




一、通俗易懂的例子解析
为了直观理解Jaro算法的工作原理,我们以比较两个相似名字"MARTHA"和"MARHTA"为例。这两个名字在发音上几乎相同,只是中间的字母顺序略有不同。
首先,我们计算两个字符串的匹配窗口大小。匹配窗口(MW)定义为:MW = floor(max(len(s1), len(s2))/2) - 1 。对于这两个长度均为6的名字,MW = floor(6/2)-1 = 2。这意味着在比较字符时,如果一个字符在字符串s1中的位置与它在字符串s2中的位置相差不超过2,那么这两个字符被视为匹配。
接下来,我们逐个字符进行匹配。从第一个字符开始,M与M匹配;第二个字符A与A匹配;第三个字符R与R匹配;第四个字符T与H不匹配,但H在第五个位置,距离第四个位置相差1(不超过MW=2),因此T与H匹配;第五个字符H与T不匹配,但T在第四个位置,距离第五个位置相差1,因此H与T匹配;最后一个字符A与A匹配。这样,两个字符串共有6个匹配字符,即m=6。
然后,我们需要确定换位数目(t)。换位是指匹配字符在两个字符串中的顺序不同的情况。在匹配字符序列中,MARTHA的匹配字符顺序是M-A-R-T-H-A,而MARHTA的匹配字符顺序是M-A-R-H-T-A。比较这两个序列,发现T和H的位置发生了交换。每个换位涉及两个字符,因此换位数目t=2/2=1。
最后,计算Jaro相似度:
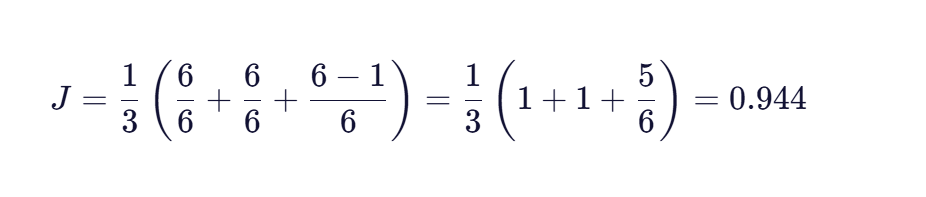 相似度得分为0.944(接近1),表明这两个字符串非常相似,符合我们的直观判断。
相似度得分为0.944(接近1),表明这两个字符串非常相似,符合我们的直观判断。
另一个例子是比较"DwAyNE"和"DuANE"。这两个字符串的匹配窗口MW=2(假设两个字符串长度分别为5和4)。通过匹配窗口比较,发现D、A、N、E四个字符匹配,因此m=4。由于所有匹配字符的顺序都相同,没有换位,t=0。计算Jaro相似度:
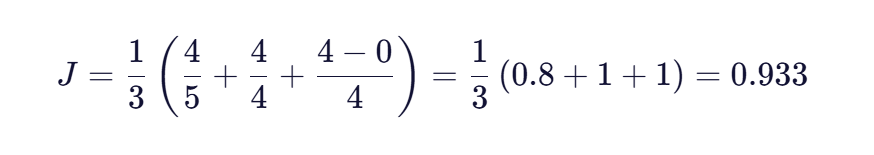 虽然两个字符串长度不同且首字母大小写不同,但相似度仍然很高,这展示了Jaro算法在处理实际应用中的灵活性。
虽然两个字符串长度不同且首字母大小写不同,但相似度仍然很高,这展示了Jaro算法在处理实际应用中的灵活性。
二、Jaro算法原理步骤详解
Jaro算法的计算过程可以分为以下几个关键步骤:
第一步:确定匹配窗口大小
匹配窗口是Jaro算法的基础概念,它决定了在比较两个字符串时,字符之间的最大允许距离。窗口大小计算公式为:
MW = floor(max(len(s1), len(s2))/2) - 1
这个窗口大小确保了算法只关注字符在相对位置上的匹配,而非绝对位置。例如,对于长度为10的字符串,窗口大小为4,意味着一个字符在s1中的位置i,最多可以与s2中位置i-4到i+4范围内的字符进行匹配。第二步:找出匹配字符对
- 遍历两个字符串中的每个字符,寻找在匹配窗口范围内且未被重复匹配的字符对。具体步骤如下:初始化两个数组(或标记数组)来记录已匹配的字符位置
- 对于字符串s1中的每个字符,检查字符串s2中在匹配窗口范围内的字符
- 如果找到匹配且未被标记,则记录匹配位置并标记为已匹配
- 确保每个字符只能匹配一次,避免重复计算
第三步:计算匹配字符数(m)
- 匹配字符数m是两个字符串中成功匹配的字符对的总数。在计算m时,需要注意两点:匹配字符必须在各自的字符串中处于匹配窗口范围内
- 每个字符只能匹配一次,不能重复使用
第四步:确定换位数目(t)
- 换位数目是指匹配字符对中顺序不同的字符对数量。具体计算方法如下:将两个字符串中的匹配字符提取出来,形成两个字符序列
- 比较这两个序列中的字符顺序
- 统计字符顺序不同的位置对数
- 换位数目t为统计结果的一半(因为每对换位涉及两个字符)
第五步:计算Jaro相似度
基于前面计算的结果,应用Jaro相似度公式进行计算:

其中,m是匹配字符数,t是换位数目,|s1|和|s2|分别是两个字符串的长度。
三、Jaro相似度公式总结与解释
Jaro相似度的数学公式可以分解为三个主要部分,每个部分都反映了字符串相似度的不同维度:
公式一:匹配字符比例
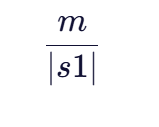
