




 该文章详细探讨了使用3*3滤波器深度增加对图像识别精度的影响,VGG模型在ImageNet2014挑战赛中表现出色。研究发现,小滤波器和堆叠设计有助于减少参数和提高性能。
该文章详细探讨了使用3*3滤波器深度增加对图像识别精度的影响,VGG模型在ImageNet2014挑战赛中表现出色。研究发现,小滤波器和堆叠设计有助于减少参数和提高性能。
题目:VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
论文下载地址:VGG论文
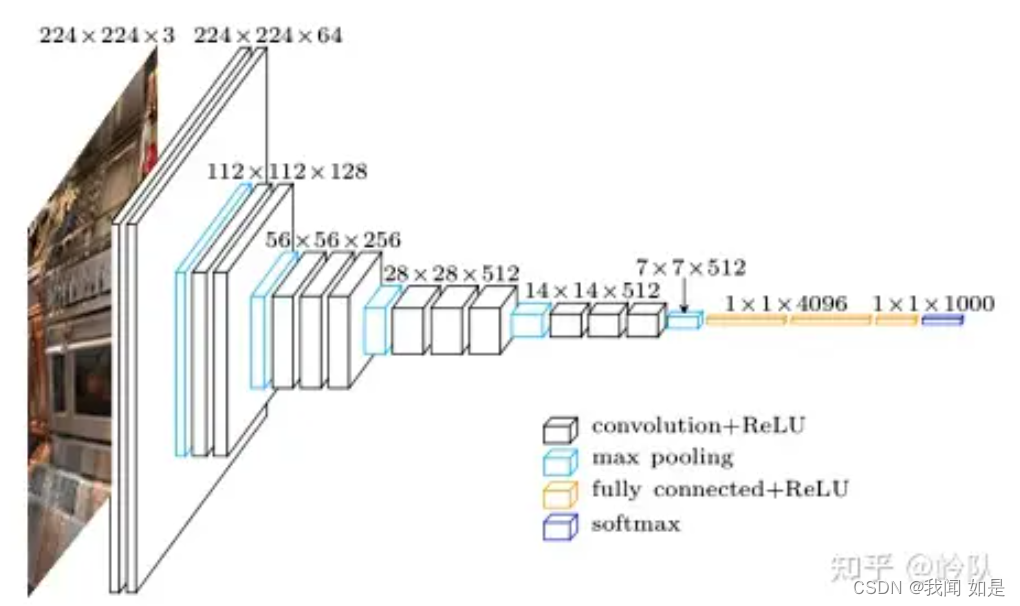
摘要
目的:研究深度对精度的影响
方法:使用3*3滤波器不断增加深度,16和19效果显著
成绩:在ImageNet 2014挑战赛中定位项目第1名,分类项目第2名;在其它数据集上也表现良好。
1、介绍
卷积网络(ConvNets)取得成功,得益于大规模图片库(比如ImageNet)和快速计算系统(比如GPU),也得益于ILSVRC比赛的举行。
研究深度与精度的关系,并使用小的3*3滤波器。
2、ConvNet配置
2.1 配置
输入:224*224(固定尺寸)
预处理:每个像素减去平均RGB值,其
