




.概述
Transformer架构无疑是大型语言模型(LLMs)成功背后的核心动力。从开源的Mistral到封闭的ChatGPT,几乎所有主流的LLM都在使用这一架构。然而,随着技术的不断进步,研究者们已经开始探索新的架构,有望在未来挑战Transformer的地位。其中,Mamba作为一种状态空间模型,正在成为备受关注的潜力新星。
2.内容
2.1 什么是Mamba?
Mamba 是一种新型的架构,通常被归类为状态空间模型(State Space Model,SSM)。它是为了克服传统神经网络架构(如 Transformer)在处理长期依赖和复杂序列数据时的一些局限性而提出的。Mamba 作为一种新的架构,旨在改进大规模语言模型(LLMs)和其他任务的表现,尤其是在生成任务、自然语言理解、时间序列建模等方面。
1. 背景
传统的 Transformer 架构虽然在许多任务上表现出色,但它在处理非常长的序列时,尤其是需要捕捉长期依赖关系的任务中,面临着计算和内存瓶颈的问题。Mamba 的提出,正是为了解决这些问题,它借用了状态空间模型的原理,从而能够更高效地建模复杂的时间依赖和序列关系。
2. 状态空间模型(SSM)是什么?
状态空间模型是一类数学模型,广泛应用于信号处理和时间序列分析中。其基本思想是通过一个隐含的“状态”来描述系统的演化,而观察到的数据(即输出)是基于这个隐状态的。状态空间模型通常包括一个状态转移方程和一个观测方程,能够有效地捕捉系统的动态变化。
3. Mamba的核心创新
Mamba 是在状态空间模型的基础上发展出来的一种架构,它通过引入可变性和灵活性,试图解决 Transformer 在长序列建模中的一些缺陷。具体来说,Mamba 通过设计更高效的模型参数化和状态空间更新机制,使得模型在捕捉长期依赖时不仅更加高效,同时也能够处理更大规模的数据集和更长的序列。
4. Mamba与Transformer的对比
- 计算效率:Mamba 架构能在处理长序列时显著降低计算和内存的开销,相比于 Transformer 中的自注意力机制,Mamba 更适合于大规模数据的高效处理。
- 长期依赖捕捉:Mamba 在处理长期依赖关系方面具有优势,因为它更善于通过状态空间的更新机制维持长期的记忆。
