




前言:
今天主要学习了Redis基础知识,比如它的通用命令和Redis的java客户端的一些知识。写一个学习日记记录一下所学的知识。
学习收获:
首先Redis是一种NoSQL数据库,所以在介绍Redis之前先介绍一下NoSQL。
NoSQL:
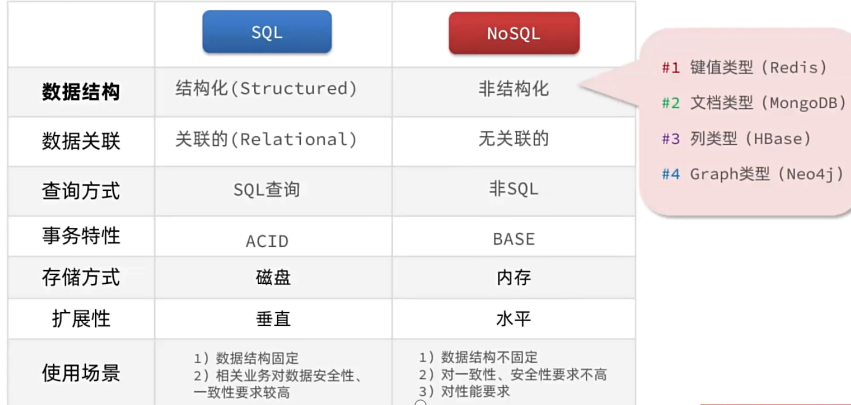
NoSQL与SQL不同的是,它是非关系型数据库,旨在解决传统关系型数据库在处理海量数据、高并发场景、灵活数据模型的局限性,并且更注重高性能、高可用性和可扩展性。S:Structured意为结构化,按照约定去插入数据库,并且结构不能改变。而NoSQL就是一种非结构化的数据库,比如说Redis,Document,Graph等,这些数据结构都没有严格的要求,比较松散。
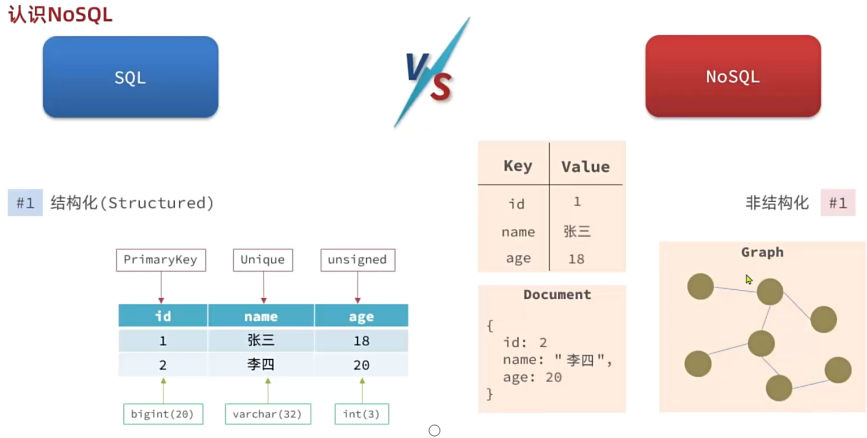
并且NoSQL的表与表之间也是无关联的。NoSQL也没有固定的语法格式,使用比较简单,没有复杂的语法。
不过相比与SQL,NoSQL无法满足事务的ACID这种强一致特性,但是它采用BASE理论(基本可用、软状态、最终一致性)来牺牲强一致性换取性能。
NosQL vs SQL:
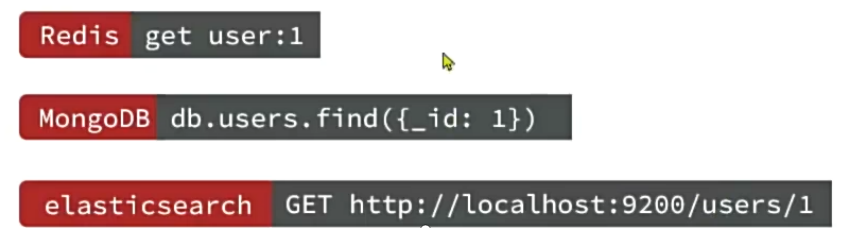
Redis:
Redis(Remote Dictionary Server),远程字典服务器,是一个基于内存的键值型Nosql数据库。
特征:
- 键值型(key-value) 型,value支持多种不同数据结构,功能丰富
- 单线程,每个命令具备原子性
- 低延迟,速度快(基于内存、IO多路复用、良好的编码)
- 支持数据持久化
通过RDB定期快照,将内存数据保存到磁盘,来进行备份和恢复。或者AOF来记录写操作日志,数据更安全,支持重写机制避免文件过大。
- 支持主存集群、分片集群
主存集群可以就是说 从节点可以备份主节点的数据,如果主节点宕机,数据在从节点也能被找得到,并且还能提高IO的效率。而分片集群就是把数据进行了拆分,比如把这些数据拆为了n份,存在不同的节点上去,然后用很多机器一起存,增加了存储的上限。
- 支持多语言客户端
比如说Jedis(Java)、Redis-py(Python)等。
Redis是一个key-value的数据库,key一般是String类型,不过value的类型多种多样。
key的结构:
Redis的key容许有多个单词形成层级结构,多个单词之间用‘ :’隔开,格式如下:
![]()
比如我们的项目名称叫dianping,有user和product两种不同的类型的数据,我们可以这样定义key:
dianping:user:1
dianping:product:1
如果Value是一个Java对象,比如一个User对象,则可以将对象序列化为JSON字符串后存储 。