均值为[123.68,116.78,103.94].
滤波器:3*3,也有使用1*1
卷积层参数:stride=1,padding=1
最大池化层:滤波器2*2,stride=2
全连接层:3个(前两个4096个通道,最后一个为1000个,对应分类数)
最后一层:soft-max层
激活函数:ReLU
改进:取消LRN,因为没有增加精度,反而增加计算时间占用内存。
感受野:参考
感受野
重点:堆叠两个3*3的卷积核替代5*5卷积核,堆叠三个3*3的卷积核替代7*7卷积核。拥有相同的感受野,减少参数。
2.2 结构
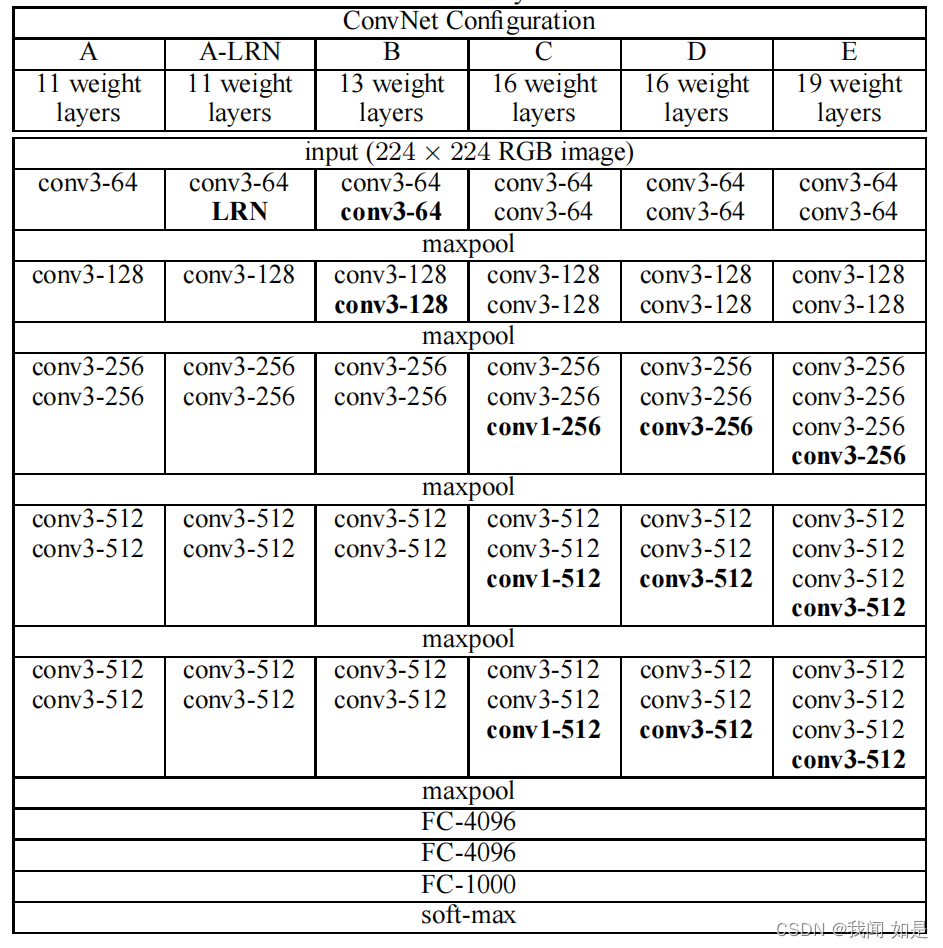

在AlexNet第一层使用11*11滤波器,s=4;ZFNet第一层使用7*7滤波器,s=2的结构。而VGG全部使用3*3的滤波器,s=1,实现全像素卷积。通过堆叠3*3滤波器,也可以减少参数量。比如通道为C,3*3滤波器的参数量为
 ,而同样通道的7*7滤波器,参数量为
,而同样通道的7*7滤波器,参数量为
 ,参数量减少81%。
,参数量减少81%。
3 分类框架
3.1 训练
使用mini-batch gradient descent优化器,设置batch size=256,momentum=0.9.L2设置为5*10-4,dropout=0.5,学习率lr=0.01.
