




文章简介
VERY DEEP CONVOLUTIONAL NETWORKS
FOR LARGE-SCALE IMAGE RECOGNITION
该文章介绍了基于深度卷积神经网络的大规模图像分类(经典网络),验证了卷积神经网络的深度对大规模图像分类准确率的影响。
作者:Karen Simonyan & Andrew Zisserman
单位:牛津大学(Visual Geometry Group)
论文地址
论文研究背景
自从2012年AlexNet将深度学习的方法应用 ImageNet的图像分类比赛中并取得state of the art的惊人结果后,大家开始相仿并在此基础上进行大量尝试和改进。
1. 小卷积核
在第一个卷积层用了更小的卷积核和卷积stride
2. 多尺度
训练和测试使用整张图的不同尺度
vgg作者不仅将上面的两种方法应用到自己的网络设计和训练测试阶段,同时还考虑了网络深度对结果的影响。
论文研究成果
2014年在ILSVRC比赛中获得了分类项目的第二名(第一名是GoogLeNet),和定位项目的第一名。同时模型对其他数据集有很好的泛化能力。
VGG由于其结果简单,提取特征能力强,所以应用场景广泛。
例如:快速风格迁移算法,目标检测的backbone,提取特征(faster rcnn, ssd等),gan网络内容特征提取,进行内容计算(内容损失是gan网络损失的一部分)。
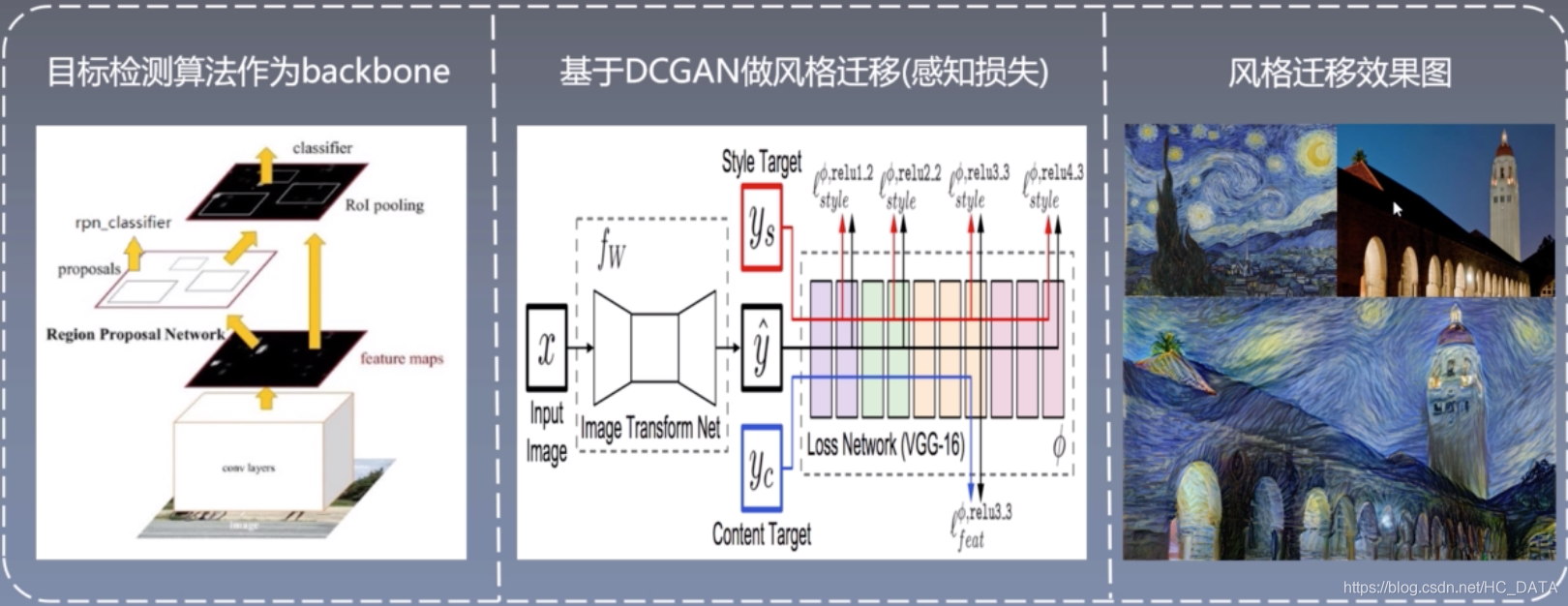
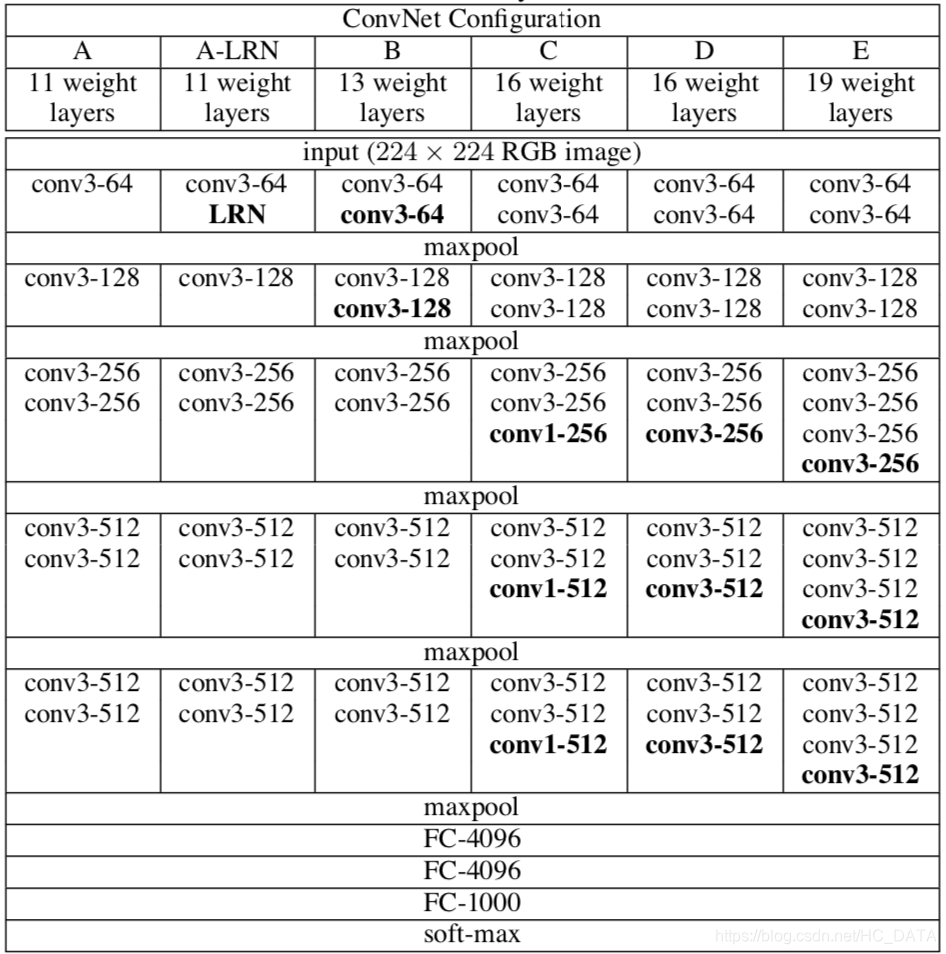
进行了6组对比实验,如下图所示,包括A,A-LRN,B,C,D,E六种不同的网络结构。其中A-LRN网络在A网络的基础上加入了LRN层,B网络在A-LRN网络基础上加入了两个3x3卷积层,C网络在B网络基础上又加入了3个1x1卷积,D网络将C网络中的1x1卷积换成了3x3卷积,E网络又在D网络的基础上加入了3个3x3卷积。
单尺度测试结果对比
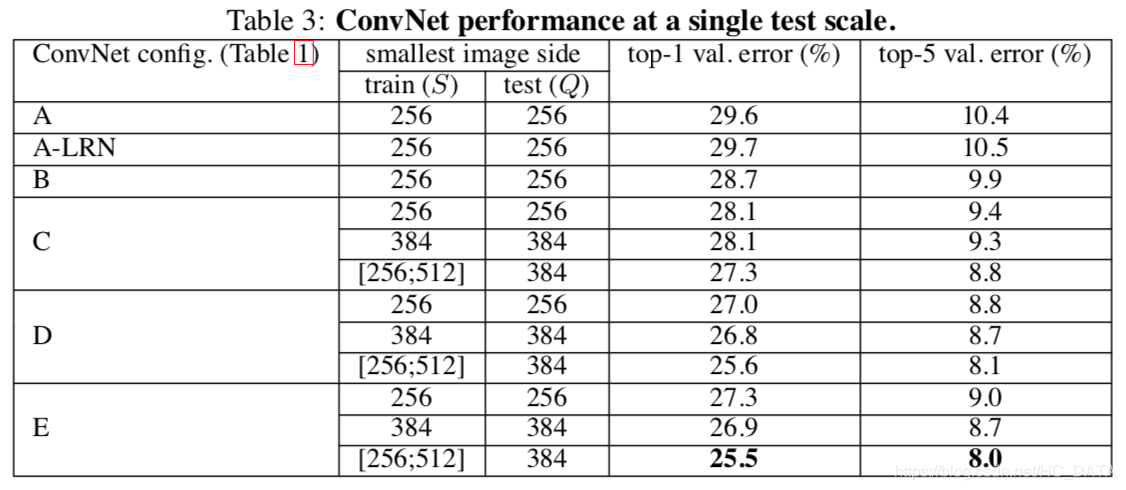
结论:
- LRN对网络性能提升没有太大作用,因此后面网络结构中没有加入LRN层(A和A-LRN对比实验得出)
