







总览学习目录篇 链接地址:https://blog.youkuaiyun.com/xczjy200888/article/details/124057616
B站:李宏毅2020机器学习笔记 3 —— 梯度下降Gradient Descent
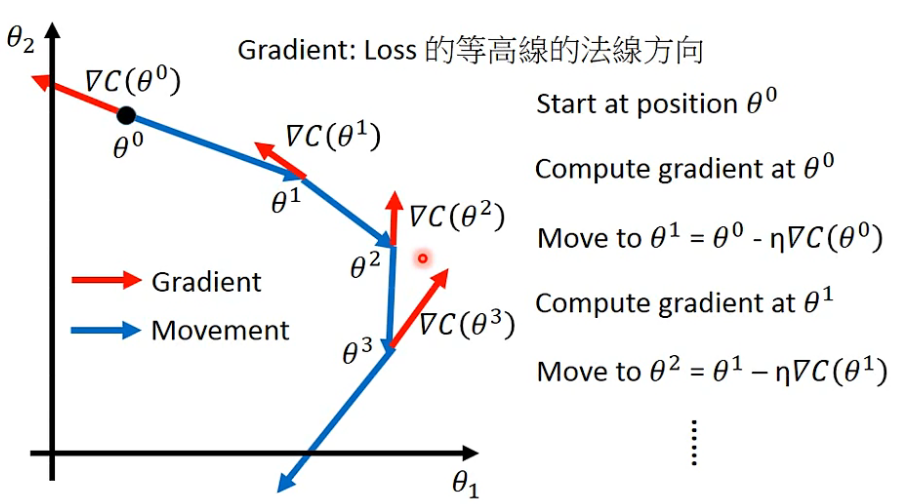
一、回顾:梯度下降
1、在回归篇的第四步已经提到,利用梯度下降算法解决函数参数优化问题

θ
1
θ^1
θ1表示在
θ
0
θ^0
θ0基础上调整后的,下一状态的参数
2、下图中
C
(
θ
)
C(θ)
C(θ)表示的是损失函数
L
(
θ
)
L(θ)
L(θ),下一次的参数优化方向,根据损失函数梯度下降的方向(损失函数递减,因为目的是最小化损失函数)
二、学习率 learning rate
1. 学习率大小的影响
- 当学习率小的时候,损失函数优化速度慢,如蓝色线条
- 当学习率大的时候,损失函数优化速度快,但容易卡主,来回震荡,无法到达最优,如绿色线条
- 当学习率很大的时候,损失函数无法优化,如蓝色线条
- 当学习率刚刚好的时候,损失函数可以得到很好的优化,如红色线条

要确定损失函数值在稳定的下降,才能真正的训练,建议设置learning rate的时候,可以画一下上图右图。
2. 调整学习率
- 起初:学习率设置较大,快速接近最优值
- 后期:在接近最优值时,降低学习率,避免来回震荡

三、梯度下降算法
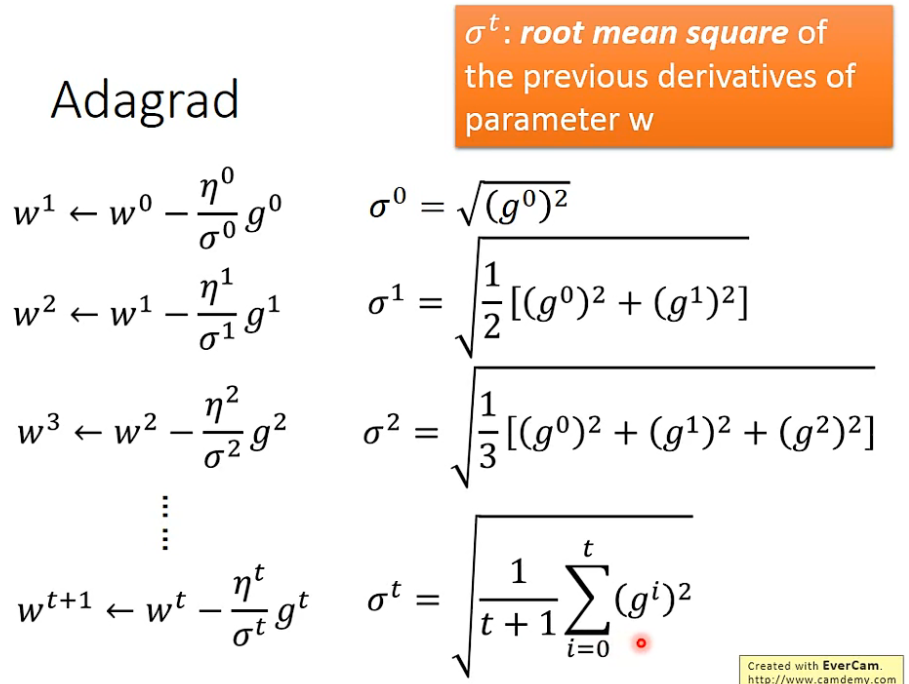
1. 自适应梯度算法 adagrad
1.1 自适应梯度算法提出
- 批处理梯度下降: w t + 1 = w t − η t g t w^{t+1} = w^t-η^tg^t wt+1=wt−ηtgt
- 自适应梯度下降:
w
t
+
1
=
w
t
−
η
t
σ
t
g
t
w^{t+1} = w^t- \frac{η^t}{σ^t}g^t
wt+1=wt−σtηtgt

