




 本文详细解析了PyTorch中交叉熵损失函数的工作原理,对比了torch.nn.functional.cross_entropy()与torch.nn.CrossEntropyLoss()的区别,通过实例演示了交叉熵函数的计算过程,并解释了其在多分类任务中的应用。
本文详细解析了PyTorch中交叉熵损失函数的工作原理,对比了torch.nn.functional.cross_entropy()与torch.nn.CrossEntropyLoss()的区别,通过实例演示了交叉熵函数的计算过程,并解释了其在多分类任务中的应用。
在PyTorch 中有 torch.nn.functional.cross_entropy() 与 torch.nn.CrossEntropyLoss()
区别可以参考 nn 与 nn.functional 有什么区别
1.交叉熵公式
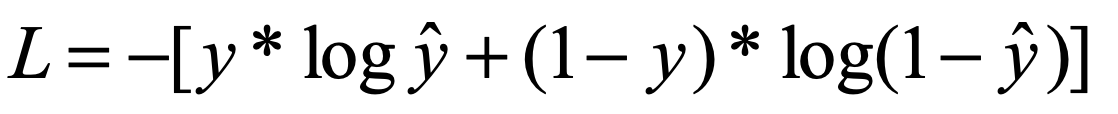
其中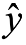 是经过softmax后表征属于某个标签的概率,y表示其实属于某类的概率,在实际样本中,只有0或者1。多分类时,就会变为:
是经过softmax后表征属于某个标签的概率,y表示其实属于某类的概率,在实际样本中,只有0或者1。多分类时,就会变为:
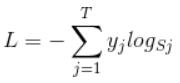
yi 就是上面而分类的y,可以看作是一个1*T的向量,里面的T个值,只有一个值是1,其他T-1个值都是0,也就变为了:
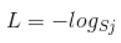
(此处log底为e)Sj为真实标签的概率,Sj=P,简单的softmax计算
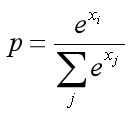
参考一篇博客大概了解cross_entropy函数是怎么进行计算的:网址
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
input = torch.randn(1,5,requires_grad=True) #返回一个标准正态分布的张量
target = torch.empty(1,dtype = torch.long).random_(5)
probs = F.softmax(input, dim=1) #dim=1 代表行,一行代表一组数据 ,转换后一行相加为1 probs是一个二维tensor
output = F.cross_entropy(input,target) #cross_entropy输入不需要经过概率化处理,内部会进行
print ("输入为5类: ")
print (input)
print ("得分转化为概率: ")
print (probs)
print ("要计算loss的类别: ")
print (target)
print ("计算loss的结果: " )
print (output)
first = 0
for i in range(1):
first -= input[i][target[i]]
second = 0
for i in range(1):
for j in range(5):
second += math.exp(input[i][j])
res = 0
res += first +math.log(second)
print ("自己的计算结果1: ")
print (res)
print ("自己的计算结果2: ")
print (-math.log(probs[0][target[0]]))
输出:
输入为5类:
tensor([[ 0.1211, -0.0970, 2.2645, -0.0199, -0.2258]], requires_grad=True)
得分转化为概率:
tensor([[0.0840, 0.0675, 0.7162, 0.0729, 0.0594]], grad_fn=<SoftmaxBackward>)
要计算loss的类别:
tensor([3])
计算loss的结果:
tensor(2.6182, grad_fn=<NllLossBackward>)
自己的计算结果1:
tensor(2.6182, grad_fn=<AddBackward0>)
自己的计算结果2:
2.6181786766366715
在分类任务中训练时,某张图片输入网络,经过特征提取->全连接层分类(得分向量)->最后经过softmax函数得到属于各类的概率,此次预测就已经结束。之后就需要根据得到的结果去反馈,优化模型,此时能参考的只有各个类别的概率,需要将概率转化为调整的一个指标(该调整多少),而这些概率实际需要关注的只有一个:预测为实际标签的概率。这里选择的转化函数就是交叉熵函数,经过整理可以简化-log(底为e),是一个递减函数,概率越高,loss越小。


















 2376
2376

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









