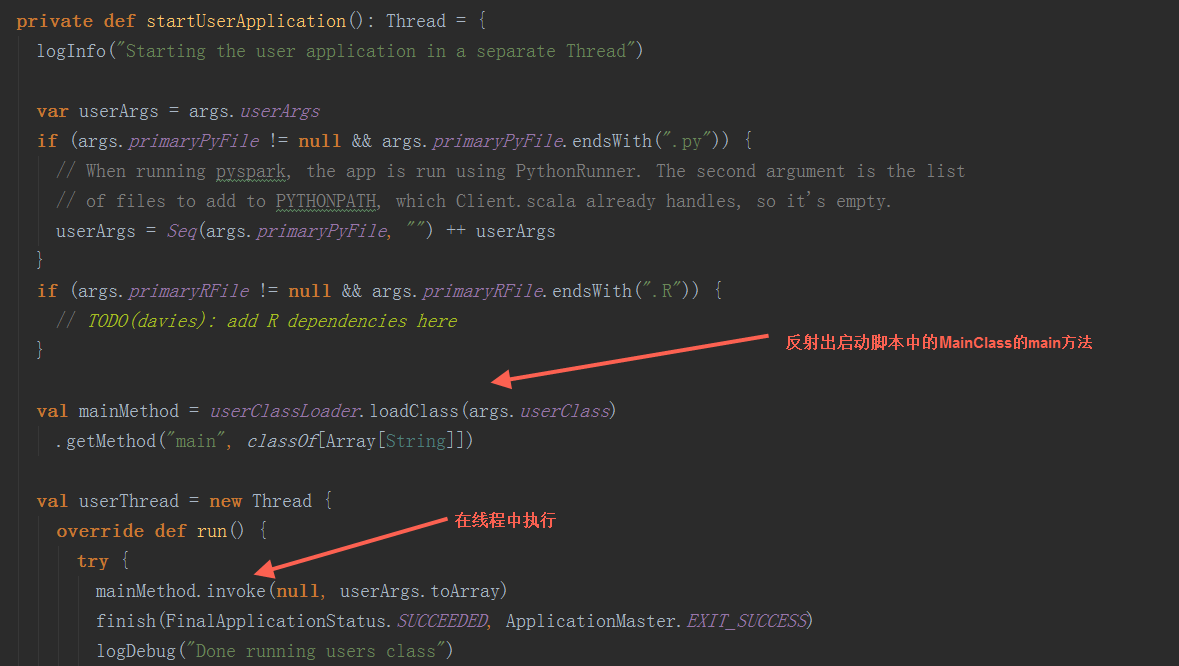
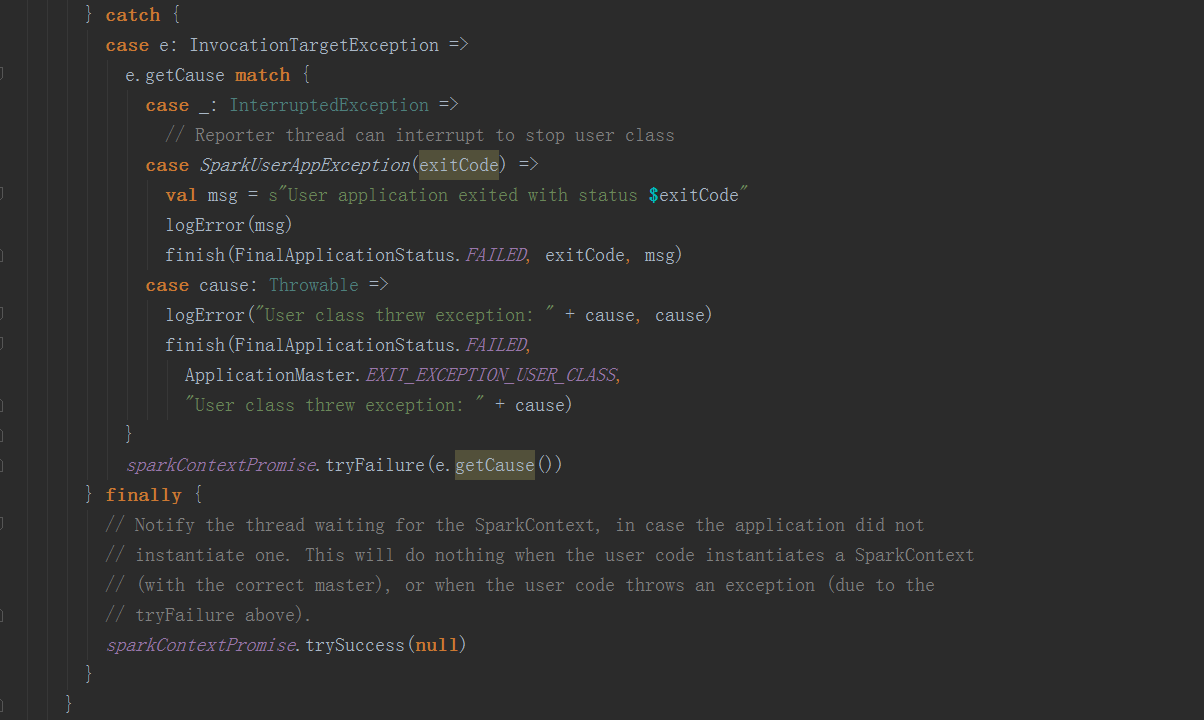
 userClassThread.join通过运行startUserApplication方法返回的线程启动Driver
userClassThread.join通过运行startUserApplication方法返回的线程启动Driver
在其run方法中,通过反射执行userClass中的main方法启动Driver。
- Driver篇
 Spark会将Driver中的任务提交给Executor中,具体的计算是发生在Executor上,调用线程,在线程池用运行计算,每个任务都会有独立的Executor计算。