这一部分表示字符串s1中匹配字符的比例。其中,m是匹配字符数,|s1|是字符串s1的长度。该比例越高,说明s1中有越多的字符在s2中找到匹配,字符串相似度也就越高。
公式二:匹配字符比例
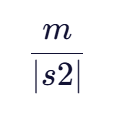
这一部分与公式一类似,但针对字符串s2。它反映了s2中字符被匹配的比例,同样越高表示相似度越高。
公式三:匹配字符顺序一致性
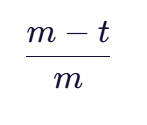
这一部分衡量了匹配字符的顺序一致性。其中,t是换位数目,即匹配字符中顺序不同的字符对数的一半 。当t=0时,说明所有匹配字符的顺序都相同,这部分得分为1;当t增加时,得分会相应降低,反映出字符顺序差异对相似度的影响。
最终的Jaro相似度是这三个部分的平均值:
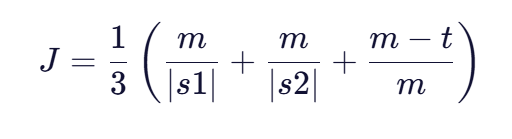
在实际应用中,Jaro相似度的取值范围在0到1之间,其中:
- 1表示两个字符串完全相同
- 0表示两个字符串完全不同
- 0.9以上通常表示字符串高度相似
- 0.7以上可能表示字符串有一定程度的相似性
需要注意的是,当m=0时(即两个字符串没有匹配字符),Jaro相似度直接为0,无需进行其他计算。这是因为此时两个字符串没有任何共同字符,相似度显然为零。
四、Jaro与Jaro-Winkler的区别
Jaro算法后来被William E. Winkler改进,形成了Jaro-Winkler算法 。两者的主要区别在于Jaro-Winkler增加了对字符串开头相同部分的敏感度,特别适用于人名等字符串的匹配。
Jaro-Winkler的相似度计算公式为:
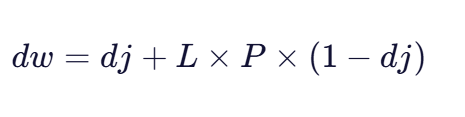
其中:
- dj是Jaro相似度
- L是前缀部分匹配的长度(通常最大为4)
- P是一个调整因子(通常设为0.1,最大不超过0.25)
例如,对于"MARTHA"和"MARHTA",如果前缀匹配长度L=3(前三个字符M-A-R相同),则Jaro-Winkler相似度为:
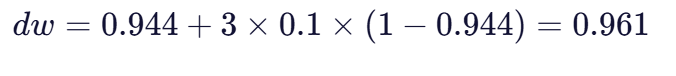
这种改进使得算法对字符串开头相同部分更加敏感,从而提高了相似度评估的准确性,特别是在处理人名等需要考虑姓氏或首字母的场景。
五、Jaro算法的应用场景
Jaro算法作为一种高效的字符串相似度计算方法,在实际应用中有多种重要用途 :
数据清洗与去重:在数据处理过程中,经常需要识别和合并重复的记录。Jaro算法可以快速计算不同字符串之间的相似度,帮助识别潜在的重复数据。例如,在客户信息表中,"张伟"和"伟张"可能指向同一个人,Jaro算法可以有效识别这种相似性。
拼写纠错:在搜索引擎或输入法中,Jaro算法可以用来评估用户输入的字符串与正确字符串之间的相似度,从而提供拼写建议或自动纠错。例如,当用户输入"exmaple"时,算法可以识别出与"example"的相似度较高。
记录链接:在数据整合过程中,Jaro算法可以用来匹配不同数据源中的相同实体。例如,医院系统中可能有多个记录描述同一位患者,但姓名拼写略有不同,Jaro算法可以帮助识别这些记录。
地址匹配:在物流或地图服务中,Jaro算法可以用来匹配相似的地址。例如,"北京路1号"和"北京路1号"虽然完全相同,但"北京路1号"和"北京路1号"由于存在一个换位字符(“京"和"口”),相似度会相应降低。
姓名匹配:在用户认证或身份识别系统中,Jaro算法可以用来匹配相似的姓名。例如,"李明"和"李铭"虽然有一个字符不同,但由于匹配窗口的存在,算法可以识别出它们的高度相似性。
六、Jaro算法的局限性
尽管Jaro算法在处理短字符串相似度计算方面表现良好,但它也存在一些局限性:
匹配窗口的固定性:Jaro算法的匹配窗口是基于字符串长度计算的固定值,这可能在某些情况下不够灵活。例如,对于较长的字符串,匹配窗口可能过大,导致一些不相关的字符也被视为匹配。
换位计算的简化性:Jaro算法将换位数目简单地定义为顺序不同的字符对数的一半,这可能无法准确反映复杂的字符顺序差异。例如,对于多个字符需要交换的情况,算法可能低估了顺序差异的影响。