String类型:
String类型,也就是字符串类型,是Redis中最简单的存储类型。其value是字符串,不过根据字符串的格式不同,又能分为3类:
- String:普通字符串
- int:整数类型,可以做自增、自减操作
- float:浮点类型,可以做自增、自减操作
但是不管哪种格式,底层都是通过字节数组形式存储的,只不过编码方式不同。字符串类型的最大空间不能超过512m。
常用的命令:
SET key "value" # 设置值
GET key # 获取值
INCR counter # 计数器自增(原子性)
DECRBY counter 5 # 计数器减5
SETNX key "value" # 仅当键不存在时设置(用于分布式锁)
SETEX key 3600 "value" # 设置值并同时设置过期时间(秒)
MSET user:1:name "Alice" user:1:age 25 user:1:city "Beijing" #批量操作
Hash类型:
Hash类型,也叫散列,它的value是一个无序字典,类似于Java中的HashMap结构。因为如果用String结构是将对象序列化为JSON字符串后存储,当需要修改对象某个字段时很不方便。而Hash结构可以将对象中的每个字段独立存储,可以针对带个字段做CRUD:
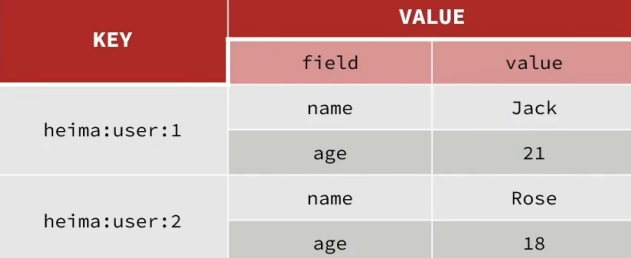
并且相比多个String存储,Hash可以减少内存随便和键空间的消耗。
常用命令:
HSET user:1 name "Alice" # 设置哈希字段
HGET user:1 name # 获取单个字段
HGETALL user:1 # 获取所有字段和值
HINCRBY user:1 age 1 # 字段自增
HDEL user:1 email # 删除字段
List类型:
Redis中的List类型与Java中的LinkedList类似,可以看做是一个双向链表结构。既可以支持正向检索也可以支持反向检索。其特征也与LinkedList类似:
- 有序
- 元素可重复
- 插入和删除速度快
- 查询速度一般
List的底层实现取决于数据量和元素大小:
- 压缩列表(ziplist):
适合于小数据量(元素少,长度短),通过连续内存块存储,节省空间。如果当列表长度或元素大小超过阈值时,自动转为双向列表。
- 双向链表(linkedlist):
适用于大数据量,每个节点包含前驱和后继指针,支持快速的增删改查。并且Redis引入quicklist(双向链表+压缩列表)优化内存占有,每个节点是一个压缩列表,减少链表节点的数量。
常用命令:
|
| 从列表左侧(头部)插入一个或多个元素。 |
RPUSH key value [value ...] | 从列表右侧(尾部)插入一个或多个元素。 |
LPOP key | 删除并返回列表左侧第一个元素。 |
RPOP key | 删除并返回列表右侧第一个元素。 |
LLEN key | 获取列表长度。 |
LRANGE key start stop | 获取列表中指定区间的元素(索引从 0 开始,-1 表示最后一个元素)。 |
LSET key index value | 修改指定索引位置的元素值。 |
LREM key count value | 删除列表中前 count 个值为 value 的元素(count>0 从左往右删,count<0 从右往左删,count=0 删所有)。 |
LPUSHX key value | 仅当列表存在时,从左侧插入元素(原子操作)。 |
RPUSHX key value | 仅当列表存在时,从右侧插入元素(原子操作)。 |
LINDEX key index | 获取指定索引位置的元素。 |
应用场景:
朋友圈点赞或者评论(谁先谁后)。
Set类型:
Redis的Set结构与Java中的HashSet类似,可以看作是一个value为null的HashMap。因为也是一个hash表,因此具备与HashSet类似的特征:
- 无序
- 元素不可重复
- 查找快
- 支持交集、并集、差集等功能
并且Set的底层实现也是由元素类型和数量决定的:
- 整数集合:
适用于所有元素都是整数且数量较少的场景。并且用有序数据存储整数,节省内存,但插入非整数时会自动转换为哈希表。
- 哈希表:
适用于元素为非整数或者数量超过阈值的场景。基于哈希表实现,插入、删除、查询的平均复杂度为O(1).。并且Redis6.0引入渐进式rehash,避免大规模数据迁移时阻塞主线程。
常用命令:
SADD key member [member ...] | 向集合中添加一个或多个元素(自动去重)。 |
SREM key member [member ...] | 从集合中删除一个或多个元素。 |
SCARD key | 获取集合中元素的数量。 |
SISMEMBER key member | 判断元素是否存在于集合中(存在返回1,不存在返回0)。 |
SMEMBERS key | 返回集合中的所有元素(顺序随机)。 |
SRANDMEMBER key [count] | 随机返回集合中的count个元素(不指定count时返回 1 个,可用于抽样)。 |
SPOP key [count] | 随机删除并返回集合中的count个元素(不指定count时删除 1 个)。 |
SINTER key [key ...] | 返回多个集合的交集(共同元素)。 |
SUNION key [key ...] | 返回多个集合的并集(所有元素去重)。 |
SDIFF key [key ...] | 返回第一个集合与其他集合的差集(存在于第一个集合但不存在于其他集合的元素)。 |
应用场景:
共同好友列表,通过多个集合的交集来实现。
SortedSet类型:
Redis的SortedSet是一个可排序的set集合,与Java中的TreeSet有些类似,但是底层数据结构还是差别很大的。SorterSet中的每一个元素都带有一个score属性,可以基于score属性对元素进行排序,底层的实现就是一个跳表加hash表。
SortedSet具备一下特性:
- 可排序
- 元素不重复
- 查询速度快
其底层的跳表(SkipList) + 哈希表:一般元素数量较多或者分数为浮点数使用。
- 跳表:按分数排序,支持快速范围查询。
- 哈希表:存储元素到分数的映射。
常用命令:
ZADD key score member [score member ...] | 向集合中添加元素及分数(重复元素会更新分数)。 |
ZREM key member [member ...] | 删除集合中的一个或多个元素。 |
ZCARD key | 获取集合中元素的数量。 |
ZSCORE key member | 获取元素的分数。 |
ZRANK key member | 获取元素的排名(按分数升序,从 0 开始)。 |
ZREVRANK key member | 获取元素的排名(按分数降序,从 0 开始)。 |
ZRANGE key start stop [WITHSCORES] | 按分数升序返回指定索引范围的元素(start、stop为索引,0-based)。 |
ZREVRANGE key start stop [WITHSCORES] | 按分数降序返回指定索引范围的元素。 |
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count] | 按分数范围升序查询元素(min≤score≤max,(min表示不包含min)。 |
ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count] | 按分数范围降序查询元素。 |
ZINCRBY key increment member | 为元素的分数增加指定增量(支持负数)。 |
ZCOUNT key min max | 统计分数在指定范围内的元素数量。 |
应用场景:
排行榜系统,比如游戏积分排名、商品销量排行等。
Redis的Java客户端:
Jedis:
以Redis命令作为方法的名称,学习成本低,简单实用。但是Jedis实列是线程不安全的,多线程环境下需要基于连接池来使用。
- 再使用Jedis时,我们首先要引入依赖:

- 然后建立连接:
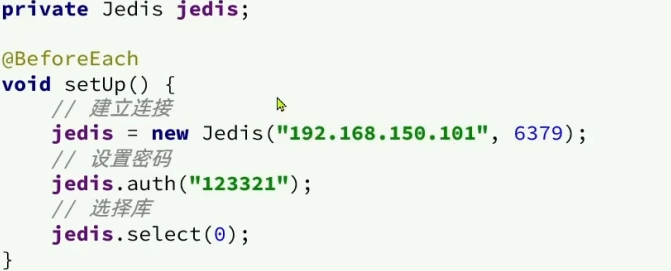
- 此时我们就可以进行测试,比如测试String类型:

- 最后释放资源。

Jedis连接池:
Jedis本身是线程不安全的,如果在多线程且并发的情况下,并且频繁的创建和销毁连接会有性能损耗,所以要通过使用Jedis连接池来连接。
// 配置连接池参数
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMinIdle(0); //最小空闲连接
poolConfig.setMaxTotal(100); // 最大连接数
poolConfig.setMaxIdle(20); // 最大空闲连接数
poolConfig.setTestOnBorrow(true); // 取连接时测试可用性
// 创建连接池(有密码版本)
JedisPool jedisPool = new JedisPool(poolConfig, 192.168.150.101, 6379, 3000, "123456");
//从连接池获取连接
try (Jedis jedis = jedisPool.getResource()) {
// 使用 Jedis 执行 Redis 命令
jedis.set("key", "value");
String value = jedis.get("key");
} catch (Exception e) {
// 处理异常
}
JedisPool(连接池对象)传入的是连接的一些参数,而JedisPoolConfig(连接池配置)传入的是池的一些参数。并且连接池一般就配置:最大连接数,空闲连接数和等待时间。
SpringDataRedis:
SpringData是Spring中数据操作的模块,包含对各种数据库的集成,其中对Redis的集成模块就叫做SpringDataRedis。它集成了Spring生态,可以无缝整合Spring的依赖注入、事务管理、缓存抽象等特性。所以SpringDataRedis有很多功能:
- 提供了对不同Redis客户端的整合
- 提供了RedisTemplate统一API来操作Redis
- 支持Redis的发布订阅模型
- 支持Redis哨兵和Redis集群
- 支持基于Lettuce的响应式编程
- 支持基于JDK、JSON、字符串、Spring对象的数据序列化和反序列化
- 支持基于Redis的JDKCollection实现
他的核心组件就是RedisTemplate,其中封装了各种对Redis的操作。

SpringDataRedis使用:
- 引入依赖:

不管是我们的Redis还是Jedis,底层都会通过commons-pool2实现连接池效果。
- 配置文件:

Springboot的自动装配,可以让我们不用 用编码的方式来配置文件,直接在application.yml配置Redis信息。
- 注入RedisTemplate:
![]()
- 编写测试:

直接注入RedisTemplate,因为SpringBoot实现了自动装配,并且Spring默认使用的lettuce连接池。
SpringDataRedis的序列化方式:
RedisTemplate可以接收任意的Object作为值写入Redis,只不过写入前会把Object序列化为字节形式,默认采用JDK序列化,得到的结果就是这样:

所以这种序列化方式的缺点就是:
- 可读性差
- 内存占用大
具体来说就是因为RedisTemplate的set方法接收的是Object并不是String,所以就会都把他们作为Java对象帮我们转为我们所需要的字节,底层采用了JDK的序列化方式。
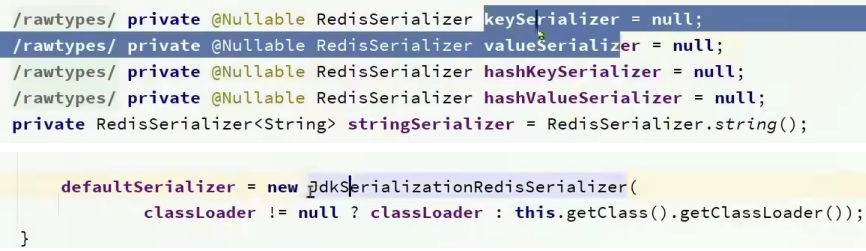
在没定义上面四个值时,就会走上图的第二个这个默认的jdk序列化器。而jdk的序列化器用Object输出流来写出对象,就会把Java对象转为字节。所以采会看到下面这种字节内容。

为了解决这种可读性差我们有两种方式:
- Key使用StringRedis序列化器,Value使用GenericJackson2Json序列化器。所以可以自定义RedisTemplate的序列化方式:

虽然JSON这种的序列化方式可以满足我们的需求,但还是会存在一些问题,如下:
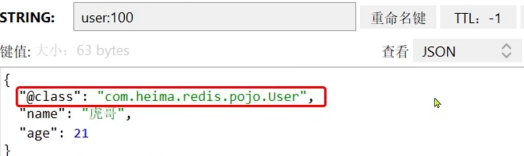
这种方式为了在反序列化时知道对象的类型,JSON序列化器会将类的class类型写入json结果中,存入Redis,带来额外的内存开销。所以我们为了节省内存空间,我们并不会使用JSON序列化器处理value,而是统一使用String序列化器,要求只能存储String类型的key和valu。当需要存储Java对象是,去手动完成对象的序列化和反序列化。 所有就有了我们的第二种。
- 手动序列化和反序列化对象:
Spring默认提供了一个StringRedisTemplate类,它的key和value的序列化方式默认就是String方式,省区了我们自定义RedisTemplate的过程:
public class StringRedisTemplate extends RedisTemplate<String, String> {
/**
* Constructs a new <code>StringRedisTemplate</code> instance. {@link #setConnectionFactory(RedisConnectionFactory)}
* and {@link #afterPropertiesSet()} still need to be called.
*/
public StringRedisTemplate() {
setKeySerializer(RedisSerializer.string());
setValueSerializer(RedisSerializer.string());
setHashKeySerializer(RedisSerializer.string());
setHashValueSerializer(RedisSerializer.string());
}
/**
* Constructs a new <code>StringRedisTemplate</code> instance ready to be used.
*
* @param connectionFactory connection factory for creating new connections
*/
public StringRedisTemplate(RedisConnectionFactory connectionFactory) {
this();
setConnectionFactory(connectionFactory);
afterPropertiesSet();
}
protected RedisConnection preProcessConnection(RedisConnection connection, boolean existingConnection) {
return new DefaultStringRedisConnection(connection);
}
}

通过这种方式读出来的反序列化后的User对象:

总结:
今天回顾了Redis的一些常见的数据结构已经他们的常用命令。并且了解了Jedis和SpringDateRedis的实现方式、如何使用已经他们一些底层的实现原理。总之收获颇丰,特此记录一下。

















 4054
4054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