1.2 σ t σ^t σt参数解释
g
t
g^t
gt表示损失函数对参数的导数
σ
t
σ^t
σt表示
w
w
w之前求导的均方根
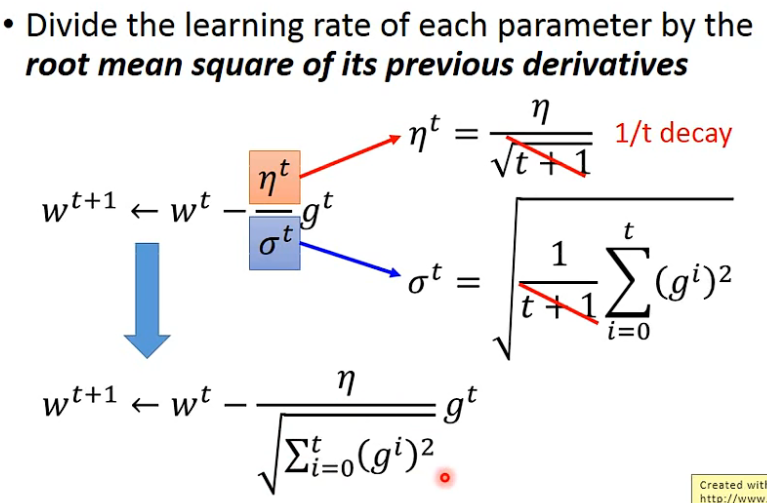
1.3 最终式子
自适应梯度下降:
w
t
+
1
=
w
t
−
η
∑
i
=
0
t
(
g
i
)
2
g
t
w^{t+1} = w^t- \frac{η}{\sqrt{\sum_{i=0}^t{(g^i)^2}}}g^t
wt+1=wt−∑i=0t(gi)2ηgt
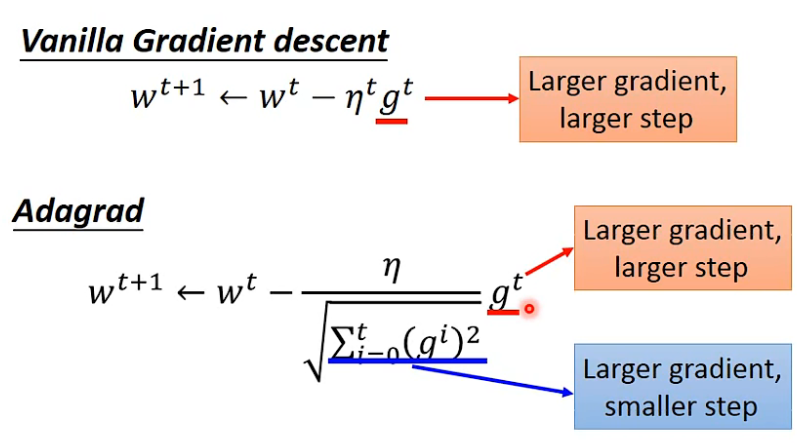
1.4 矛盾点
-
梯度越大,优化step越大,但是在自适应梯度算法中,分母矛盾?
-
解释:

-
如果step的大小和微分的大小成正比,可能是最好的step。只在考虑一个参数时,才成立
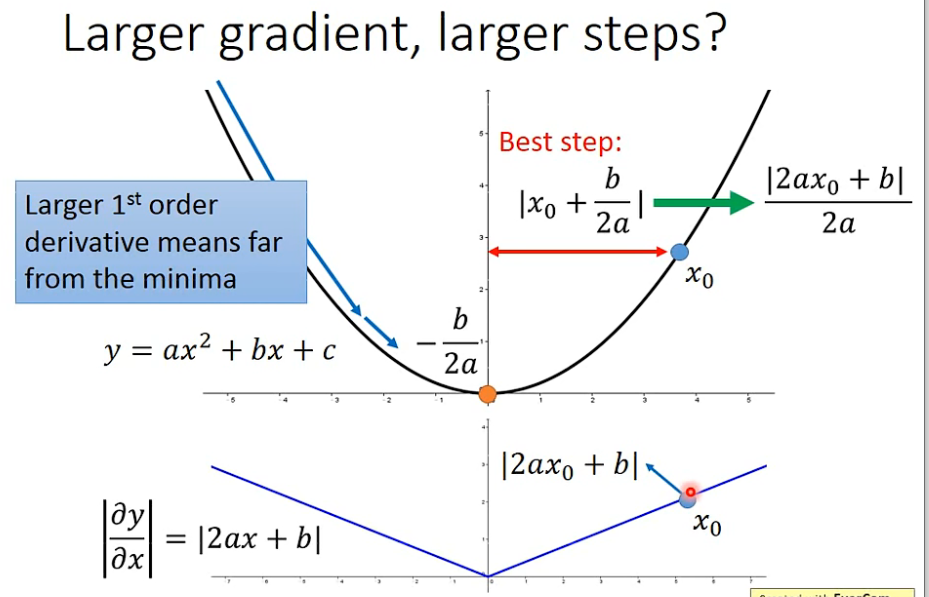
- 从
x
0
x_0
x0开始做梯度下降,最好的step是
∣
x
0
+
b
2
a
∣
|x_0+\frac{b}{2a}|
∣x0+2ab∣,这样就一步到最优了,整理后为
∣
2
a
x
0
+
b
∣
2
a
\frac{|2ax_0+b|}{2a}
2a∣2ax0+b∣,分子刚好等于微分。
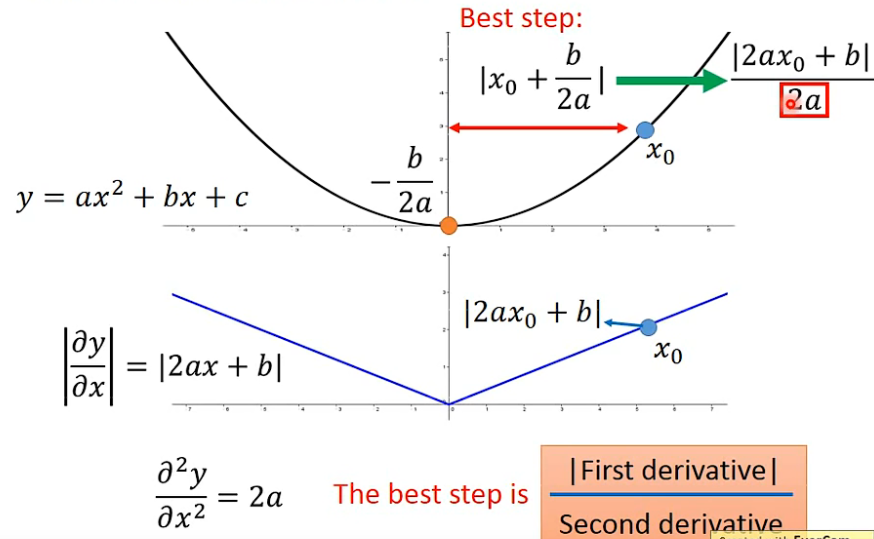
- 从
x
0
x_0
x0开始做梯度下降,最好的step是
∣
x
0
+
b
2
a
∣
|x_0+\frac{b}{2a}|
∣x0+2ab∣,这样就一步到最优了,整理后为
∣
2
a
x
0
+
b
∣
2
a
\frac{|2ax_0+b|}{2a}
2a∣2ax0+b∣,分子刚好等于微分。
-
最好的step,和一次微分成正比,和二次微分成反比。
-
想办法证明: ∑ i = 0 t ( g i ) 2 \sqrt{\sum_{i=0}^t{(g^i)^2}} ∑i=0t(gi)2和二次微分有关系?
- 二次微分和
一
次
微
分
2
\sqrt{一次微分^2}
一次微分2值比较接近
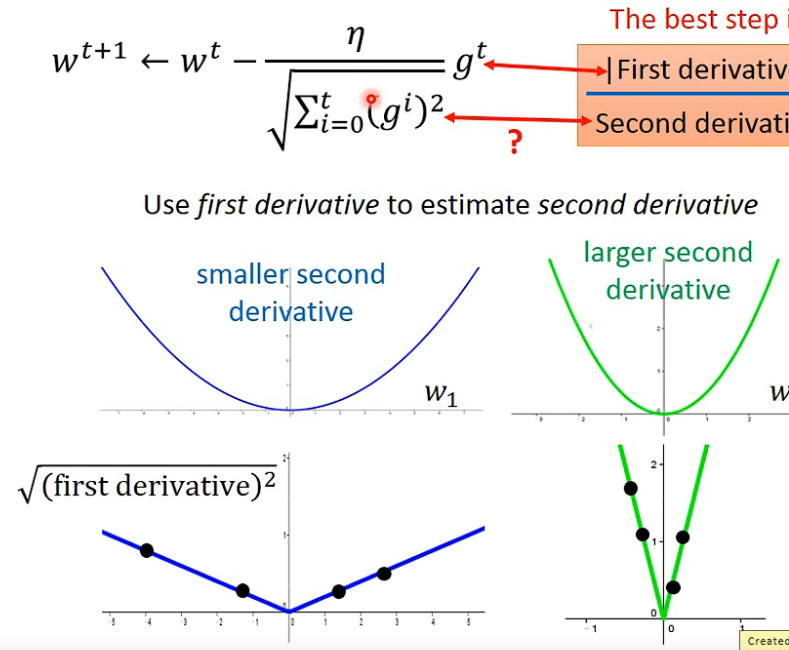
- 二次微分和
一
次
微
分
2
\sqrt{一次微分^2}
一次微分2值比较接近
2. 随机梯度下降算法 stochastic gradient descent
- 随机梯度下降算法:随机选择一个样本计算梯度