- 加深网络深度能够提升分类精度(A和B网络对比,C网络第一组实验和A、B网络对比)
- 单独扩大尺度对网络性能提升没什么效果(C网络的第一组和第二组实验对比)
- 对于同一个网络结构多尺度训练可以提高网络精度(C网络的三组实验对比)
- 将1x1的卷积替换为3x3的卷积是有效的(D网络与C网络的实验对比)
- E模型(VGG19)效果最好,一定程度加深网络可以提高网络精度。
多尺度测试结果对比
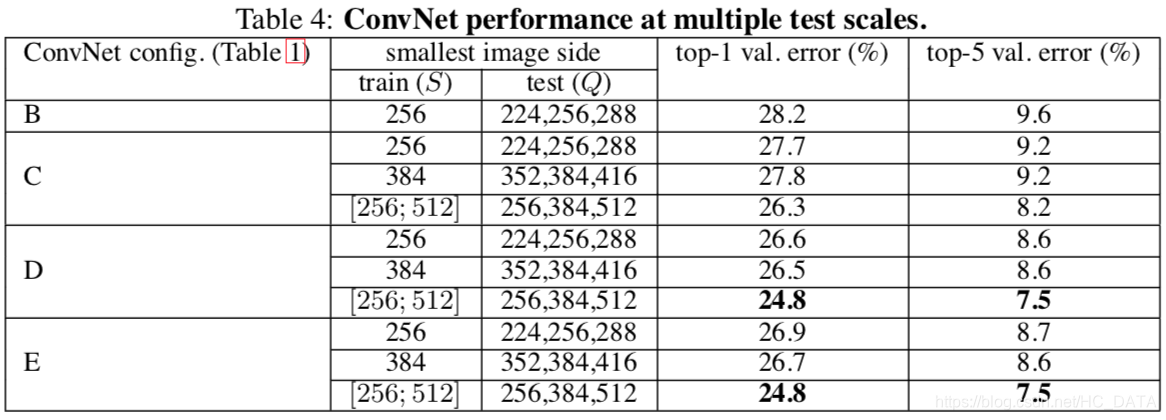
结论
- 对比单尺度预测,多尺度综合预测能够提升预测的精度,证明了scale jittering(尺度抖动)的作用。
- D和E多尺度综合预测效果一样,但是E网络要比D网络深,因此D网络(VGG16)为best model。
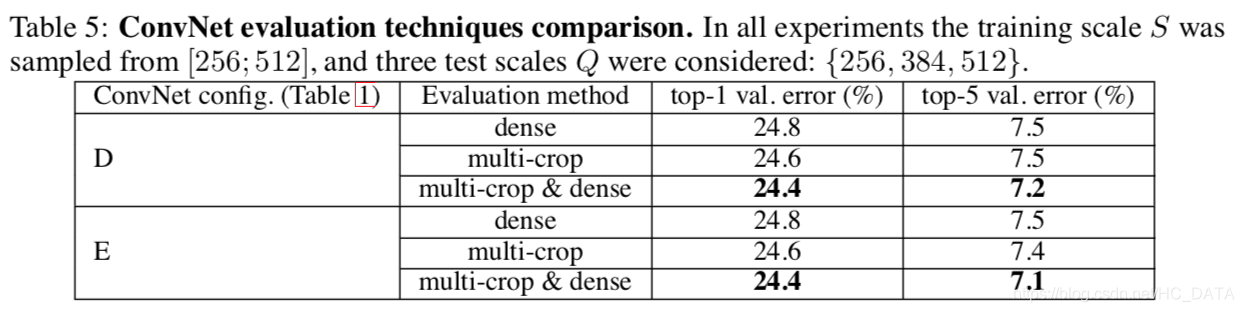
结论:dense evaluation & multi-crop两种测试方法联合使用效果最好