不考虑字符插入或删除:与编辑距离算法不同,Jaro算法主要关注字符匹配和顺序,不考虑字符的插入或删除操作。这在某些情况下可能限制算法的适用性。
对长字符串的敏感度不足:对于较长的字符串,Jaro算法的相似度评分可能不够敏感,因为匹配字符的比例可能被稀释。例如,两个长度为100的字符串,即使有90个字符匹配且顺序相同,相似度评分可能仅为0.9,这在某些应用中可能不够准确。
不考虑字符权重:Jaro算法对每个字符赋予相同的权重,没有考虑某些字符可能比其他字符更重要。例如,在人名匹配中,姓氏可能比名字更重要,但算法无法区分这种权重差异。
七、Jaro算法的实现考虑
在实际实现Jaro算法时,需要注意以下几点:
字符大小写处理:通常情况下,算法会忽略字符的大小写差异,将所有字符统一转换为小写或大写后再进行比较。这可以提高算法对实际应用的适应性。
特殊字符处理:对于包含特殊字符(如标点符号、空格等)的字符串,算法需要决定是否将这些字符视为匹配的一部分。通常的做法是移除非字母数字字符,只比较字母和数字部分。
性能优化:对于较长的字符串,Jaro算法的计算复杂度可能较高。可以通过优化匹配窗口的遍历方式,减少不必要的比较操作,提高算法效率。
边界条件处理:当两个字符串长度差异较大时,匹配窗口可能无法有效覆盖字符匹配的范围。需要考虑如何处理这些边界情况,确保算法的稳定性和准确性。
结果阈值设定:在实际应用中,通常需要设定一个相似度阈值来判断两个字符串是否足够相似。例如,在数据清洗中,可能将阈值设为0.7或0.8,只有相似度超过该阈值的字符串才会被考虑合并。
八、Jaro算法与其他相似度算法的比较
Jaro算法与常见的其他字符串相似度算法相比,具有以下特点:
与Levenshtein距离的比较:Levenshtein距离基于字符的插入、删除和替换操作来计算两个字符串之间的最小编辑距离。而Jaro算法则主要关注字符的匹配和顺序,不考虑这些操作。Levenshtein算法更适用于长字符串的相似度计算,而Jaro算法则更适合短字符串的匹配。
与余弦相似度的比较:余弦相似度通常用于向量空间模型中的文本相似度计算,关注的是词频向量的夹角。而Jaro算法则直接比较字符的匹配情况和顺序。余弦相似度更适合处理长文本或文档级别的相似度计算,而Jaro算法更适合处理短字符串的精确匹配。
与Jaccard指数的比较:Jaccard指数计算两个集合的交集与并集的比值,通常用于集合相似度计算。而Jaro算法则考虑字符的顺序和位置差异。Jaccard指数更适合处理无序集合的相似度计算,而Jaro算法则更适合处理有序字符串的匹配。
与Smith-Waterman算法的比较:Smith-Waterman算法是一种基于动态规划的序列比对算法,通常用于生物信息学中的DNA序列比对。它考虑了字符匹配的连续性和局部相似度。而Jaro算法则更简单,主要关注全局的字符匹配和顺序。Smith-Waterman算法更精确但计算复杂度更高,Jaro算法则更简单但可能不够精确。
九、Jaro算法的未来发展
随着自然语言处理和数据科学的发展,Jaro算法也在不断演进和优化:
扩展应用范围:Jaro算法最初设计用于处理短字符串的相似度计算,但随着研究的深入,它也在不断扩展应用范围,包括处理长文本、多语言字符串等。
与其他算法结合:Jaro算法可以与其他相似度算法结合使用,形成更强大的相似度评估系统。例如,可以先使用Jaro算法进行初步筛选,再使用更复杂的算法进行精确匹配。
改进匹配窗口机制:研究者正在探索更灵活的匹配窗口机制,以提高算法对不同长度字符串的适应性。例如,可以根据字符串的相似度动态调整匹配窗口大小。
考虑字符权重:未来的Jaro算法可能会引入字符权重机制,使某些字符(如姓氏的首字母)比其他字符具有更高的匹配权重。
处理多模态数据:Jaro算法可能会扩展到处理多模态数据,如结合文本和语音信息进行更全面的相似度评估。
总之,Jaro相似度算法作为一种简单而有效的字符串相似度计算方法,通过匹配字符、换位计算和顺序一致性评估,能够准确地反映两个字符串之间的相似程度。理解其原理和计算步骤,可以帮助我们更好地应用这一算法解决实际问题,如数据清洗、拼写纠错和记录链接等。

















 388
388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