Spark会将Driver中的任务提交给Executor中,具体的计算是发生在Executor上,调用线程,在线程池用运行计算,每个任务都会有独立的Executor计算。
1) SparkContext
在Driver端SparkContext初始化中, 调用createTaskScheduler方法创建SchedulerBackend和TaskScheduler,实例化DAGScheduler,然后调用TaskScheduler.start方法启动TaskScheduler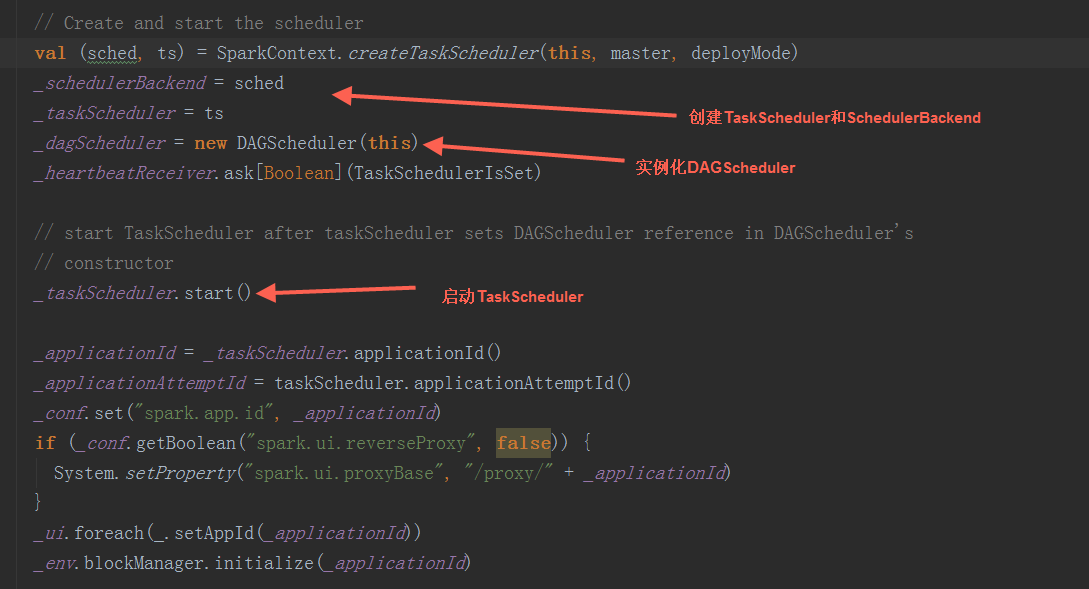

















 1426
1426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