模型融合结果对比
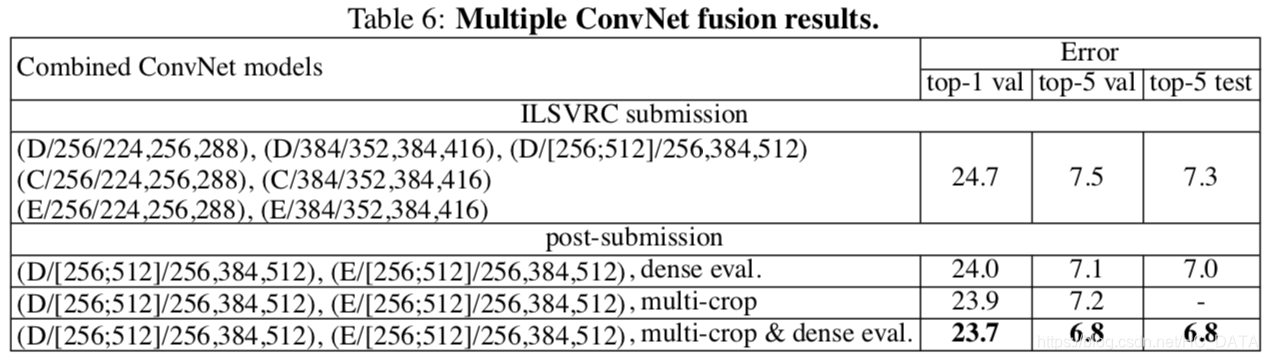
结论: 融合模型D和E之后模型错误率进一步下降
与其他网络结果对比
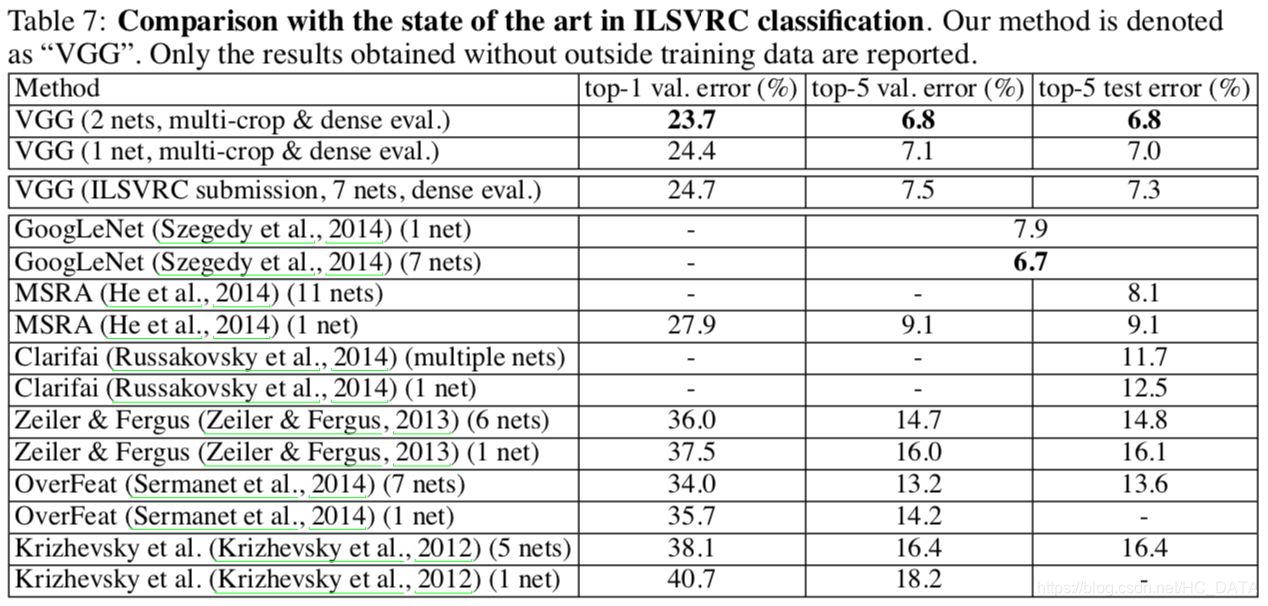
结论:GoogLeNet分类效果冠军,VGG亚军优于其他网络。
论文结论
- 在一定范围内,通过增加深度能有效地提升网络性能;
- 最佳模型VGG16,从头到尾只有3x3卷积与2x2池化,简洁优美;
- 多个小卷积核比单个大卷积核性能好(与Alexnet对比可知);
- AlexNet曾经用到的LRN层并没有带来性能的提升,因此在其他组的网络中均没有出现LRN层;
- 尺度抖动scale jittering(多尺度训练、多尺度测试)有利于网络性能的提升。
感受野
感受野(Receptive Field)的定义是卷积神经网络每一层输出的特征图(feature map)上的像素点在输入图片上映射的区域大小。再通俗点的解释是,特征图上的一个点跟原图上有关系的点的区域。
感受野概念为什么重要?