网络的初始化很重要。
3.3 细节
使用C++caffe工具箱,多GPU并行运行。
4 分类实验
数据集
使用ILSVRC-2012数据集,1000个类,分为三组:训练集(130万张)、验证集(5万张)、测试集(10万张)。用top-1和top-5错误率进行评价。
4.1 单尺度评估
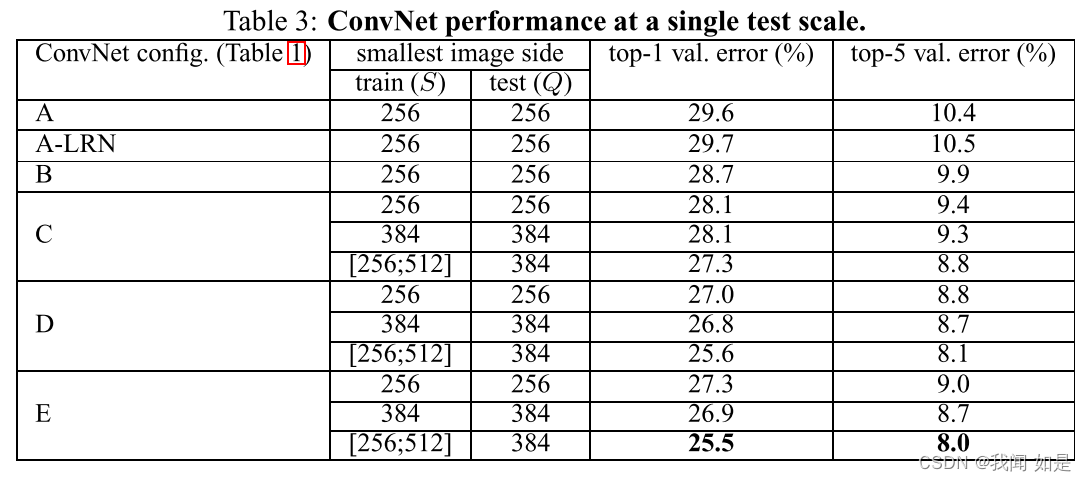
使用LRN和没有使用LRN的效果差不多,所以后面的实验取消了LRN。
小的滤波器优于较大的滤波器。
4.2 多尺度评估
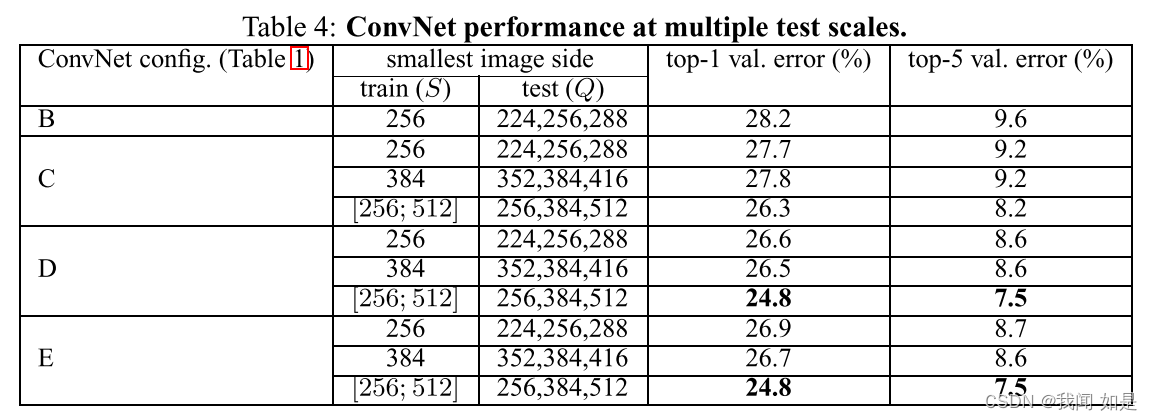
多尺度比单尺度效果更好,尤其层数越深表现越好。
4.3 多裁剪评估
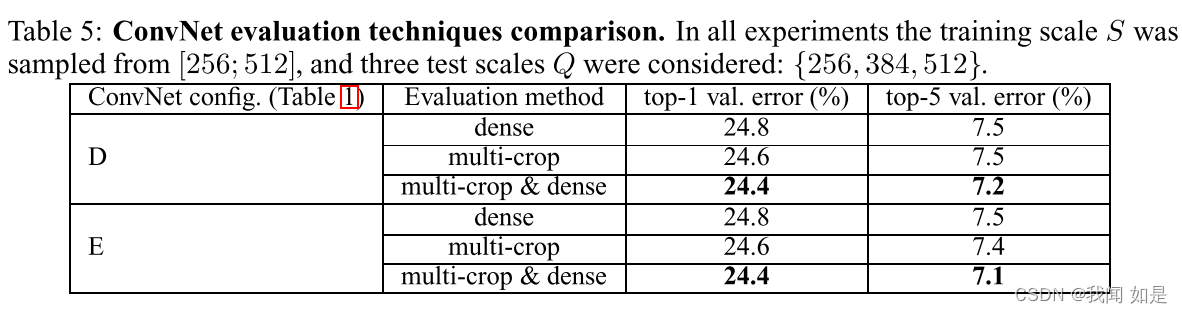
两者组合效果更好。
4.4 卷积融合

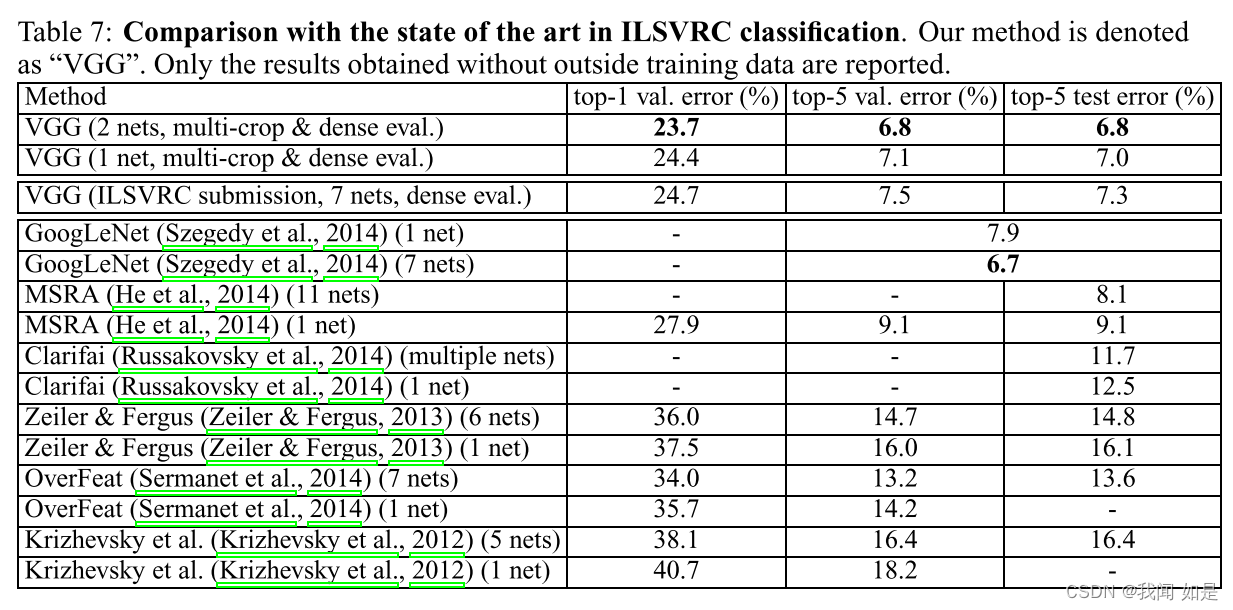
4.5 与其他最好模型的比较
参考资料:

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