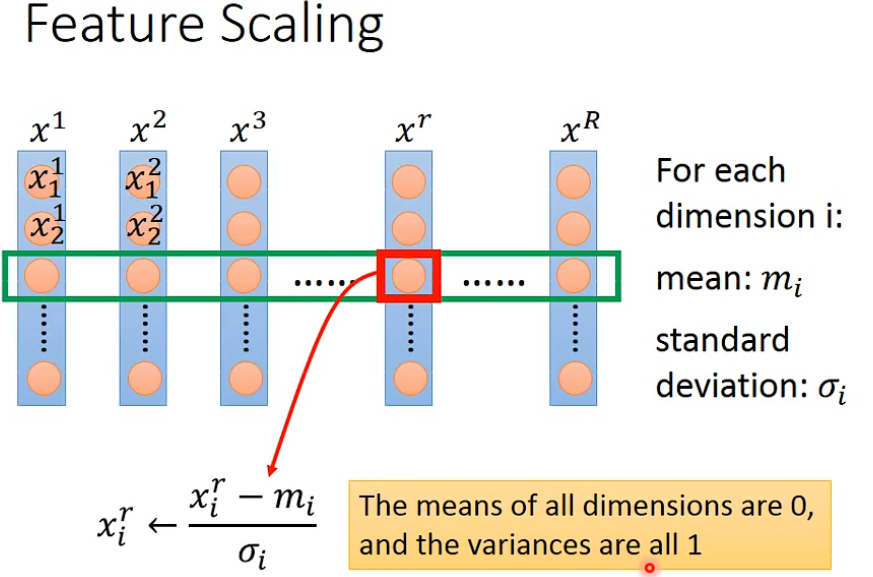
3. 特征缩放 feature scaling
- 特征缩放的目标就是数据规范化,使得特征的范围具有可比性
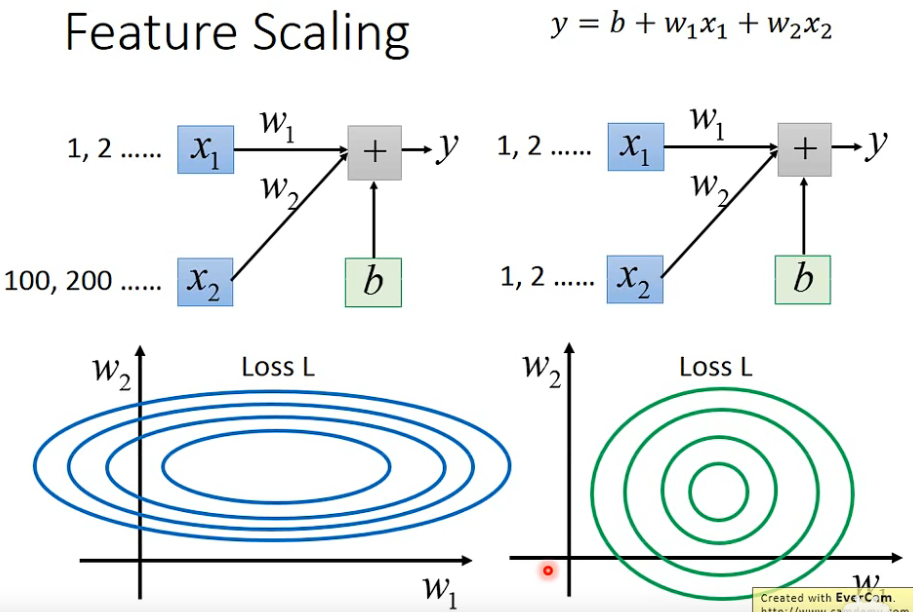
3.1 怎么做特征缩放?
- 调节比例
x ′ = x − m i n ( x ) m a x ( x ) − m i n ( x ) x' = \frac{x-min(x)}{max(x)- min(x)} x′=max(x)−min(x)x−min(x) - 平均值规范化
x ′ = x − m e a n ( x ) m a x ( x ) − m i n ( x ) x' = \frac{x-mean(x)}{max(x)- min(x)} x′=max(x)−min(x)x−mean(x) - 常用:标准化的特征缩放
x ′ = x − m e a n ( x ) s t d ( x ) x' = \frac{x-mean(x)}{std(x)} x′=std(x)x−mean(x)
四、梯度下降理论基础
1. 泰勒级数 Taylor series
- 一个参数的泰勒展开式