感受野被称作是CNN最重要的概念之一,目标检测的流行算法比如SSD,Faster-Rcnn等中prior box和Anchor box的设计都是以感受野为依据进行的设计。
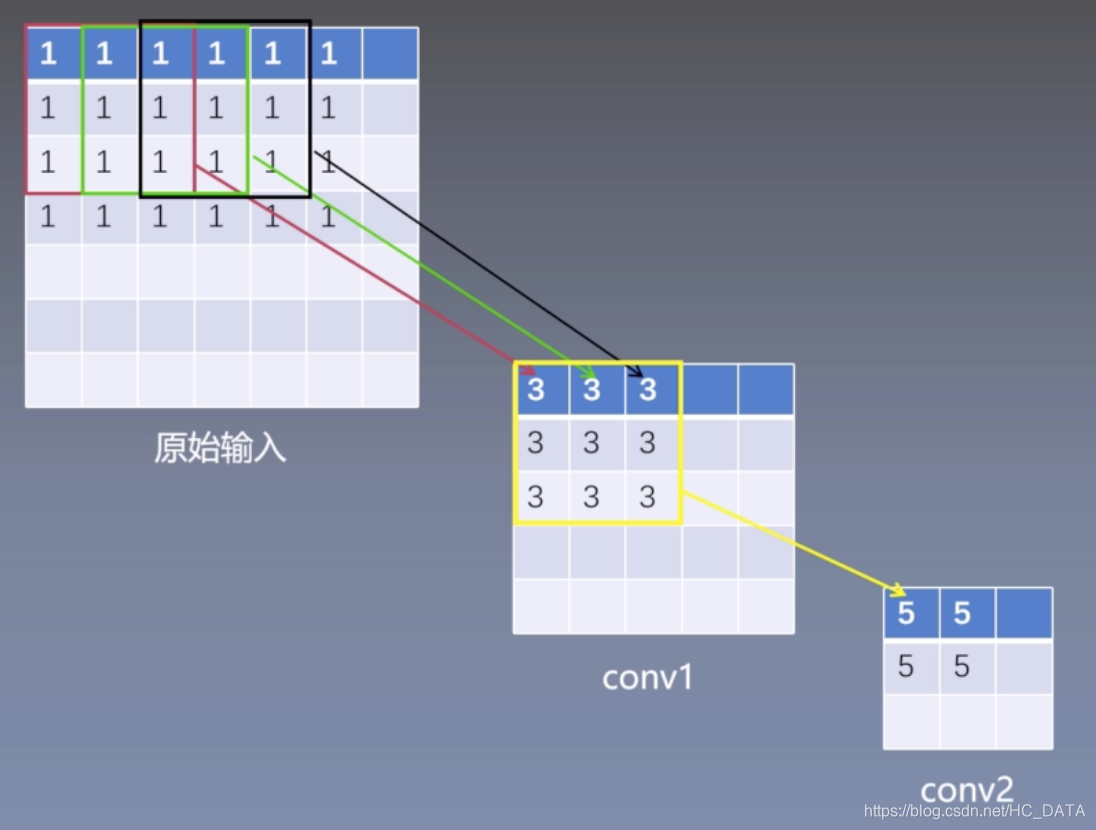
输入原始图大小为7x7,
conv1: 3x3 strides=1 valid
feature: (7-3+1) / 1 = 5
conv2: 3x3 strides=1 valid
feature: (5-3+1) / 1 = 3
原始输入感受野:1
conv1层感受野:3
conv2层感受野:5
思考:
如果conv1: 5x5 strides=1 valid 感受野是多少?
答:感受野为5
结论
1个5x5卷积核感受野大小与2个3x3卷积核的感受野等效,以此类推三个3x3的卷积核的感受野与一个7x7卷积核的感受野等效。
感受野计算公式

注意:这只是理论感受野,实际上起作用的感受野是小于理论感受野
论文结构

摘要
本文研究了在大规模图片识别中,卷积神经网络的深度对准确率的影响。我们的主要贡献是通过非常小的3x3卷积核的神经网络架构全面评估了增加深度对网络的影响,结果表明16-19层的网络可以使现有设置的网络性能得到显著提高。这项发现是我们在2014年的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 149
149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