- 灵活性与扩展性:Mamba 在多个任务上的表现均有所提升,尤其是在需要动态调节模型参数的场景中,Mamba 表现得更加灵活。
Mamba 是在论文《Mamba: Linear-Time Sequence Modeling with Selective State Spaces》中首次提出的一种新型架构。该论文详细介绍了如何通过选择性状态空间来实现线性时间的序列建模。
2.2 Transformer回顾
在了解Mamba架构的独特之处之前,我们先回顾一下Transformer模型及其局限性。Transformer以其将文本输入视作由多个标记构成的序列而著称,但这一视角也带来了一些固有的问题。具体来说,Transformer的一个显著缺点是它对长距离依赖的处理方式,这限制了它在某些任务中的表现。
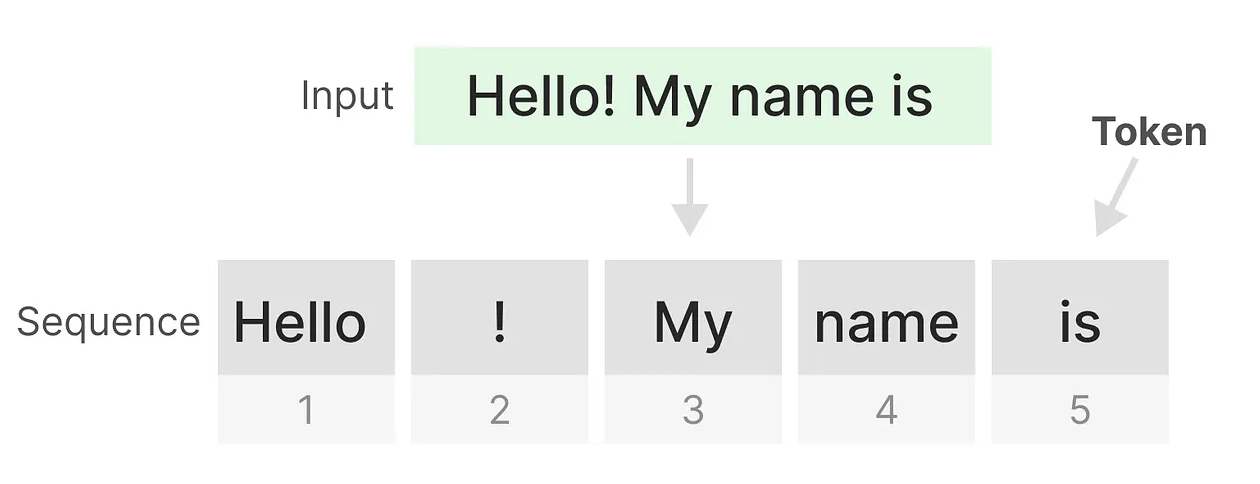
Transformer的一个重要优势在于它能够灵活地“回顾”输入序列中的任何一个先前的标记,无论输入的长度如何。这种自注意力机制使得Transformer能够捕捉到输入中的全局依赖关系,从而生成更准确的表示,尤其适用于处理复杂的文本数据。
2.3 Transformer 的核心组件
Transformer模型由编码器和解码器两个主要部分组成。编码器负责将输入文本转换为高维表示,而解码器则基于这些表示生成目标文本。通过这种结构的协同工作,Transformer不仅能高效地进行语言翻译,还能广泛应用于文本生成、摘要提取等多种任务。
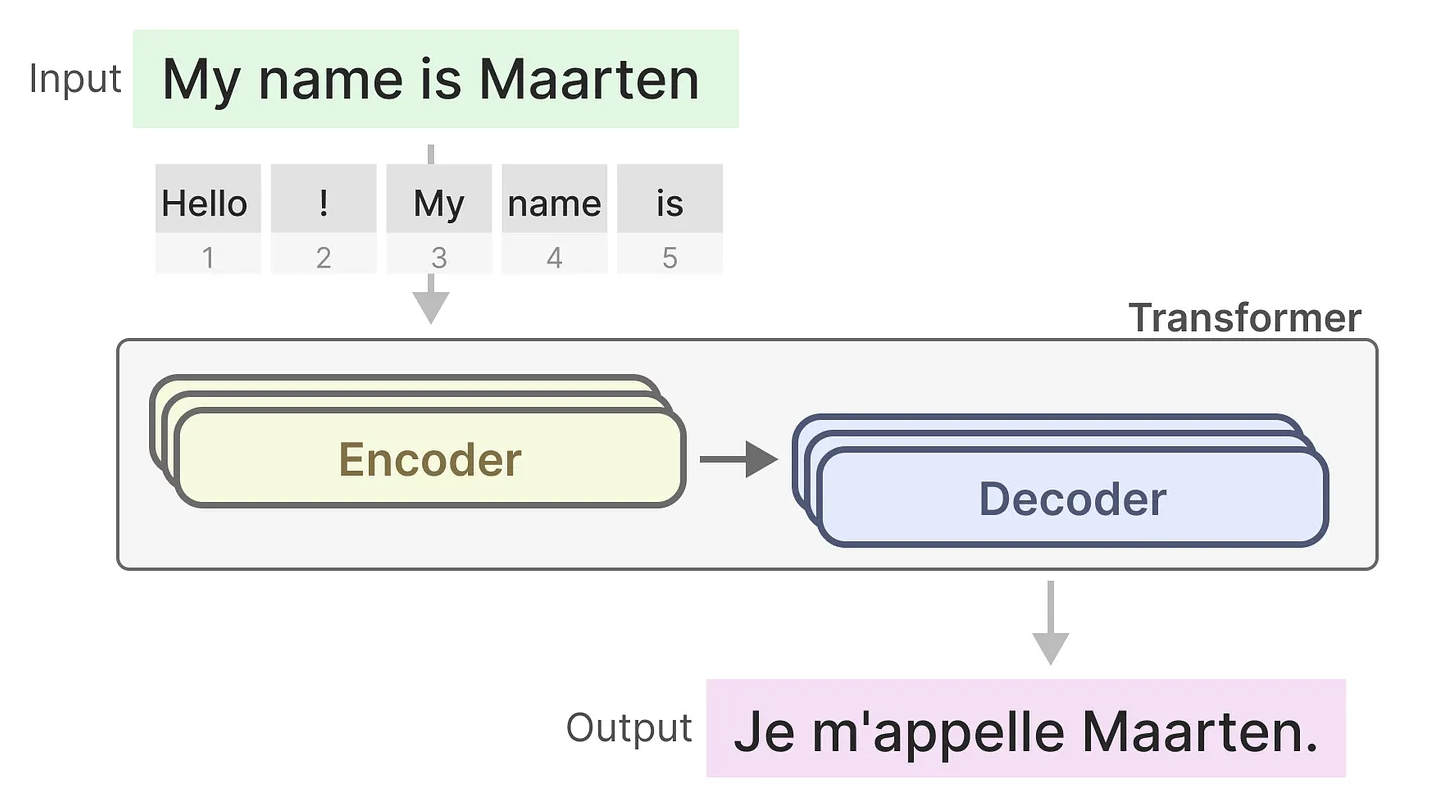
通过只使用解码器部分,我们可以将Transformer架构应用于生成任务,形成一种新的模型——生成式预训练变换器(GPT)。GPT通过解码器块处理输入文本,并生成相关的输出文本,广泛应用于文本生成、对话系统等领域。与传统的编码器-解码器结构不同,GPT通过纯解码器方式直接进行自回归生成,使得它在生成式任务中表现出色。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 325
325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