- 多参数的泰勒展开式

2. 两个参数的梯度下降
- 两个参数:
s
s
s和
θ
θ
θ无关,所以想要
L
(
θ
)
L(θ)
L(θ)值最小化,就是寻求在原点为(a,b)基础上,向量
(
u
,
v
)
(u,v)
(u,v)和向量
(
θ
1
−
a
,
θ
2
−
b
)
(θ_1-a,θ_2-b)
(θ1−a,θ2−b)乘积的最小值,就是他们反方向的时候。

- u u u相当于损失函数对 θ 1 θ_1 θ1的一阶导数(根据泰勒展开式至第一阶导数,根据极限,要 x x x和 y y y越接近 x 0 x_0 x0, y 0 y_0 y0,展开式的后面几项才可忽略;越接近,相当于红色圆圈半径越小)
-
v
v
v相当于损失函数对
θ
2
θ_2
θ2的一阶导数

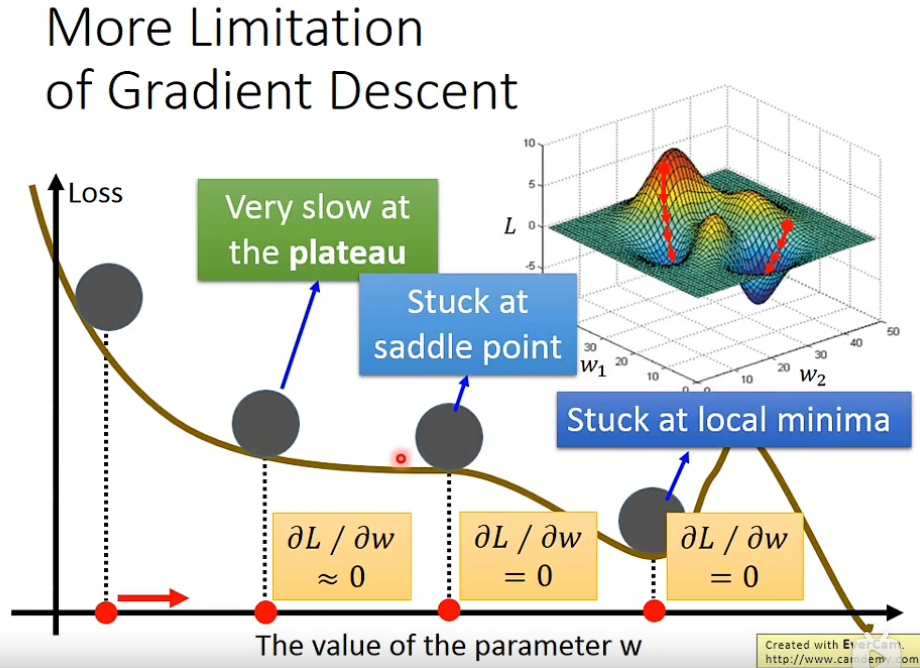
3. 梯度下降算法限制
- 在高原点,导数值接近0,以为已经到达最优点,优化就停下来了
- 在鞍点,导数值接近0,陷入局部最优点


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











